Your UnEmbedding Matrix is Secretly a Feature Lens for Text Embeddings
Pith reviewed 2026-06-27 21:59 UTC · model grok-4.3
The pith
The unembedding matrix encodes a subspace that writes frequent tokens into LLM embeddings, and filtering it out refines semantic quality while enabling dimension reduction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
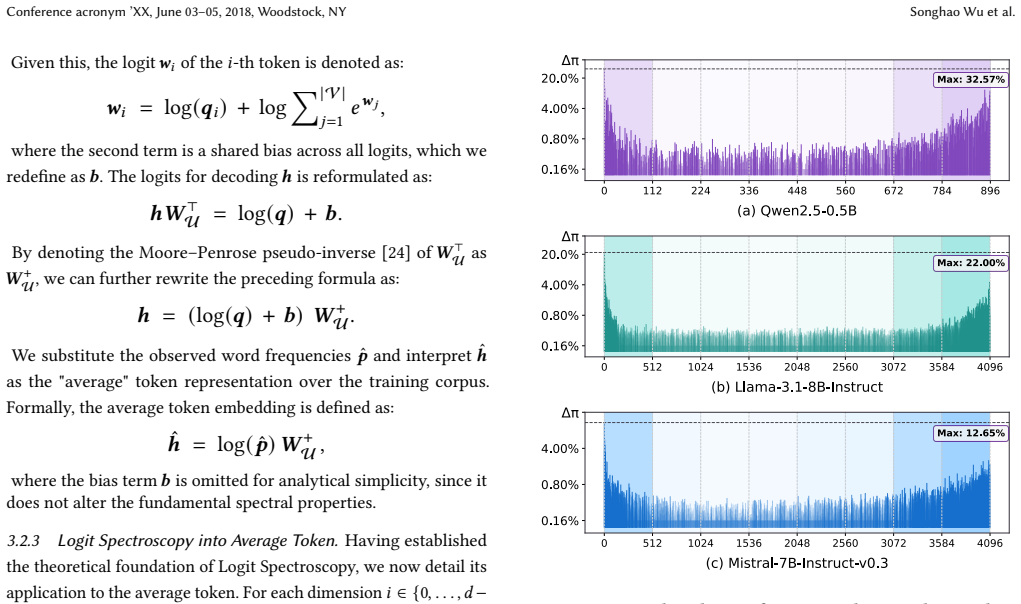
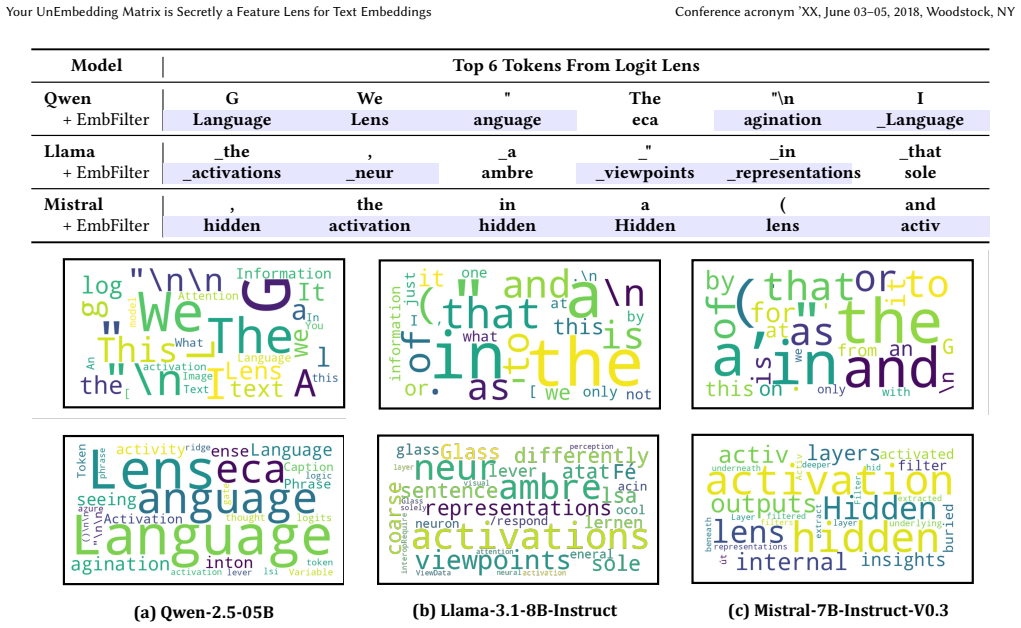
The unembedding matrix within LLMs encodes a latent space that is actively writing frequent tokens into embedding space. By filtering out this subspace, EmbedFilter suppresses the influence of high-frequency tokens, thereby enhancing semantic representations. As a byproduct, this enables an inherent dimensionality reduction that lowers index storage and speeds retrieval while fully preserving the refined embedding quality.
What carries the argument
EmbedFilter, the linear transformation that projects embeddings orthogonal to the high-frequency token subspace identified inside the unembedding matrix.
If this is right
- LLMs equipped with EmbedFilter achieve superior zero-shot performance on downstream embedding tasks.
- Embedding dimensions can be reduced significantly while maintaining or improving quality.
- Index storage costs drop and retrieval speeds increase due to the lower dimensions.
- The refinement works across multiple different LLM backbones without retraining.
Where Pith is reading between the lines
- The same unembedding subspace might be removable at inference time in any model that uses a tied or untied output projection.
- Embedding-specific fine-tuning objectives could be redesigned to penalize this subspace from the start rather than correcting for it afterward.
- The technique may extend to other representation tasks where vocabulary-frequency bias appears in hidden states.
Load-bearing premise
The alignment of embeddings with high-frequency tokens is caused by a distinct, removable subspace in the unembedding matrix that carries no essential semantic information.
What would settle it
An experiment in which applying EmbedFilter either fails to raise or actively lowers scores on standard text embedding benchmarks, or in which the filtered embeddings lose critical semantic distinctions that the original embeddings preserved.
Figures

read the original abstract
Large language models exhibit impressive zero-shot capabilities across a wide range of downstream tasks. However, they struggle to function as off-the-shelf embedding models, leading to suboptimal performance on massive text embedding benchmarks. In this paper, we identify a potential cause underlying this deficiency. Our motivation stems from an unexpected observation: text embeddings tend to align with frequent but uninformative tokens when projected onto the vocabulary space. We argue that this excessive expression of high-frequency tokens suppresses the model's ability to capture nuanced semantics. To address this, we introduce EmbedFilter, a simple linear transformation designed to refine text embeddings derived from LLMs directly. Specifically, we uncover that the unembedding matrix within LLMs encodes a latent space that is actively writing these frequent tokens into embedding space. By filtering out this subspace, EmbedFilter suppress the influence of high-frequency tokens, thereby enhancing semantic representations. As a compelling byproduct, this enables an inherent dimensionality reduction, lowering index storage and speedup retrieval while fully preserving the refined embedding quality. Our experiments across multiple LLM backbones demonstrate that LLMs equipped with EmbedFilter achieve superior zero-shot downstream performance even with significantly reduced embedding dimensions. We hope our findings provide deeper insights into the mechanisms of LLM-based representations and inspire more principled designs to improve text embeddings training. Our code is available at https://github.com/CentreChen/EmbFilter.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLM-derived text embeddings align excessively with high-frequency but uninformative tokens when projected into vocabulary space, which suppresses nuanced semantic capture. It identifies a corresponding low-rank subspace in the unembedding matrix W that 'writes' these tokens into embeddings, and introduces EmbedFilter as a linear projection that removes this subspace. The resulting refined embeddings are argued to improve zero-shot performance on text embedding benchmarks while permitting substantial dimensionality reduction without quality loss. Experiments across multiple LLM backbones are reported to support these gains, with code released.
Significance. If the central causal claim holds, the work supplies a simple, training-free post-processing step that could improve off-the-shelf LLM embeddings for retrieval and similarity tasks while cutting storage and latency costs. The open-sourced implementation is a clear strength that supports reproducibility and follow-up work. The mechanistic framing around the unembedding matrix could also inform future embedding-model training objectives.
major comments (2)
- [§4] §4 (experimental evaluation): No ablations compare EmbedFilter against generic low-rank projections of equivalent rank, such as PCA on the raw embedding matrix, mean subtraction, or random orthogonal removal of the same number of dimensions. Without these controls it remains possible that any dimensionality-reducing linear map produces the observed gains, which would undermine the claim that the frequency-aligned subspace identified from W is the specific performance bottleneck.
- [§3.2] §3.2 (definition of EmbedFilter): The construction of the filter assumes that directions in W correlated with token frequency can be excised without discarding task-relevant semantics, yet the manuscript provides no direct test (e.g., performance on tasks where high-frequency tokens carry signal, or semantic similarity probes before/after filtering) that the removed subspace is semantically dispensable rather than merely correlated with frequency.
minor comments (2)
- [Abstract] The abstract refers to 'massive text embedding benchmarks' without naming them; the main text should explicitly list all evaluation datasets and metrics in the first paragraph of the experimental section for clarity.
- [§3] Notation for the unembedding matrix and the identified subspace should be introduced once with consistent symbols (e.g., W and the projector P) and reused uniformly rather than re-described in multiple sections.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the experimental claims. We address each major point below and outline revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (experimental evaluation): No ablations compare EmbedFilter against generic low-rank projections of equivalent rank, such as PCA on the raw embedding matrix, mean subtraction, or random orthogonal removal of the same number of dimensions. Without these controls it remains possible that any dimensionality-reducing linear map produces the observed gains, which would undermine the claim that the frequency-aligned subspace identified from W is the specific performance bottleneck.
Authors: We agree that direct comparisons to generic low-rank methods are necessary to establish specificity. The manuscript identifies the subspace via correlation with token frequency in W, but without controls it is possible the gains arise from dimensionality reduction alone. In the revision we will add ablations using PCA on the embedding matrix, mean subtraction, and random orthogonal projections of matching rank, reporting results on the same benchmarks to show that the W-derived filter yields gains beyond generic projections. revision: yes
-
Referee: [§3.2] §3.2 (definition of EmbedFilter): The construction of the filter assumes that directions in W correlated with token frequency can be excised without discarding task-relevant semantics, yet the manuscript provides no direct test (e.g., performance on tasks where high-frequency tokens carry signal, or semantic similarity probes before/after filtering) that the removed subspace is semantically dispensable rather than merely correlated with frequency.
Authors: The observed gains on semantic zero-shot benchmarks provide supporting evidence that the excised directions are not required for those tasks. Nevertheless, we acknowledge the absence of targeted probes. In revision we will add before/after semantic similarity analyses on standard probes and will attempt to identify or construct tasks where high-frequency tokens carry signal, to more directly test dispensability of the subspace. revision: partial
Circularity Check
No circularity; derivation is self-contained from matrix analysis
full rationale
The paper constructs EmbedFilter by direct inspection of the unembedding matrix W to identify and remove a subspace aligned with high-frequency tokens. No equations, fitted parameters renamed as predictions, or self-citations are present in the abstract or description that reduce the claimed improvement to a tautology or input by construction. The method is presented as an independent linear map derived from observed alignments in W itself, with no load-bearing prior results from the same authors invoked to justify uniqueness or the ansatz.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Parishad BehnamGhader, Vaibhav Adlakha, Marius Mosbach, Dzmitry Bahdanau, Nicolas Chapados, and Siva Reddy. 2024. LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders. arXiv:2404.05961 [cs.CL] https://arxiv.org/abs/ 2404.05961
arXiv 2024
-
[2]
Nora Belrose, Zach Furman, Logan Smith, Jason Wu, Brian Ge, Alisa Trakhten- berg, Misha Shah, and Jacob Gurney. 2023. Eliciting Latent Predictions from Transformers with the Tuned Lens.arXiv preprint arXiv:2303.08112(2023)
Pith/arXiv arXiv 2023
-
[3]
Alexander Bondarenko, Maik Fröbe, Meriem Beloucif, Lukas Gienapp, Yamen Ajjour, Alexander Panchenko, Chris Biemann, Benno Stein, Henning Wachsmuth, Martin Potthast, and Matthias Hagen. 2020. Overview of Touché 2020: Argument Retrieval: Extended Abstract. InExperimental IR Meets Multilinguality, Multi- modality, and Interaction: 11th International Conferen...
-
[4]
Vera Boteva, Demian Gholipour, Artem Sokolov, and Stefan Riezler. 2016. A Full- Text Learning to Rank Dataset for Medical Information Retrieval. InProceedings of the European Conference on Information Retrieval (ECIR)(Padova, Italy). Springer
2016
-
[5]
and Angeli, Gabor and Potts, Christopher and Manning, Christopher D
Samuel R. Bowman, Gabor Angeli, Christopher Potts, and Christopher D. Man- ning. 2015. A large annotated corpus for learning natural language inference. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Pro- cessing, Lluís Màrquez, Chris Callison-Burch, and Jian Su (Eds.). Association for Computational Linguistics, Lisbon, Por...
-
[6]
Nicola Cancedda. 2024. Spectral Filters, Dark Signals, and Attention Sinks. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computational Linguistics, Bangkok, Thailand, 4792–4808. doi:10.18653/v1/2024.acl-long.263
-
[7]
Arman Cohan, Sergey Feldman, Iz Beltagy, Doug Downey, and Daniel S. Weld
-
[8]
SPECTER: Document-level Representation Learning using Citation- informed Transformers. InACL
-
[9]
DeepSeek-AI. 2026. DeepSeek-V4: Towards Highly Efficient Million-Token Con- text Intelligence
2026
-
[10]
Kawin Ethayarajh. 2019. How Contextual are Contextualized Word Represen- tations? Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Pro- cessing (EMNLP-IJCNLP), Kentaro Inui, Jing Jiang, Vincent...
-
[11]
Luyu Gao and Jamie Callan. 2022. Unsupervised Corpus Aware Language Model Pre-training for Dense Passage Retrieval. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Smaranda Muresan, Preslav Nakov, and Aline Villavicencio (Eds.). Association for Computa- tional Linguistics, Dublin, Ireland,...
-
[12]
Tianyu Gao, Xingcheng Yao, and Danqi Chen. 2021. SimCSE: Simple Contrastive Learning of Sentence Embeddings. InProceedings of the 2021 Conference on Em- pirical Methods in Natural Language Processing, Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih (Eds.). Association for Compu- tational Linguistics, Online and Punta Cana, Domini...
-
[13]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783 (2024)
Pith/arXiv arXiv 2024
-
[14]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, De- vendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7B. arXiv:2310.068...
Pith/arXiv arXiv 2023
-
[15]
Ting Jiang, Shaohan Huang, Zhongzhi Luan, Deqing Wang, and Fuzhen Zhuang
-
[16]
Jiang, T., Huang, S., Luan, Z., Wang, D., and Zhuang, F
Scaling Sentence Embeddings with Large Language Models. InFindings of the Association for Computational Linguistics: EMNLP 2024, Yaser Al-Onaizan, Mo- hit Bansal, and Yun-Nung Chen (Eds.). Association for Computational Linguistics, Miami, Florida, USA, 3182–3196. doi:10.18653/v1/2024.findings-emnlp.181
-
[17]
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361(2020)
Pith/arXiv arXiv 2020
-
[18]
Aditya Kusupati, Gantavya Bhatt, Aniket Rege, Matthew Wallingford, Aditya Sinha, Vivek Ramanujan, William Howard-Snyder, Kaifeng Chen, Sham Kakade, Prateek Jain, et al. 2022. Matryoshka representation learning.Advances in Neural Information Processing Systems35 (2022), 30233–30249
2022
-
[19]
Yibin Lei, Di Wu, Tianyi Zhou, Tao Shen, Yu Cao, Chongyang Tao, and Andrew Yates. 2024. Meta-Task Prompting Elicits Embeddings from Large Language Models. InProceedings of the 62nd Annual Meeting of the Association for Computa- tional Linguistics (Volume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computational L...
-
[20]
Bohan Li, Hao Zhou, Junxian He, Mingxuan Wang, Yiming Yang, and Lei Li. 2020. On the Sentence Embeddings from Pre-trained Language Models. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 9119–9130
2020
-
[21]
Ziyue Li and Tianyi Zhou. 2025. Your Mixture-of-Experts LLM Is Secretly an Embedding Model for Free. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=eFGQ97z5Cd
2025
-
[22]
Ang Lv, Yuhan Chen, Kaiyi Zhang, Yulong Wang, Lifeng Liu, Ji-Rong Wen, Jian Xie, and Rui Yan. 2024. Interpreting Key Mechanisms of Factual Recall in Transformer-Based Language Models. arXiv:2403.19521 [cs.CL] https://arxiv. org/abs/2403.19521
arXiv 2024
-
[23]
Macedo Maia, Siegfried Handschuh, André Freitas, Brian Davis, Ross McDer- mott, Manel Zarrouk, and Alexandra Balahur. 2018. WWW’18 Open Challenge: Financial Opinion Mining and Question Answering. (2018), 1941–1942
2018
-
[24]
Niklas Muennighoff, Nouamane Tazi, Loic Magne, and Nils Reimers. 2023. MTEB: Massive Text Embedding Benchmark. InProceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, Andreas Vlachos and Isabelle Augenstein (Eds.). Association for Computational Linguistics, Dubrovnik, Croatia, 2014–2037. doi:10.18653/...
-
[25]
Zhijie Nie, Richong Zhang, and Zhanyu Wu. 2025. A Text is Worth Several Tokens: Text Embedding from LLMs Secretly Aligns Well with The Key Tokens. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (Eds.). Association...
-
[26]
R. Penrose. 1955. A generalized inverse for matrices.Proceedings of the Cambridge Philosophical Society51, 3 (1955), 406–413. doi:10.1017/S0305004100030784
-
[27]
Kirk Roberts, Tasmeer Alam, Steven Bedrick, Dina Demner-Fushman, Kyle Lo, Ian Soboroff, Ellen Voorhees, Lucy Lu Wang, and William R Hersh. 2021. Searching for Scientific Evidence in a Pandemic: An Overview of TREC-COVID. arXiv:2104.09632 [cs.IR]
arXiv 2021
-
[28]
Jacob Mitchell Springer, Suhas Kotha, Daniel Fried, Graham Neubig, and Aditi Raghunathan. 2025. Repetition Improves Language Model Embeddings. In The Thirteenth International Conference on Learning Representations. https: //openreview.net/forum?id=Ahlrf2HGJR
2025
-
[29]
Jianlin Su, Jiarun Cao, Weijie Liu, and Yangyiwen Ou. 2021. Whiten- ing Sentence Representations for Better Semantics and Faster Retrieval. arXiv:2103.15316 [cs.CL] https://arxiv.org/abs/2103.15316
arXiv 2021
-
[30]
Qwen Team. 2024. Qwen2.5: A Party of Foundation Models. https://qwenlm. github.io/blog/qwen2.5/
2024
-
[31]
Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. 2021. BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2). https://openreview. net/forum?id=wCu6T5xFjeJ
2021
-
[32]
Raghuveer Thirukovalluru and Bhuwan Dhingra. 2025. GenEOL: Harnessing the Generative Power of LLMs for Training-Free Sentence Embeddings. InFindings of the Association for Computational Linguistics: NAACL 2025, Luis Chiruzzo, Alan Ritter, and Lu Wang (Eds.). Association for Computational Linguistics, Albuquerque, New Mexico, 2295–2308. doi:10.18653/v1/202...
-
[33]
Henning Wachsmuth, Shahbaz Syed, and Benno Stein. 2018. Retrieval of the Best Counterargument without Prior Topic Knowledge. InACL
2018
-
[34]
David Wadden, Shanchuan Lin, Kyle Lo, Lucy Lu Wang, Madeleine van Zuylen, Arman Cohan, and Hannaneh Hajishirzi. 2020. Fact or Fiction: Verifying Scientific Claims. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, Online, 7534–7550. doi:10.18653/v1/2020.emnlp-main.609
-
[35]
text" denotes the sentences to be embedded. PromptEOL Qwen Summarize the sentence:
Maurice Weber, Daniel Fu, Quentin Anthony, Yonatan Oren, Shane Adams, Anton Alexandrov, Xiaozhong Lyu, Huu Nguyen, Xiaozhe Yao, Virginia Adams, Ben Athiwaratkun, Rahul Chalamala, Kezhen Chen, Max Ryabinin, Tri Dao, Percy Liang, Christopher Ré, Irina Rish, and Ce Zhang. 2024. RedPajama: an Open Dataset for Training Large Language Models. arXiv:2411.12372 [...
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.