SWE-Explore: Benchmarking How Coding Agents Explore Repositories
Pith reviewed 2026-06-27 21:20 UTC · model grok-4.3
The pith
Agentic explorers outperform classical retrieval when locating relevant code regions for repository issues.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
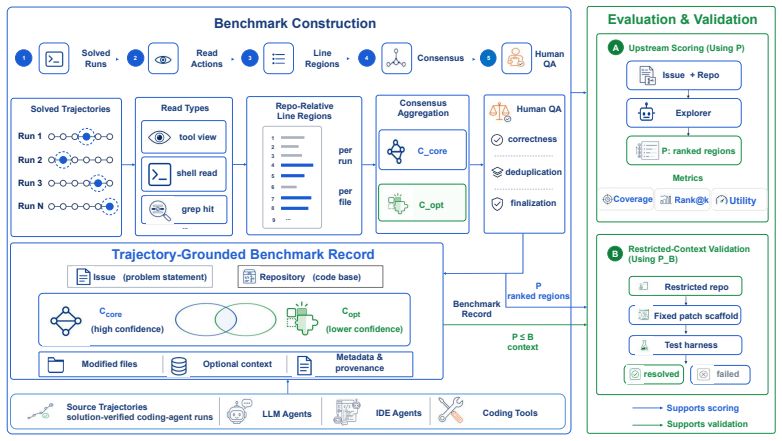
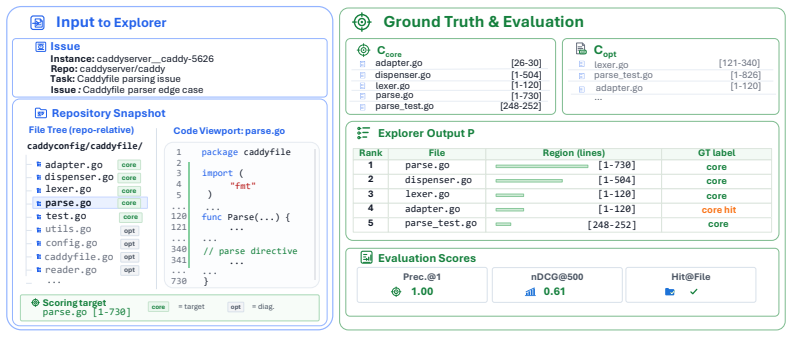
SWE-Explore requires an explorer to produce a ranked list of relevant code regions for a given issue under a fixed line budget. Line-level ground truth is distilled from trajectories of agents that independently solved the same issue. Across retrieval baselines, general coding agents, and specialized localizers, agentic explorers achieve higher coverage and better ranking; the three evaluation dimensions strongly track downstream repair success. File-level localization is already strong for modern methods, but line-level coverage and context-efficient ranking remain the axes that differentiate state-of-the-art explorers.
What carries the argument
SWE-Explore benchmark that scores ranked retrieval of code regions under a fixed line budget using ground truth extracted from successful agent trajectories.
If this is right
- Higher scores on coverage, ranking, and context-efficiency metrics predict higher rates of successful bug repair.
- Agentic explorers form a distinct performance tier above classical retrieval methods.
- File-level localization is already strong while line-level coverage and efficient ranking remain the differentiating factors.
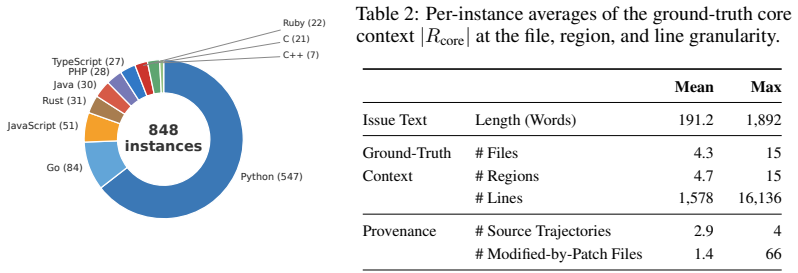
- The benchmark spans 10 languages and 203 repositories, supporting broad comparison of exploration strategies.
Where Pith is reading between the lines
- Separating exploration evaluation from full repair allows targeted iteration on retrieval components before full pipeline testing.
- Ground truth drawn only from successful trajectories may systematically favor exploration styles already known to work.
- The fixed-budget format could be reused to study context-length trade-offs when scaling agents to larger repositories.
Load-bearing premise
That the code regions visited in successful independent trajectories accurately represent the minimal relevant set an explorer should retrieve for each issue.
What would settle it
A method that scores highest on SWE-Explore coverage, ranking, and efficiency but produces no measurable increase in end-to-end repair rates when plugged into a full agent pipeline.
Figures


read the original abstract
Repository-level coding benchmarks such as SWE-bench have driven a rapid surge in the capabilities of coding agents. Yet they usually treat coding tasks as a holistic, binary prediction problem (e.g., resolved or unresolved), neglecting fine-grained agent capabilities such as repository understanding, context retrieval, code localization, and bug diagnosis. In this paper, we introduce SWE-Explore, a benchmark that isolates the evaluation of repository exploration, a critical capability of coding agents. Given a repository and an issue, SWE-Explore asks an explorer to return a ranked list of relevant code regions under a fixed line budget. SWE-Explore covers 848 issues across 10 programming languages and 203 open-source repositories. For each instance, we derive line-level ground truth from independent agent trajectories that successfully solved the same issue, distilling the specific code regions their solution paths actually consulted. We evaluate exploration along coverage, ranking, and context-efficiency dimensions, showing that these metrics strongly track downstream repair behavior. Across a broad set of retrieval methods, general coding agents, and specialized localizers, we find that agentic explorers form a clear tier above classical retrieval. While file-level localization is already strong for modern methods, line-level coverage and efficient ranking remain the key axes differentiating state-of-the-art explorers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SWE-Explore, a benchmark isolating repository exploration for coding agents. Given an issue and repo, explorers return a ranked list of relevant code regions under a fixed line budget. Ground truth is line-level regions distilled from independent successful agent trajectories that solved the issue. The benchmark spans 848 issues across 10 languages and 203 repositories. Evaluation uses coverage, ranking, and context-efficiency metrics, which are shown to track downstream repair performance. Results indicate agentic explorers form a clear tier above classical retrieval methods, with file-level localization already strong but line-level coverage and efficient ranking as key differentiators.
Significance. If the evaluation protocol is free of bias, the work fills a gap by providing fine-grained metrics for exploration (a prerequisite for repair) rather than binary SWE-bench outcomes. The scale (multi-language, hundreds of repos) and the reported correlation between exploration metrics and repair success are useful contributions for guiding agent development. Credit is due for releasing a benchmark that separates exploration from end-to-end repair.
major comments (1)
- [Abstract and ground-truth construction section] Abstract and ground-truth construction section: line-level ground truth is obtained by distilling code regions consulted in independent successful agent trajectories. Because relevance is defined exactly by the paths taken by those trajectories, any explorer whose retrieval behavior correlates with the ground-truth-generating agents receives inflated coverage and ranking scores by construction. Classical retrieval methods that surface different but functionally necessary regions receive no credit. This directly undermines the headline claim that agentic explorers form a clear tier above classical retrieval and that the metrics strongly track repair behavior. The paper should either (a) provide an independent (e.g., human-annotated or cross-agent-class) ground-truth validation or (b) quantify how much the observed tiering changes when ground truth is replaced by an alternative source.
minor comments (2)
- [Methods] The abstract states that trajectories are 'independent,' but the manuscript should explicitly report the set of agents used to generate ground truth versus those evaluated, including any overlap in model families or prompting strategies.
- [Results] Table or figure reporting per-language or per-repository variance in the agentic-vs-classical gap would strengthen the 'clear tier' claim.
Simulated Author's Rebuttal
We thank the referee for highlighting this important methodological consideration regarding ground-truth construction. We respond to the concern below and indicate planned revisions.
read point-by-point responses
-
Referee: Abstract and ground-truth construction section: line-level ground truth is obtained by distilling code regions consulted in independent successful agent trajectories. Because relevance is defined exactly by the paths taken by those trajectories, any explorer whose retrieval behavior correlates with the ground-truth-generating agents receives inflated coverage and ranking scores by construction. Classical retrieval methods that surface different but functionally necessary regions receive no credit. This directly undermines the headline claim that agentic explorers form a clear tier above classical retrieval and that the metrics strongly track repair behavior. The paper should either (a) provide an independent (e.g., human-annotated or cross-agent-class) ground-truth validation or (b) quantify how much the observed tiering changes when ground truth is replaced by an alternative source.
Authors: The ground truth is derived exclusively from trajectories of agents that independently succeeded in resolving the issues, capturing the precise regions consulted during effective repairs. This is intentional: the benchmark measures an explorer's ability to surface code that has been shown to enable task completion, rather than regions that might be relevant under other criteria. While we recognize that this construction can advantage explorers whose behavior aligns with the ground-truth agents, the manuscript already reports that the resulting coverage, ranking, and efficiency metrics correlate with downstream repair success across a wide range of methods, including classical retrieval baselines. This empirical correlation provides evidence that the metrics remain informative for practical agent development. We will revise the manuscript to add an explicit discussion paragraph in the ground-truth section addressing the design rationale, the potential for behavioral correlation, and the supporting repair-performance correlation as validation. We do not perform a full alternative ground-truth experiment, as that lies outside the current scope. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper constructs line-level ground truth from independent successful agent trajectories (abstract) and evaluates a range of retrieval methods, general agents, and localizers against coverage/ranking/efficiency metrics that are reported to track repair. This construction uses an external success filter on separate trajectories rather than defining relevance via the evaluated explorers themselves or reducing any claimed result to a fitted parameter or self-citation. No equations, self-definitional loops, or load-bearing self-citations appear; the benchmark remains self-contained against its stated external anchor.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Successful agent trajectories on the same issue provide the authoritative set of relevant code regions for exploration evaluation.
Forward citations
Cited by 2 Pith papers
-
LLM Agents Can See Code Repositories
Visual graphs of repository structure added to text inputs for multimodal LLM agents reduce token consumption by up to 26% while maintaining or improving issue-resolution accuracy.
-
Code Isn't Memory: A Structural Codebase Index Inside a Coding Agent
Ablation study finds that a structural codebase index improves localization and resolve rates in coding agents on two SWE benchmarks without raising per-cell cost.
Reference graph
Works this paper leans on
-
[1]
Claude code: Ai-assisted coding in real-world codebases, 2025
Anthropic. Claude code: Ai-assisted coding in real-world codebases, 2025. URL https: //claude.ai/code. Accessed: 2026-05
2025
-
[2]
Ibragim Badertdinov, Alexander Golubev, Maksim Nekrashevich, Anton Shevtsov, Simon Karasik, Andrei Andriushchenko, Maria Trofimova, Daria Litvintseva, and Boris Yangel. Swe- rebench: An automated pipeline for task collection and decontaminated evaluation of software engineering agents, 2025. URLhttps://arxiv.org/abs/2505.20411
arXiv 2025
-
[3]
Beyondswe: Can current code agent survive beyond single-repo bug fixing?, 2026
Guoxin Chen, Fanzhe Meng, Jiale Zhao, Minghao Li, Daixuan Cheng, Huatong Song, Jie Chen, Yuzhi Lin, Hui Chen, Xin Zhao, Ruihua Song, Chang Liu, Cheng Chen, Kai Jia, and Ji-Rong 10 Wen. Beyondswe: Can current code agent survive beyond single-repo bug fixing?, 2026. URL https://arxiv.org/abs/2603.03194
Pith/arXiv arXiv 2026
-
[4]
Swe-exp: Experience-driven software issue resolution.arXiv preprint arXiv:2507.23361, 2025
Silin Chen, Shaoxin Lin, Yuling Shi, Heng Lian, Xiaodong Gu, Longfei Yun, Dong Chen, Lin Cao, Jiyang Liu, Nu Xia, et al. Swe-exp: Experience-driven software issue resolution.arXiv preprint arXiv:2507.23361, 2025
arXiv 2025
-
[5]
Prasanna, Arman Cohan, and Xingyao Wang
Zhaoling Chen, Xiangru Tang, Gangda Deng, Fang Wu, Jialong Wu, Zhiwei Jiang, Viktor K. Prasanna, Arman Cohan, and Xingyao Wang. LocAgent: Graph-guided LLM agents for code localization.CoRR, abs/2503.09089, 2025. doi: 10.48550/arXiv.2503.09089
-
[6]
Jimenez, John Yang, Leyton Ho, Tejal Patwardhan, Kevin Liu, and Aleksander Madry
Neil Chowdhury, James Aung, Chan Jun Shern, Oliver Jaffe, Dane Sherburn, Giulio Starace, Evan Mays, Rachel Dias, Marwan Aljubeh, Mia Glaese, Carlos E. Jimenez, John Yang, Leyton Ho, Tejal Patwardhan, Kevin Liu, and Aleksander Madry. Introducing SWE-bench verified, August 2024. URLhttps://openai.com/index/introducing-swe-bench-verified/. OpenAI milestone, ...
2024
-
[7]
Swe-bench pro: Can ai agents solve long-horizon software engineering tasks?, 2025
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, Karmini Sampath, Maya Krishnan, Srivatsa Kundurthy, Sean Hendryx, Zifan Wang, Vijay Bharadwaj, Jeff Holm, Raja Aluri, Chen Bo Calvin Zhang, Noah Jacobson, Bing Liu, and Brad Kenstler. Swe-bench pro: Can ai agents solve long-ho...
Pith/arXiv arXiv 2025
-
[8]
CodeSearchNet challenge: Evaluating the state of semantic code search, 2019
Hamel Husain, Ho-Hsiang Wu, Tiferet Gazit, Miltiadis Allamanis, and Marc Brockschmidt. CodeSearchNet challenge: Evaluating the state of semantic code search, 2019. URL https: //arxiv.org/abs/1909.09436
Pith/arXiv arXiv 2019
-
[9]
Cumulated gain-based evaluation of IR techniques
Kalervo Järvelin and Jaana Kekäläinen. Cumulated gain-based evaluation of IR techniques. ACM Transactions on Information Systems, 20(4):422–446, 2002. doi: 10.1145/582415.582418
-
[10]
Issue localization via llm-driven iterative code graph searching, 2025
Zhonghao Jiang, Xiaoxue Ren, Meng Yan, Wei Jiang, Yong Li, and Zhongxin Liu. Issue localization via llm-driven iterative code graph searching, 2025. URL https://arxiv.org/ abs/2503.22424
arXiv 2025
-
[11]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? InThe Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=VTF8yNQM66
2024
-
[12]
Swe-debate: Competitive multi-agent debate for software issue resolution
Han Li, Yuling Shi, Shaoxin Lin, Xiaodong Gu, Heng Lian, Xin Wang, Yantao Jia, Tao Huang, and Qianxiang Wang. Swe-debate: Competitive multi-agent debate for software issue resolution. arXiv preprint arXiv:2507.23348, 2025
arXiv 2025
-
[13]
Barr, Federica Sarro, Zhaoyang Chu, and He Ye
Han Li, Letian Zhu, Bohan Zhang, Rili Feng, Jiaming Wang, Yue Pan, Earl T. Barr, Federica Sarro, Zhaoyang Chu, and He Ye. ContextBench: A benchmark for context retrieval in coding agents.CoRR, abs/2602.05892, 2026. doi: 10.48550/arXiv.2602.05892
-
[14]
Repobench: Benchmarking repository- level code auto-completion systems
Tianyang Liu, Canwen Xu, and Julian McAuley. Repobench: Benchmarking repository- level code auto-completion systems. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=pPjZIOuQuF
2024
-
[15]
Training software engineering agents and verifiers with swe-gym, 2025
Jiayi Pan, Xingyao Wang, Graham Neubig, Navdeep Jaitly, Heng Ji, Alane Suhr, and Yizhe Zhang. Training software engineering agents and verifiers with swe-gym, 2025. URL https: //arxiv.org/abs/2412.21139
Pith/arXiv arXiv 2025
-
[16]
Weihan Peng, Yuling Shi, Yuhang Wang, Xinyun Zhang, Beijun Shen, and Xiaodong Gu. Swe-qa: Can language models answer repository-level code questions?arXiv preprint arXiv:2509.14635, 2025
Pith/arXiv arXiv 2025
-
[17]
The probabilistic relevance framework: BM25 and beyond.Foundations and Trends in Information Retrieval, 3(4):333–389, 2009
Stephen Robertson and Hugo Zaragoza. The probabilistic relevance framework: BM25 and beyond.Foundations and Trends in Information Retrieval, 3(4):333–389, 2009. doi: 10.1561/ 1500000019. 11
2009
-
[18]
Term-weighting approaches in automatic text retrieval
Gerard Salton and Christopher Buckley. Term-weighting approaches in automatic text retrieval. Information Processing & Management, 24(5):513–523, 1988. doi: 10.1016/0306-4573(88) 90021-0
-
[19]
Yuling Shi, Songsong Wang, Chengcheng Wan, Min Wang, and Xiaodong Gu. From code to correctness: Closing the last mile of code generation with hierarchical debugging.arXiv preprint arXiv:2410.01215, 2024
arXiv 2024
-
[20]
Longcodezip: Compress long context for code language models
Yuling Shi, Yichun Qian, Hongyu Zhang, Beijun Shen, and Xiaodong Gu. Longcodezip: Compress long context for code language models. In2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE), pages 141–153. IEEE, 2025
2025
-
[21]
Between lines of code: Unraveling the distinct patterns of machine and human programmers
Yuling Shi, Hongyu Zhang, Chengcheng Wan, and Xiaodong Gu. Between lines of code: Unraveling the distinct patterns of machine and human programmers. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE), pages 1628–1639. IEEE, 2025
2025
-
[22]
CodeScout: Contextual Problem Statement Enhancement for Software Agents
Manan Suri, Xiangci Li, Mehdi Shojaie, Songyang Han, Chao-Chun Hsu, Shweta Garg, Aniket Anand Deshmukh, and Varun Kumar. CodeScout: Contextual problem statement en- hancement for software agents.CoRR, abs/2603.05744, 2026. doi: 10.48550/arXiv.2603.05744
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2603.05744 2026
-
[23]
SWE-dev: Building software engineering agents with training and inference scaling
Haoran Wang, Zhenyu Hou, Yao Wei, Jie Tang, and Yuxiao Dong. SWE-dev: Building software engineering agents with training and inference scaling. InFindings of the Association for Computational Linguistics: ACL 2025, pages 3742–3761. Association for Computational Linguistics, 2025. doi: 10.18653/v1/2025.findings-acl.193. URL https://aclanthology. org/2025.f...
-
[24]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig. OpenHands: An open platform for AI soft...
Pith/arXiv arXiv 2024
-
[25]
Context compression for llm agents: A survey of methods, failure modes, and evaluation
Yifei Wang, Ziteng Wang, Yuling Shi, Silin Chen, Xinrui Wang, Yueqi Wang, Beijun Shen, Linjing Li, Xiaodong Gu, Julian McAuley, et al. Context compression for llm agents: A survey of methods, failure modes, and evaluation. 2026
2026
-
[26]
SWE-Pruner: Self-Adaptive Context Pruning for Coding Agents
Yuhang Wang, Yuling Shi, Mo Yang, Rongrui Zhang, Shilin He, Heng Lian, Yuting Chen, Siyu Ye, Kai Cai, and Xiaodong Gu. SWE-pruner: Self-adaptive context pruning for coding agents. CoRR, abs/2601.16746, 2026. doi: 10.48550/arXiv.2601.16746
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.16746 2026
-
[27]
Agentless: Demystifying LLM-based Software Engineering Agents
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. Agentless: Demystifying LLM-based software engineering agents.CoRR, abs/2407.01489, 2024. doi: 10.48550/arXiv. 2407.01489
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2024
-
[28]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik R
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik R. Narasimhan, and Ofir Press. SWE-agent: Agent-computer interfaces enable automated software engineering. InAdvances in Neural Information Processing Systems, 2024. URL https: //openreview.net/forum?id=mXpq6ut8J3
2024
-
[29]
SWE-bench multimodal: Do AI systems generalize to visual software domains? InThe Thirteenth International Conference on Learning Representations, 2025
John Yang, Carlos E Jimenez, Alex L Zhang, Kilian Lieret, Joyce Yang, Xindi Wu, Ori Press, Niklas Muennighoff, Gabriel Synnaeve, Karthik R Narasimhan, Diyi Yang, Sida Wang, and Ofir Press. SWE-bench multimodal: Do AI systems generalize to visual software domains? InThe Thirteenth International Conference on Learning Representations, 2025. URL https: //ope...
2025
-
[30]
John Yang, Kilian Lieret, Carlos E. Jimenez, Alexander Wettig, Kabir Khandpur, Yanzhe Zhang, Binyuan Hui, Ofir Press, Ludwig Schmidt, and Diyi Yang. Swe-smith: Scaling data for software engineering agents, 2025. URLhttps://arxiv.org/abs/2504.21798
Pith/arXiv arXiv 2025
-
[31]
OrcaLoca: An LLM agent framework for software issue localization
Zhongming Yu, Hejia Zhang, Yujie Zhao, Hanxian Huang, Matrix Yao, Ke Ding, and Jishen Zhao. OrcaLoca: An LLM agent framework for software issue localization. InInterna- tional Conference on Machine Learning, 2025. URL https://openreview.net/forum? id=LyUfPOvM6I. 12
2025
-
[32]
Multi-swe-bench: A multilingual benchmark for issue resolving, 2025
Daoguang Zan, Zhirong Huang, Wei Liu, Hanwu Chen, Linhao Zhang, Shulin Xin, Lu Chen, Qi Liu, Xiaojian Zhong, Aoyan Li, Siyao Liu, Yongsheng Xiao, Liangqiang Chen, Yuyu Zhang, Jing Su, Tianyu Liu, Rui Long, Kai Shen, and Liang Xiang. Multi-swe-bench: A multilingual benchmark for issue resolving, 2025. URLhttps://arxiv.org/abs/2504.02605
Pith/arXiv arXiv 2025
-
[33]
Linghao Zhang, Shilin He, Chaoyun Zhang, Yu Kang, Bowen Li, Chengxing Xie, Junhao Wang, Maoquan Wang, Yufan Huang, Shengyu Fu, Elsie Nallipogu, Qingwei Lin, Yingnong Dang, Saravan Rajmohan, and Dongmei Zhang. Swe-bench goes live!, 2025. URL https: //arxiv.org/abs/2505.23419
arXiv 2025
-
[34]
AutoCodeRover: Au- tonomous program improvement
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury. AutoCodeRover: Au- tonomous program improvement. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, 2024. doi: 10.1145/3650212.3680384
-
[35]
MULocBench: A benchmark for localizing code and non-code issues in software projects, 2025
Zejun Zhang, Jian Wang, Qingyun Yang, Yifan Pan, Yi Tang, Yi Li, Zhenchang Xing, Tian Zhang, Xuandong Li, and Guoan Zhang. MULocBench: A benchmark for localizing code and non-code issues in software projects, 2025. URLhttps://arxiv.org/abs/2509.25242
arXiv 2025
-
[36]
Jian Zhou, Hongyu Zhang, and David Lo. Where should the bugs be fixed? more accurate information retrieval-based bug localization based on bug reports. InProceedings of the 34th International Conference on Software Engineering, pages 14–24. IEEE, 2012. doi: 10.1109/ ICSE.2012.6227210
arXiv 2012
-
[37]
SWE Context Bench: A Benchmark for Context Learning in Coding
Jared Zhu, Minhao Hu, and Junde Wu. SWE context bench: A benchmark for context learning in coding.CoRR, abs/2602.08316, 2026. doi: 10.48550/arXiv.2602.08316. A Dataset Details This appendix supplements §3.2. The main paper reports the aggregate benchmark statistics; here we specify the retained instance set, record schema, and repository-snapshot assumpti...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.08316 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.