SlideCheck: Guiding Self-Supervised Pretraining of Pathology Foundation Models via Dataset Distributions
Pith reviewed 2026-06-29 08:43 UTC · model grok-4.3
The pith
SlideCheck scores on frozen features let researchers select pathology pretraining patches by abnormality and malignancy to control biological composition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
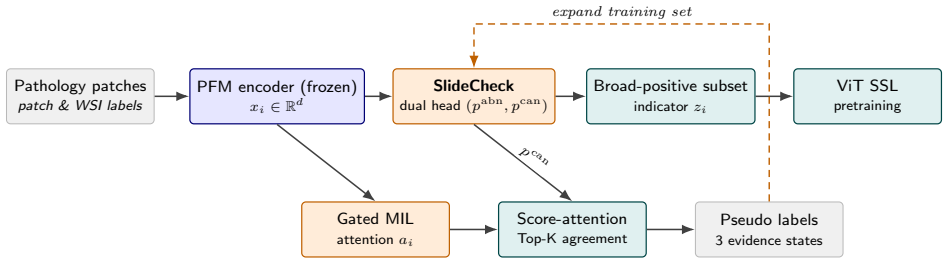
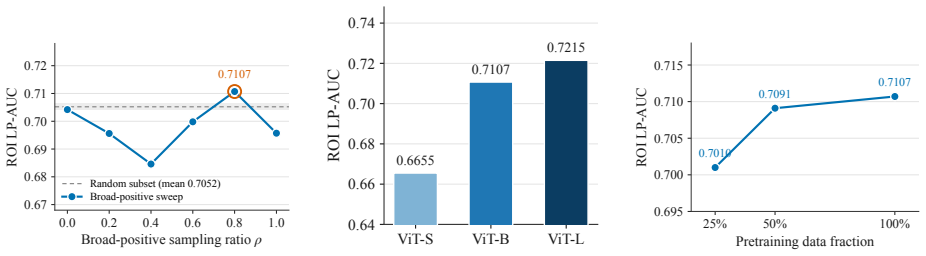
SlideCheck uses a dual-head MLP to model broad abnormal morphology and malignant evidence separately, with a regularized feature-space scorer and score-attention agreement to mine high-confidence pseudo labels. These scores construct broad-positive ViT pretraining subsets by selecting patches where either score exceeds a threshold. The resulting data distributions influence downstream self-supervised pretraining behavior, with curated subsets approaching full-data performance and indicating that biological composition is a controllable factor in pathology foundation model development.
What carries the argument
Dual-head MLP that separately scores abnormal morphology and malignant evidence, combined with score-attention agreement for pseudo-label mining to guide subset construction.
If this is right
- SlideCheck-defined data distributions influence the downstream behavior of self-supervised ViT pretraining.
- Curated subsets can approach full-data performance.
- Explicitly scored patch pools support more efficient and auditable pretraining data construction.
- Biological composition is an important controllable factor in pathology foundation model development.
Where Pith is reading between the lines
- Researchers could use similar scoring to audit existing pretraining datasets for unintended biological biases.
- Targeted inclusion of specific abnormality levels might improve model robustness to rare cases.
- This method could extend to other imaging domains where patch-level supervision is sparse.
Load-bearing premise
The dual-head MLP scores and score-attention agreement produce reliable patch-level evidence of abnormality and malignancy that can be used to construct pretraining subsets without introducing selection bias or missing key biological patterns.
What would settle it
Training self-supervised ViT models on SlideCheck-curated subsets and finding they consistently underperform models trained on the full dataset or on randomly selected subsets of the same size.
Figures
read the original abstract
Pathology foundation models are pretrained on large streams of WSI-derived patches, while supervision during data construction is often slide-level, sparse, or heterogeneous. This mismatch makes it difficult to understand and control which biological patterns enter the pretraining data. We propose SlideCheck, a lightweight pretraining data guidance tool built on frozen pathology foundation model patch features. Rather than serving as a standalone patch diagnostic model, SlideCheck provides explicit abnormality and malignancy scores for organizing, filtering, and auditing pathology pretraining data. SlideCheck uses a dual-head MLP to separately model broad abnormal morphology and malignant evidence. A regularized feature-space scorer provides a supervised anchor for patch-level evidence estimation, while score-attention agreement combines patch scores with WSI-level MIL attention to mine high-confidence pseudo labels. The same scores are then used to construct broad-positive ViT pretraining subsets, where a patch is selected if either abnormality or malignancy evidence exceeds a threshold. Experiments show that SlideCheck-defined data distributions influence the downstream behavior of self-supervised ViT pretraining, indicating that biological composition is an important controllable factor in pathology foundation model development. Curated subsets can approach full-data performance, suggesting that explicitly scored patch pools may support more efficient and auditable pretraining data construction. These findings position SlideCheck as a data guidance and auditing layer for transforming large, undifferentiated patch pools into controllable and reusable pretraining datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SlideCheck, a lightweight tool that uses frozen pathology foundation model patch features, a dual-head MLP for separate abnormality and malignancy scoring, a regularized supervised anchor, and score-attention agreement with MIL to mine pseudo-labels. These scores are used to construct broad-positive pretraining subsets (selecting patches where either score exceeds a threshold). The central claim is that SlideCheck-defined data distributions influence the downstream behavior of self-supervised ViT pretraining and that curated subsets can approach full-data performance, positioning the method as a data guidance and auditing layer.
Significance. If the experimental claims hold with rigorous validation, the work would demonstrate that biological composition is a controllable factor in pathology foundation model pretraining and could support more efficient, auditable dataset construction. No machine-checked proofs, reproducible code releases, or parameter-free derivations are described.
major comments (2)
- [Abstract] Abstract: the claim that 'Experiments show that SlideCheck-defined data distributions influence the downstream behavior of self-supervised ViT pretraining' and that 'Curated subsets can approach full-data performance' is asserted without any quantitative results, baselines, statistical tests, ablation details, or description of how influence was measured. This is load-bearing for the central claim.
- [Abstract] Abstract (paragraph on dual-head MLP and pseudo-label mining): the headline claim requires that the dual-head MLP scores and score-attention agreement produce reliable, unbiased patch-level evidence of abnormality and malignancy. The manuscript provides no validation of these scores against independent ground truth, no analysis of potential selection bias from the frozen feature extractor, and no check for systematic omission of rare morphologies.
minor comments (2)
- [Abstract] The abstract refers to 'a regularized feature-space scorer' as the supervised anchor but does not specify the regularization term, loss function, or training details for this component.
- [Abstract] The selection rule ('a patch is selected if either abnormality or malignancy evidence exceeds a threshold') introduces a free parameter (the threshold) whose sensitivity is not discussed.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment point by point below, focusing on strengthening the abstract and clarifying the intended role of the scoring components.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'Experiments show that SlideCheck-defined data distributions influence the downstream behavior of self-supervised ViT pretraining' and that 'Curated subsets can approach full-data performance' is asserted without any quantitative results, baselines, statistical tests, ablation details, or description of how influence was measured. This is load-bearing for the central claim.
Authors: We agree the abstract would be improved by incorporating concrete quantitative support for these claims. In the revised version we will add references to key experimental outcomes from the results section (including how influence was quantified via downstream task performance), along with mention of the baselines, ablations, and statistical comparisons used. This will make the central claim more self-contained in the abstract without altering the manuscript's experimental content. revision: yes
-
Referee: [Abstract] Abstract (paragraph on dual-head MLP and pseudo-label mining): the headline claim requires that the dual-head MLP scores and score-attention agreement produce reliable, unbiased patch-level evidence of abnormality and malignancy. The manuscript provides no validation of these scores against independent ground truth, no analysis of potential selection bias from the frozen feature extractor, and no check for systematic omission of rare morphologies.
Authors: The manuscript explicitly positions SlideCheck as a data guidance and auditing layer rather than a diagnostic model, with validation occurring through the downstream effect on self-supervised pretraining rather than direct diagnostic accuracy. We will add a dedicated limitations paragraph discussing potential selection bias from the frozen extractor and the possibility of under-representing rare morphologies. This addresses the concern while preserving the tool's stated purpose. revision: partial
Circularity Check
No significant circularity; derivation self-contained
full rationale
The abstract and described method construct SlideCheck scores via a supervised regularized anchor plus MIL attention agreement, then apply those scores to select pretraining subsets and measure downstream ViT effects. No equations, self-citations, or fitted-input renamings are present that would make the reported influence on pretraining performance equivalent to the selection procedure by construction. The central empirical claim (distribution control and near-full-data performance) rests on external validation rather than definitional reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- selection threshold
axioms (2)
- domain assumption Features from a frozen pathology foundation model are sufficient to train a lightweight scorer for abnormality and malignancy.
- domain assumption Score-attention agreement produces high-confidence pseudo labels suitable for guiding data selection.
Reference graph
Works this paper leans on
-
[1]
Big self-supervised models advance medical image classification
Shekoofeh Azizi, Basil Mustafa, Fiona Ryan, Zachary Beaver, Jan Freyberg, Jonathan Deaton, Aaron Loh, Alan Karthikesalingam, Simon Kornblith, Ting Chen, et al. Big self-supervised models advance medical image classification. InProceedings of the IEEE/CVF international conference on computer vision, pages 3478–3488, 2021
2021
-
[2]
Unitopatho, a labeled histopathological dataset for colorectal polyps classification and adenoma dysplasia grading
Carlo Alberto Barbano, Daniele Perlo, Enzo Tartaglione, Attilio Fiandrotti, Luca Bertero, Paola Cassoni, and Marco Grangetto. Unitopatho, a labeled histopathological dataset for colorectal polyps classification and adenoma dysplasia grading. In2021 IEEE International Conference on Image Processing (ICIP), pages 76–80. IEEE, 2021
2021
-
[3]
Bracs: A dataset for breast carcinoma subtyping in h&e histology images.Database, 2022:baac093, 2022
Nadia Brancati, Anna Maria Anniciello, Pushpak Pati, Daniel Riccio, Giosu` e Scognamiglio, Guillaume Jaume, Giuseppe De Pietro, Maurizio Di Bonito, Antonio Foncubierta, Gerardo Botti, et al. Bracs: A dataset for breast carcinoma subtyping in h&e histology images.Database, 2022:baac093, 2022. 7
2022
-
[4]
Clinical-grade computational pathology using weakly supervised deep learning on whole slide images.Nature medicine, 25(8):1301–1309, 2019
Gabriele Campanella, Matthew G Hanna, Luke Geneslaw, Allen Miraflor, Vitor Werneck Krauss Silva, Klaus J Busam, Edi Brogi, Victor E Reuter, David S Klimstra, and Thomas J Fuchs. Clinical-grade computational pathology using weakly supervised deep learning on whole slide images.Nature medicine, 25(8):1301–1309, 2019
2019
-
[5]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv´ e J´ egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021
2021
-
[6]
Scaling vision transformers to gigapixel images via hierarchical self-supervised learning
Richard J Chen, Chengkuan Chen, Yicong Li, Tiffany Y Chen, Andrew D Trister, Rahul G Krishnan, and Faisal Mahmood. Scaling vision transformers to gigapixel images via hierarchical self-supervised learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16144–16155, 2022
2022
-
[7]
Towards a general-purpose foundation model for computational pathology.Nature medicine, 30(3):850–862, 2024
Richard J Chen, Tong Ding, Ming Y Lu, Drew FK Williamson, Guillaume Jaume, Andrew H Song, Bowen Chen, Andrew Zhang, Daniel Shao, Muhammad Shaban, et al. Towards a general-purpose foundation model for computational pathology.Nature medicine, 30(3):850–862, 2024
2024
-
[8]
A multimodal whole-slide foundation model for pathology.Nature medicine, pages 1–13, 2025
Tong Ding, Sophia J Wagner, Andrew H Song, Richard J Chen, Ming Y Lu, Andrew Zhang, Anurag J Vaidya, Guillaume Jaume, Muhammad Shaban, Ahrong Kim, et al. A multimodal whole-slide foundation model for pathology.Nature medicine, pages 1–13, 2025
2025
-
[9]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[10]
Data filtering networks
Alex Fang, Albin Madappally Jose, Amit Jain, Ludwig Schmidt, Alexander Toshev, and Vaishaal Shankar. Data filtering networks. InInternational Conference on Learning Representations, volume 2024, pages 36221–36237, 2024
2024
-
[11]
Datacomp: In search of the next generation of multimodal datasets.Advances in Neural Information Processing Systems, 36:27092–27112, 2023
Samir Yitzhak Gadre, Gabriel Ilharco, Alex Fang, Jonathan Hayase, Georgios Smyrnis, Thao Nguyen, Ryan Marten, Mitchell Wortsman, Dhruba Ghosh, Jieyu Zhang, et al. Datacomp: In search of the next generation of multimodal datasets.Advances in Neural Information Processing Systems, 36:27092–27112, 2023
2023
-
[12]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll´ ar, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022
2022
-
[13]
Attention-based deep multiple instance learning
Maximilian Ilse, Jakub Tomczak, and Max Welling. Attention-based deep multiple instance learning. In International conference on machine learning, pages 2127–2136. PMLR, 2018
2018
-
[14]
Benchmarking self- supervised learning on diverse pathology datasets
Mingu Kang, Heon Song, Seonwook Park, Donggeun Yoo, and S´ ergio Pereira. Benchmarking self- supervised learning on diverse pathology datasets. in 2023 ieee. InCVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3344–3354
2023
-
[15]
Dong Li, Guihong Wan, Xintao Wu, Xinyu Wu, Ajit J Nirmal, Christine G Lian, Peter K Sorger, Yevgeniy R Semenov, and Chen Zhao. A survey on computational pathology foundation models: Datasets, adaptation strategies, and evaluation tasks.arXiv preprint arXiv:2501.15724, 2025
-
[16]
A visual-language foundation model for computational pathology.Nature medicine, 30(3):863–874, 2024
Ming Y Lu, Bowen Chen, Drew FK Williamson, Richard J Chen, Ivy Liang, Tong Ding, Guillaume Jaume, Igor Odintsov, Long Phi Le, Georg Gerber, et al. A visual-language foundation model for computational pathology.Nature medicine, 30(3):863–874, 2024
2024
-
[17]
Data-efficient and weakly supervised computational pathology on whole-slide images.Nature biomedical engineering, 5(6):555–570, 2021
Ming Y Lu, Drew FK Williamson, Tiffany Y Chen, Richard J Chen, Matteo Barbieri, and Faisal Mahmood. Data-efficient and weakly supervised computational pathology on whole-slide images.Nature biomedical engineering, 5(6):555–570, 2021. 8
2021
-
[18]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth´ ee Darcet, Th´ eo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
A data- efficient strategy for building high-performing medical foundation models.Nature biomedical engineering, 9(4):539–551, 2025
Yuqi Sun, Weimin Tan, Zhuoyao Gu, Ruian He, Siyuan Chen, Miao Pang, and Bo Yan. A data- efficient strategy for building high-performing medical foundation models.Nature biomedical engineering, 9(4):539–551, 2025
2025
-
[20]
Transformer-based unsupervised contrastive learning for histopathological image classification
Xiyue Wang, Sen Yang, Jun Zhang, Minghui Wang, Jing Zhang, Wei Yang, Junzhou Huang, and Xiao Han. Transformer-based unsupervised contrastive learning for histopathological image classification. Medical image analysis, 81:102559, 2022
2022
-
[21]
A whole-slide foundation model for digital pathology from real-world data.Nature, 630(8015):181–188, 2024
Hanwen Xu, Naoto Usuyama, Jaspreet Bagga, Sheng Zhang, Rajesh Rao, Tristan Naumann, Cliff Wong, Zelalem Gero, Javier Gonz´ alez, Yu Gu, et al. A whole-slide foundation model for digital pathology from real-world data.Nature, 630(8015):181–188, 2024
2024
-
[22]
mixup: Beyond Empirical Risk Minimization
Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimization.arXiv preprint arXiv:1710.09412, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
A foundation model for generalizable disease detection from retinal images.Nature, 622(7981):156–163, 2023
Yukun Zhou, Mark A Chia, Siegfried K Wagner, Murat S Ayhan, Dominic J Williamson, Robbert R Struyven, Timing Liu, Moucheng Xu, Mateo G Lozano, Peter Woodward-Court, et al. A foundation model for generalizable disease detection from retinal images.Nature, 622(7981):156–163, 2023
2023
-
[24]
Understanding pre-training data effects in retinal foundation models using two large fundus cohorts.Nature Communications, 2026
Yukun Zhou, Zheyuan Wang, Yilan Wu, Ariel Yuhan Ong, Siegfried K Wagner, Eden Ruffell, Mark A Chia, Zhouyu Guan, Lie Ju, Justin Engelmann, et al. Understanding pre-training data effects in retinal foundation models using two large fundus cohorts.Nature Communications, 2026
2026
-
[25]
Eric Zimmermann, Eugene Vorontsov, Julian Viret, Adam Casson, Michal Zelechowski, George Shaikovski, Neil Tenenholtz, James Hall, David Klimstra, Razik Yousfi, et al. Virchow2: Scaling self-supervised mixed magnification models in pathology.arXiv preprint arXiv:2408.00738, 2024. 9
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.