CultureScore: Evaluating Cultural Faithfulness in Video Generation Models
Pith reviewed 2026-06-27 22:26 UTC · model grok-4.3
The pith
No current video generation model achieves culturally faithful outputs, topping out at 56.8 percent on CultureScore.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
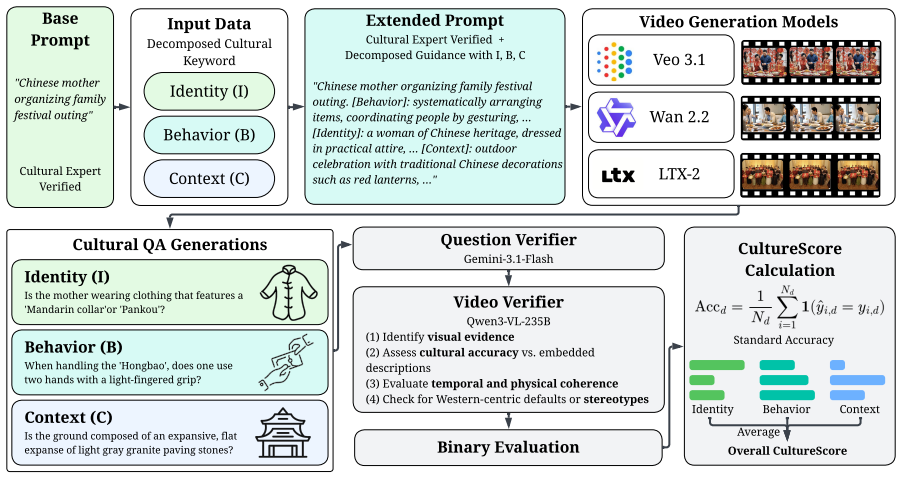
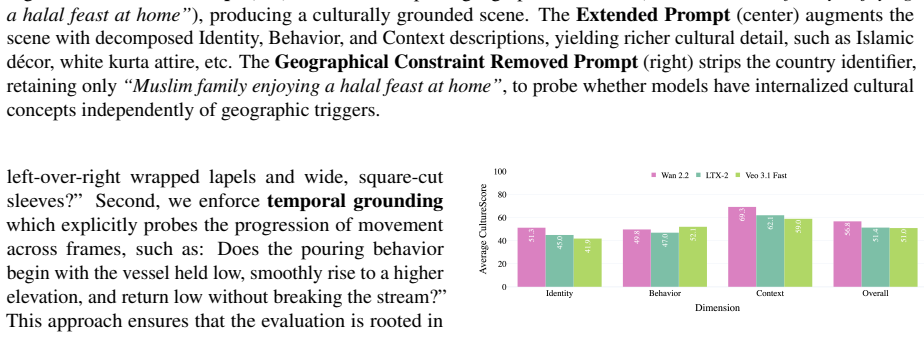
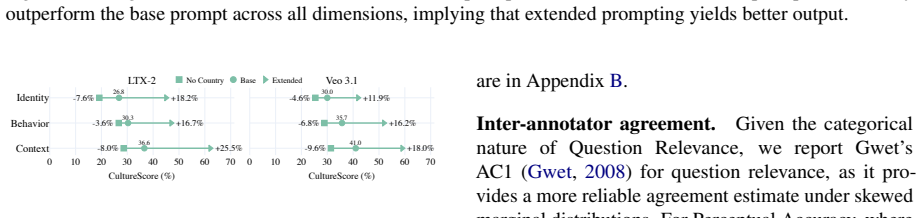
CultureScore decomposes cultural faithfulness into Identity, Context, and Behavior and applies the framework to 6,174 videos generated by three state-of-the-art models across an evaluation suite of ten countries, revealing that the highest overall score is 56.8 percent while Behavior remains below 52.1 percent for every model; human preference rankings match CultureScore directionally yet invert relative to VideoScore rankings.
What carries the argument
CultureScore, the compositional framework that evaluates cultural faithfulness along the three dimensions of Identity, Context, and Behavior using a fixed 10-country prompt suite.
If this is right
- Video generation pipelines must improve their handling of normative gestures and social interactions to raise CultureScore.
- Benchmarks for these models should combine cultural faithfulness measures with visual quality scores rather than relying on the latter alone.
- Human preference data already indicate that cultural accuracy affects perceived quality more than current visual metrics capture.
Where Pith is reading between the lines
- The low Behavior scores may trace back to under-representation of diverse interaction patterns in training data.
- Expanding the country set or adding new dimensions could reveal whether the current gaps generalize or are specific to the tested suite.
Load-bearing premise
The three dimensions of Identity, Context, and Behavior together with the 10-country prompt set give a valid and unbiased measure of cultural faithfulness.
What would settle it
A new model that scores above 70 percent overall on CultureScore, or a human study in which annotators consistently prefer the highest-VideoScore model over the highest-CultureScore model, would falsify the central claims.
Figures






read the original abstract
As video generation models like Veo 3.1 and LTX-2 advance, their ability to accurately represent diverse global cultures remains a critical yet understudied frontier. Current metrics, such as VideoScore, only measure visual quality but offer no mechanism for assessing cultural faithfulness. Consequently, a model that replaces a Namaste with a handshake receives the same score as one that generates the gesture correctly. We propose CultureScore, a compositional evaluation framework that decomposes cultural faithfulness into three granular dimensions: Identity (who is represented), Context (culturally localized background), and Behavior (normative gestures and interactions). We operationalize this framework through an evaluation suite spanning 10 countries, yielding 6,174 generated videos across three state-of-the-art models. Our evaluation reveals that no current model achieves culturally faithful video generation: the best-performing model reaches only 56.8\% overall CultureScore, with Behavior the most challenging dimension, which remains below 52.1\% across all models. Furthermore, human preference rankings align directionally with CultureScore but are inverted relative to VideoScore; the highest-scoring model on visual quality was ranked last by annotators, underscoring that cultural faithfulness is an essential criterion for equitable video generation. Data and code are available at https://huggingface.co/datasets/ankurani/CultureScore.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CultureScore, a compositional framework that decomposes cultural faithfulness in video generation into three dimensions (Identity, Context, Behavior) and applies it to an evaluation suite of prompts spanning 10 countries. It generates 6,174 videos from three state-of-the-art models, reports that the best model reaches only 56.8% overall CultureScore (with Behavior below 52.1% for all models), and shows that CultureScore rankings align with human preferences while inverting those from VideoScore.
Significance. If the evaluation suite and annotation protocol are shown to be representative and unbiased, the work identifies a clear gap in current video models' ability to handle cultural content and demonstrates that visual-quality metrics alone are insufficient. The public release of data and code strengthens the contribution by enabling direct replication and extension.
major comments (3)
- [§3.2] §3.2 (Evaluation Suite): The paper does not detail the sampling procedure used to construct the 6,174 prompts across the 10 countries (e.g., stratification by topic, frequency of cultural elements, or exclusion criteria), so it is impossible to determine whether the low scores reflect genuine model shortcomings or selection bias in the prompt set.
- [§4.2] §4.2 (Annotation Protocol): No information is provided on annotator recruitment, cultural origin, or expertise matching the 10 countries; without this, scores on Behavior and Context may simply capture Western annotator priors rather than culturally grounded judgments.
- [§5] §5 (Results): Inter-annotator agreement statistics (e.g., Fleiss' kappa per dimension) and any calibration or bias-mitigation procedures are absent, so the headline figures (56.8% overall, <52.1% Behavior) cannot be assessed for reliability or used to support the claim that no model achieves cultural faithfulness.
minor comments (2)
- [Abstract] The abstract states that human preference rankings align directionally with CultureScore; the corresponding table or figure should explicitly report the rank correlation coefficient.
- [§3.1] Notation for the three dimensions is introduced without a concise formal definition (e.g., a short equation or decision tree) that annotators could reference.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on improving the transparency and rigor of our evaluation methodology. We address each major comment below and commit to revisions that enhance the manuscript without altering our core findings.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Evaluation Suite): The paper does not detail the sampling procedure used to construct the 6,174 prompts across the 10 countries (e.g., stratification by topic, frequency of cultural elements, or exclusion criteria), so it is impossible to determine whether the low scores reflect genuine model shortcomings or selection bias in the prompt set.
Authors: We agree that explicit details on prompt construction are required to assess representativeness. In the revised manuscript, we will expand §3.2 with a full description of the sampling procedure, including stratification by country and topic, selection of cultural elements, and exclusion criteria. This addition will directly address concerns about potential selection bias. revision: yes
-
Referee: [§4.2] §4.2 (Annotation Protocol): No information is provided on annotator recruitment, cultural origin, or expertise matching the 10 countries; without this, scores on Behavior and Context may simply capture Western annotator priors rather than culturally grounded judgments.
Authors: We acknowledge that annotator background information is essential for validating cultural judgments. We will revise §4.2 to include details on annotator recruitment, cultural origins, and relevant expertise for the 10 countries, along with any procedures used to ensure alignment with local cultural contexts. This will clarify that judgments were not solely based on external priors. revision: yes
-
Referee: [§5] §5 (Results): Inter-annotator agreement statistics (e.g., Fleiss' kappa per dimension) and any calibration or bias-mitigation procedures are absent, so the headline figures (56.8% overall, <52.1% Behavior) cannot be assessed for reliability or used to support the claim that no model achieves cultural faithfulness.
Authors: We agree that inter-annotator agreement and bias mitigation details are necessary to support the reliability of the reported scores. In the revised manuscript, we will report Fleiss' kappa (or equivalent) per dimension in §5, along with descriptions of calibration procedures and bias-mitigation steps. These additions will allow readers to evaluate the robustness of the 56.8% and <52.1% figures. revision: yes
Circularity Check
No circularity: CultureScore is an independently defined metric applied to external model outputs.
full rationale
The paper defines CultureScore as a new compositional framework with three dimensions (Identity, Context, Behavior) and an evaluation suite of 6,174 videos from three external models across 10 countries. No equations, derivations, fitted parameters, or predictions appear. The central results (e.g., max 56.8% CultureScore) are direct outputs of applying the defined metric to model generations, with no reduction to self-citation chains or input-by-construction. This matches the reader's assessment of score 2.0 and contains no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8734–8743
Grid diffusion models for text-to-video gener- ation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8734–8743. Sina Malakouti, Boqing Gong, and Adriana Kovashka
-
[2]
Scalable Diffusion Models with Transformers
Culture in action: Evaluating text-to-image models through social activities. InThe Fourteenth International Conference on Learning Representa- tions. Shravan Nayak, Mehar Bhatia, Xiaofeng Zhang, Verena Rieser, Lisa Anne Hendricks, Sjoerd Van Steenkiste, Yash Goyal, Karolina Stanczak, and Aishwarya Agrawal. 2025. CulturalFrames: Assessing cultural expecta...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Towards Accurate Generative Models of Video: A New Metric & Challenges
VF-eval: Evaluating multimodal LLMs for generating feedback on AIGC videos. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 21126–21146, Vienna, Austria. Association for Computational Linguistics. Charles Spearman. 1961. The proof and measurement of association between two things. Th...
work page internal anchor Pith review Pith/arXiv arXiv 1961
-
[4]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan: Open and advanced large-scale video generative models.Preprint, arXiv:2503.20314. Xiang Wang, Shiwei Zhang, Hangjie Yuan, Zhiwu Qing, Biao Gong, Yingya Zhang, Yujun Shen, Changxin Gao, and Nong Sang. 2024. A recipe for scaling up text-to-video generation with text-free videos. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Yes/No Format:Every question must be structured so that a ”Yes” indicates cultural faithfulness and a ”No” indicates a failure or cultural inaccuracy
-
[6]
Do not assume the evaluating model has implicit cultural knowledge
Embedded Visual Descriptions:Embed precise visual, physical, or spatial descriptions directly into the question. Do not assume the evaluating model has implicit cultural knowledge. (e.g., Instead of ”Is the person wearing a traditional Kimono?”, ask ”Is the person wearing a traditional Kimono, characterized by left-over-right wrapped lapels and wide, squa...
-
[7]
(e.g., ”Does the pouring Behavior begin with the vessel held low, smoothly rise to a higher elevation, and return low without breaking the stream?”)
Temporal Grounding (Crucial for Behaviors):Questions MUST explicitly probe the sequence, duration, physics, or progression of the movement across frames. (e.g., ”Does the pouring Behavior begin with the vessel held low, smoothly rise to a higher elevation, and return low without breaking the stream?”)
-
[8]
grounded
Explicit vs. Implicit:Generate questions for explicitly requested elements, AND mandatory implicit elements required for cultural authenticity. Actively avoid Western-centric stereotypes (e.g., implicitly checking that a traditional daily Context avoids hyper-exoticized or religious backdrops unless the Context or the prompt requires them). 5.Weighting St...
-
[9]
Identify the visual evidence:Describe exactly what you observe in the video frames—specific Identitys, clothing details, spatial arrangements, architectural elements, lighting, and colors
-
[10]
Do not rely on implicit cultural knowledge—only evaluate what the question explicitly describes
Assess cultural accuracy:Compare your observations against the culturally specific visual descriptions embedded in the question. Do not rely on implicit cultural knowledge—only evaluate what the question explicitly describes
-
[11]
Note whether Behaviors follow the temporal grounding specified in the question
Evaluate temporal and physical coherence (for Behavior questions):Examine the sequence, duration, physics, and progression of movements across frames. Note whether Behaviors follow the temporal grounding specified in the question
-
[12]
culturally unique
Check for stereotyping or inauthenticity:Flag if the video substitutes Western-centric defaults, hyper-exoticized elements, or generic representations in place of the specific cultural markers described in the question. After your reasoning, provide the final answer as either Yes or No. ”Yes” means the video is culturally faithful for what the question as...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.