Beyond Item IDs: Scaling Short-Form-Video Recommendation via Semantic-Native Long Sequence Modeling
Pith reviewed 2026-07-01 00:49 UTC · model grok-4.3
The pith
Semantic IDs paired with a compression transformer let recommendation systems model much longer user histories at production scale.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
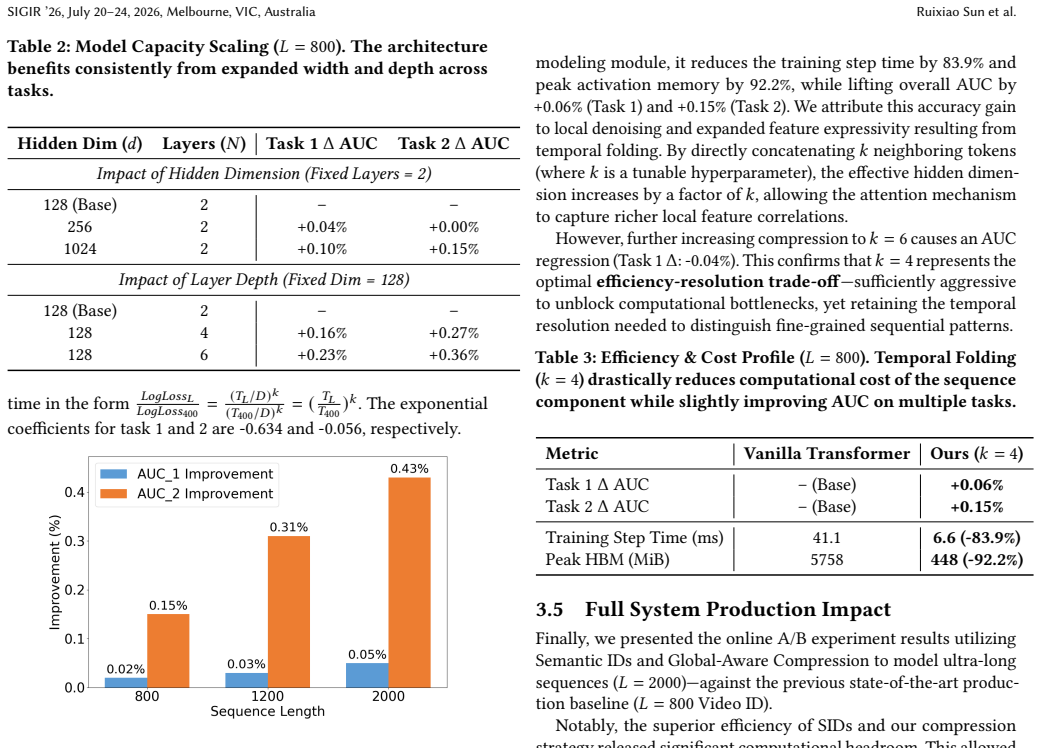
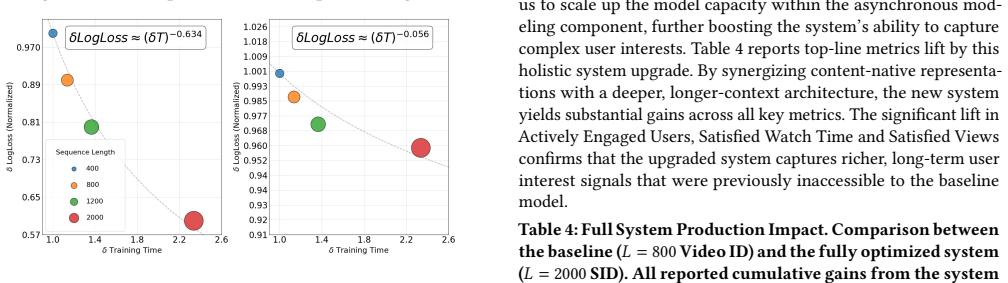
By adopting content-native Semantic IDs that are depth-truncated to coarse granularity, the framework reduces embedding table size from corpus cardinality while enabling generalization to cold-start items through shared prefixes; the Global-Aware Compression Transformer then applies non-parametric temporal folding and unified global query integration to condense long sequences, removing both the representation sparsity and quadratic attention barriers so that longer user histories can be modeled at affordable cost.
What carries the argument
The Global-Aware Compression Transformer, which condenses sequences via non-parametric temporal folding and unified global query integration to alleviate quadratic self-attention costs.
If this is right
- Sequence lengths that were previously infeasible become affordable under fixed latency and resource budgets.
- Cold-start content receives useful representations from shared semantic prefixes without separate training.
- Embedding tables shrink from the size of the full item corpus to a much smaller semantic vocabulary.
- Offline profiling shows order-of-magnitude drops in peak memory and computational overhead.
- Large-scale online tests record gains in satisfied user engagement and satisfied content consumption.
Where Pith is reading between the lines
- The same folding and global-query mechanism could be applied to other high-volume sequence tasks such as session modeling or news recommendation.
- Because Semantic IDs are derived from content features, the approach may reduce dependence on item-specific interaction data for new catalogs.
- Access to longer histories could surface slower-changing preference patterns that short windows overlook.
- The compression ratio achieved may allow even longer sequences if additional non-parametric reductions are layered on top.
Load-bearing premise
Depth-truncated Semantic IDs retain enough content relationships to beat atomic Video IDs, and the folding plus global query steps preserve the user-interest signals required for ranking.
What would settle it
A controlled production A/B test in which the Semantic ID and compression components are turned off shows no lift in satisfied engagement or content consumption metrics.
Figures


read the original abstract
Capturing user interests across extensive watch histories is critical for short-form video recommendation, yet scaling sequence length is limited by two bottlenecks: the semantic sparsity of atomic Video IDs and the quadratic computational complexity of Transformers. Traditional orthogonal Video IDs fail to capture content relationships and demand large embedding tables, while the quadratic complexity of self-attention restricts the maximum sequence length under strict industrial latency and resource constraints. In this work, we present a production-deployed framework for modeling ultra-long user behavior sequences at a billion-user scale. We first address the representation bottleneck by adopting content-native Semantic IDs. By utilizing depth-truncated, coarse-grained Semantic IDs, we shrink the embedding table size from corpus cardinality. This compact representation naturally generalizes to cold-start content through shared semantic prefixes. Second, to overcome the sequence scaling barrier, we introduce a Global-Aware Compression Transformer that leverages non-parametric temporal folding and unified global query integration to effectively condense the sequence, alleviating both the memory and computational bottlenecks of standard self-attention. Offline profiling on our computing infrastructure demonstrates an order-of-magnitude reduction in peak memory footprint and a drastic decrease in computational overhead. This efficiency gain enables supporting longer sequence lengths at an affordable cost in production, yielding substantial online gains in satisfied user engagement and satisfied content consumption in large-scale online A/B tests.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to address two bottlenecks in short-form video recommendation—semantic sparsity of atomic Video IDs and quadratic complexity of Transformers—via depth-truncated Semantic IDs that shrink embedding tables and generalize to cold-start items, plus a Global-Aware Compression Transformer using non-parametric temporal folding and global query integration to condense sequences. It reports an order-of-magnitude memory reduction from offline profiling and substantial gains in satisfied user engagement and content consumption from large-scale online A/B tests.
Significance. If the efficiency and engagement claims hold with supporting evidence, the work would be significant for industrial recommender systems by enabling affordable ultra-long sequence modeling at billion-user scale. The semantic-native representation for cold-start generalization is a clear strength if empirically validated.
major comments (3)
- [Abstract] Abstract: the central claims of 'order-of-magnitude reduction in peak memory footprint' and 'substantial online gains' are asserted without any quantitative results, baselines, ablation studies, or error analysis, which is load-bearing for the efficiency and engagement assertions.
- [Description of the two bottlenecks and proposed solutions] Description of the two bottlenecks and proposed solutions: the claim that depth-truncated Semantic IDs preserve enough content relationships to improve over atomic Video IDs lacks any ablation on embedding granularity or direct comparison, undermining the representation-bottleneck solution.
- [Description of the two bottlenecks and proposed solutions] Description of the two bottlenecks and proposed solutions: no analysis is supplied of what temporal information is discarded by non-parametric temporal folding, which is required to confirm that critical user-interest signals are retained after condensation.
minor comments (1)
- [Abstract] The abstract would be strengthened by including at least one concrete metric (e.g., memory reduction factor or A/B lift percentage) even if detailed tables appear later.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below with clarifications from the manuscript and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of 'order-of-magnitude reduction in peak memory footprint' and 'substantial online gains' are asserted without any quantitative results, baselines, ablation studies, or error analysis, which is load-bearing for the efficiency and engagement assertions.
Authors: The abstract summarizes findings whose quantitative details appear in Sections 4 (Offline Profiling) and 5 (Online A/B Tests), which report the memory reduction factor, computational overhead decrease, and engagement lifts relative to production baselines together with statistical significance. We will revise the abstract to include the key quantitative figures and explicit references to those sections. revision: yes
-
Referee: [Description of the two bottlenecks and proposed solutions] Description of the two bottlenecks and proposed solutions: the claim that depth-truncated Semantic IDs preserve enough content relationships to improve over atomic Video IDs lacks any ablation on embedding granularity or direct comparison, undermining the representation-bottleneck solution.
Authors: The experimental sections already contain head-to-head comparisons of depth-truncated Semantic IDs against atomic Video IDs, demonstrating gains in cold-start handling and overall metrics. While an exhaustive granularity ablation is not present, the chosen truncation depth is justified by the resulting table-size reduction and end-to-end performance. We will add a concise ablation table on truncation depth in the revised manuscript. revision: yes
-
Referee: [Description of the two bottlenecks and proposed solutions] Description of the two bottlenecks and proposed solutions: no analysis is supplied of what temporal information is discarded by non-parametric temporal folding, which is required to confirm that critical user-interest signals are retained after condensation.
Authors: The Global-Aware Compression Transformer description explains that non-parametric folding is combined with global-query integration precisely to retain long-range interest signals; the offline and online results serve as empirical confirmation that critical signals are preserved. A dedicated analysis of discarded temporal components is not included; we will add a short discussion of folding's effect on sequence statistics and interest retention in the revision. revision: partial
Circularity Check
No circularity; methods are independent responses to explicitly stated bottlenecks
full rationale
The paper presents depth-truncated Semantic IDs and the Global-Aware Compression Transformer (with non-parametric temporal folding and global query integration) as direct engineering responses to the two named bottlenecks of semantic sparsity and quadratic self-attention cost. No equations, fitted parameters, or predictions are shown that reduce claimed efficiency or online gains to internal definitions or self-citations. The abstract and description treat both components as external, falsifiable improvements over atomic Video IDs and standard Transformers, with gains validated by offline profiling and A/B tests rather than by construction. This is the normal case of a self-contained applied systems paper.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Self-attention has quadratic computational complexity with sequence length
invented entities (2)
-
Semantic IDs
no independent evidence
-
Global-Aware Compression Transformer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Zheng Chai, Qin Ren, Xijun Xiao, Huizhi Yang, Bo Han, Sijun Zhang, Di Chen, Hui Lu, Wenlin Zhao, Lele Yu, et al . 2025. Longer: Scaling up long sequence modeling in industrial recommenders. InProceedings of the Nineteenth ACM Conference on Recommender Systems. 247–256
2025
-
[2]
Jianxin Chang, Chenbin Zhang, Zhiyi Fu, Xiaoxue Zang, Lin Guan, Jing Lu, Yiqun Hui, Dewei Leng, Yanan Niu, Yang Song, et al. 2023. TWIN: TWo-stage interest network for lifelong user behavior modeling in CTR prediction at kuaishou. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 3785–3794
2023
-
[3]
Qiwei Chen, Huan Zhao, Wei Li, Pipei Huang, and Wenwu Ou. 2019. Behavior sequence transformer for e-commerce recommendation in alibaba. InProceedings of the 1st international workshop on deep learning practice for high-dimensional sparse data. 1–4
2019
-
[4]
Zhimin Chen, Chenyu Zhao, Ka Chun Mo, Yunjiang Jiang, Jane H Lee, Shouwei Chen, Khushhall Chandra Mahajan, Ning Jiang, Kai Ren, Jinhui Li, et al . 2025. Massive Memorization with Hundreds of Trillions of Parameters for Sequential Transducer Generative Recommenders.arXiv preprint arXiv:2510.22049(2025)
-
[5]
Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep Neural Networks for YouTube Recommendations. InProceedings of the 10th ACM Conference on Recommender Systems. ACM, 191–198
2016
-
[6]
Tim Donkers, Benedikt Loepp, and Jürgen Ziegler. 2017. Sequential user-based recurrent neural network recommendations. InProceedings of the eleventh ACM conference on recommender systems. 152–160
2017
- [7]
-
[8]
Ruining He, Lukasz Heldt, Lichan Hong, Raghunandan Keshavan, Shifan Mao, Nikhil Mehta, Zhengyang Su, Alicia Tsai, Yueqi Wang, Shao-Chuan Wang, et al
- [9]
-
[10]
Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk
-
[11]
In International Conference on Learning Representations (ICLR)
Session-based Recommendations with Recurrent Neural Networks. In International Conference on Learning Representations (ICLR)
- [12]
-
[13]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recom- mendation. In2018 IEEE international conference on data mining (ICDM). IEEE, 197–206
2018
-
[14]
Yuening Li, Diego Uribe, Chuan He, Jiaxi Tang, Qingyun Liu, Junjie Shan, Ben Most, Kaushik Kalyan, Shuchao Bi, Xinyang Yi, et al. 2024. Short-form Video Needs Long-term Interests: An Industrial Solution for Serving Large User Se- quence Models. InProceedings of the 18th ACM Conference on Recommender Systems. 832–834
2024
-
[15]
Wenhan Lyu, Devashish Tyagi, Yihang Yang, Ziwei Li, Ajay Somani, Karthikeyan Shanmugasundaram, Nikola Andrejevic, Ferdi Adeputra, Curtis Zeng, Arun K Singh, et al. 2025. DV365: Extremely Long User History Modeling at Instagram. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 4717–4727
2025
-
[16]
Qi Pi, Guorui Zhou, Yujing Zhang, Zhe Wang, Lejian Ren, Ying Fan, Xiaoqiang Zhu, and Kun Gai. 2020. Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction. InProceedings of the 29th ACM International Conference on Information & Knowledge Management. 2685–2692
2020
-
[17]
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Tran, Jonah Samost, et al
-
[18]
Recommender systems with generative retrieval.Advances in Neural Information Processing Systems36 (2023), 10299–10315
2023
-
[19]
Zihua Si, Lin Guan, ZhongXiang Sun, Xiaoxue Zang, Jing Lu, Yiqun Hui, Xingchao Cao, Zeyu Yang, Yichen Zheng, Dewei Leng, Kai Zheng, Chenbin Zhang, Yanan Niu, Yang Song, and Kun Gai. 2024. TWIN V2: Scaling Ultra-Long User Behavior Sequence Modeling for Enhanced CTR Prediction at Kuaishou. InProceedings of the 33rd ACM International Conference on Informatio...
-
[20]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang
-
[21]
InProceedings of the 28th ACM international conference on information and knowledge management
BERT4Rec: Sequential recommendation with bidirectional encoder rep- resentations from transformer. InProceedings of the 28th ACM international conference on information and knowledge management. 1441–1450
-
[22]
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis
-
[23]
Efficient streaming language models with attention sinks.arXiv preprint arXiv:2309.17453(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhao- jie Gong, Fangda Gu, Michael He, et al. 2024. Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations.arXiv preprint arXiv:2402.17152(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [25]
-
[26]
Guorui Zhou, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, and Kun Gai. 2019. Deep interest evolution network for click-through rate prediction. InProceedings of the AAAI conference on artificial intelligence, Vol. 33. 5941–5948
2019
-
[27]
Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep interest network for click-through rate prediction. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1059–1068
2018
-
[28]
Han Zhu, Xiang Li, Pengye Zhang, Guozheng Li, Jie He, Han Li, and Kun Gai
-
[29]
InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining
Learning tree-based deep model for recommender systems. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1079–1088
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.