DuMate-DeepResearch: An Auditable Multi-Agent System with Recursive Search and Rubric-Grounded Reasoning
Pith reviewed 2026-06-27 22:02 UTC · model grok-4.3
The pith
A multi-agent framework decouples core logic from tools and adds graph planning, recursive search agents, and rubric optimization to handle long-horizon deep research tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
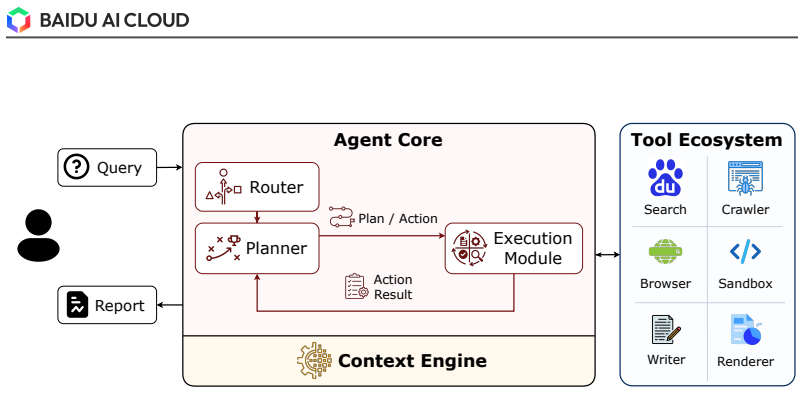
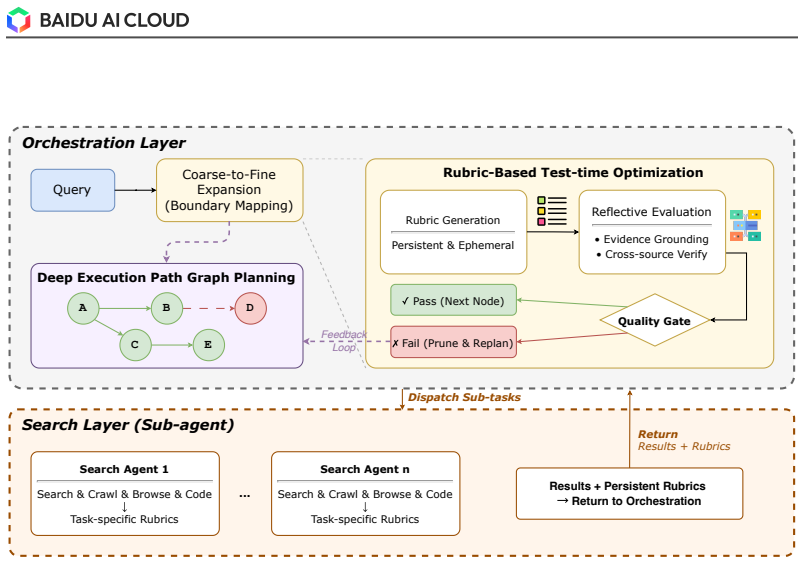
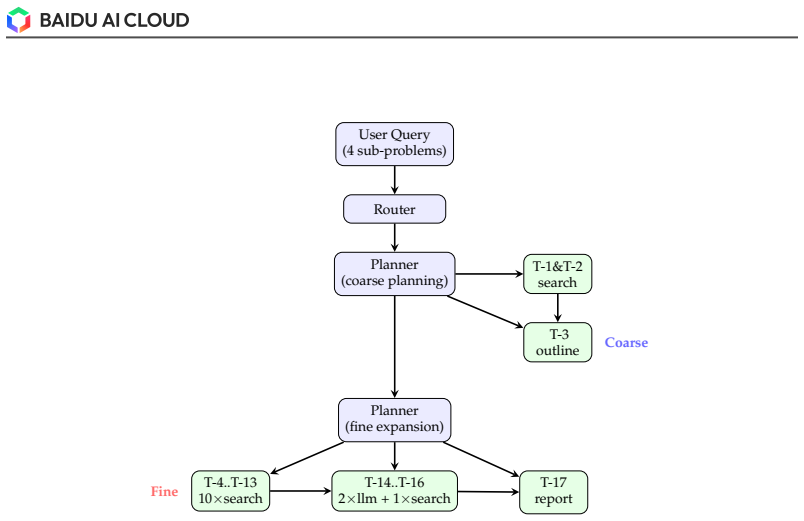
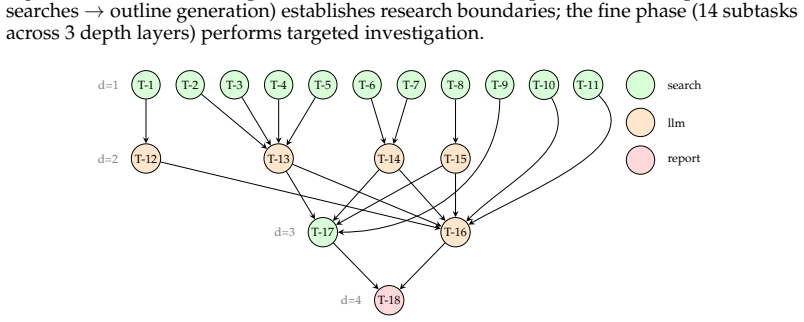
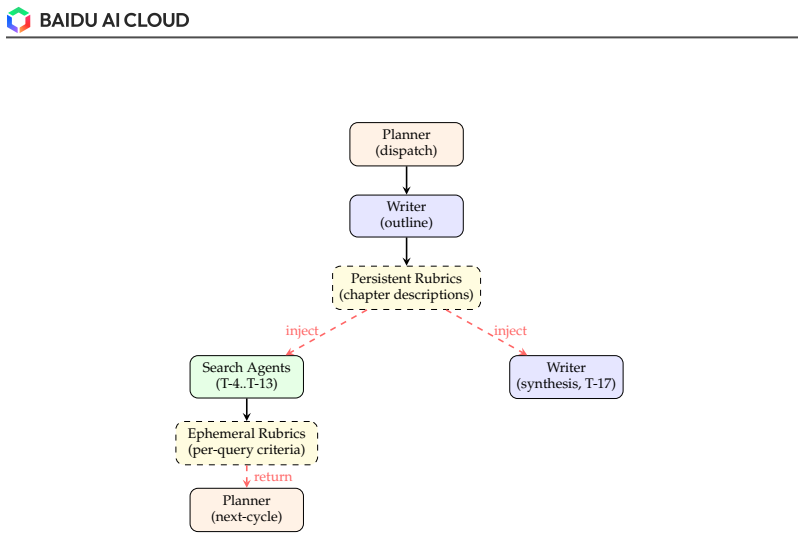
The central claim is that decoupling the Agent Core from the Tool Ecosystem for explicit traceability, combined with a graph-based dynamic planning strategy that expands and revises the roadmap via reflection, re-planning, backtracking, and parallel branching, a recursive two-level execution design that delegates sub-tasks to an inner Search Agent running its own loop, and a rubric-based test-time optimization that generates task-specific quality criteria as live scaffolds for evidence-grounded synthesis and adaptive stopping, enables the system to overcome the four main limitations of current deep research agents and reach the highest scores on two benchmarks.
What carries the argument
The three mechanisms—graph-based dynamic planning strategy, recursive two-level execution design with an inner Search Agent, and rubric-based test-time optimization mechanism—carry the argument by addressing planning scope, execution stability, and synthesis grounding.
If this is right
- Every intermediate decision and tool call becomes explicitly traceable because the Agent Core is separated from the Tool Ecosystem.
- The research roadmap can be continuously revised through reflection, re-planning, backtracking, and parallel branching.
- Complex search sub-tasks are isolated inside an inner Search Agent that runs its own planning loop, reducing noise in long-horizon execution.
- Task-specific rubrics generated at test time serve as dynamic criteria for evidence-grounded synthesis and adaptive stopping.
Where Pith is reading between the lines
- The auditability feature could support verification needs in domains where decision paths must be reviewed after the fact.
- The recursive delegation pattern might transfer to other agent workflows that involve noisy external tools or extended sequences of actions.
- Rubric generation at runtime could be tested as a general technique for steering synthesis in open-ended generation tasks beyond research reports.
Load-bearing premise
The two benchmarks validly measure deep research capability and that performance differences are caused by the three proposed mechanisms rather than other implementation factors or benchmark tuning.
What would settle it
An ablation experiment that removes the recursive Search Agent or the rubric mechanism and measures whether overall scores on DeepResearch Bench and DeepResearch Bench II fall below the previous best reported systems would settle whether those mechanisms drive the gains.
Figures
read the original abstract
Deep Research (DR) has emerged as a new agentic paradigm to tackle complex, open-ended research tasks, demanding systems that can iteratively frame problems, acquire evidence, verify sources, and synthesize long-form reports. In practice, however, current DR systems are constrained by four interrelated limitations: long-horizon planning over an underspecified scope, the bottleneck of decomposing and scheduling such tasks within a single agent, hallucination risk in long-form synthesis, and limited process auditability. This technical report presents DuMate-DeepResearch, a multi-agent DR framework built on the Qianfan Agent Foundry. The framework decouples the Agent Core, which handles task understanding, planning, and scheduling, from an extensible Tool Ecosystem for retrieval, evidence acquisition, and report rendering, making every intermediate decision and tool invocation explicitly traceable. Building on this infrastructure, DuMate-DeepResearch further introduces three mechanisms: (i) a graph-based dynamic planning strategy expands the research roadmap coarse-to-fine and continuously revises it through reflection, re-planning, backtracking, and parallel branching; (ii) a recursive two-level execution design delegates each complex search sub-task to an inner Search Agent that runs its own planning loop, isolating noisy retrieval and stabilizing long-horizon execution; (iii) a rubric-based test-time optimization mechanism dynamically generates task-specific quality criteria and uses them as live reasoning scaffolds for evidence-grounded synthesis and adaptive stopping. Across two deep research benchmarks, DuMate-DeepResearch establishes new state-of-the-art results: the best overall score (58.03%) on DeepResearch Bench, and the best overall score (61.95%) on DeepResearch Bench II while ranking first in information recall and analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents DuMate-DeepResearch, an auditable multi-agent system for deep research tasks built on the Qianfan Agent Foundry. It decouples the Agent Core (task understanding, planning, scheduling) from an extensible Tool Ecosystem (retrieval, evidence acquisition, report rendering) to ensure traceability of decisions. Three mechanisms are introduced: (i) graph-based dynamic planning that expands the research roadmap coarse-to-fine and revises it via reflection, re-planning, backtracking, and parallel branching; (ii) recursive two-level execution that delegates complex search sub-tasks to an inner Search Agent running its own planning loop; (iii) rubric-based test-time optimization that dynamically generates task-specific quality criteria as reasoning scaffolds for synthesis and adaptive stopping. The system reports new state-of-the-art overall scores of 58.03% on DeepResearch Bench and 61.95% on DeepResearch Bench II, with first place in information recall and analysis.
Significance. If the reported scores are robust and the performance gains can be attributed to the three mechanisms, the work contributes a practical, traceable multi-agent architecture that directly targets long-horizon planning, execution stability, and synthesis quality in agentic research systems. The explicit auditability through decoupled components and live rubrics is a constructive emphasis for the field.
major comments (1)
- [the benchmark results and experimental evaluation] The central claim attributes the SOTA scores (58.03% and 61.95%) to the graph-based dynamic planning, recursive two-level execution, and rubric-based optimization, yet the experimental evaluation reports only the complete system against external baselines. No ablation studies (full system vs. system minus one mechanism) are described to isolate the contribution of each mechanism. This attribution is load-bearing for the claims in the abstract.
minor comments (1)
- The abstract states specific benchmark scores without accompanying details on baselines, statistical tests, error bars, or data splits; the full experimental section should supply these for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The concern about the lack of ablation studies to support attribution of the reported SOTA performance to the three proposed mechanisms is well-taken and directly addresses a load-bearing aspect of our claims. We will revise the experimental evaluation accordingly.
read point-by-point responses
-
Referee: The central claim attributes the SOTA scores (58.03% and 61.95%) to the graph-based dynamic planning, recursive two-level execution, and rubric-based optimization, yet the experimental evaluation reports only the complete system against external baselines. No ablation studies (full system vs. system minus one mechanism) are described to isolate the contribution of each mechanism. This attribution is load-bearing for the claims in the abstract.
Authors: We agree that the current evaluation reports only end-to-end results and does not isolate the contribution of each mechanism through ablations. This limits the strength of the causal attribution in the abstract and introduction. In the revised manuscript we will add a dedicated ablation section that systematically removes or disables each of the three components (graph-based planning, recursive two-level execution, and rubric-based optimization) while keeping all other elements fixed, and report the resulting scores on both DeepResearch Bench and DeepResearch Bench II. These experiments will be run under the same evaluation protocol to allow direct comparison. revision: yes
Circularity Check
No circularity: engineering system paper with external benchmark measurements
full rationale
The paper is a descriptive technical report on a multi-agent framework introducing three mechanisms (graph-based dynamic planning, recursive two-level execution, rubric-based optimization) and reporting SOTA scores on two external benchmarks (58.03% and 61.95%). No mathematical derivations, equations, parameter fittings, or self-citations appear in the provided text that reduce any claim to its own inputs by construction. Benchmark results are presented as independent external evaluations rather than internally derived quantities. The absence of ablations affects attribution strength but does not constitute circularity in the derivation sense. This is a standard self-contained engineering description against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Yiqun Chen, Lingyong Yan, Weiwei Sun, Xinyu Ma, Yi Zhang, Shuaiqiang Wang, Dawei Yin, Yiming Yang, and Jiaxin Mao. Improving retrieval-augmented generation through multi-agent reinforcement learning.arXiv preprint arXiv:2501.15228, 2025b. Yiqun Chen, Erhan Zhang, Lingyong Yan, Shuaiqiang Wang, Jizhou Huang, Dawei Yin, and Jiaxin Mao. Mao-arag: Multi-agent...
-
[2]
Hanxing Ding, Liang Pang, Zihao Wei, Huawei Shen, and Xueqi Cheng. Retrieve only when it needs: Adaptive retrieval augmentation for hallucination mitigation in large language models.arXiv preprint arXiv:2402.10612,
-
[3]
DeepResearch Bench: A Comprehensive Benchmark for Deep Research Agents
URL https://arxiv. org/abs/2506.11763. Yuwen Du, Rui Ye, Shuo Tang, Xinyu Zhu, Yijun Lu, Yuzhu Cai, and Siheng Chen. Openseeker: Democratizing frontier search agents by fully open-sourcing training data. arXiv preprint arXiv:2603.15594,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Retrieval-Augmented Generation for Large Language Models: A Survey
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yixin Dai, Jiawei Sun, Haofen Wang, Haofen Wang, et al. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997, 2(1):32,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Xinyan Guan, Jiali Zeng, Fandong Meng, Chunlei Xin, Yaojie Lu, Hongyu Lin, Xianpei Han, Le Sun, and Jie Zhou. Deeprag: Thinking to retrieve step by step for large language models.arXiv preprint arXiv:2502.01142,
-
[6]
URLhttps://arxiv.org/abs/2507.16075. Chen Hu, Haikuo Du, Heng Wang, Lin Lin, Mingrui Chen, Peng Liu, Ruihang Miao, Tianchi Yue, Wang You, Wei Ji, Wei Yuan, Wenjin Deng, Xiaojian Yuan, Xiaoyun Zhang, Xiangyu Liu, Xikai Liu, Yanming Xu, Yicheng Cao, Yifei Zhang, Yongyao Wang, Yubo Shu, Yurong Zhang, Yuxiang Zhang, Zheng Gong, Zhichao Chang, Binyan Li, Dan M...
-
[7]
URL https://arxiv.org/abs/2512.20491. 21 Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi-Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave. Atlas: few-shot learning with retrieval augmented language models
-
[8]
Jinhao Jiang, Jiayi Chen, Junyi Li, Ruiyang Ren, Shijie Wang, Wayne Xin Zhao, Yang Song, and Tao Zhang. Rag-star: Enhancing deliberative reasoning with retrieval augmented verification and refinement.arXiv preprint arXiv:2412.12881,
-
[9]
Pengcheng Jiang, Jiacheng Lin, Lang Cao, Runchu Tian, SeongKu Kang, Zifeng Wang, Jimeng Sun, and Jiawei Han. Deepretrieval: Hacking real search engines and retrievers with large language models via reinforcement learning.arXiv preprint arXiv:2503.00223,
-
[10]
Active retrieval augmented generation
Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. Active retrieval augmented generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 7969–7992,
2023
-
[11]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Dense passage retrieval for open-domain question an- swering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question an- swering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing,
2020
-
[13]
Deepresearch bench ii: Diagnosing deep research agents via rubrics from expert report, 2026a
Ruizhe Li, Mingxuan Du, Benfeng Xu, Chiwei Zhu, Xiaorui Wang, and Zhendong Mao. Deepresearch bench ii: Diagnosing deep research agents via rubrics from expert report, 2026a. URLhttps://arxiv.org/abs/2601.08536. Wanli Li, Bince Qu, Bo Pan, Jianyu Zhang, Zheng Liu, Pan Zhang, Wei Chen, and Bo Zhang. Literesearcher: A scalable agentic rl training framework f...
-
[14]
Search-o1: Agentic Search-Enhanced Large Reasoning Models
Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, and Zhicheng Dou. Search-o1: Agentic search-enhanced large reasoning models.arXiv preprint arXiv:2501.05366, 2025a. Xiaoxi Li, Jiajie Jin, Guanting Dong, Hongjin Qian, Yongkang Wu, Ji-Rong Wen, Yutao Zhu, and Zhicheng Dou. Webthinker: Empowering large reasoning models...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
URL https://arxiv.org/abs/ 2511.19399. Zhengliang Shi, Yiqun Chen, Haitao Li, Weiwei Sun, Shiyu Ni, Yougang Lyu, Run-Ze Fan, Bowen Jin, Yixuan Weng, Minjun Zhu, Qiujie Xie, Xinyu Guo, Qu Yang, Jiayi Wu, Jujia Zhao, Xiaqiang Tang, Xinbei Ma, Cunxiang Wang, Jiaxin Mao, Qingyao Ai, Jen-Tse Huang, Wenxuan Wang, Yue Zhang, Yiming Yang, Zhaopeng Tu, and Zhaochu...
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao
URLhttps://arxiv.org/abs/2512.02038. Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. In Advances in Neural Information Processing Systems,
-
[17]
R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning
Huatong Song, Jinhao Jiang, Yingqian Min, Jie Chen, Zhipeng Chen, Wayne Xin Zhao, Lei Fang, and Ji-Rong Wen. R1-searcher: Incentivizing the search capability in llms via reinforcement learning.arXiv preprint arXiv:2503.05592,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Scaling agents via continual pre-training
Liangcai Su, Zhen Zhang, Guangyu Li, Zhuo Chen, Chenxi Wang, Maojia Song, Xinyu Wang, Kuan Li, Jialong Wu, Xuanzhong Chen, et al. Scaling agents via continual pre-training. arXiv preprint arXiv:2509.13310,
-
[19]
Weihang Su, Yichen Tang, Qingyao Ai, Zhijing Wu, and Yiqun Liu. Dragin: dynamic retrieval augmented generation based on the information needs of large language models. arXiv preprint arXiv:2403.10081,
-
[20]
URLhttps://arxiv.org/abs/2511.11793. MiroMind Team, S Bai, L Bing, L Lei, R Li, X Li, X Lin, E Min, L Su, B Wang, et al. Mirothinker-1.7 & h1: Towards heavy-duty research agents via verification.arXiv preprint arXiv:2603.15726, 2026a. Venus Team, Sunhao Dai, Yong Deng, Jinzhen Lin, Yusheng Song, Guoqing Wang, Xiaofeng Wu, Yuqi Zhou, Shuo Yang, Zhenzhe Yin...
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
LiveResearchBench: A Live Benchmark for User-Centric Deep Research in the Wild
URLhttps://arxiv.org/abs/2510.14240. 23 Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Tree of thoughts: Deliberate problem solving with large language models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. InAdvances in Neural Information Processing Systems, 2023a. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoni...
-
[23]
arXiv preprint arXiv:2508.12752 , year=
URLhttps://arxiv.org/abs/2508.12752. Yuxiang Zheng, Dayuan Fu, Xiangkun Hu, Xiaojie Cai, Lyumanshan Ye, Pengrui Lu, and Pengfei Liu. DeepResearcher: Scaling deep research via reinforcement learning in real- world environments. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (eds.),Proceedings of the 2025 Conference on Emp...
-
[24]
Association for Computational Linguistics. ISBN 979-8-89176-332-6. doi: 10.18653/v1/2025.emnlp-main
-
[25]
Yuhang Zhou, Kai Zheng, Qiguang Chen, Mengkang Hu, Qingfeng Sun, Can Xu, and Jingjing Chen
URLhttps://aclanthology.org/2025.emnlp-main.22/. Yuhang Zhou, Kai Zheng, Qiguang Chen, Mengkang Hu, Qingfeng Sun, Can Xu, and Jingjing Chen. Offseeker: Online reinforcement learning is not all you need for deep research agents.arXiv preprint arXiv:2601.18467,
-
[26]
Bin Zhu, Qianghuai Jia, Tian Lan, Junyang Ren, Feng Gu, Feihu Jiang, Longyue Wang, Zhao Xu, and Weihua Luo. Marco deepresearch: Unlocking efficient deep research agents via verification-centric design.arXiv preprint arXiv:2603.28376, 2026a. Chiwei Zhu, Benfeng Xu, Mingxuan Du, Shaohan Wang, Xiaorui Wang, Zhendong Mao, and Yongdong Zhang. Fs-researcher: Te...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.