QBugLM: An Agentic Benchmarking Framework for LLM-based Quantum Software Debugging
Pith reviewed 2026-06-27 21:18 UTC · model grok-4.3
The pith
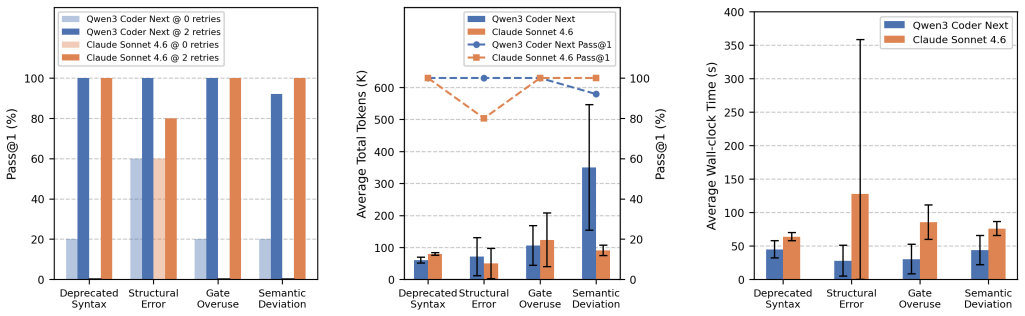
Iterative feedback raises LLM success on quantum software debugging from under 25% to over 80%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
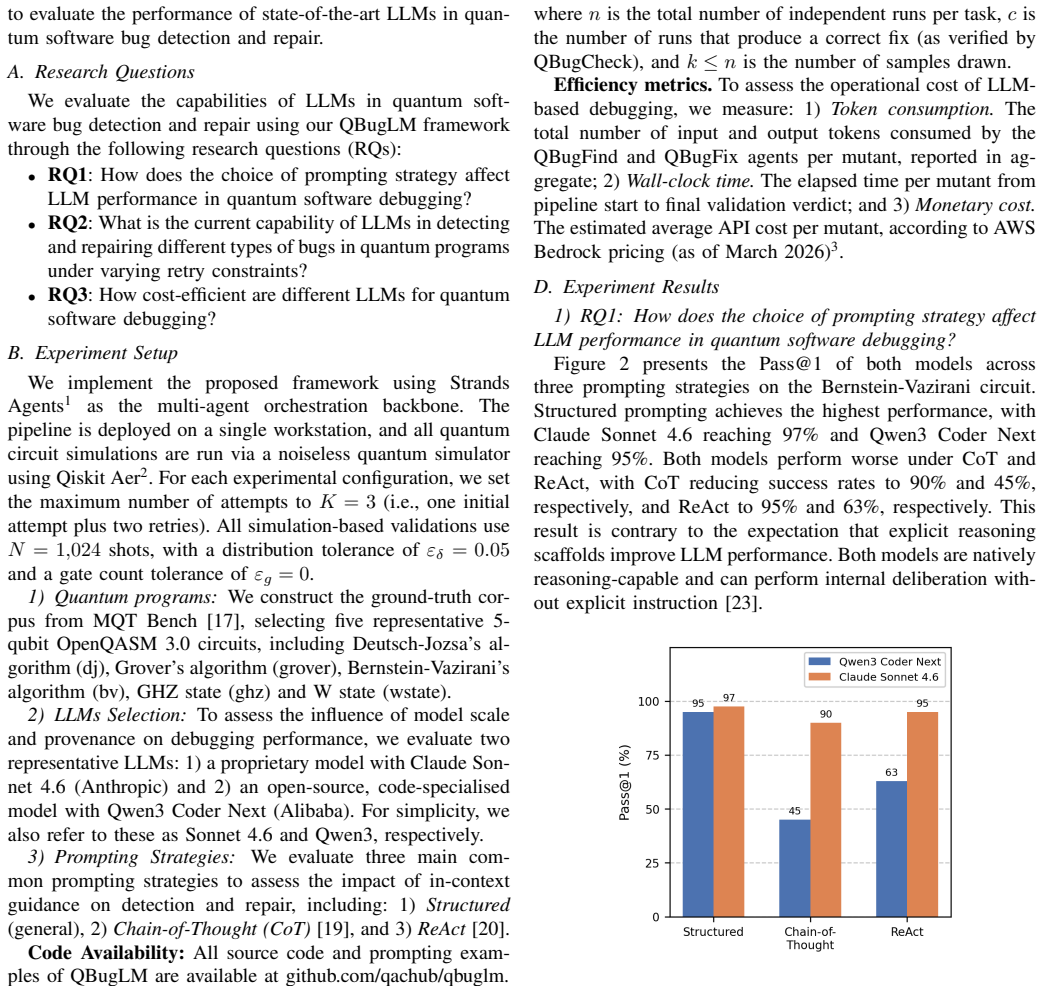
QBugLM automates bug injection, LLM-driven detection and repair, and simulation validation for framework-agnostic OpenQASM 3.0 code. Experiments with Claude 4.6 Sonnet and Qwen3 Coder Next show that a single retry with feedback raises Pass@1 from below 25% to above 80%, and that structured prompting can exceed the performance of Chain-of-Thought and ReAct under fixed-resource constraints.
What carries the argument
QBugLM, the multi-agent framework that sequences taxonomy-driven bug injection, LLM detection and repair, and simulation-based validation.
If this is right
- Iterative feedback loops are required for LLMs to reach high success rates on quantum debugging tasks.
- Simpler structured prompting can replace more elaborate reasoning strategies for capable models under fixed compute limits.
- The framework enables systematic comparison of LLMs across bug categories and quantum program sizes.
- The pipeline supports development of automated repair tools for quantum software.
Where Pith is reading between the lines
- Quantum debugging may favor repeated interaction over single-shot advanced reasoning more than classical software debugging does.
- The same framework could be applied to test whether current LLMs handle errors that arise only after transpilation or hardware mapping.
- Extending the taxonomy to include errors from specific quantum SDKs would allow targeted benchmarking of library-specific bugs.
Load-bearing premise
The taxonomy-driven bug injection and simulation-based validation produce bugs and correctness checks that match the errors found in real quantum software.
What would settle it
A direct comparison of the bug types and frequencies generated by the framework against a corpus of real production quantum program errors would falsify the representativeness claim if the distributions diverge substantially.
Figures

read the original abstract
Quantum software bugs often yield silent, incorrect outputs rather than explicit errors, making them particularly difficult to detect and repair with conventional techniques. Although large language models (LLMs) have shown strong performance on classical software engineering tasks, their ability to debug quantum code remains largely unexplored. To bridge this gap, we propose QBugLM, a multi-agent framework that automates the quantum software debugging pipeline, from taxonomy-driven bug injection to LLM-based detection and repair, and finally to simulation-based validation, for framework-agnostic OpenQASM 3.0 programs. We further conduct a comprehensive case study using QBugLM to benchmark two LLMs, Claude 4.6 Sonnet and Qwen3 Coder Next, across different prompting strategies, bug categories, and quantum programs. Our results show that iterative feedback is critical, as a single retry raises Pass@1 from below 25% to above 80%. Moreover, simpler structured prompting can even outperform Chain-of-Thought and ReAct for reasoning-capable models under fixed-resource constraints. Our work takes initial steps toward benchmarking LLM capabilities for debugging quantum programs and offers practical insights to support future efforts in automated quantum software repair.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces QBugLM, a multi-agent framework for benchmarking LLM-based debugging of quantum software. It automates taxonomy-driven bug injection into OpenQASM 3.0 programs, LLM detection/repair via different prompting strategies (including iterative feedback), and simulation-based validation. A case study with Claude 4.6 Sonnet and Qwen3 Coder Next reports that a single retry raises Pass@1 from below 25% to above 80%, and that simpler structured prompting can outperform Chain-of-Thought and ReAct under fixed resources.
Significance. If the empirical claims hold, the work provides the first systematic agentic benchmark for LLM quantum debugging and useful practical guidance on iteration and prompting. The framework design itself is a contribution for reproducible evaluation in this emerging area. Credit is given for the focus on framework-agnostic OpenQASM 3.0 and the multi-agent structure.
major comments (2)
- [Bug injection / taxonomy] Bug injection section: the taxonomy-driven injection and simulation oracles are not validated or compared against empirical bug distributions from real quantum codebases (Qiskit, PennyLane, etc.). This is load-bearing for the central claim because the headline Pass@1 gains (single retry: <25% to >80%) are measured exclusively on the synthetic bugs; without representativeness evidence, the prompting-strategy conclusions risk being artifacts of the chosen taxonomy.
- [Case study / experimental results] Case study / results: the abstract and results report specific Pass@1 thresholds and comparisons across models and strategies, yet no details are provided on the number of programs tested, total bug instances, bug-category balance, definition of Pass@1, or statistical significance. This directly affects soundness of the empirical claims.
minor comments (2)
- [Abstract] Abstract: the phrase 'comprehensive case study' is used without any scale indicators; adding even high-level counts would improve clarity.
- [Terminology] Terminology: 'Pass@1' should be defined explicitly on first use in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help improve the clarity and rigor of our work. We address each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: [Bug injection / taxonomy] Bug injection section: the taxonomy-driven injection and simulation oracles are not validated or compared against empirical bug distributions from real quantum codebases (Qiskit, PennyLane, etc.). This is load-bearing for the central claim because the headline Pass@1 gains (single retry: <25% to >80%) are measured exclusively on the synthetic bugs; without representativeness evidence, the prompting-strategy conclusions risk being artifacts of the chosen taxonomy.
Authors: We agree that the absence of direct validation against empirical bug distributions from real quantum codebases is a limitation. Our taxonomy was constructed from a synthesis of published quantum error patterns and expert input rather than mined real bugs, as no large-scale, labeled OpenQASM bug corpus currently exists. We will revise the manuscript to (1) explicitly state this limitation in the discussion section, (2) clarify that the reported Pass@1 figures apply to the synthetic distribution we defined, and (3) note that the open-source framework is designed to accept external bug datasets for future validation. We do not claim representativeness beyond the taxonomy categories covered. revision: partial
-
Referee: [Case study / experimental results] Case study / results: the abstract and results report specific Pass@1 thresholds and comparisons across models and strategies, yet no details are provided on the number of programs tested, total bug instances, bug-category balance, definition of Pass@1, or statistical significance. This directly affects soundness of the empirical claims.
Authors: We apologize for the omission. The submitted manuscript inadvertently left out the experimental parameters. In the revised version we will add a dedicated "Experimental Setup" subsection (and corresponding table) that reports: the exact number of OpenQASM 3.0 programs (50), total injected bug instances (250), per-category counts, the formal definition of Pass@1 (fraction of bugs for which the repaired program produces identical simulation output to the original on the chosen backend), and any statistical tests applied. All numerical claims in the abstract and results will be cross-referenced to this section. revision: yes
Circularity Check
No circularity; empirical benchmark with independent measurements
full rationale
The paper describes a new multi-agent framework for bug injection, LLM-based repair, and simulation validation on OpenQASM 3.0 programs, then reports Pass@1 metrics from actual LLM executions under different prompting strategies. No equations, fitted parameters, or derivations exist. The central claims (iterative feedback improves Pass@1; structured prompting can outperform CoT/ReAct) are direct empirical outcomes from the runs, not reductions of the inputs by construction. The taxonomy and simulation oracles are design choices whose representativeness is an external validity question, not a self-referential loop. No self-citation load-bearing steps are present.
Axiom & Free-Parameter Ledger
invented entities (1)
-
QBugLM multi-agent framework
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Leveraging LLM-Based Agentic Systems to Generate Quantum Applications for Test Optimization
QPipe deploys specialized LLM agents for parsing, formulation, code generation, review, execution and verification to produce quantum applications from 20 natural-language test-optimization requirements, reporting 100...
Reference graph
Works this paper leans on
-
[1]
Testing and Debugging Quantum Programs: The Road to 2030,
N. C. Leite Ramalho, H. Amario de Souza, and M. Lordello Chaim, “Testing and Debugging Quantum Programs: The Road to 2030,”ACM Trans. Softw. Eng. Methodol., vol. 34, pp. 155:1–155:46, May 2025
2030
-
[2]
Bugs in Quantum computing platforms: an empirical study,
M. Paltenghi and M. Pradel, “Bugs in Quantum computing platforms: an empirical study,”Proc. ACM Program. Lang., vol. 6, pp. 86:1–86:27, Apr. 2022
2022
-
[3]
Bugs4Q: A benchmark of existing bugs to enable controlled testing and debugging studies for quantum programs,
P. Zhao, Z. Miao, S. Lan, and J. Zhao, “Bugs4Q: A benchmark of existing bugs to enable controlled testing and debugging studies for quantum programs,”Journal of Systems and Software, vol. 205, p. 111805, Nov. 2023
2023
-
[4]
Automated quantum software engineering,
A. Sarkar, “Automated quantum software engineering,”Automated Soft- ware Engineering, vol. 31, p. 36, Apr. 2024
2024
-
[5]
Large Language Models for Software Engineering: Survey and Open Problems,
A. Fan, B. Gokkaya, M. Harman, M. Lyubarskiy, S. Sengupta, S. Yoo, and J. M. Zhang, “Large Language Models for Software Engineering: Survey and Open Problems,” inProceedings of the 2023 IEEE/ACM International Conference on Software Engineering: Future of Software Engineering (ICSE-FoSE), pp. 31–53, May 2023
2023
-
[6]
LLM-Based Multi-Agent Systems for Software Engineering: Literature Review, Vision, and the Road Ahead,
J. He, C. Treude, and D. Lo, “LLM-Based Multi-Agent Systems for Software Engineering: Literature Review, Vision, and the Road Ahead,” ACM Trans. Softw. Eng. Methodol., vol. 34, pp. 124:1–124:30, May 2025
2025
-
[7]
Pro- gramming quantum computers with large language models,
E. R. Henderson, J. M. Henderson, J. Ange, and M. A. Thornton, “Pro- gramming quantum computers with large language models,” inQuantum Information Science, Sensing, and Computation XVII(M. Hayduk, M. L. Fanto, and C. M. T. Jr, eds.), vol. 13451, p. 1345104, SPIE, 2025
2025
-
[8]
Qiskit code assistant: training LLMs for generating quantum computing code,
N. Dupuis, L. Buratti, S. Vishwakarma, A. V . Forrat, D. Kremer, I. Faro, R. Puri, and J. Cruz-Benito, “Qiskit code assistant: training LLMs for generating quantum computing code,” May 2024. arXiv:2405.19495
-
[9]
PennyCoder: Efficient Domain-Specific LLMs for PennyLane-Based Quantum Code Generation,
A. Basit, M. Shao, M. H. Asif, N. Innan, M. Kashif, A. Marchisio, and M. Shafique, “PennyCoder: Efficient Domain-Specific LLMs for PennyLane-Based Quantum Code Generation,” inProceedings of the 2025 IEEE International Conference on Quantum Computing and En- gineering (QCE), pp. 229–234, Aug. 2025
2025
-
[10]
Agent-Q: Fine-Tuning Large Language Models for Quantum Circuit Generation and Optimization,
L. Jern, V . Uotila, C. Yu, and B. Zhao, “Agent-Q: Fine-Tuning Large Language Models for Quantum Circuit Generation and Optimization,” inProceedings of the 2025 IEEE International Conference on Quantum Computing and Engineering (QCE), vol. 01, pp. 1621–1632, Aug. 2025
2025
-
[11]
QuanBench: Benchmarking Quantum Code Generation with Large Language Models,
X. Guo, M. Wang, and J. Zhao, “QuanBench: Benchmarking Quantum Code Generation with Large Language Models,” inProceedings of the 2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE), pp. 2657–2669, Nov. 2025. ISSN: 2643-1572
2025
-
[12]
QHackBench: Benchmarking Large Language Models for Quantum Code Generation Using PennyLane Hackathon Challenges,
A. Basit, M. Shao, M. H. Asif, N. Innan, M. Kashif, A. Marchisio, and M. Shafique, “QHackBench: Benchmarking Large Language Models for Quantum Code Generation Using PennyLane Hackathon Challenges,” inProceedings of the 2025 IEEE International Conference on Quantum Artificial Intelligence (QAI), pp. 316–322, Nov. 2025
2025
-
[13]
Qiskit HumanEval: An Evaluation Benchmark For Quantum Code Generative Models,
S. Vishwakarma, F. Harkins, S. Golecha, V . S. Bajpe, N. Dupuis, L. Buratti, D. Kremer, I. Faro, R. Puri, and J. Cruz-Benito, “Qiskit HumanEval: An Evaluation Benchmark For Quantum Code Generative Models,” June 2024. arXiv:2406.14712
-
[14]
Enhancing LLM-based Quantum Code Generation with Multi-Agent Optimization and Quantum Error Correction,
C. Campbell, H. M. Chen, W. Luk, and H. Fan, “Enhancing LLM-based Quantum Code Generation with Multi-Agent Optimization and Quantum Error Correction,” inProceedings of the 2025 62nd ACM/IEEE Design Automation Conference (DAC), pp. 1–7, June 2025
2025
-
[15]
Leveraging Mutation Analysis for LLM-based Repair of Quantum Programs,
C. Yoshida, Y . Ishimoto, O. Nourry, M. Kondo, M. Matsushita, Y . Kamei, and Y . Higo, “Leveraging Mutation Analysis for LLM-based Repair of Quantum Programs,” Jan. 2026. arXiv:2601.12273 [cs]
-
[16]
OpenQASM 3: A Broader and Deeper Quantum Assembly Language,
A. Cross, A. Javadi-Abhari, T. Alexander, N. De Beaudrap, L. S. Bishop, S. Heidel, C. A. Ryan, P. Sivarajah, J. Smolin, J. M. Gambetta, and B. R. Johnson, “OpenQASM 3: A Broader and Deeper Quantum Assembly Language,”ACM Transactions on Quantum Computing, vol. 3, pp. 1– 50, 9 2022
2022
-
[17]
MQT Bench: Benchmark- ing Software and Design Automation Tools for Quantum Computing,
N. Quetschlich, L. Burgholzer, and R. Wille, “MQT Bench: Benchmark- ing Software and Design Automation Tools for Quantum Computing,” Quantum, vol. 7, p. 1062, July 2023
2023
-
[18]
QMutPy: a mutation testing tool for Quantum algorithms and applications in Qiskit,
D. Fortunato, J. Campos, and R. Abreu, “QMutPy: a mutation testing tool for Quantum algorithms and applications in Qiskit,” inProceedings of the 31st ACM SIGSOFT International Symposium on Software Testing and Analysis, pp. 797–800, ACM, July 2022
2022
-
[19]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. Le, and D. Zhou, “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models,” Jan. 2023. arXiv:2201.11903
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
ReAct: Synergizing Reasoning and Acting in Language Models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing Reasoning and Acting in Language Models,” Mar
-
[21]
SPoC: Search-based Pseudocode to Code,
S. Kulal, P. Pasupat, K. Chandra, M. Lee, O. Padon, A. Aiken, and P. S. Liang, “SPoC: Search-based Pseudocode to Code,” inAdvances in Neural Information Processing Systems (NeurIPS 2019), vol. 32, Curran Associates, Inc., 2019
2019
-
[22]
Evaluating Large Language Models Trained on Code
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. d. O. Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry, P. Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter, P. Tillet, F. P. Such, D. Cummings, M. Plappert, F. Chantzis, E. Barnes, A. Herbert-V...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[23]
Asking the Right Questions: Improving Reasoning with Generated Stepping Stones
H. Hu, T. Fu, M. Jiang, A. H. Miller, Y . Bachrach, and J. N. Foerster, “Asking the Right Questions: Improving Reasoning with Generated Stepping Stones,” Feb. 2026. arXiv:2602.19069
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
QBugs: A Collection of Reproducible Bugs in Quantum Algorithms and a Supporting Infrastructure to Enable Controlled Quantum Software Testing and Debugging Experiments ,
J. Campos and A. Souto, “ QBugs: A Collection of Reproducible Bugs in Quantum Algorithms and a Supporting Infrastructure to Enable Controlled Quantum Software Testing and Debugging Experiments ,” inProceedings of the 2021 IEEE/ACM 2nd International Workshop on Quantum Software Engineering (Q-SE), pp. 28–32, IEEE, June 2021
2021
-
[25]
QChecker: Detecting Bugs in Quantum Programs via Static Analysis,
P. Zhao, X. Wu, Z. Li, and J. Zhao, “QChecker: Detecting Bugs in Quantum Programs via Static Analysis,” inProceedings of the 2023 IEEE/ACM 4th International Workshop on Quantum Software Engineering (Q-SE), pp. 50–57, May 2023
2023
-
[26]
ScaffCC: a framework for compilation and analysis of quantum computing programs,
A. JavadiAbhari, S. Patil, D. Kudrow, J. Heckey, A. Lvov, F. T. Chong, and M. Martonosi, “ScaffCC: a framework for compilation and analysis of quantum computing programs,” inProceedings of the 11th ACM Conference on Computing Frontiers, pp. 1–10, ACM, May 2014
2014
-
[27]
Quito: a Coverage-Guided Test Generator for Quantum Programs,
X. Wang, P. Arcaini, T. Yue, and S. Ali, “Quito: a Coverage-Guided Test Generator for Quantum Programs,” inProceedings of the 2021 36th IEEE/ACM International Conference on Automated Software En- gineering (ASE), pp. 1237–1241, Nov. 2021
2021
-
[28]
QuSBT: search-based testing of quantum programs,
X. Wang, P. Arcaini, T. Yue, and S. Ali, “QuSBT: search-based testing of quantum programs,” inProceedings of the ACM/IEEE 44th International Conference on Software Engineering: Companion Proceedings, ICSE ’22, (New York, NY , USA), pp. 173–177, ACM, Oct. 2022
2022
-
[29]
Muskit: a mutation analysis tool for quantum software testing,
E. Mendiluze, S. Ali, P. Arcaini, and T. Yue, “Muskit: a mutation analysis tool for quantum software testing,” inProceedings of the 36th IEEE/ACM International Conference on Automated Software Engineer- ing, pp. 1266–1270, IEEE, June 2022
2022
-
[30]
An applied quantum Hoare logic,
L. Zhou, N. Yu, and M. Ying, “An applied quantum Hoare logic,” in Proceedings of the 40th ACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI 2019, pp. 1149–1162, ACM, June 2019
2019
-
[31]
Automatic Repair of Quantum Programs via Unitary Operation,
Y . Li, H. Pei, L. Huang, B. Yin, and K.-Y . Cai, “Automatic Repair of Quantum Programs via Unitary Operation,”ACM Trans. Softw. Eng. Methodol., vol. 33, pp. 154:1–154:43, June 2024
2024
-
[32]
HornBro: Homotopy-Like Method for Automated Quantum Program Repair,
S. Tan, L. Lu, D. Xiang, T. Chu, C. Lang, J. Chen, X. Hu, and J. Yin, “HornBro: Homotopy-Like Method for Automated Quantum Program Repair,”Proc. ACM Softw. Eng., vol. 2, pp. FSE034:734–FSE034:756, June 2025
2025
-
[33]
On Repairing Quantum Programs Using ChatGPT,
X. Guo, J. Zhao, and P. Zhao, “On Repairing Quantum Programs Using ChatGPT,” inProceedings of the 5th ACM/IEEE International Workshop on Quantum Software Engineering, Q-SE 2024, pp. 9–16, ACM, Aug. 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.