On the Shoulders of Giants: Empowering Automated Smart Contract Auditing via the GiAnt Corpus
Pith reviewed 2026-06-27 21:48 UTC · model grok-4.3
The pith
GiANT automates extraction of 7,711 smart contract vulnerabilities from 388 real-world audit reports using LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
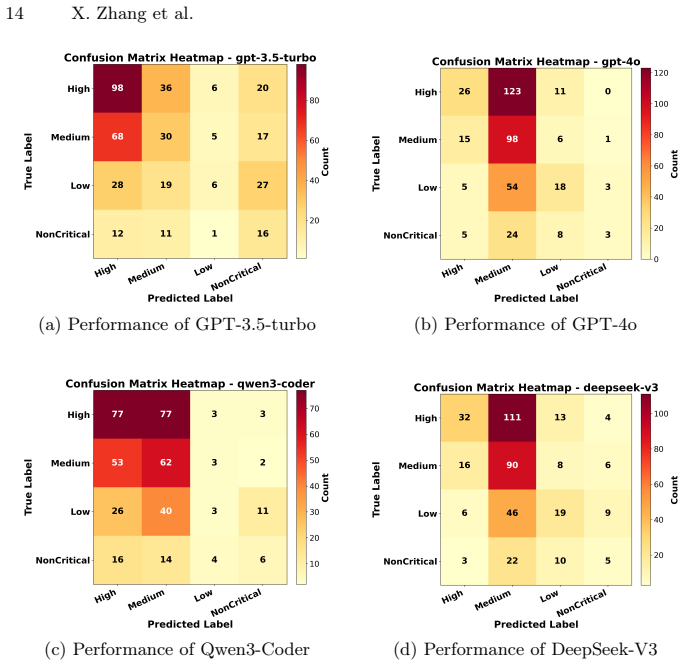
The central discovery is that running the GiANT framework on 388 real-world audit reports yields the GiAnt Corpus with 7,711 vulnerability findings at five severity levels. Extraction relies on divide-and-conquer plus chain-of-thought to pull structured details, and LLM-as-a-judge ensures quality. Human reviewers rate the output at a mean of 4.76 out of 5 with strong agreement. Benchmarks on the corpus give baseline results for LLMs performing vulnerability detection, code summarization, mitigation recommendation, and gas optimization.
What carries the argument
Divide-and-conquer strategy with Chain-of-Thought for structured extraction from reports, paired with an LLM-as-a-judge quality control step.
If this is right
- The GiAnt Corpus allows benchmarking of LLMs on vulnerability detection and related auditing tasks.
- It establishes performance baselines for state-of-the-art models on those tasks.
- The approach offers a scalable alternative to manual dataset curation for smart contract auditing.
- Structured data across severity levels facilitates diverse research applications.
Where Pith is reading between the lines
- Applying the same extraction process to reports from other auditing sources could expand available data for security research.
- High-quality extracted datasets might accelerate development of AI systems that assist or replace parts of human audits.
- Patterns identified across the large corpus could inform better vulnerability prevention strategies in contract development.
Load-bearing premise
The LLM extraction and quality control process accurately and completely captures the vulnerabilities described in the original human audit reports without systematic errors or omissions.
What would settle it
A side-by-side manual audit of extracted entries against their source reports that finds consistent missing vulnerabilities or misrepresented details.
Figures


read the original abstract
High-quality smart contract auditing datasets are crucial for evaluating security tools and advancing smart contract security research. Two major limitations of existing datasets are the manual-induced scalability bottleneck and the deficiency in data granularity and diversity. To address these limitations, we propose GiANT, an automated framework designed to curate smart contract auditing datasets by distilling vulnerability insights from real-world auditing reports. GiANT employs a divide-and-conquer strategy coupled with the Chain-of-Thought technique to extract structured vulnerability information from Code4rena reports, followed by an LLM-as-a-judge mechanism to perform rigorous quality assurance. To evaluate GiANT's effectiveness, we run it on 388 real-world audit reports and generate the GiAnt Corpus comprising 7,711 vulnerability findings across five severity levels. Manual assessment of the dataset demonstrates exceptional reliability in information extraction, achieving a mean quality score of $4.76\pm0.37$ (out of 5) with inter-rater agreement $\kappa$ of 0.88. We further validate the practicality of our dataset by benchmarking 4 state-of-the-art LLMs on vulnerability detection, code summarization, mitigation recommendation, and automated gas optimization tasks, to establish performance baselines, thereby providing a valuable data foundation for future research in automated smart contract auditing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the GiANT framework, which applies an LLM-based divide-and-conquer strategy with Chain-of-Thought prompting to extract structured vulnerability findings from 388 Code4rena audit reports, followed by an LLM-as-a-judge quality filter. This produces the GiAnt Corpus containing 7,711 vulnerability findings across five severity levels. The authors report a mean manual quality score of 4.76±0.37 (out of 5) with inter-rater agreement κ=0.88 on sampled items and demonstrate utility by benchmarking four state-of-the-art LLMs on vulnerability detection, code summarization, mitigation recommendation, and gas optimization tasks.
Significance. If the extraction process can be shown to be both high-precision and complete, the resulting corpus would address key scalability and granularity limitations in existing smart-contract auditing datasets and provide a reusable foundation for training and evaluating automated auditing tools. The reported benchmarking baselines would then serve as a concrete reference point for future LLM-based auditing research.
major comments (3)
- [Evaluation section] Evaluation section: the manual assessment reports quality scores and κ=0.88 on sampled extracted findings but supplies no information on the sampling procedure for the 388 reports or the 7,711 items, the exact extraction and judging prompts, exclusion criteria, or controls for LLM-judge bias. These omissions directly affect the strength of the claim that the corpus is a reliable distillation of the source reports.
- [Corpus construction] Corpus construction (GiANT pipeline description): the method is evaluated only on precision-oriented metrics (quality of retained items). No recall or completeness audit is performed against the original human-written audit reports to verify that every mentioned vulnerability was extracted without systematic omission or distortion. This gap is load-bearing for the central claim that the 7,711 findings constitute a faithful, high-granularity corpus suitable for benchmarking.
- [Benchmarking experiments] Benchmarking experiments: the performance baselines for the four LLMs are presented without discussion of how potential under-extraction in the corpus could bias the measured task accuracies or limit the generalizability of the reported results.
minor comments (2)
- [Abstract and Results] The abstract states that findings span five severity levels; the main text should explicitly map these levels to the original Code4rena severity categories and report the distribution across the 7,711 items.
- [Figures and Tables] Figure captions and table headers should include the exact number of reports and findings used in each evaluation step to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable suggestions. Below we provide point-by-point responses to the major comments, indicating the revisions we will make to address them.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section: the manual assessment reports quality scores and κ=0.88 on sampled extracted findings but supplies no information on the sampling procedure for the 388 reports or the 7,711 items, the exact extraction and judging prompts, exclusion criteria, or controls for LLM-judge bias. These omissions directly affect the strength of the claim that the corpus is a reliable distillation of the source reports.
Authors: We agree these details are necessary for reproducibility and to support the reliability claim. In the revised manuscript we will expand the Evaluation section to specify the sampling procedure (random selection of 30 reports and 150 findings), include the exact extraction and judging prompts in an appendix, state the exclusion criteria applied during sampling, and add a comparison of LLM-judge outputs against human annotations on a 50-item subset to address potential judge bias. revision: yes
-
Referee: [Corpus construction] Corpus construction (GiANT pipeline description): the method is evaluated only on precision-oriented metrics (quality of retained items). No recall or completeness audit is performed against the original human-written audit reports to verify that every mentioned vulnerability was extracted without systematic omission or distortion. This gap is load-bearing for the central claim that the 7,711 findings constitute a faithful, high-granularity corpus suitable for benchmarking.
Authors: We acknowledge that the absence of a recall evaluation limits the strength of the completeness claim. Our validation emphasized precision of retained items. We will add a dedicated Limitations section that explicitly discusses the lack of a full recall audit, notes the resource constraints that prevented it, and clarifies that the corpus is presented as a high-precision extraction rather than a guaranteed exhaustive one. revision: yes
-
Referee: [Benchmarking experiments] Benchmarking experiments: the performance baselines for the four LLMs are presented without discussion of how potential under-extraction in the corpus could bias the measured task accuracies or limit the generalizability of the reported results.
Authors: We agree that potential bias from incomplete extraction should be addressed. In the revised Benchmarking section we will add a paragraph noting that the high manual quality scores and inter-rater agreement provide indirect support for limited under-extraction, that any missed items would likely affect all models similarly (preserving relative rankings), and that the reported accuracies should be interpreted as potentially conservative lower bounds. revision: yes
Circularity Check
No circularity in empirical corpus curation pipeline
full rationale
The paper describes an LLM-based divide-and-conquer extraction pipeline applied to 388 Code4rena reports, producing 7,711 findings whose quality is measured by independent human raters (mean score 4.76±0.37, κ=0.88). No equations, parameter fitting, predictions derived from fitted inputs, or self-citation chains appear in the provided text. The central claim rests on external human validation rather than any quantity defined from the extraction process itself; therefore the derivation chain is self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM divide-and-conquer plus Chain-of-Thought prompting can extract structured vulnerability information from Code4rena reports at scale
- domain assumption An LLM-as-a-judge mechanism provides rigorous quality assurance comparable to human review
Reference graph
Works this paper leans on
-
[1]
https://github.com/pymupdf/PyMuPDF
Pymupdf. https://github.com/pymupdf/PyMuPDF
-
[2]
https://zenodo.org/records/19325553 (2026)
Our replication package. https://zenodo.org/records/19325553 (2026)
arXiv 2026
-
[3]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv:2303.08774 (2023)
Pith/arXiv arXiv 2023
-
[4]
arXiv preprint arXiv:2309.16609 (2023)
Bai, J., Bai, S., Chu, Y., Cui, Z., Dang, K., Deng, X., Fan, Y., Ge, W., Han, Y., Huang, F., et al.: Qwen technical report. arXiv preprint arXiv:2309.16609 (2023)
Pith/arXiv arXiv 2023
-
[5]
Automated Software Engineering31(2), 63 (2024)
Chen, J., Hu, J., Xia, X., Lo, D., Grundy, J., Gao, Z., Chen, T.: Angels or demons: investigating and detecting decentralized financial traps on ethereum smart con- tracts. Automated Software Engineering31(2), 63 (2024)
2024
-
[6]
IEEE Transactions on Software Engineering (2025)
Chen, J., Shao, Z., Yang, S., Shen, Y., Wang, Y., Chen, T., Shan, Z., Zheng, Z.: Numscout: Unveiling numerical defects in smart contracts using llm-pruning symbolic execution. IEEE Transactions on Software Engineering (2025)
2025
-
[7]
Chen, J., Shen, Y., Zhang, J., Li, Z., Grundy, J., Shao, Z., Wang, Y., Wang, J., Chen, T., Zheng, Z.: Forge: An llm-driven framework for large-scale smart contract vulnerability dataset construction (2025), https://arxiv.org/abs/2506.18795
arXiv 2025
-
[8]
Code4rena: https://code4rena.com/
-
[9]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Dai, Z., Chen, B., Zhao, Z., Tang, X., Wu, S., Yao, C., Gao, Z., Chen, J.: Less is more: Adaptive program repair with bug localization and preference learning. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 128–136 (2025)
2025
-
[10]
In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Dai, Z., Yao, C., Han, W., Yuanying, Y., Gao, Z., Chen, J.: Mpcoder: Multi-user personalized code generator with explicit and implicit style representation learning. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 3765–3780 (2024)
2024
-
[11]
arXiv preprint arXiv:2601.08545 (2026)
Dai, Z., Zhao, Z., Wang, H., Tang, X., Wu, S., Yao, C., Gao, Z., Chen, J.: Learner- tailored program repair: A solution generator with iterative edit-driven retrieval enhancement. arXiv preprint arXiv:2601.08545 (2026)
arXiv 2026
-
[12]
DeFiLlama: https://defillama.com/ (2026)
2026
-
[13]
Ding, Y., Fu, Y., Ibrahim, O., Sitawarin, C., Chen, X., Alomair, B., Wagner, D., Ray, B., Chen, Y.: Vulnerability detection with code language models: How far are we? arXiv preprint arXiv:2403.18624 (2024)
arXiv 2024
-
[14]
Empirical review of automated analysis tools on 47,587 ethereum smart contracts,
Durieux, T., Ferreira, J.F., Abreu, R., Cruz, P.: Empirical review of auto- mated analysis tools on 47,587 ethereum smart contracts. In: Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering. ICSE ’20. https://doi.org/10.1145/3377811.3380364
-
[15]
In: 2019 IEEE/ACM 2nd international workshop on emerging trends in software engineering for blockchain (WETSEB)
Feist, J., Grieco, G., Groce, A.: Slither: a static analysis framework for smart contracts. In: 2019 IEEE/ACM 2nd international workshop on emerging trends in software engineering for blockchain (WETSEB). pp. 8–15. IEEE (2019) 20 X. Zhang et al
2019
-
[16]
In: Proceedings of the 35th IEEE/ACM international conference on automated software engineering
Gao, Z.: When deep learning meets smart contracts. In: Proceedings of the 35th IEEE/ACM international conference on automated software engineering. pp. 1400– 1402 (2020)
2020
-
[17]
In: 2019 IEEE International Conference on Software Maintenance and Evolution (ICSME)
Gao, Z., Jayasundara, V., Jiang, L., Xia, X., Lo, D., Grundy, J.: Smartembed: A tool for clone and bug detection in smart contracts through structural code embedding. In: 2019 IEEE International Conference on Software Maintenance and Evolution (ICSME). pp. 394–397. IEEE (2019)
2019
-
[18]
IEEE Transactions on Software Engineering47(12), 2874–2891 (2020)
Gao, Z., Jiang, L., Xia, X., Lo, D., Grundy, J.: Checking smart contracts with structural code embedding. IEEE Transactions on Software Engineering47(12), 2874–2891 (2020)
2020
-
[19]
Hedera Hashgraph, LLC: What is a smart contract audit? https://hedera.com/learning/smart-contract-audit/
-
[20]
In: 2021 36th IEEE/ACM International Conference on Automated Software Engineering (ASE)
Hu, X., Gao, Z., Xia, X., Lo, D., Yang, X.: Automating user notice generation for smart contract functions. In: 2021 36th IEEE/ACM International Conference on Automated Software Engineering (ASE). pp. 5–17. IEEE (2021)
2021
-
[21]
Survey of hallucination in natural language generation,
Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., Ishii, E., Bang, Y.J., Madotto, A., Fung, P.: Survey of hallucination in natural language generation. ACM Computing Surveys 55(12) (2023). https://doi.org/10.1145/3571730
-
[22]
Li, X., Li, Z., Li, W., Zhang, Y., Wang, X.: No more hidden pitfalls? exposing smart contract bad practices with llm-powered hybrid analysis. ACM Trans. Softw. Eng. Methodol. (2026). https://doi.org/10.1145/3795692, just Accepted
-
[23]
In: 2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE)
Lin, H., Gao, Z., Chen, J., Chen, X., Yang, X., Bao, L.: Actaint: Agent-based taint analysis for access control vulnerabilities in smart contracts. In: 2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE). pp. 2555–2567. IEEE (2025)
2025
-
[24]
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al.: Deepseek-v3 technical report. arXiv:2412.19437 (2024)
Pith/arXiv arXiv 2024
-
[25]
In: 33rd USENIX Security Symposium (USENIX Security 24)
Liu, P., Liu, J., Fu, L., Lu, K., Xia, Y., Zhang, X., Chen, W., Weng, H., Ji, S., Wang, W.: Exploring{ChatGPT’s} capabilities on vulnerability management. In: 33rd USENIX Security Symposium (USENIX Security 24). pp. 811–828 (2024)
2024
-
[26]
In: Findings of the Association for Computational Linguistics: ACL 2023
Liu, X., Tan, Y., Xiao, Z., Zhuge, J., Zhou, R.: Not the end of story: An eval- uation of chatgpt-driven vulnerability description mappings. In: Findings of the Association for Computational Linguistics: ACL 2023. pp. 3724–3731 (2023)
2023
-
[27]
Lu, S., Guo, D., Ren, S., Huang, J., Svyatkovskiy, A., Blanco, A., Clement, C., Drain, D., Jiang, D., Tang, D., et al.: Codexglue: A machine learning benchmark dataset for code understanding and generation. arXiv:2102.04664 (2021)
Pith/arXiv arXiv 2021
-
[28]
In: Proceedings of the 2016 ACM SIGSAC conference on computer and communications security
Luu, L., Chu, D.H., Olickel, H., Saxena, P., Hobor, A.: Making smart contracts smarter. In: Proceedings of the 2016 ACM SIGSAC conference on computer and communications security. pp. 254–269 (2016)
2016
-
[29]
Proceedings of the ACM on Software Engineering1(FSE), 2355–2377 (2024)
Mai, Y., Gao, Z., Hu, X., Bao, L., Liu, Y., Sun, J.: Are human rules necessary? generating reusable apis with cot reasoning and in-context learning. Proceedings of the ACM on Software Engineering1(FSE), 2355–2377 (2024)
2024
-
[30]
In: 2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE)
Mai,Y.,Gao,Z.,Wang,H.,Bi,T.,Hu,X.,Xia,X.,Sun,J.:Towardsbetteranswers: Automated stack overflow post updating. In: 2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). pp. 591–603. IEEE (2025)
2025
-
[31]
https://owasp.org/www-project-smart-contract-top-10/
OWASP Foundation: OWASP smart contract top 10 - 2026. https://owasp.org/www-project-smart-contract-top-10/
2026
-
[32]
IEEE Transactions on Software Engineering (2026) Empowering Automated Smart Contract Auditing via the GiAnt Corpus 21
Ruan, Y., Gao, Z., Chen, J., Bao, L., Yang, X.: Improving gas efficiency in smart contracts: Data-driven insights and llm-assisted remediation. IEEE Transactions on Software Engineering (2026) Empowering Automated Smart Contract Auditing via the GiAnt Corpus 21
2026
-
[33]
In: 2024 IEEE Symposium on Security and Privacy (SP)
Sendner, C., Petzi, L., Stang, J., Dmitrienko, A.: Large-scale study of vulnerability scanners for ethereum smart contracts. In: 2024 IEEE Symposium on Security and Privacy (SP). pp. 2273–2290. IEEE (2024)
2024
-
[34]
https://solidityscan.com/web3hackhub?year=2025, accessed: 2026-03-02
SolidityScan: Web3HackHub: 2025 Web3 security incidents statistics. https://solidityscan.com/web3hackhub?year=2025, accessed: 2026-03-02
2025
-
[35]
SolidityScan: Web3HackHub 2024 annual security report: Analyzing 149 incidents and $1.42b losses. Tech. rep., SolidityScan (2024), https://solidityscan.com/
2024
-
[36]
Sun, Y., Wu, D., Xue, Y., Liu, H., Ma, W., Zhang, L., Liu, Y., Li, Y.: Llm4vuln: A unified evaluation framework for decoupling and enhancing llms’ vulnerability reasoning. arXiv:2401.16185 (2024)
arXiv 2024
-
[37]
In: Proceedings of the IEEE/ACM 46th international conference on soft- ware engineering
Sun, Y., Wu, D., Xue, Y., Liu, H., Wang, H., Xu, Z., Xie, X., Liu, Y.: Gptscan: Detecting logic vulnerabilities in smart contracts by combining gpt with program analysis. In: Proceedings of the IEEE/ACM 46th international conference on soft- ware engineering. pp. 1–13 (2024)
2024
-
[38]
In: Proceedings of the 2018 ACM SIGSAC conference on computer and communications security (2018)
Tsankov, P., Dan, A., Drachsler-Cohen, D., Gervais, A., Buenzli, F., Vechev, M.: Securify: Practical security analysis of smart contracts. In: Proceedings of the 2018 ACM SIGSAC conference on computer and communications security (2018)
2018
-
[39]
IEEE Transactions on Software Engineering50(11), 2732–2752 (2024)
Wang, H., Gao, Z., Hu, X., Lo, D., Grundy, J., Wang, X.: Just-in-time todo-missed commits detection. IEEE Transactions on Software Engineering50(11), 2732–2752 (2024)
2024
-
[40]
Wohlin, C., Runeson, P., Höst, M., Ohlsson, M.C., Regnell, B., Wesslén, A., et al.: Experimentation in software engineering, vol. 236. Springer (2012)
2012
-
[41]
Xia, B., Bi, T., Xing, Z., Lu, Q., Zhu, L.: An empirical study on software bill of materials: Where we stand and the road ahead (2023), https://arxiv.org/abs/2301.05362
arXiv 2023
-
[42]
In: 2025 IEEE/ACM International Workshop on Large Language Models for Code (LLM4Code)
Xia, S., He, M., Song, L., Zhang, Y.: Sc-bench: A large-scale dataset for smart contract auditing. In: 2025 IEEE/ACM International Workshop on Large Language Models for Code (LLM4Code). pp. 57–64 (2025). https://doi.org/10.1109/LLM4Code66737.2025.00012
-
[43]
ACM Transactions on Software Engineering and Methodology34(3), 1–31 (2025)
Xiang, J., Gao, Z., Bao, L., Hu, X., Chen, J., Xia, X.: Automating comment genera- tion for smart contract from bytecode. ACM Transactions on Software Engineering and Methodology34(3), 1–31 (2025)
2025
-
[44]
Xue, Z., Gao, Z., Wang, S., Hu, X., Xia, X., Li, S.: Selfpico: Self-guided partial codeexecutionwithllms.In:Proceedingsofthe33rdACMSIGSOFTInternational Symposium on Software Testing and Analysis. pp. 1389–1401 (2024)
2024
-
[45]
ACM Transactions on Software Engineering and Methodology (2025)
Xue, Z., Zhang, X., Gao, Z., Hu, X., Gao, S., Xia, X., Li, S.: Clean code, better models: Enhancing llm performance with smell-cleaned dataset. ACM Transactions on Software Engineering and Methodology (2025)
2025
-
[46]
In: 2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE)
Yan, D., Gao, Z., Liu, Z.: A closer look at different difficulty levels code gener- ation abilities of chatgpt. In: 2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE). pp. 1887–1898. IEEE (2023)
2023
-
[47]
Yashavant,C.S.,Kumar,S.,Karkare,A.:Scrawld:Adatasetofrealworldethereum smart contracts labelled with vulnerabilities. arXiv:2202.11409 (2022)
arXiv 2022
-
[48]
ACM Transactions on Software Engineering and Methodology (2025)
Yu, J., Gao, Z., Bao, L., Liu, Z.: Enhancing domain-specific code completion via collaborative inference with large and small language models. ACM Transactions on Software Engineering and Methodology (2025)
2025
-
[49]
In: 2020 IEEE international conference on software maintenance and evolution (ICSME)
Zhang, P., Xiao, F., Luo, X.: A framework and dataset for bugs in ethereum smart contracts. In: 2020 IEEE international conference on software maintenance and evolution (ICSME). pp. 139–150. IEEE (2020)
2020
-
[50]
arXiv preprint arXiv:1904.09675 (2019) 22 X
Zhang, T., Kishore, V., Wu, F., Weinberger, K.Q., Artzi, Y.: Bertscore: Evaluating text generation with bert. arXiv preprint arXiv:1904.09675 (2019) 22 X. Zhang et al
Pith/arXiv arXiv 1904
-
[51]
In: 2023 IEEE/ACM 45th International Conference on Software Engi- neering (ICSE)
Zhang, Z., Zhang, B., Xu, W., Lin, Z.: Demystifying exploitable bugs in smart contracts. In: 2023 IEEE/ACM 45th International Conference on Software Engi- neering (ICSE). pp. 615–627. IEEE (2023)
2023
-
[52]
IEEE Transactions on Software Engineering50(6) (2024)
Zheng, Z., Su, J., Chen, J., Lo, D., Zhong, Z., Ye, M.: Dappscan: Building large- scale datasets for smart contract weaknesses in dapp projects. IEEE Transactions on Software Engineering50(6) (2024). https://doi.org/10.1109/tse.2024.3383422
-
[53]
Future Gen- eration Computer Systems105, 475–491 (2020)
Zheng, Z., Xie, S., Dai, H.N., Chen, W., Chen, X., Weng, J., Imran, M.: An overview on smart contracts: Challenges, advances and platforms. Future Gen- eration Computer Systems105, 475–491 (2020)
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.