Robotic Policy Adaptation via Weight-Space Meta-Learning
Pith reviewed 2026-06-27 21:41 UTC · model grok-4.3
The pith
WIZARD predicts task-specific LoRA weights for frozen vision-language-action policies from a language instruction and short video in one forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
WIZARD learns during meta-training to map task evidence consisting of language instructions and short videos directly to expert LoRA updates, enabling the prediction of task-specific adaptation weights for a frozen VLA policy in one forward pass for unseen tasks.
What carries the argument
Weight-space meta-learner that predicts LoRA parameters from task evidence.
If this is right
- Performance improves by up to 2x on unseen dataset collections and up to 14x on unseen tasks in the LIBERO benchmark.
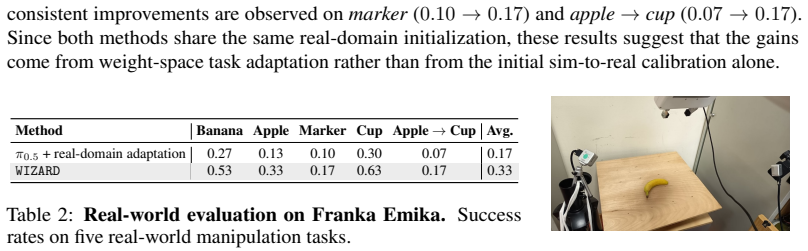
- Generated adapters outperform a real-domain adapted baseline when tested on a physical Franka Emika Panda robot.
- Adaptation occurs without collecting target-task action labels or performing test-time optimization.
Where Pith is reading between the lines
- The same evidence-to-weight mapping could be tested on other parameter-efficient tuning methods beyond LoRA.
- If the meta-learner generalizes across robot embodiments, it might reduce the data needed when moving policies between hardware platforms.
- Task relationships captured in weight space could support rapid switching among many tasks without storing separate adapted policies.
Load-bearing premise
Meta-training on seen tasks produces a mapping from task evidence to expert LoRA updates that generalizes to entirely unseen tasks and real-robot conditions without any further optimization or labels.
What would settle it
Run WIZARD on a set of tasks whose language and visual features have no overlap with the meta-training distribution and measure whether success rates remain higher than the unadapted baseline policy.
Figures











read the original abstract
Vision-Language-Action (VLA) models are emerging as a promising paradigm for robotic manipulation, enabling general-purpose policies trained from large corpora of demonstrations and action labels. However, adapting these models to new tasks still typically requires task-specific demonstrations, action annotations, and additional fine-tuning, making deployment costly and difficult to scale. We propose WIZARD, a weight-space meta-learning framework that sidesteps task-specific fine-tuning by generating task-specific LoRA parameters for a frozen VLA policy. Given only a language instruction and a short demonstration video, WIZARD predicts the corresponding adaptation weights in a single forward pass, without target-task action labels or test-time optimization. During meta-training, WIZARD learns to map task evidence directly to expert LoRA updates, capturing relationships between tasks in weight space. Experiments on LIBERO show that WIZARD improves performance by up to ~2x on unseen dataset collections and up to ~14x on unseen tasks. On a Franka Emika Panda, WIZARD consistently improves over a real-domain adapted baseline, showing that generated adapters provide task-level specialization beyond simulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WIZARD, a weight-space meta-learning approach for Vision-Language-Action (VLA) policies. It trains a meta-learner to map task evidence (language instruction plus short demonstration video) directly to expert LoRA adaptation weights for a frozen base policy. At inference, adaptation occurs in a single forward pass with no target-task action labels and no test-time optimization. Experiments on the LIBERO benchmark are reported to yield up to ~2× gains on unseen dataset collections and ~14× on unseen tasks; real-robot results on a Franka Emika Panda are claimed to outperform a real-domain adapted baseline.
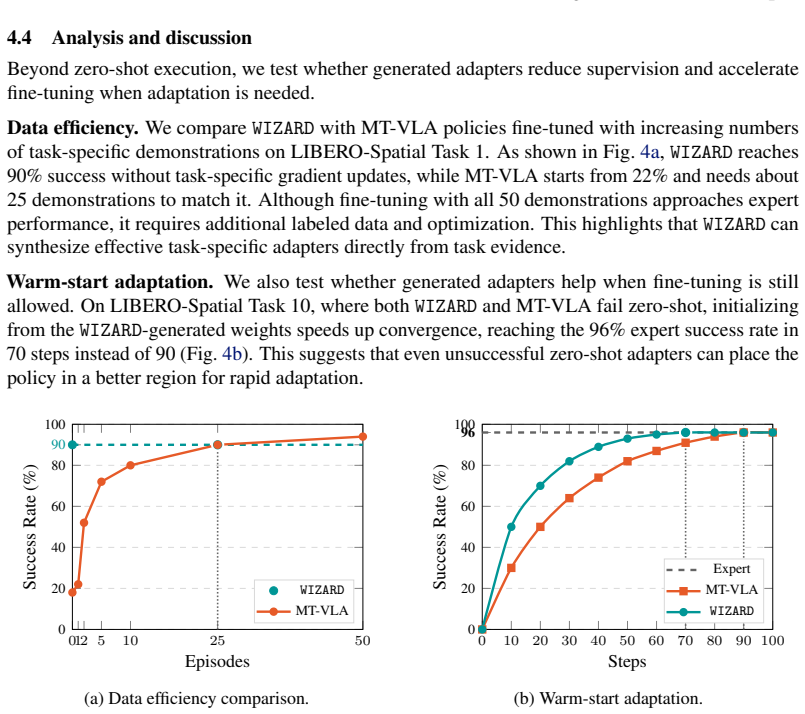
Significance. If the reported generalization holds, the method would materially lower the data and compute cost of deploying VLA policies on new tasks. The core technical idea—learning an explicit mapping from task evidence to weight-space updates rather than performing per-task optimization—is a clear departure from standard fine-tuning or test-time adaptation pipelines and could influence future meta-learning work in robotics.
major comments (3)
- [Abstract] Abstract: the central generalization claim (single-forward-pass adaptation to entirely unseen tasks and real-robot conditions) is supported only by aggregate performance multipliers (~2× and ~14×) with no accompanying experimental protocol, baseline definitions, number of trials, statistical tests, or error bars. This leaves the load-bearing claim that the meta-trained mapping extrapolates beyond the training distribution without further evidence.
- [Experiments (LIBERO results)] The weakest assumption identified in the stress-test note is not addressed: the paper must demonstrate that the LIBERO 'unseen' task splits are distributionally disjoint from meta-training tasks with respect to object categories, skill primitives, and scene structure; otherwise the reported gains may reflect interpolation rather than the claimed extrapolation in weight space.
- [Real-robot experiments] Real-robot section: the claim that generated adapters provide task-level specialization beyond simulation requires explicit comparison of the distribution of visual and proprioceptive evidence between simulation meta-training and real-robot test conditions; without this, the transfer result cannot be isolated from possible domain-gap artifacts.
minor comments (2)
- [Abstract] Abstract: the multipliers '~2×' and '~14×' are presented without stating the absolute success rates or the precise baseline policies against which they are measured; these quantities should appear in the main experimental tables.
- [Method] Notation: the mapping f(evidence) → ΔLoRA is described at a high level but the precise input representation (video encoding, language embedding) and output parameterization (which LoRA layers, rank, scaling) are not formalized in an equation; adding a compact definition would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, agreeing where additional evidence or clarification is warranted and outlining the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central generalization claim (single-forward-pass adaptation to entirely unseen tasks and real-robot conditions) is supported only by aggregate performance multipliers (~2× and ~14×) with no accompanying experimental protocol, baseline definitions, number of trials, statistical tests, or error bars. This leaves the load-bearing claim that the meta-trained mapping extrapolates beyond the training distribution without further evidence.
Authors: We agree that the abstract, due to length constraints, presents only aggregate multipliers without protocol details. In the revision we will update the abstract to reference the experimental settings (e.g., number of trials per task, multiple random seeds for error bars, and baseline definitions) and add explicit cross-references to Section 4 and the appendix, where full protocols, statistical tests, and per-task results already appear. This strengthens the presentation of the generalization claim without changing its substance. revision: yes
-
Referee: [Experiments (LIBERO results)] The weakest assumption identified in the stress-test note is not addressed: the paper must demonstrate that the LIBERO 'unseen' task splits are distributionally disjoint from meta-training tasks with respect to object categories, skill primitives, and scene structure; otherwise the reported gains may reflect interpolation rather than the claimed extrapolation in weight space.
Authors: This is a fair and important observation. The original manuscript relies on the official LIBERO unseen splits without an explicit distributional analysis. We will add this analysis in the revised experiments section, including quantitative comparisons of object category overlap, skill primitive distributions (via available annotations), and scene structure embeddings between meta-training and unseen tasks. The results of this analysis will be reported transparently to support or qualify the extrapolation interpretation. revision: yes
-
Referee: [Real-robot experiments] Real-robot section: the claim that generated adapters provide task-level specialization beyond simulation requires explicit comparison of the distribution of visual and proprioceptive evidence between simulation meta-training and real-robot test conditions; without this, the transfer result cannot be isolated from possible domain-gap artifacts.
Authors: We acknowledge that an explicit distributional comparison is needed to isolate task specialization from domain-gap effects. In the revision we will add quantitative and visual comparisons (feature histograms, statistical distances on visual embeddings, and proprioceptive statistics) between the simulation meta-training distribution and the real-robot test conditions. This will be placed in the real-robot experiments section or appendix to substantiate the claim. revision: yes
Circularity Check
No circularity: standard meta-learning setup with independent generalization claims
full rationale
The paper trains a predictor during meta-training to map task evidence (language + video) to expert LoRA updates on seen tasks, then evaluates single-forward-pass inference on held-out unseen tasks and real-robot conditions. No equations, fitted parameters, or self-citations are shown that reduce the reported gains to inputs by construction. This is ordinary supervised meta-learning whose validity rests on empirical splits rather than definitional equivalence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Meta-training on seen tasks produces a mapping from task evidence to expert LoRA updates that generalizes to unseen tasks without further optimization.
invented entities (1)
-
WIZARD meta-learner
no independent evidence
Reference graph
Works this paper leans on
-
[1]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, T. Jackson, S. Jesmonth, N. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, I. Leal, K.-H. Lee, S. Levine, Y . Lu, U. Malla, D. Manjunath, I. Mordatch, O. Nachum, C. Parada, J. Peralta, E. Perez, K. Pertsch, J....
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Driess, F
D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. H. Vuong, T. Yu, W. Huang, Y . Chebotar, P. Sermanet, D. Duckworth, S. Levine, V . Van- houcke, K. Hausman, M. Toussaint, K. Greff, A. Zeng, I. Mordatch, and P. R. Florence. Palm-e: An embodied multimodal language model. InInternational Conference on Machine Learning,
-
[3]
URLhttps://api.semanticscholar.org/CorpusID:257364842
-
[4]
J. E. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, and W. Chen. Lora: Low-rank adaptation of large language models.ArXiv, abs/2106.09685, 2021. URL https://api. semanticscholar.org/CorpusID:235458009
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
X. Zhou, Y . Xu, G. Tie, Y . Chen, G. Zhang, D. Chu, P. Zhou, and L. Sun. Libero-pro: Towards robust and fair evaluation of vision-language-action models beyond memorization, 2026. URL https://arxiv.org/abs/2510.03827
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
M. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. Openvla: An open-source vision-language-action model.CoRL, 2024
2024
-
[7]
Black, N
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π0: A vision-language- action flow model for general robot control, 2026. URL https://arxiv.org...
2026
-
[8]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. V...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [9]
-
[10]
Hegde, S
S. Hegde, S. Das, G. Salhotra, and G. S. Sukhatme. Warpd: World model assisted reactive policy diffusion. 2024. URLhttps://api.semanticscholar.org/CorpusID:278960144
2024
- [11]
-
[12]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning, 2023. URLhttps://arxiv.org/abs/2306.03310
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
S. Reed, K. Zolna, E. Parisotto, S. G. Colmenarejo, A. Novikov, G. Barth-Maron, M. Gimenez, Y . Sulsky, J. Kay, J. T. Springenberg, T. Eccles, J. Bruce, A. Razavi, A. Edwards, N. Heess, Y . Chen, R. Hadsell, O. Vinyals, M. Bordbar, and N. de Freitas. A generalist agent, 2022. URL https://arxiv.org/abs/2205.06175. 9
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, K. Choromanski, T. Ding, D. Driess, K. A. Dubey, C. Finn, P. R. Florence, C. Fu, M. G. Arenas, K. Gopalakrishnan, K. Han, K. Hausman, A. Herzog, J. Hsu, B. Ichter, A. Irpan, N. J. Joshi, R. C. Julian, D. Kalashnikov, Y . Kuang, I. Leal, S. Levine, H. Michalewski, I. Mordatch, K. Pertsch, K. Rao, K. Reymann, ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
URLhttps://api.semanticscholar.org/CorpusID:260293142
-
[16]
D. Kalashnikov, J. Varley, Y . Chebotar, B. Swanson, R. Jonschkowski, C. Finn, S. Levine, and K. Hausman. Mt-opt: Continuous multi-task robotic reinforcement learning at scale, 2021. URLhttps://arxiv.org/abs/2104.08212
-
[17]
Bousmalis, G
K. Bousmalis, G. Vezzani, D. Rao, C. Devin, A. X. Lee, M. Bauzá, T. Davchev, Y . Zhou, A. Gupta, A. Raju, A. Laurens, C. Fantacci, V . Dalibard, M. Zambelli, M. F. Martins, R. Pevce- viciute, M. Blokzijl, M. Denil, N. Batchelor, T. Lampe, E. Parisotto, K. Zolna, S. E. Reed, S. G. Colmenarejo, J. Scholz, A. Abdolmaleki, O. Groth, J.-B. Regli, O. O. Sushkov...
2023
-
[18]
arXiv preprint arXiv:2210.03094 , year=
Y . Jiang, A. Gupta, Z. Zhang, G. Wang, Y . Dou, Y . Chen, L. Fei-Fei, A. Anandkumar, Y . Zhu, and L. J. Fan. Vima: General robot manipulation with multimodal prompts.ArXiv, abs/2210.03094,
-
[19]
URLhttps://api.semanticscholar.org/CorpusID:252735175
-
[20]
X. Zhang and A. Boularias. One-shot imitation learning with invariance matching for robotic manipulation, 2024. URLhttps://arxiv.org/abs/2405.13178
-
[21]
Achille, M
A. Achille, M. Lam, R. Tewari, A. Ravichandran, S. Maji, C. C. Fowlkes, S. Soatto, and P. Per- ona. Task2vec: Task embedding for meta-learning.2019 IEEE/CVF International Conference on Computer Vision (ICCV), pages 6429–6438, 2019. URLhttps://api.semanticscholar. org/CorpusID:60440365
2019
-
[22]
James, M
S. James, M. Bloesch, and A. J. Davison. Task-embedded control networks for few-shot imitation learning.Conference on Robot Learning (CoRL), 2018
2018
- [23]
- [24]
-
[25]
Kumar, Z
A. Kumar, Z. Fu, D. Pathak, and J. Malik. Rma: Rapid motor adaptation for legged robots. 2021
2021
- [26]
-
[27]
J. Beck, M. Jackson, R. Vuorio, and S. Whiteson. Hypernetworks in meta-reinforcement learning. InConference on Robot Learning, 2022. URL https://api.semanticscholar. org/CorpusID:253018758
2022
-
[28]
J. Ba, G. E. Hinton, V . Mnih, J. Z. Leibo, and C. Ionescu. Using fast weights to attend to the recent past. InNeural Information Processing Systems, 2016. URL https://api. semanticscholar.org/CorpusID:568305. 10
2016
-
[29]
Generative NeuroEvolution for Deep Learning
P. Verbancsics and J. Harguess. Generative neuroevolution for deep learning, 2013. URL https://arxiv.org/abs/1312.5355
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[30]
D. Ha, A. Dai, and Q. V . Le. Hypernetworks, 2016. URL https://arxiv.org/abs/1609. 09106
2016
-
[31]
Brock, T
A. Brock, T. Lim, J. M. Ritchie, and N. Weston. Smash: One-shot model architecture search through hypernetworks.International Conference on Learning Representations, 2018. URL https://api.semanticscholar.org/CorpusID:3489117
2018
-
[32]
B. Knyazev, M. Drozdzal, G. W. Taylor, and A. Romero-Soriano. Parameter predic- tion for unseen deep architectures.ArXiv, abs/2110.13100, 2021. URL https://api. semanticscholar.org/CorpusID:239768239
-
[33]
K. Schürholt, B. Knyazev, X. G. i Nieto, and D. Borth. Hyper-representations as generative models: Sampling unseen neural network weights.ArXiv, abs/2209.14733, 2022. URL https://api.semanticscholar.org/CorpusID:252595700
-
[34]
W. Peebles, I. Radosavovic, T. Brooks, A. A. Efros, and J. Malik. Learning to learn with generative models of neural network checkpoints, 2022. URL https://arxiv.org/abs/ 2209.12892
- [35]
-
[36]
K. Wang, D. Tang, B. Zeng, Y . Yin, Z. Xu, Y . Zhou, Z. Zang, T. Darrell, Z. Liu, and Y . You. Neural network diffusion, 2024
2024
- [37]
- [38]
- [39]
-
[40]
Charakorn, E
R. Charakorn, E. Cetin, Y . Tang, and R. T. Lange. Text-to-lora: Instant transformer adaption,
- [41]
-
[42]
Z. Zhang. A flexible new technique for camera calibration.IEEE Transactions on pattern analysis and machine intelligence, 22(11):1330–1334, 2000
2000
-
[43]
Khazatsky, K
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, P. D. Fagan, J. Hejna, M. Itkina, M. Lepert, Y . J. Ma, P. T. Miller, J. Wu, S. Belkhale, S. Dass, H. Ha, A. Jain, A. Lee, Y . Lee, M. Memmel, S. Park, I. Radosavovic, K. Wang, A. Zhan, K. Black, C. Chi, K. B. Hatch, S. Lin, J. ...
2024
-
[44]
Siciliano, L
B. Siciliano, L. Sciavicco, L. Villani, and G. Oriolo.Robotics: Modelling, Planning and Control. Advanced Textbooks in Control and Signal Processing. Springer London, 2010. ISBN 9781846286414
2010
-
[45]
Y . He and S. Liu. Analytical inverse kinematics for Franka Emika Panda – a geometrical solver for 7-DOF manipulators with unconventional design. In2021 9th International Conference on Control, Mechatronics and Automation (ICCMA2021). IEEE, Nov. 2021. doi:10.1109/ ICCMA54375.2021.9646185. 12 Appendix This appendix provides supplementary material supportin...
-
[46]
" 2:if".action_in_proj
This aligned feature map is then temporally tiled across 168 distinct time steps, yielding an input tensor of shape168×16×512. Decomposed 3D convolutional blocks:The core of the decoder utilizes custom 3D convolutional layers. Rather than computing a standard 3D convolution, which is prohibitively expensive and prone to overfitting, we decompose the opera...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.