Multilingual Refusal Alignment for Safer Large Language Models
Pith reviewed 2026-07-04 17:49 UTC · model glm-5.2
The pith
English-only safety training fails across languages
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
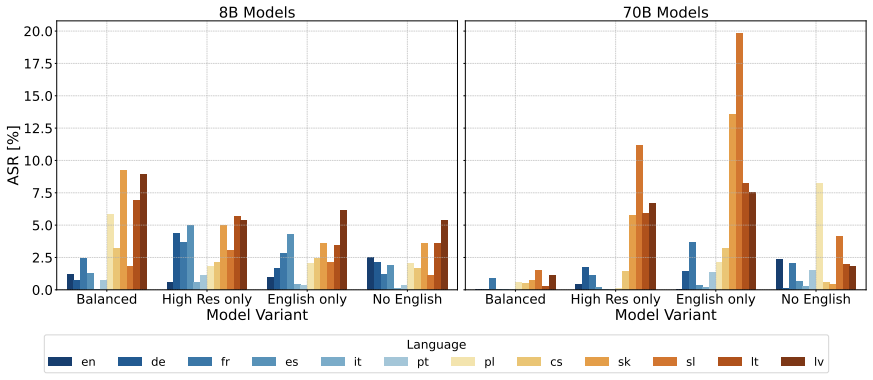
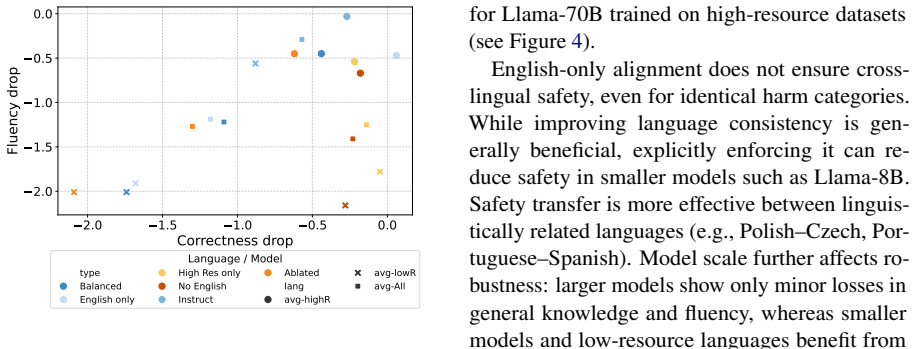
The central discovery is that safety alignment does not transfer cross-lingually from English alone: a model trained to refuse harmful English prompts will still comply with the same harmful prompts presented in lower-resourced European languages. When the authors instead train DPO on a balanced multilingual preference dataset across 12 languages, attack success rates drop to near-zero levels for the 70B model (0.47% average) and remain low for the 8B model (3.52% average), with negligible loss on general knowledge benchmarks. The authors also find that cross-lingual safety transfer is most effective between linguistically related languages, and that smaller models suffer disproportionate de
What carries the argument
Direct Preference Optimization (DPO) on safety-ablated models using the RefusEU dataset, a collection of over 4,000 preference pairs per language across 12 European languages, each containing a harmful prompt with a chosen safe refusal response and a rejected unsafe compliance response. Safety is measured by Attack Success Rate (ASR) computed via an ensemble of automated safety classifiers (Llama-Guard-3-8B, PolyGuard-Qwen, and GPT-4o-mini as adjudicator).
If this is right
- Multilingual safety alignment should become a standard requirement for any LLM deployed across languages, rather than relying on English-centric training to generalize.
- Low-resource European languages are the most vulnerable gap in current safety alignment, and dedicated training data for these languages is necessary to close it.
- Linguistic similarity between training and evaluation languages can be leveraged to prioritize which languages to include in alignment data when full coverage is impractical.
- The RefusEU dataset and evaluation protocol provide a reusable benchmark for measuring multilingual safety progress across European languages.
Load-bearing premise
The entire evaluation pipeline depends on automated safety classifiers to judge whether model outputs are safe or unsafe. If these classifiers are systematically stricter or more lenient in certain languages, the reported attack success rates could reflect classifier bias rather than genuine safety differences.
What would settle it
If independent human reviewers, fluent in each of the 12 languages, judged the model outputs and found that the ASR differences between English-only and multilingual training were substantially smaller than reported (or that the classifiers systematically mislabeled outputs in specific languages), the central claim would be undermined.
Figures






read the original abstract
As Large Language Models (LLMs) are deployed globally, ensuring their safety and alignment across multiple languages becomes paramount. However, safety behaviors often vary unpredictably between languages, posing significant challenges for consistent and ethical AI. In this work, we systematically investigate the dynamics of multilingual alignment, exploring whether single-language alignment transfers cross-lingually, how language consistency is preserved during training, and the resulting trade-offs with general knowledge capabilities. We introduce RefusEU, a novel refusal alignment dataset covering 12 European languages, including a dedicated test set for evaluating current state-of-the-art models. Our controlled Direct Preference Optimization (DPO) experiments provide two key insights: aligning models exclusively in English is insufficient to ensure cross-lingual safety, even for the same harm categories, whereas training on multilingual datasets can improve safety without degrading general performance, as measured by the Global MMLU benchmark.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper introduces RefusEU, a multilingual refusal alignment dataset covering 12 European languages, and uses controlled DPO experiments on ablated Llama-3.1-8B and 70B models to investigate whether English-only alignment suffices for cross-lingual safety. Four training configurations (balanced, high-resource only, English-only, no-English) plus 11 single-language runs are evaluated on ASR, language consistency, Global MMLU, and fluency/correctness. The central claims are: (1) English-only alignment is insufficient for cross-lingual safety, and (2) multilingual training improves safety without degrading general performance.
Significance. The paper addresses an important gap in multilingual LLM safety. The RefusEU dataset, covering 12 European languages with DPO-format preference pairs and a separate test split, is a useful contribution. The controlled experimental design—starting from ablated baselines and comparing multiple training configurations—provides a clean setup for studying alignment transfer. The inclusion of language consistency and fluency/correctness metrics alongside ASR and Global MMLU gives a multi-dimensional evaluation. The cross-lingual transfer analysis in Table 2, showing that linguistically related languages transfer more effectively, is a valuable empirical finding.
Simulated Author's Rebuttal
We thank the referee for the careful reading and positive assessment of our contributions. The referee report recommends major revision but does not enumerate specific major comments in the report provided to us—the 'MAJOR COMMENTS' section appears empty. We interpret the recommendation as reflecting concerns that are implicit in the referee's summary and significance assessment. Below we address the substantive points that can reasonably be inferred from the report, and we identify areas where the manuscript can be strengthened in revision.
read point-by-point responses
-
Referee: The referee report recommends 'major_revision' but the MAJOR COMMENTS section is empty, so we infer concerns from the summary and significance text. One likely concern is that the manuscript could better contextualize RefusEU relative to existing multilingual safety datasets and more clearly articulate the novel contribution beyond dataset release.
Authors: We agree that the related work section, while reasonably comprehensive, could more sharply position RefusEU against existing datasets. In particular, we will expand the comparison to explicitly note that RefusEU is, to our knowledge, the first European-focused dataset providing DPO-format preference triples (question, chosen, rejected) with a dedicated test split across 12 languages, and we will clarify how this differs from evaluation-only datasets (PolygloToxicityPrompts, RTP-LX, SORRY-Bench) and from the training datasets introduced by Aakanksha et al. (2024) and Deng et al. (2024). We will also add a summary table comparing existing multilingual safety datasets on dimensions such as language coverage, format (prompts vs. preference pairs), train/test split availability, and intended use (evaluation vs. training). This should make the contribution clearer. revision: yes
-
Referee: A second likely concern is methodological transparency: the ablation procedure was performed externally, and the manuscript should clarify the reproducibility and reliability of the ablated baselines.
Authors: We acknowledge this is a valid concern. The ablated models (NeuralDaredevil-8B-abliterated and Llama-3.1-70B-Instruct-lorablated) were adopted from publicly available sources, and we did not perform the ablation ourselves. In revision, we will add a paragraph in Section 4.1 that explicitly discusses this limitation: we will note the source of each ablated model, describe the ablation method at a higher level of detail (refusal direction identification and weight modification as per Arditi et al., 2024), and acknowledge that differences in ablation methodology could affect baseline ASR. We will also note that the high initial ASR scores across all languages (Table 1) confirm that the safety mechanisms were effectively disabled, which is the property we require for our experimental setup. revision: yes
-
Referee: A third likely concern is the evaluation methodology: ASR is computed using an ensemble of Llama-Guard-3-8B, PolyGuard-Qwen, and GPT-4o-mini as adjudicator, and the reliability of this pipeline should be discussed more thoroughly.
Authors: This is a fair point. We provide inter-annotator agreement results (Figure 2, Cohen's Kappa) but do not extensively discuss the limitations of LLM-as-judge for safety classification, particularly for low-resource languages. In revision, we will add a discussion in Section 4.5 noting that (1) the agreement between Llama-Guard-3-8B and PolyGuard-Qwen exceeds 90% on identical labels across the evaluated samples, (2) the stricter dual-agreement criterion for the training set reduces false positives, and (3) we acknowledge that LLM-based safety classifiers may have language-specific biases, particularly for Slavic and Baltic languages. We will also note that the manual audit (Appendix C.2, 1,200 samples) confirmed 100% precision on chosen-response safety labels, providing a human-validated floor on label quality. revision: yes
-
Referee: A fourth likely concern is the generalizability of findings beyond the two Llama model families studied.
Authors: We agree that our training experiments are limited to Llama-3.1-8B and 70B. While we do evaluate seven additional open-access models on the RefusEU test set (Section 5.5, Table 16), we do not conduct DPO training experiments on these models. In revision, we will explicitly state this as a limitation in the Limitations section and frame it as future work. We note that the cross-lingual transfer patterns observed in Table 2 (linguistically related languages transfer more effectively) are consistent with findings from Kanepajs et al. (2024) on GPT-4o and Mistral Large 2, suggesting the phenomenon is not model-specific, though we cannot confirm this for the training dynamics without additional experiments. revision: partial
-
Referee: A fifth likely concern is that the manuscript's claims about 'not degrading general performance' should be qualified, given that Table 3 shows some per-language drops (e.g., Portuguese for 70B, Korean for 8B).
Authors: We accept that the claim should be stated more precisely. The average Global MMLU performance drop across all languages is below 0.006 for both model sizes, but individual languages do show larger fluctuations. In revision, we will qualify the claim in the abstract and findings to state that multilingual training 'does not substantially degrade general performance on average, as measured by Global MMLU,' and we will note the specific exceptions (Portuguese for 70B, Korean for one 8B run) in the results section. We will also add a note that these per-language variations are within the range of typical DPO training noise for models of this scale. revision: yes
-
Referee: A sixth likely concern is the dataset's entirely synthetic generation and the potential for cultural or linguistic bias in the generated prompts.
Authors: We already acknowledge this in the Limitations section, but we can strengthen the discussion. In revision, we will add a note that the crime categories are derived from the Llama-Guard taxonomy (which is English-centric in its design) and that the attack styles follow the Rainbow teaming methodology. We will also note that the manual audit (Appendix C.2) showed high topic relevance (Q2: 99-100% across languages) but variable style adherence (Q3: 61-88%), which we attribute to the instruction to apply styles only when contextually appropriate. We will add a discussion of the risk that synthetic generation may not capture culture-specific harms that differ across European countries, and frame multilingual cultural adaptation as important future work. revision: yes
- The referee report's MAJOR COMMENTS section is empty. We have responded to the concerns we could reasonably infer from the summary and significance assessment, but if there are specific major comments that were intended but not transmitted to us, we would welcome the opportunity to address them directly.
Circularity Check
Same classifiers used for dataset construction and evaluation, but external benchmarks and manual audit partially break the circularity.
specific steps
-
fitted input called prediction
[§3 (Dataset construction) and §4.5 (Evaluation)]
"questions labeled as unsafe by both the Llama-Guard-3-8B and PolyGuard-Qwen models were retained [...] only pairs in which the refusal answers were consistently marked as safe (by Llama-Guard-3-8B and Polyguard-Qwen) and the compliance responses were labeled as unsafe (by at least one of the two guard models) were retained. [...] The final ASR score was computed by first generating predictions using Llama-Guard-3-8B and PolyGuard-Qwen. In cases where the outputs of these two models diverged, GPT-4o-mini [...] was employed as an adjudicator"
The same two classifiers (Llama-Guard-3-8B and PolyGuard-Qwen) are used to construct the DPO training data (filtering chosen/rejected pairs) and to evaluate the trained models (computing ASR). DPO optimizes the model to produce responses on the 'safe' side of these classifiers' decision boundaries; the evaluation then measures success using those same boundaries. If the classifiers share a systematic blind spot in a language, the model could learn to exploit it, yielding artificially low ASR. However, this is partially mitigated: (1) RTP-LX and PolygloToxicityPrompts are external benchmarks not constructed by the authors, and (2) a manual audit (Table 8) validates dataset quality. The circularity is real but partial, not total.
full rationale
The paper has a genuine methodological overlap: the same automated classifiers define the training signal and the evaluation metric. This is a structural weakness. However, the central claim—that English-only alignment is insufficient for cross-lingual safety—is tested against external benchmarks (RTP-LX, PolygloToxicityPrompts, Global MMLU) that are not constructed by the authors. The manual audit (Table 8) independently validates the 'chosen' responses as safe refusals across all 1,200 samples. The train/test split is by category-style group to prevent contamination. The circularity does not reduce the central claim to a tautology; it introduces a shared-method bias risk that the paper partially acknowledges (Figure 2) but does not fully analyze. Score 2 reflects that this is a methodological concern, not a definitional equivalence.
Axiom & Free-Parameter Ledger
free parameters (4)
- DPO beta =
0.1
- learning_rate =
1e-6
- num_train_epochs =
3
- test set size per category =
100
axioms (5)
- domain assumption Automated safety classifiers (Llama-Guard-3-8B, PolyGuard-Qwen, GPT-4o-mini) can reliably determine whether a model response is safe or unsafe across all 12 tested languages.
- domain assumption Refusal abliteration (removing the refusal direction from model weights) produces a clean baseline where safety mechanisms are genuinely disabled, rather than merely weakened.
- domain assumption Global MMLU is a valid proxy for general multilingual capabilities that could be degraded by safety alignment.
- domain assumption Synthetic adversarial prompts generated via the Rainbow teaming methodology (Samvelyan et al., 2024) are representative of real-world harmful queries across all 12 languages.
- standard math DPO on preference pairs (refusal vs. compliance) is an appropriate method for instilling multilingual safety alignment.
Reference graph
Works this paper leans on
-
[1]
Rainbow-Teaming for the P olish Language: A Reproducibility Study
Krasnod e bska, Aleksandra and Chrabaszcz, Maciej and Kusa, Wojciech. Rainbow-Teaming for the P olish Language: A Reproducibility Study. Proceedings of the 5th Workshop on Trustworthy NLP (TrustNLP 2025). 2025
work page 2025
-
[2]
Rainbow Teaming: Open-Ended Generation of Diverse Adversarial Prompts , author=. 2024 , eprint=
work page 2024
- [3]
-
[4]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
work page 2024
-
[5]
ORPO: Monolithic Preference Optimization without Reference Model , author=. 2024 , eprint=
work page 2024
-
[6]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. 2024 , eprint=
work page 2024
-
[7]
An Embarrassingly Simple Defense Against LLM Abliteration Attacks , author=. 2025 , eprint=
work page 2025
-
[8]
Refusal in Language Models Is Mediated by a Single Direction , author=. 2024 , eprint=
work page 2024
-
[9]
All Languages Matter: On the Multilingual Safety of Large Language Models , author=. 2024 , eprint=
work page 2024
-
[10]
Benchmarking LLM Guardrails in Handling Multilingual Toxicity , author=. 2024 , eprint=
work page 2024
-
[11]
CIVICS: Building a Dataset for Examining Culturally-Informed Values in Large Language Models , author=. 2024 , eprint=
work page 2024
-
[12]
Code-Switching Red-Teaming: LLM Evaluation for Safety and Multilingual Understanding , author=. 2025 , eprint=
work page 2025
-
[13]
From One to Many: Expanding the Scope of Toxicity Mitigation in Language Models
Ermis, Beyza and Pozzobon, Luiza and Hooker, Sara and Lewis, Patrick. From One to Many: Expanding the Scope of Toxicity Mitigation in Language Models. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.893
-
[15]
Language Model Alignment in Multilingual Trolley Problems , author=. 2025 , eprint=
work page 2025
-
[17]
arXiv preprint arXiv:2412.15035 , year=
LLMs Lost in Translation: M-ALERT uncovers Cross-Linguistic Safety Gaps , author=. arXiv preprint arXiv:2412.15035 , year=
-
[18]
Low-Resource Languages Jailbreak GPT-4 , author=
-
[20]
S-Eval: Towards Automated and Comprehensive Safety Evaluation for Large Language Models , author=. 2025 , eprint=
work page 2025
-
[21]
Multilingual Blending: Large Language Model Safety Alignment Evaluation with Language Mixture
Song, Jiayang and Huang, Yuheng and Zhou, Zhehua and Ma, Lei. Multilingual Blending: Large Language Model Safety Alignment Evaluation with Language Mixture. Findings of the Association for Computational Linguistics: NAACL 2025. 2025
work page 2025
-
[22]
The Twelfth International Conference on Learning Representations , year=
Multilingual Jailbreak Challenges in Large Language Models , author=. The Twelfth International Conference on Learning Representations , year=
- [23]
-
[24]
First Conference on Language Modeling , year=
PolygloToxicityPrompts: Multilingual Evaluation of Neural Toxic Degeneration in Large Language Models , author=. First Conference on Language Modeling , year=
-
[25]
PolyGuard: A Multilingual Safety Moderation Tool for 17 Languages , author=. 2025 , eprint=
work page 2025
-
[28]
The Thirteenth International Conference on Learning Representations , year=
Sorry-bench: Systematically evaluating large language model safety refusal , author=. The Thirteenth International Conference on Learning Representations , year=
-
[31]
Workshop on Socially Responsible Language Modelling Research , year=
Towards Safe Multilingual Frontier AI , author=. Workshop on Socially Responsible Language Modelling Research , year=
-
[32]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Women Are Beautiful, Men Are Leaders: Gender Stereotypes in Machine Translation and Language Modeling , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
work page 2024
-
[33]
XTRUST: On the Multilingual Trustworthiness of Large Language Models , author=. 2024 , eprint=
work page 2024
-
[34]
The State of Multilingual LLM Safety Research: From Measuring the Language Gap to Mitigating It , author=. 2025 , eprint=
work page 2025
-
[35]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Safetyprompts: a systematic review of open datasets for evaluating and improving large language model safety , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[38]
Training language models to follow instructions with human feedback , author=. 2022 , eprint=
work page 2022
-
[39]
A General Language Assistant as a Laboratory for Alignment , author=. 2021 , eprint=
work page 2021
-
[41]
Aakanksha, Arash Ahmadian, Beyza Ermis, Seraphina Goldfarb-Tarrant, Julia Kreutzer, Marzieh Fadaee, and Sara Hooker. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.671 The multilingual alignment prism: Aligning global and local preferences to reduce harm . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages ...
-
[42]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, and 1 others. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. 2024. https://arxiv.org/abs/2406.11717 Refusal in language models is mediated by a single direction . Preprint, arXiv:2406.11717
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Amanda Askell, Yuntao Bai, Anna Chen, Dawn Drain, Deep Ganguli, Tom Henighan, Andy Jones, Nicholas Joseph, Ben Mann, Nova DasSarma, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Jackson Kernion, Kamal Ndousse, Catherine Olsson, Dario Amodei, Tom Brown, Jack Clark, and 3 others. 2021. https://arxiv.org/abs/2112.00861 A general language assistant as a...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[45]
Rishabh Bhardwaj, Duc Anh Do, and Soujanya Poria. 2024. https://doi.org/10.18653/v1/2024.acl-long.762 Language models are H omer simpson! safety re-alignment of fine-tuned language models through task arithmetic . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14138--14149, Bangkok...
-
[46]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, and 1 others. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Adrian De Wynter, Ishaan Watts, Tua Wongsangaroonsri, Minghui Zhang, Noura Farra, Nektar Ege Altıntoprak, Lena Baur, Samantha Claudet, Pavel Gajdušek, Qilong Gu, Anna Kaminska, Tomasz Kaminski, Ruby Kuo, Akiko Kyuba, Jongho Lee, Kartik Mathur, Petter Merok, Ivana Milovanović, Nani Paananen, and 13 others. 2025. https://doi.org/10.1609/aaai.v39i27.35011 Rt...
-
[48]
Yue Deng, Wenxuan Zhang, Sinno Jialin Pan, and Lidong Bing. 2024. Multilingual jailbreak challenges in large language models. In The Twelfth International Conference on Learning Representations
work page 2024
-
[49]
Emman Haider, Daniel Perez-Becker, Thomas Portet, Piyush Madan, Amit Garg, Atabak Ashfaq, David Majercak, Wen Wen, Dongwoo Kim, Ziyi Yang, Jianwen Zhang, Hiteshi Sharma, Blake Bullwinkel, Martin Pouliot, Amanda Minnich, Shiven Chawla, Solianna Herrera, Shahed Warreth, Maggie Engler, and 12 others. 2024. https://arxiv.org/abs/2407.13833 Phi-3 safety post-t...
-
[50]
Jiwoo Hong, Noah Lee, and James Thorne. 2024. https://arxiv.org/abs/2403.07691 Orpo: Monolithic preference optimization without reference model . Preprint, arXiv:2403.07691
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
Devansh Jain, Priyanshu Kumar, Samuel Gehman, Xuhui Zhou, Thomas Hartvigsen, and Maarten Sap. 2024. Polyglotoxicityprompts: Multilingual evaluation of neural toxic degeneration in large language models. In First Conference on Language Modeling
work page 2024
-
[52]
Arturs Kanepajs, Vladimir Ivanov, and Richard Moulange. 2024. Towards safe multilingual frontier ai. In Workshop on Socially Responsible Language Modelling Research
work page 2024
-
[53]
Aleksandra Krasnod e bska, Maciej Chrabaszcz, and Wojciech Kusa. 2025. https://aclanthology.org/2025.trustnlp-main.12/ Rainbow-teaming for the P olish language: A reproducibility study . In Proceedings of the 5th Workshop on Trustworthy NLP (TrustNLP 2025), pages 155--165, Albuquerque, New Mexico. Association for Computational Linguistics
work page 2025
-
[54]
Aleksandra Krasnod e bska, Katarzyna Dziewulska, Karolina Seweryn, Maciej Chrabaszcz, and Wojciech Kusa. 2026. https://doi.org/10.18653/v1/2026.eacl-long.44 Safety of large language models beyond E nglish: A systematic literature review of risks, biases, and safeguards . In Proceedings of the 19th Conference of the E uropean Chapter of the A ssociation fo...
- [55]
-
[56]
Debora Nozza, Federico Bianchi, and Dirk Hovy. 2021. https://doi.org/10.18653/v1/2021.naacl-main.191 HONEST : Measuring hurtful sentence completion in language models . In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2398--2406, Online. Association for...
-
[57]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. 2022. https://arxiv.org/abs/2203.02155 Training language models to f...
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [58]
-
[59]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. 2024. https://arxiv.org/abs/2305.18290 Direct preference optimization: Your language model is secretly a reward model . Preprint, arXiv:2305.18290
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[60]
Paul R \"o ttger, Fabio Pernisi, Bertie Vidgen, and Dirk Hovy. 2025. Safetyprompts: a systematic review of open datasets for evaluating and improving large language model safety. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 27617--27627
work page 2025
-
[61]
Mikayel Samvelyan, Sharath Chandra Raparthy, Andrei Lupu, Eric Hambro, Aram H. Markosyan, Manish Bhatt, Yuning Mao, Minqi Jiang, Jack Parker-Holder, Jakob Foerster, Tim Rocktäschel, and Roberta Raileanu. 2024. https://arxiv.org/abs/2402.16822 Rainbow teaming: Open-ended generation of diverse adversarial prompts . Preprint, arXiv:2402.16822
-
[62]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. https://arxiv.org/abs/1707.06347 Proximal policy optimization algorithms . Preprint, arXiv:1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [63]
-
[64]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. https://arxiv.org/abs/2402.03300 Deepseekmath: Pushing the limits of mathematical reasoning in open language models . Preprint, arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[65]
Shivalika Singh, Angelika Romanou, Cl \'e mentine Fourrier, David Ifeoluwa Adelani, Jian Gang Ngui, Daniel Vila-Suero, Peerat Limkonchotiwat, Kelly Marchisio, Wei Qi Leong, Yosephine Susanto, Raymond Ng, Shayne Longpre, Sebastian Ruder, Wei-Yin Ko, Antoine Bosselut, Alice Oh, Andre Martins, Leshem Choshen, Daphne Ippolito, and 4 others. 2025. https://doi....
-
[66]
Abhishek Singhania, Christophe Dupuy, Shivam Sadashiv Mangale, and Amani Namboori. 2025. https://doi.org/10.18653/v1/2025.trustnlp-main.11 Multi-lingual multi-turn automated red teaming for LLM s . In Proceedings of the 5th Workshop on Trustworthy NLP (TrustNLP 2025), pages 141--154, Albuquerque, New Mexico. Association for Computational Linguistics
- [67]
- [68]
-
[69]
Tinghao Xie, Xiangyu Qi, Yi Zeng, Yangsibo Huang, Udari Madhushani Sehwag, Kaixuan Huang, Luxi He, Boyi Wei, Dacheng Li, Ying Sheng, and 1 others. 2025. Sorry-bench: Systematically evaluating large language model safety refusal. In The Thirteenth International Conference on Learning Representations
work page 2025
-
[70]
Zheng-Xin Yong, Beyza Ermis, Marzieh Fadaee, Stephen H. Bach, and Julia Kreutzer. 2025. https://arxiv.org/abs/2505.24119 The state of multilingual llm safety research: From measuring the language gap to mitigating it . Preprint, arXiv:2505.24119
- [71]
-
[72]
Xiaohan Yuan, Jinfeng Li, Dongxia Wang, Yuefeng Chen, Xiaofeng Mao, Longtao Huang, Jialuo Chen, Hui Xue, Xiaoxia Liu, Wenhai Wang, Kui Ren, and Jingyi Wang. 2025. https://arxiv.org/abs/2405.14191 S-eval: Towards automated and comprehensive safety evaluation for large language models . Preprint, arXiv:2405.14191
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.