CAPE: Contrastive Action-conditioned Parallel Encoding for Embodied Planning
Pith reviewed 2026-06-27 21:36 UTC · model grok-4.3
The pith
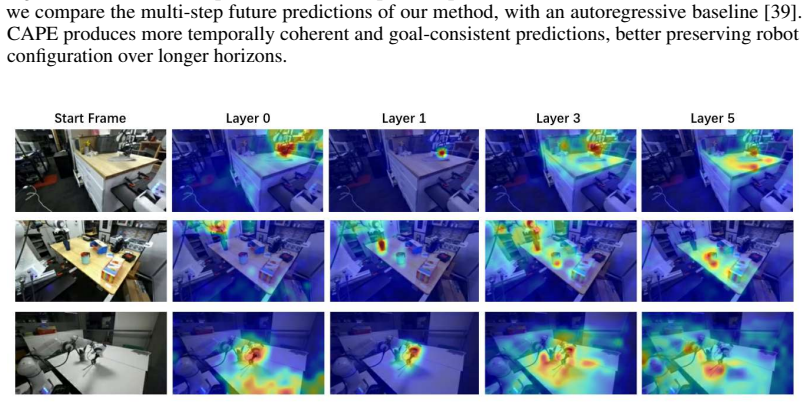
CAPE learns visual dynamics by contrasting future outcomes from different action sequences rather than reconstructing pixels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
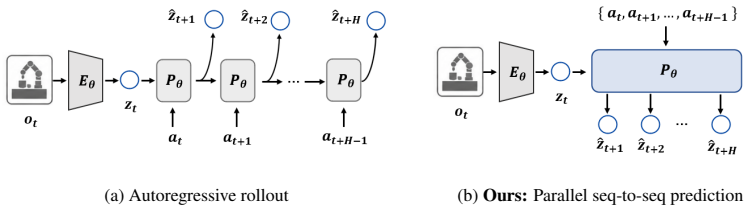
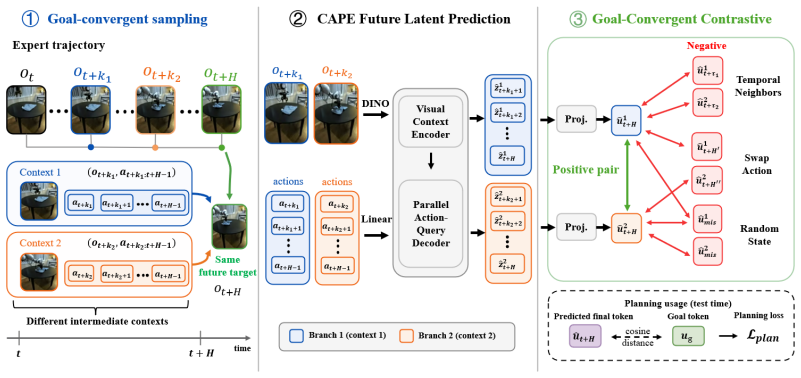
Given an initial observation and candidate action sequence, CAPE decodes the full future latent trajectory in a single forward pass and is trained with a Goal-Convergent Contrastive Objective that aligns predictions corresponding to the same future outcome while separating those corresponding to different outcomes, yielding better future-state retrieval, offline action matching, and closed-loop planning than reconstruction-based baselines on DROID and RoboCasa while reducing planning-time inference cost at long horizons.
What carries the argument
Goal-Convergent Contrastive Objective that aligns same-outcome latent predictions and separates different-outcome predictions, paired with parallel single-pass trajectory decoding.
If this is right
- CAPE substantially outperforms prior baselines on future-state retrieval, offline action matching, and closed-loop planning.
- It reduces planning-time inference cost at long prediction horizons relative to rollout-based alternatives.
- The learned representations support zero-shot transfer from real-world DROID data to RoboCasa.
- Training focuses capacity on action-conditioned changes that determine manipulation outcomes rather than visually salient but planning-irrelevant content.
Where Pith is reading between the lines
- The single-pass decoding property could enable planning loops on hardware with tight latency constraints where iterative rollout models become prohibitive.
- If outcome similarity in latent space is the key driver, the same contrastive pattern might transfer to predictive models in non-robotic domains such as video game agents or traffic forecasting.
- Replacing reconstruction with contrastive objectives could be tested on other embodied benchmarks to measure whether the efficiency gain scales with horizon length.
Load-bearing premise
That a contrastive loss based on outcome similarity will produce latent trajectories whose structure improves downstream planning more than reconstruction objectives do.
What would settle it
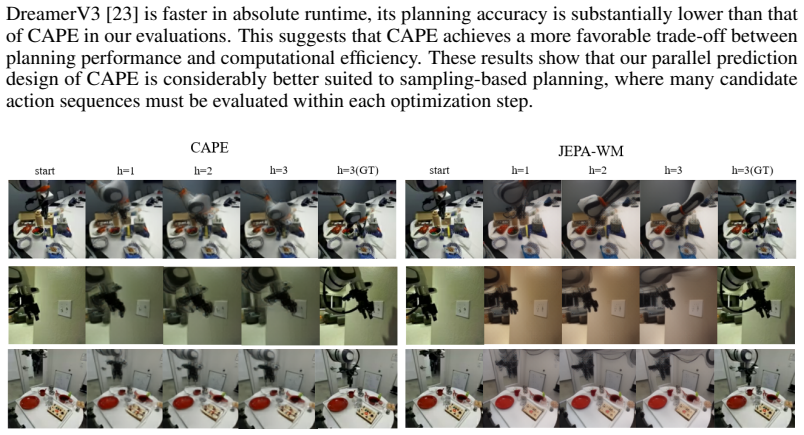
An experiment on the DROID dataset in which a reconstruction-based visual dynamics model achieves equal or higher success rates on closed-loop planning tasks than CAPE at matched compute budgets would falsify the central performance claim.
Figures


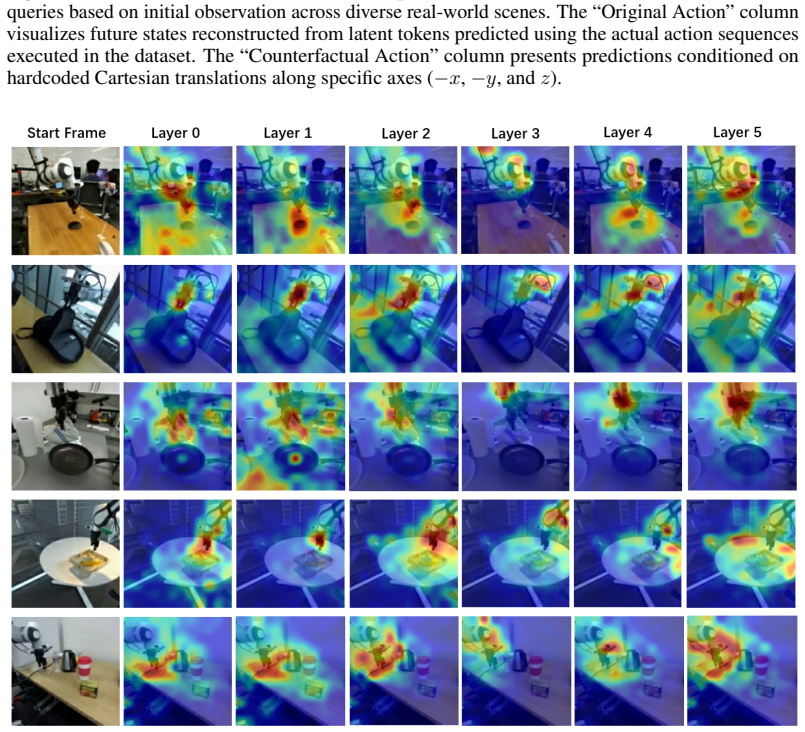
read the original abstract
Embodied agents need to predict the future consequences of candidate actions in order to plan effectively before execution. Existing visual dynamics models learn by reconstructing future visual states or rolling out dense latent representations, which spreads learning capacity across visually salient but planning-irrelevant content rather than the action-conditioned changes that drive manipulation outcomes. We propose CAPE, a Contrastive Action-conditioned Parallel Encoding framework that learns visual dynamics by distinguishing the future outcomes induced by different action sequences. Given an initial observation and a candidate action sequence, CAPE decodes the full future latent trajectory in a single forward pass and is trained with a Goal-Convergent Contrastive Objective that aligns predictions corresponding to the same future outcome while separating those corresponding to different outcomes. On real-world DROID and zero-shot transfer to RoboCasa, CAPE substantially outperforms prior baselines on future-state retrieval, offline action matching, and closed-loop planning, while notably reducing planning-time inference cost at long prediction horizons.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CAPE, a Contrastive Action-conditioned Parallel Encoding framework for embodied planning. It learns visual dynamics models by decoding full future latent trajectories in a single forward pass from an initial observation and candidate action sequence, trained via a Goal-Convergent Contrastive Objective that aligns same-outcome predictions and separates different ones. The central claim is that this focuses capacity on action-conditioned changes relevant to manipulation outcomes (unlike reconstruction-based or dense rollout models) and yields substantial gains over prior baselines on future-state retrieval, offline action matching, and closed-loop planning on real-world DROID data with zero-shot transfer to RoboCasa, while reducing planning-time inference cost at long horizons.
Significance. If the empirical results hold and the contrastive objective is shown to drive the gains, the approach could meaningfully advance sample-efficient and computationally lighter planning in robotics by producing latent spaces whose similarity structure better supports retrieval and action selection without full visual reconstruction.
major comments (2)
- [Experiments] Experiments section: the manuscript provides no ablation that holds the parallel single-pass encoder/decoder architecture fixed while swapping only the training objective (Goal-Convergent Contrastive Objective versus a reconstruction baseline). This is load-bearing for the central claim, as the abstract and introduction attribute performance improvements on DROID and RoboCasa specifically to the contrastive signal producing better latent trajectory similarity structure.
- [§4 (Method) and Experiments] §4 (Method) and Experiments: without the isolation ablation, observed gains on future-state retrieval, action matching, and closed-loop planning could arise from differences in model capacity, parallel decoding mechanics, or other unablated factors rather than the contrastive objective itself.
minor comments (2)
- [Abstract] Abstract: quantitative results, baseline names, and exact metrics are referenced but not supplied, making it difficult to assess the magnitude of the claimed improvements without the full experimental tables.
- [Method] Notation for the Goal-Convergent Contrastive Objective could be clarified with an explicit equation showing the positive/negative pair construction and temperature parameter.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We agree that isolating the contribution of the Goal-Convergent Contrastive Objective while holding the parallel single-pass architecture fixed is necessary to support the central claims, and we will add this ablation in the revised manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the manuscript provides no ablation that holds the parallel single-pass encoder/decoder architecture fixed while swapping only the training objective (Goal-Convergent Contrastive Objective versus a reconstruction baseline). This is load-bearing for the central claim, as the abstract and introduction attribute performance improvements on DROID and RoboCasa specifically to the contrastive signal producing better latent trajectory similarity structure.
Authors: We agree that the requested ablation is load-bearing. The current comparisons are against prior baselines that differ in architecture, rollout style, and objective simultaneously. In the revision we will add an ablation that trains the identical CAPE parallel encoder/decoder architecture once with the Goal-Convergent Contrastive Objective and once with a matched-capacity reconstruction objective, reporting retrieval, matching, and planning metrics on both DROID and RoboCasa to isolate the objective's effect. revision: yes
-
Referee: [§4 (Method) and Experiments] §4 (Method) and Experiments: without the isolation ablation, observed gains on future-state retrieval, action matching, and closed-loop planning could arise from differences in model capacity, parallel decoding mechanics, or other unablated factors rather than the contrastive objective itself.
Authors: We acknowledge that alternative explanations remain possible without the isolation experiment. The new ablation will keep model capacity, parallel decoding mechanics, and all other architectural choices identical while varying only the training objective, thereby directly testing whether the contrastive signal (rather than capacity or parallel decoding) drives the observed improvements in latent similarity structure and downstream tasks. revision: yes
Circularity Check
No circularity: new contrastive objective presented without reduction to fitted inputs or self-citation chains
full rationale
The paper introduces CAPE as a new framework using a Goal-Convergent Contrastive Objective for learning visual dynamics via outcome distinction rather than reconstruction. No equations, derivations, or parameter-fitting steps are shown in the provided abstract or description that would reduce any claimed prediction or result to its own inputs by construction. The method is framed as an architectural and objective-level proposal with empirical claims on DROID and RoboCasa, without self-definitional loops, fitted-input predictions, or load-bearing self-citations that collapse the central claim. This is the common case of a self-contained proposal whose validity rests on external benchmarks rather than internal equivalence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chris- tensen, Hao Su, Jiajun Wu, and Yunzhu Li
Bo Ai, Stephen Tian, Haochen Shi, Yixuan Wang, Tobias Pfaff, Cheston Tan, Henrik I. Chris- tensen, Hao Su, Jiajun Wu, and Yunzhu Li. A review of learning-based dynamics models for robotic manipulation.Science Robotics, 10(106):eadt1497, 2025
2025
-
[2]
Devon Hjelm
Ankesh Anand, Evan Racah, Sherjil Ozair, Yoshua Bengio, Marc-Alexandre Côté, and R. Devon Hjelm. Unsupervised state representation learning in Atari. InAdvances in Neural Information Processing Systems, volume 32, pages 8766–8779, 2019
2019
-
[3]
Self-supervised learning from images with a joint- embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint- embedding predictive architecture. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15619–15629, 2023
2023
-
[4]
Mido Assran et al. V-JEPA 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025
Pith/arXiv arXiv 2025
-
[5]
VICReg: Variance-invariance-covariance regular- ization for self-supervised learning
Adrien Bardes, Jean Ponce, and Yann LeCun. VICReg: Variance-invariance-covariance regular- ization for self-supervised learning. InInternational Conference on Learning Representations, 2022
2022
-
[6]
V-JEPA: Latent video prediction for visual representation learning
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mido Assran, and Nicolas Ballas. V-JEPA: Latent video prediction for visual representation learning. InInternational Conference on Learning Representations, 2024
2024
-
[7]
Genie: Generative interactive environments
Jake Bruce, Michael Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 4603–4623. PMLR, 2024
2024
-
[8]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InProceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 1597–1607. PMLR, 2020
2020
-
[9]
RoboNet: Large-scale multi-robot learning
Sudeep Dasari, Frederik Ebert, Stephen Tian, Suraj Nair, Bernadette Bucher, Karl Schmeckpeper, Siddharth Singh, Sergey Levine, and Chelsea Finn. RoboNet: Large-scale multi-robot learning. arXiv preprint arXiv:1910.11215, 2019
Pith/arXiv arXiv 1910
-
[10]
Lee, and Sergey Levine
Frederik Ebert, Chelsea Finn, Alex X. Lee, and Sergey Levine. Self-supervised visual planning with temporal skip connections. InProceedings of the 1st Annual Conference on Robot Learning, volume 78 ofProceedings of Machine Learning Research, pages 344–356. PMLR, 2017
2017
-
[11]
Frederik Ebert, Chelsea Finn, Sudeep Dasari, Annie Xie, Alex Lee, and Sergey Levine. Visual foresight: Model-based deep reinforcement learning for vision-based robotic control.arXiv preprint arXiv:1812.00568, 2018
Pith/arXiv arXiv 2018
-
[12]
FOCUS: Object-centric world models for robotic manipulation.Frontiers in Neurorobotics, 19:1585386, 2025
Stefano Ferraro, Pietro Mazzaglia, Tim Verbelen, and Bart Dhoedt. FOCUS: Object-centric world models for robotic manipulation.Frontiers in Neurorobotics, 19:1585386, 2025
2025
-
[13]
Deep visual foresight for planning robot motion
Chelsea Finn and Sergey Levine. Deep visual foresight for planning robot motion. InIEEE International Conference on Robotics and Automation, pages 2786–2793, 2017
2017
-
[14]
Unsupervised learning for physical in- teraction through video prediction
Chelsea Finn, Ian Goodfellow, and Sergey Levine. Unsupervised learning for physical in- teraction through video prediction. InAdvances in Neural Information Processing Systems, volume 29, pages 64–72, 2016
2016
-
[15]
Learning visual predictive models of physics for playing billiards
Katerina Fragkiadaki, Pulkit Agrawal, Sergey Levine, and Jitendra Malik. Learning visual predictive models of physics for playing billiards. InInternational Conference on Learning Representations, 2016. 10
2016
-
[16]
Garcia, David M
Carlos E. Garcia, David M. Prett, and Manfred Morari. Model predictive control: Theory and practice—a survey.Automatica, 25(3):335–348, 1989
1989
-
[17]
Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Daniel Guo, Mohammad Ghesh- laghi Azar, Bilal Piot, Koray Kavukcuoglu, Rémi Munos, and Michal Valko
Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre H. Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Daniel Guo, Mohammad Ghesh- laghi Azar, Bilal Piot, Koray Kavukcuoglu, Rémi Munos, and Michal Valko. Bootstrap your own latent: A new approach to self-supervised learning. InAdvances in Neural Information ...
2020
-
[18]
Jun Guo, Xiaojian Ma, Yikai Wang, Min Yang, Huaping Liu, and Qing Li. FlowDreamer: An RGB-D world model with flow-based motion representations for robot manipulation.arXiv preprint arXiv:2505.10075, 2025
arXiv 2025
-
[19]
Recurrent world models facilitate policy evolution
David Ha and Jürgen Schmidhuber. Recurrent world models facilitate policy evolution. In Advances in Neural Information Processing Systems, volume 31, pages 2455–2467, 2018
2018
-
[20]
Learning latent dynamics for planning from pixels
Danijar Hafner, Timothy Lillicrap, Ian Fischer, Ruben Villegas, David Ha, Honglak Lee, and James Davidson. Learning latent dynamics for planning from pixels. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 2555–2565. PMLR, 2019
2019
-
[21]
Lillicrap, Jimmy Ba, and Mohammad Norouzi
Danijar Hafner, Timothy P. Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to con- trol: Learning behaviors by latent imagination. InInternational Conference on Learning Representations, 2020
2020
-
[22]
Lillicrap, Mohammad Norouzi, and Jimmy Ba
Danijar Hafner, Timothy P. Lillicrap, Mohammad Norouzi, and Jimmy Ba. Mastering Atari with discrete world models. InInternational Conference on Learning Representations, 2021
2021
-
[23]
Mastering diverse control tasks through world models.Nature, 640:647–653, 2025
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse control tasks through world models.Nature, 640:647–653, 2025
2025
-
[24]
Momentum contrast for unsupervised visual representation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9729–9738, 2020
2020
-
[25]
Campbell, Krzysztof Czechowski, Dumitru Erhan, Chelsea Finn, Piotr Kozakowski, Sergey Levine, et al
Lukasz Kaiser, Mohammad Babaeizadeh, Piotr Milos, Bła ˙zej Osi ´nski, Roy H. Campbell, Krzysztof Czechowski, Dumitru Erhan, Chelsea Finn, Piotr Kozakowski, Sergey Levine, et al. Model-based reinforcement learning for Atari. InInternational Conference on Learning Representations, 2020
2020
-
[26]
DROID: A large-scale in-the-wild robot manipulation dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, et al. DROID: A large-scale in-the-wild robot manipulation dataset. InRobotics: Science and Systems, 2024
2024
-
[27]
Contrastive learning of structured world models
Thomas Kipf, Elise van der Pol, and Max Welling. Contrastive learning of structured world models. InInternational Conference on Learning Representations, 2020
2020
-
[28]
CURL: Contrastive unsupervised rep- resentations for reinforcement learning
Michael Laskin, Aravind Srinivas, and Pieter Abbeel. CURL: Contrastive unsupervised rep- resentations for reinforcement learning. InProceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 5639–5650. PMLR, 2020
2020
-
[29]
A comprehensive survey on world models for embodied AI.arXiv preprint arXiv:2510.16732, 2025
Xinqing Li, Xin He, Le Zhang, and Yun Liu. A comprehensive survey on world models for embodied AI.arXiv preprint arXiv:2510.16732, 2025
arXiv 2025
-
[30]
Aligning cyber space with physical world: A comprehensive survey on embodied AI
Yang Liu, Weixing Chen, Yongjie Bai, Xiaodan Liang, Guanbin Li, Wen Gao, and Liang Lin. Aligning cyber space with physical world: A comprehensive survey on embodied AI. IEEE/ASME Transactions on Mechatronics, 30(6):7253–7274, 2025
2025
-
[31]
Transformers are sample-efficient world models
Vincent Micheli, Eloi Alonso, and François Fleuret. Transformers are sample-efficient world models. InInternational Conference on Learning Representations, 2023
2023
-
[32]
RoboCasa: Large-scale simulation of everyday tasks for generalist robots
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Mandlekar, and Yuke Zhu. RoboCasa: Large-scale simulation of everyday tasks for generalist robots. InRobotics: Science and Systems, 2024. 11
2024
-
[33]
Lewis, and Satinder Singh
Junhyuk Oh, Xiaoxiao Guo, Honglak Lee, Richard L. Lewis, and Satinder Singh. Action- conditional video prediction using deep networks in Atari games. InAdvances in Neural Information Processing Systems, volume 28, pages 2863–2871, 2015
2015
-
[34]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael G. Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jégou, Julien Mairal, Patric...
2024
-
[35]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4172–4182, 2023
2023
-
[36]
Devon Hjelm, Aaron Courville, and Philip Bachman
Max Schwarzer, Ankesh Anand, Rishab Goel, R. Devon Hjelm, Aaron Courville, and Philip Bachman. Data-efficient reinforcement learning with self-predictive representations. InInterna- tional Conference on Learning Representations, 2021
2021
-
[37]
Masked world models for visual control
Younggyo Seo, Danijar Hafner, Hao Liu, Fangchen Liu, Stephen James, Kimin Lee, and Pieter Abbeel. Masked world models for visual control. InProceedings of the 6th Conference on Robot Learning, volume 205 ofProceedings of Machine Learning Research, pages 1332–1344. PMLR, 2023
2023
-
[38]
Oriane Siméoni, Huy V . V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timothée Darcet, Théo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, Julie...
Pith/arXiv arXiv 2025
-
[39]
Basile Terver, Tsung-Yen Yang, Jean Ponce, Adrien Bardes, and Yann LeCun. What drives success in physical planning with joint-embedding predictive world models?arXiv preprint arXiv:2512.24497, 2025
Pith/arXiv arXiv 2025
-
[40]
Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018
Aäron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018
Pith/arXiv arXiv 2018
-
[41]
Rehg, Byron Boots, and Evangelos A
Grady Williams, Nolan Wagener, Brian Goldfain, Paul Drews, James M. Rehg, Byron Boots, and Evangelos A. Theodorou. Information theoretic MPC for model-based reinforcement learning. InIEEE International Conference on Robotics and Automation, pages 1714–1721, 2017
2017
-
[42]
STORM: Efficient stochastic transformer-based world models for reinforcement learning
Weipu Zhang, Gang Wang, Jian Sun, Yetian Yuan, and Gao Huang. STORM: Efficient stochastic transformer-based world models for reinforcement learning. InAdvances in Neural Information Processing Systems, volume 36, pages 27147–27166, 2023
2023
-
[43]
Weipu Zhang, Adam Jelley, Trevor McInroe, and Amos Storkey. Objects matter: Object-centric world models improve reinforcement learning in visually complex environments.arXiv preprint arXiv:2501.16443, 2025
arXiv 2025
-
[44]
TACO: Temporal latent action-driven contrastive loss for visual reinforce- ment learning
Ruijie Zheng, Xiyao Wang, Yanchao Sun, Shuang Ma, Jieyu Zhao, Huazhe Xu, Hal Daumé III, and Furong Huang. TACO: Temporal latent action-driven contrastive loss for visual reinforce- ment learning. InAdvances in Neural Information Processing Systems, volume 36, pages 48203–48225, 2023
2023
-
[45]
Premier-TACO is a few-shot policy learner: Pretraining multitask representation via temporal action-driven contrastive loss
Ruijie Zheng, Yongyuan Liang, Xiyao Wang, Shuang Ma, Hal Daumé III, Huazhe Xu, John Langford, Praveen Palanisamy, Kalyan Shankar Basu, and Furong Huang. Premier-TACO is a few-shot policy learner: Pretraining multitask representation via temporal action-driven contrastive loss. InProceedings of the 41st International Conference on Machine Learning, volume ...
2024
-
[46]
Gaoyue Zhou, Hengkai Pan, Yann LeCun, and Lerrel Pinto. DINO-WM: World models on pre-trained visual features enable zero-shot planning.arXiv preprint arXiv:2411.04983, 2024. 12 Appendix The supplementary material is organized as follows. Sec. A describes the implementation details of the CAPE architecture and training hyperparameters; Sec. B specifies the...
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.