DEFINED: A Data-Efficient Computational Framework for Fine-Grained Creativity Assessment in Debate Scenarios
Pith reviewed 2026-06-27 22:53 UTC · model grok-4.3
The pith
DEFINED scores debate creativity accurately and stably by training a language model on limited expert data through hierarchical metrics and constrained augmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
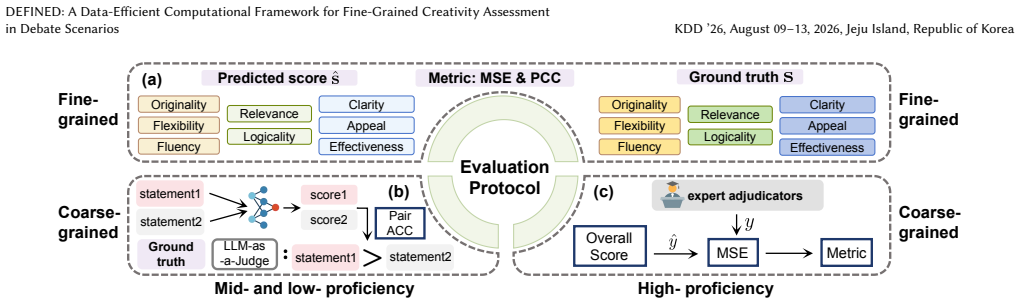
DEFINED operationalizes debate creativity through a hierarchical eight-dimensional metric system, implemented via a pre-trained autoregressive language model with a hierarchical scoring head that supports both fine-grained and coarse-grained evaluation; statements and expert scores from authentic competitions are augmented under constraints to address elite bias, and a mixed-granularity training strategy enables robust learning from limited fine-grained supervision, yielding accurate and stable scoring that outperforms prompt-based large language model evaluators and existing debate scoring methods.
What carries the argument
hierarchical eight-dimensional metric system with hierarchical scoring head on a pre-trained autoregressive language model, supported by constrained data augmentation and mixed-granularity training
If this is right
- The same architecture can produce both fine-grained dimension scores and overall creativity ratings from the same input.
- Constrained augmentation of real competition data reduces reliance on large expert-labeled corpora while preserving ecological validity.
- The resulting model outperforms both zero-shot or few-shot prompting of large language models and prior automated debate scoring techniques on the collected authentic data.
- An empirical study with debate-naive participants indicates the scores remain meaningful for mid-to-low proficiency populations.
Where Pith is reading between the lines
- If the hierarchical metric proves stable across domains, the same training recipe could be tested on other open-ended creative tasks such as policy analysis or scientific hypothesis generation.
- The data-efficiency properties suggest the framework could lower the cost barrier for deploying creativity assessment in educational or recruitment settings that currently depend on repeated human review.
- A direct test would be to retrain the scoring head on a different base model while keeping the eight-dimensional metric fixed and measure whether performance remains above the reported baselines.
Load-bearing premise
The eight-dimensional hierarchy correctly captures the relevant aspects of debate creativity so that the model can generalize from small amounts of expert-labeled data.
What would settle it
Collect new expert scores on a fresh set of debate transcripts never seen during training or augmentation; if the model's predictions show large systematic deviation from those expert scores on the same transcripts, the central performance claim does not hold.
Figures




read the original abstract
Human creativity has emerged as a critical competency in the era of large language models. Assessing creativity in complex, open-ended environments is a grand challenge in data mining, currently hindered by a reliance on standardized simple tasks and the scarcity of fine-grained expert data. As an ecologically valid assessment context, debate reflects multiple dimensions of creativity, encompassing both divergent thinking and convergent thinking. Moreover, debate is a data-rich domain, with a large volume of publicly accessible materials. Current mainstream automated scoring methods are poorly suited to complex settings such as debate, and therefore still rely on costly human evaluation. To this end, this paper proposes DEFINED, a data-efficient computational framework for fine-grained creativity assessment in debate scenarios. DEFINED operationalizes debate creativity through a hierarchical eight-dimensional metric system, implemented via a pre-trained autoregressive language model with a hierarchical scoring head that supports both fine-grained and coarse-grained evaluation. Statements and their associated expert scores were obtained from authentic debate competitions, and a constrained data augmentation strategy was employed to address the elite bias inherent in the original data. DEFINED adopts a mixed-granularity training strategy enabling robust learning from limited fine-grained supervision annotated by trained graduate experts. To rigorously validate ecological validity beyond synthetic benchmarks, we incorporate an empirical study with debate-naive participants, utilizing these authentic data to serve as a qualitative case study for mid-to-low proficiency populations. Across our evaluation protocol, our scoring model achieves accurate and stable scoring, outperforming prompt-based large language model evaluators and existing debate scoring methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DEFINED, a data-efficient framework for fine-grained creativity assessment in debate scenarios. It operationalizes debate creativity via a hierarchical eight-dimensional metric system implemented through a pre-trained autoregressive language model with a hierarchical scoring head. The approach uses constrained data augmentation to address elite bias in authentic debate competition data and a mixed-granularity training strategy to learn from limited fine-grained expert annotations by trained graduate students. An ecological validity study with debate-naive participants is included as a qualitative case study. The central claim is that the resulting scoring model achieves accurate and stable scoring, outperforming prompt-based LLM evaluators and existing debate scoring methods.
Significance. If the performance claims hold with rigorous evidence, the work could meaningfully advance automated assessment of complex, multi-dimensional creativity in ecologically valid open-ended tasks, reducing dependence on costly human raters while addressing data scarcity through augmentation and mixed-granularity training.
major comments (2)
- [Abstract] Abstract: the claim that 'our scoring model achieves accurate and stable scoring, outperforming prompt-based large language model evaluators and existing debate scoring methods' is presented without any metrics, baselines, dataset splits, inter-rater reliability statistics, ablation results on mixed-granularity training, or quantitative tables. This directly undermines verification of the central performance claim.
- [Abstract / Methods description] Hierarchical eight-dimensional metric system and mixed-granularity training (described in abstract): the operationalization is given only at high level with no equations, dimension definitions, annotation protocol details, or analysis of how the hierarchy supports robust learning from limited supervision. This is load-bearing for the data-efficiency and robustness assertions.
Simulated Author's Rebuttal
We thank the referee for their review and the opportunity to respond. The abstract is a concise summary, while the full manuscript contains the detailed metrics, equations, definitions, and protocols referenced in the comments. We address each point below and propose targeted revisions where appropriate to strengthen clarity without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'our scoring model achieves accurate and stable scoring, outperforming prompt-based large language model evaluators and existing debate scoring methods' is presented without any metrics, baselines, dataset splits, inter-rater reliability statistics, ablation results on mixed-granularity training, or quantitative tables. This directly undermines verification of the central performance claim.
Authors: We acknowledge that the abstract presents the performance claim at a summary level without accompanying numbers. The full manuscript reports these details in the Results section, including correlation metrics, baseline comparisons, dataset information, inter-rater reliability, and ablation studies on mixed-granularity training. To address the concern directly, we will revise the abstract to incorporate key quantitative results from our evaluations. revision: yes
-
Referee: [Abstract / Methods description] Hierarchical eight-dimensional metric system and mixed-granularity training (described in abstract): the operationalization is given only at high level with no equations, dimension definitions, annotation protocol details, or analysis of how the hierarchy supports robust learning from limited supervision. This is load-bearing for the data-efficiency and robustness assertions.
Authors: The abstract provides a high-level overview consistent with standard practice for brevity. The full manuscript defines the eight dimensions with equations and hierarchy in the Methods section, details the annotation protocol (including graduate student training and reliability checks) in the Data section, and analyzes the mixed-granularity training strategy with supporting experiments in the Training and Results sections. We will revise the abstract to include a brief reference to the hierarchical structure and its role in data efficiency. revision: partial
Circularity Check
No circularity detected; no derivations or equations present to analyze
full rationale
The provided abstract and description contain no equations, training objectives, derivations, or first-principles claims that could reduce to inputs by construction. The framework is described at a high level through operationalization of metrics, data augmentation, and training strategies, with performance claims resting on empirical evaluation rather than any self-referential mathematical structure. No self-citations, fitted inputs renamed as predictions, or ansatzes are identifiable in the text, making the derivation chain self-contained by absence of any load-bearing formal steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Catalin Anghel, Andreea Alexandra Anghel, Emilia Pecheanu, Ioan Susnea, Adina Cocu, and Adrian Istrate. 2025. Multi-Model Dialectical Evaluation of LLM Rea- soning Chains: A Structured Framework with Dual Scoring Agents.Informatics 12 (2025), 76
2025
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. 2025. Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923(2025)
Pith/arXiv arXiv 2025
-
[3]
Roger E Beaty and Dan R Johnson. 2021. Automating creativity assessment with SemDis: An open platform for computing semantic distance.Behavior research methods53, 2 (2021), 757–780. KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Tongzhou Yu et al
2021
-
[4]
Qian Cao, Xiting Wang, Yuzhuo Yuan, Yahui Liu, Fang Luo, and Ruihua Song
-
[5]
Evaluating text creativity across diverse domains: A dataset and large language model evaluator.arXiv preprint arXiv:2505.19236(2025)
arXiv 2025
-
[6]
Shelley H Carson, Jordan B Peterson, and Daniel M Higgins. 2005. Reliability, validity, and factor structure of the creative achievement questionnaire.Creativity research journal17, 1 (2005), 37–50
2005
-
[7]
Liying Cheng, Lidong Bing, Ruidan He, Qian Yu, Yan Zhang, and Luo Si. 2022. IAM: A Comprehensive and Large-Scale Dataset for Integrated Argument Mining Tasks. InProceedings of the 60th Annual Meeting of the Association for Computa- tional Linguistics. Dublin, Ireland, 2277–2287
2022
-
[8]
Arthur Cropley. 2006. In praise of convergent thinking.Creativity research journal18, 3 (2006), 391–404
2006
-
[9]
Paul V DiStefano, John D Patterson, and Roger E Beaty. 2025. Automatic scoring of metaphor creativity with large language models.Creativity Research Journal 37, 4 (2025), 555–569
2025
-
[10]
Boris Forthmann, Oluwatosin Oyebade, Adebusola Ojo, Fritz Günther, and Heinz Holling. 2019. Application of latent semantic analysis to divergent thinking is biased by elaboration.The Journal of Creative Behavior53, 4 (2019), 559–575
2019
-
[11]
Amnon Glassner and Baruch B. Schwarz. 2007. What stands and develops between creative and critical thinking? Argumentation?Thinking Skills and Creativity2 (2007)
2007
-
[12]
Shai Gretz, Roni Friedman, Edo Cohen-Karlik, Assaf Toledo, Dan Lahav, Ranit Aharonov, and Noam Slonim. 2020. A Large-Scale Dataset for Argument Quality Ranking: Construction and Analysis. InProceedings of the 34th AAAI Conference on Artificial Intelligence. New York, NY, 7805–7813
2020
-
[13]
Joy Paul Guilford. 1956. The structure of intellect.Psychological bulletin53, 4 (1956), 267
1956
-
[14]
Paul Guilford
J. Paul Guilford. 1967. The Nature of Human Intelligence.McGraw-Hill,(1967)
1967
-
[15]
David JP Heinen and Dan R Johnson. 2018. Semantic distance: An automated measure of creativity that is novel and appropriate.Psychology of Aesthetics, Creativity, and the Arts12, 2 (2018), 144
2018
-
[16]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-Rank Adaptation of Large Language Models. InProceedings of the 10th International Conference on Learning Representations. Virtual
2022
-
[17]
Xinyu Hu, Li Lin, Mingqi Gao, Xunjian Yin, and Xiaojun Wan. 2024. Themis: A reference-free nlg evaluation language model with flexibility and interpretability. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 15924–15951
2024
-
[18]
Emanuel Jauk, Mathias Benedek, and Aljoscha C Neubauer. 2014. The road to creative achievement: A latent variable model of ability and personality predictors. European journal of personality28, 1 (2014), 95–105
2014
-
[19]
Mahdi Karami and Ali Ghodsi. 2024. Orchid: Flexible and Data-Dependent Convolution for Sequence Modeling. InAdvances in Neural Information Processing Systems 38. Vancouver,Canada
2024
-
[20]
T Leopold, Attilio Di Battista, Ximena Jativa, Shuvasish Sharma, R Li, and S Grayling. 2025. Future of jobs report 2025. InWorld Economic Forum. Geneva, Switzerland
2025
-
[21]
Ruizhe Li, Chiwei Zhu, Benfeng Xu, Xiaorui Wang, and Zhendong Mao. 2025. Automated Creativity Evaluation for Large Language Models: A Reference-Based Approach.Computing Research Repositoryabs/2504.15784 (2025)
arXiv 2025
-
[22]
Jingcong Liang, Rong Ye, Meng Han, Ruofei Lai, Xinyu Zhang, Xuan-Jing Huang, and Zhongyu Wei. 2024. Debatrix: Multi-dimensional debate judge with iterative chronological analysis based on llm. InFindings of the 62nd Annual Meeting of the Association for Computational Linguistics. Bangkok, Thailand, 14575–14595
2024
-
[23]
Xinyi Liu, Pinxin Liu, and Hangfeng He. 2024. An Empirical Analysis on Large Language Models in Debate Evaluation. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics. Bangkok, Thailand, 470–487
2024
-
[24]
Devin C Lonergan, Ginamarie M Scott, and Michael D Mumford. 2004. Evaluative aspects of creative thought: Effects of appraisal and revision standards.Creativity Research Journal16, 2-3 (2004), 231–246
2004
-
[25]
Simone A Luchini, Nadine T Maliakkal, Paul V DiStefano, Antonio Laverghetta Jr, John D Patterson, Roger E Beaty, and Roni Reiter-Palmon. 2025. Automated scoring of creative problem solving with large language models: A comparison of originality and quality ratings.Psychology of Aesthetics, Creativity, and the Arts(2025)
2025
-
[26]
Martha T Mednick and Sharon Halpern. 1968. Remote associates test.Psycholog- ical Review(1968)
1968
-
[27]
Sarnoff Mednick. 1962. The associative basis of the creative process.Psychological review69, 3 (1962), 220
1962
-
[28]
Michael D Mumford and Tristan McIntosh. 2017. Creative thinking processes: The past and the future.The Journal of Creative Behavior51, 4 (2017), 317–322
2017
-
[29]
Michael D Mumford, Michele I Mobley, Roni Reiter-Palmon, Charles E Uhlman, and Lesli M Doares. 1991. Process analytic models of creative capacities.Creativity research journal4, 2 (1991), 91–122
1991
-
[30]
2024.PISA 2022 Results (Volume III): Creative minds, creative schools
OECD. 2024.PISA 2022 Results (Volume III): Creative minds, creative schools. OECD Publications Centre, Paris, France
2024
-
[31]
Peter Organisciak, Selcuk Acar, Denis Dumas, and Kelly Berthiaume. 2023. Be- yond semantic distance: Automated scoring of divergent thinking greatly im- proves with large language models.Thinking Skills and Creativity49 (2023), 101356
2023
-
[32]
Namgyoo K Park, Monica Youngshin Chun, and Jinju Lee. 2016. Revisiting indi- vidual creativity assessment: Triangulation in subjective and objective assessment methods.Creativity Research Journal28, 1 (2016), 1–10
2016
-
[33]
Philip M Podsakoff, Scott B MacKenzie, Jeong-Yeon Lee, and Nathan P Podsakoff
-
[34]
Common method biases in behavioral research: a critical review of the literature and recommended remedies.Journal of applied psychology88, 5 (2003), 879
2003
-
[35]
José Pombal, Dongkeun Yoon, Patrick Fernandes, Ian Wu, Seungone Kim, Ricardo Rei, Graham Neubig, and André FT Martins. 2025. M-Prometheus: A Suite of Open Multilingual LLM Judges.arXiv preprint arXiv:2504.04953(2025)
arXiv 2025
-
[36]
Ranjani Prabhakaran, Adam E Green, and Jeremy R Gray. 2014. Thin slices of creativity: Using single-word utterances to assess creative cognition.Behavior research methods46, 3 (2014), 641–659
2014
-
[37]
Allen Roush, Yusuf Shabazz, Arvind Balaji, Peter Zhang, Stefano Mezza, Markus Zhang, Sanjay Basu, Sriram Vishwanath, Mehdi Fatemi, and Ravid Shwartz- Ziv. 2024. OpenDebateEvidence: A Massive-Scale Argument Mining and Sum- marization Dataset. InAdvances in Neural Information Processing Systems 38. Vancouver,Canada
2024
-
[38]
Mark A Runco and Garrett J Jaeger. 2012. The standard definition of creativity. Creativity research journal24, 1 (2012), 92–96
2012
-
[39]
Gabriella Skitalinskaya, Jonas Klaff, and Henning Wachsmuth. 2021. Learning From Revisions: Quality Assessment of Claims in Argumentation at Scale. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics. Virtual, 1718–1729
2021
-
[40]
Noam Slonim, Yonatan Bilu, Carlos Alzate, Roy Bar-Haim, Ben Bogin, Francesca Bonin, Leshem Choshen, Edo Cohen-Karlik, Lena Dankin, Lilach Edelstein, Liat Ein-Dor, Roni Friedman-Melamed, Assaf Gavron, Ariel Gera, Martin Gleize, Shai Gretz, Dan Gutfreund, Alon Halfon, Daniel Hershcovich, Ron Hoory, Yufang Hou, Shay Hummel, Michal Jacovi, Charles Jochim, Yoa...
2021
-
[41]
Hwanjun Song, Minseok Kim, Dongmin Park, Yooju Shin, and Jae-Gil Lee. 2023. Learning From Noisy Labels With Deep Neural Networks: A Survey.IEEE Transactions on Neural Networks and Learning Systems34 (2023), 8135–8153
2023
-
[42]
Branden Thornhill-Miller, Anaëlle Camarda, Maxence Mercier, Jean-Marie Burkhardt, Tiffany Morisseau, Samira Bourgeois-Bougrine, Florent Vinchon, Stephanie El Hayek, Myriam Augereau-Landais, Florence Mourey, et al. 2023. Creativity, critical thinking, communication, and collaboration: Assessment, certi- fication, and promotion of 21st century skills for th...
2023
-
[43]
E Paul Torrance. 1966. Torrance tests of creative thinking.Educational and psychological measurement(1966)
1966
-
[44]
Henning Wachsmuth, Nona Naderi, Ivan Habernal, Yufang Hou, Graeme Hirst, Iryna Gurevych, and Benno Stein. 2017. Argumentation Quality Assessment: Theory vs. Practice. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vol. 2. Vancouver, Canada, 250–255
2017
-
[45]
Fuyu Wang, Jiangtong Li, Kun Zhu, and Changjun Jiang. 2025. InspireDebate: Multi-Dimensional Subjective-Objective Evaluation-Guided Reasoning and Opti- mization for Debating.arXiv preprint arXiv:2506.18102(2025)
arXiv 2025
-
[46]
Lu Wang, Nick Beauchamp, Sarah Shugars, and Kechen Qin. 2017. Winning on the Merits: The Joint Effects of Content and Style on Debate Outcomes.Transactions of the Association for Computational Linguistics5 (2017), 219–232
2017
-
[47]
Xuewei Wang, Weiyan Shi, Richard Kim, Yoojung Oh, Sijia Yang, Jingwen Zhang, and Zhou Yu. 2019. Persuasion for Good: Towards a Personalized Persuasive Dialogue System for Social Good. InProceedings of the 57th Conference of the Association for Computational Linguistics, Vol. 1. Florence, Italy, 5635–5649
2019
-
[48]
Yixuan Wang, Yue Huang, Hong Qian, Yunzhao Wei, Yifei Ding, Wenkai Wang, Zhi Liu, Zhongjing Huang, Aimin Zhou, and Jiajun Guo. 2026. AlphaContext: An Evolutionary Tree-based Psychometric Context Generator for Creativity Assessment.arXiv preprint arXiv:2604.18398(2026)
Pith/arXiv arXiv 2026
-
[49]
Weini Weng, Chang Liu, Guoli Zhao, Luwei Song, and Xingli Zhang. 2025. Intel- ligent Assessment of Scientific Creativity by Integrating Data Augmentation and Pseudo-Labeling.Information16, 9 (2025), 785
2025
-
[50]
Wenjing Yang, Adam E Green, Qunlin Chen, Yoed N Kenett, Jiangzhou Sun, Dongtao Wei, and Jiang Qiu. 2022. Creative problem solving in knowledge-rich contexts.Trends in Cognitive Sciences26, 10 (2022), 849–859
2022
-
[51]
Liang Zeng, Robert W Proctor, and Gavriel Salvendy. 2011. Can traditional diver- gent thinking tests be trusted in measuring and predicting real-world creativity? Creativity research journal23, 1 (2011), 24–37. DEFINED: A Data-Efficient Computational Framework for Fine-Grained Creativity Assessment in Debate Scenarios KDD ’26, August 09–13, 2026, Jeju Isl...
2011
-
[52]
Yiwen Zhang, Hong Qian, Xiaowen Wang, Yixvan Wang, Mingjia Li, Jin Wu, Jiajun Guo, Xiangfeng Wang, Chanjin Zheng, and Aimin Zhou. 2026. Research on Automatic Evaluation of Idea Quality in Knowledge Building Communities. China Educational Technology472 (2026), 85–94
2026
-
[53]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM-as-a-Judge with MT- Bench and Chatbot Arena. InAdvances in Neural Information Processing Systems
2023
-
[54]
mentioning
New Orleans, LA. Appendix A Detailed Metric System Detailed definition of eight dimensional metric system: • Originality (Creativity).Originality refers to the relative uniqueness or rarity of ideas or solutions proposed within a given context [12, 36, 41]. In debates, this dimension con- cerns the distinctiveness of claims, analogies, or argumenta- tive ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.