HASA: Subnet Allocation for Compute-Constrained Model-Heterogeneous Federated Learning
Pith reviewed 2026-06-28 19:28 UTC · model grok-4.3
The pith
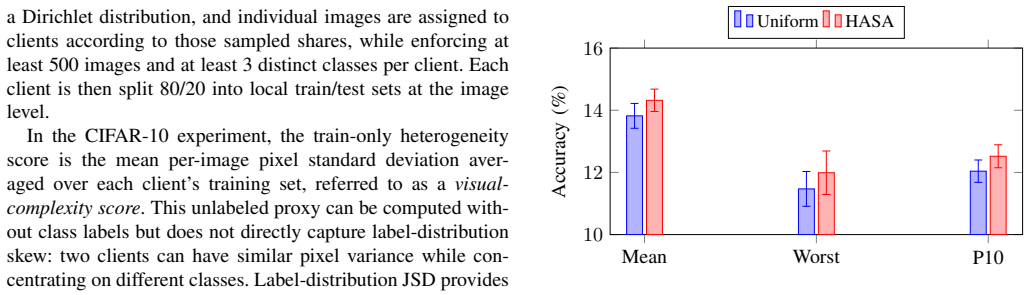
Allocating wider subnets to clients with higher data heterogeneity raises mean accuracy from 13.82% to 14.32% and improves tail performance under fixed compute in federated learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
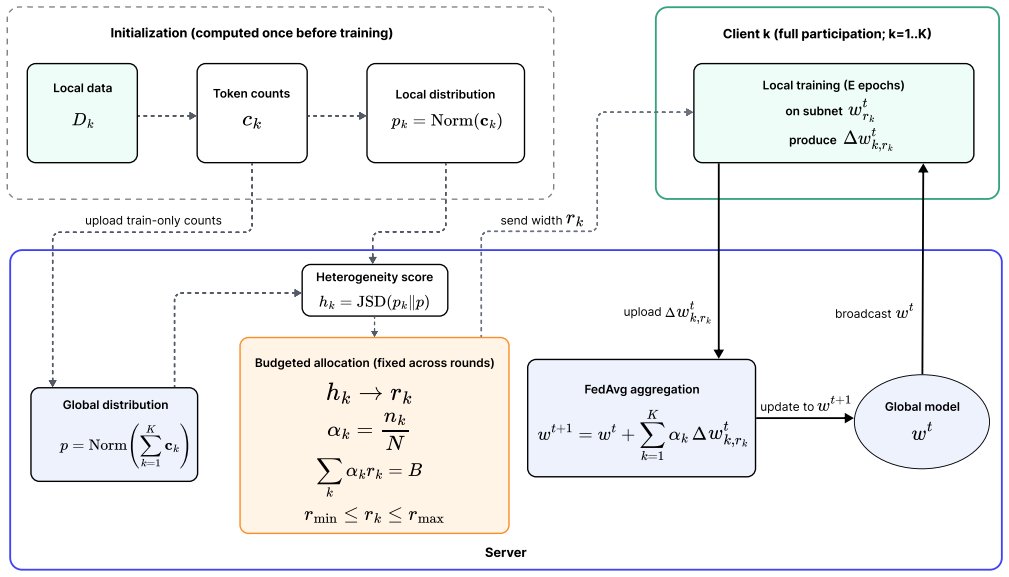
HASA is a train-only rule that assigns subnet widths based on client heterogeneity scores computed from local training data while enforcing a fixed size-weighted compute budget. On an article-title next-word prediction benchmark with seven clients, HASA improves unweighted mean client test accuracy over uniform allocation across 10 matched seeds, increasing mean client test accuracy from 13.82 percent to 14.32 percent, and improves worst-client accuracy on average. In a matched-budget comparison with representative partial-training baselines, HASA achieves the strongest worst-client and tail-client accuracy on this benchmark.
What carries the argument
The HASA allocation rule, which computes a heterogeneity score from each client's local data to decide its subnet width while holding total compute fixed.
If this is right
- Mean client test accuracy rises by half a percentage point over uniform allocation.
- Worst-client and tail-client accuracies become the highest among matched-budget partial-training methods.
- Reversing the allocation direction, so heterogeneous clients receive smaller subnets, reduces both mean and tail performance.
- The gains hold in a cross-domain image-classification setting only when the score aligns with the need for extra width.
Where Pith is reading between the lines
- The approach could extend to dynamic client pools if heterogeneity scores are recomputed periodically from recent local batches.
- Combining the allocation rule with client-specific fine-tuning after subnet training might further close the gap to full-model personalization.
- The method's reliance on local data only suggests it could apply directly to privacy-sensitive domains where central data inspection is impossible.
Load-bearing premise
The heterogeneity score must accurately reflect each client's need for additional model width.
What would settle it
An experiment on the same benchmark in which replacing the heterogeneity score with random values still yields the reported accuracy gains would show the score is not driving the improvement.
Figures
read the original abstract
Edge services increasingly use federated learning to personalize on-device models while keeping sensitive data local. In practice, deployments must handle heterogeneity in both client resources and local data distributions. Model-heterogeneous federated learning lowers client cost by allowing each client to train a subnet of a shared supernet, but most subnet-allocation policies are driven by device constraints and do not explicitly account for statistical heterogeneity. This paper proposes Heterogeneity-Aware Subnet Allocation (HASA), a train-only rule that assigns subnet widths based on client heterogeneity scores computed from local training data while enforcing a fixed size-weighted compute budget. This design enables budget-matched comparisons with alternative allocation policies. On an article-title next-word prediction benchmark with seven clients, HASA improves unweighted mean client test accuracy over uniform allocation across 10 matched seeds, increasing mean client test accuracy from 13.82 percent to 14.32 percent, and improves worst-client accuracy on average. In a matched-budget comparison with representative partial-training baselines, HASA achieves the strongest worst-client and tail-client accuracy on this benchmark. A directionality ablation shows that assigning smaller subnets to more heterogeneous clients degrades both mean and tail performance. A cross-domain image-classification study further shows that the effectiveness of heterogeneity-aware allocation depends on how well the heterogeneity score reflects clients' need for additional model width.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Heterogeneity-Aware Subnet Allocation (HASA), a train-only rule that assigns subnet widths in model-heterogeneous federated learning according to client heterogeneity scores computed from local data while enforcing a fixed size-weighted compute budget. On a seven-client article-title next-word prediction benchmark it reports an increase in unweighted mean client test accuracy from 13.82% to 14.32% versus uniform allocation across ten matched seeds, together with improved worst-client and tail-client accuracy relative to representative partial-training baselines. A directionality ablation and a cross-domain image-classification study are included; the latter is presented as evidence that effectiveness depends on how well the heterogeneity score tracks clients' need for additional model width.
Significance. If the heterogeneity score reliably tracks clients' capacity demand, the budget-matched design would allow principled allocation of limited compute in statistically heterogeneous FL deployments and could improve tail performance without raising total cost. The explicit statement that effectiveness hinges on score quality and the use of matched-budget comparisons are strengths that facilitate future verification.
major comments (2)
- [Abstract] Abstract: the central performance claims (mean accuracy lift of 0.5 pp, strongest worst- and tail-client accuracy) rest on a single benchmark with only seven clients and ten seeds; no error bars, statistical tests, or description of how the heterogeneity score is computed or how data/seed selection was performed are supplied, which is load-bearing for attributing gains to the allocation rule rather than sampling variance.
- [Abstract] Abstract: the directionality ablation tests only the sign of the allocation (smaller subnets to more heterogeneous clients) but supplies no direct evidence that the heterogeneity score correlates with clients' actual need for model width (e.g., via correlation with data-complexity or optimization-difficulty metrics), even though the paper itself states that effectiveness depends on this correlation.
minor comments (1)
- [Abstract] The abstract does not provide the formula or precise definition of the heterogeneity score, which would improve reproducibility of the allocation rule.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the strength of supporting evidence. We will revise the abstract to incorporate additional details on the experimental setup and clarify the role of the ablations and cross-domain study. The responses below address each major comment.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims (mean accuracy lift of 0.5 pp, strongest worst- and tail-client accuracy) rest on a single benchmark with only seven clients and ten seeds; no error bars, statistical tests, or description of how the heterogeneity score is computed or how data/seed selection was performed are supplied, which is load-bearing for attributing gains to the allocation rule rather than sampling variance.
Authors: We agree the abstract is concise and will expand it in revision to briefly describe the heterogeneity score computation from local data and to note that all results are averaged over 10 matched seeds with the same data partitioning. Error bars will be referenced (they appear in the main figures) and we will add a short statement on the benchmark scale as a limitation. The seven-client setting was selected to permit fine-grained per-client analysis under controlled conditions; we do not claim broad generalizability from this benchmark alone. revision: yes
-
Referee: [Abstract] Abstract: the directionality ablation tests only the sign of the allocation (smaller subnets to more heterogeneous clients) but supplies no direct evidence that the heterogeneity score correlates with clients' actual need for model width (e.g., via correlation with data-complexity or optimization-difficulty metrics), even though the paper itself states that effectiveness depends on this correlation.
Authors: The directionality ablation shows that reversing the allocation rule harms both mean and tail performance, which supports the chosen sign. We acknowledge it does not include explicit correlation coefficients with data-complexity metrics. The cross-domain image-classification experiment is presented precisely to illustrate that gains appear only when the heterogeneity score tracks clients' need for width; we will revise the abstract to make this linkage more explicit and to note that the score's validity is evidenced by the conditional effectiveness across domains rather than by the ablation alone. revision: partial
Circularity Check
No significant circularity in derivation or claims
full rationale
The paper defines HASA as an allocation rule that computes heterogeneity scores directly from local training data and assigns subnet widths under a fixed compute budget. Reported gains (13.82% to 14.32% mean accuracy) are empirical measurements on held-out test data across seeds, with directionality ablation and cross-domain checks. No equations, predictions, or first-principles results reduce to fitted inputs by construction; the score-to-width mapping is a deterministic function of externally computed inputs, not self-referential. No self-citation chains or uniqueness theorems are invoked to justify the central mechanism. The load-bearing assumption (score quality) is stated explicitly as an empirical precondition rather than derived internally.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Fortune: A negative memory overhead hardware-agnostic fault tolerance technique in dnns,
S. Nazari, M. Taheri, A. Azarpeyvand, M. Afsharchi, T. Ghasempouri, C. Herglotz, M. Daneshtalab, and M. Jenihhin, “Fortune: A negative memory overhead hardware-agnostic fault tolerance technique in dnns,” inIEEE 33rd Asian Test Symposium (ATS), 2024
2024
-
[2]
Reliability-aware performance optimization of dnn hw accelerators through heterogeneous quantization,
S. Nazari, M. Taheri, A. Azarpeyvand, M. Afsharchi, C. Herglotz, and M. Jenihhin, “Reliability-aware performance optimization of dnn hw accelerators through heterogeneous quantization,” in2025 IEEE 26th Latin American Test Symposium (LATS). IEEE, 2025, pp. 1–6
2025
-
[3]
Mix-and-match pruning: Globally guided layer-wise sparsification of dnns,
D. Monachan, S. Nazari, M. Taheri, A. Azarpeyvand, M. Krstic, M. Huebner, and C. Herglotz, “Mix-and-match pruning: Globally guided layer-wise sparsification of dnns,”arXiv preprint arXiv:2603.20280, 2026
-
[4]
Towards federated learning at scale: System design,
K. A. Bonawitz, H. Eichner, W. Grieskamp, D. Huba, A. Ingerman, V . Ivanov, C. M. Kiddon, J. Kone ˇcný, S. Mazzocchi, B. McMahan, T. V . Overveldt, D. Petrou, D. Ramage, and J. Roselander, “Towards federated learning at scale: System design,” inSysML, 2019
2019
-
[5]
Communication-Efficient Learning of Deep Networks from Decentralized Data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y. Arcas, “Communication-Efficient Learning of Deep Networks from Decentralized Data,” inProceedings of AISTATS, 2017, pp. 1273–1282
2017
-
[6]
A comprehensive empirical study of heterogeneity in federated learning,
A. M. Abdelmoniem, C.-Y . Ho, P. Papageorgiou, and M. Canini, “A comprehensive empirical study of heterogeneity in federated learning,” IEEE Internet of Things Journal, vol. 10, pp. 14 071–14 083, 2023
2023
-
[7]
Practical secure aggregation for privacy-preserving machine learning,
K. Bonawitz, V . Ivanov, B. Kreuter, A. Marcedone, H. B. McMahan, S. Patel, D. Ramage, A. Segal, and K. Seth, “Practical secure aggregation for privacy-preserving machine learning,” inACM CCS, 2017
2017
-
[8]
REFL: Resource-efficient federated learning,
A. M. Abdelmoniem, A. N. Sahu, M. Canini, and S. A. Fahmy, “REFL: Resource-efficient federated learning,” inProceedings of the Eighteenth European Conference on Computer Systems (EuroSys), 2023, pp. 215– 232
2023
-
[9]
Towards mitigating device het- erogeneity in federated learning via adaptive model quantization,
A. M. Abdelmoniem and M. Canini, “Towards mitigating device het- erogeneity in federated learning via adaptive model quantization,” in Proceedings of the 1st Workshop on Machine Learning and Systems (EuroMLSys), 2021, pp. 96–103
2021
-
[10]
Federated optimization in heterogeneous networks,
T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V . Smith, “Federated optimization in heterogeneous networks,” inProceedings of Machine Learning and Systems, 2020
2020
-
[11]
SCAFFOLD: Stochastic controlled averaging for federated learning,
S. P. Karimireddy, S. Kale, M. Mohri, S. Reddi, S. Stich, and A. T. Suresh, “SCAFFOLD: Stochastic controlled averaging for federated learning,” inProceedings of ICML, 2020
2020
-
[12]
Expanding the Reach of Federated Learning by Reducing Client Resource Requirements
S. Caldas, J. Kone ˇcny, H. B. McMahan, and A. Talwalkar, “Expanding the reach of federated learning by reducing client resource require- ments,”arXiv 1812.07210, 2019
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[13]
Heterofl: Computation and commu- nication efficient federated learning for heterogeneous clients,
E. Diao, J. Ding, and V . Tarokh, “Heterofl: Computation and commu- nication efficient federated learning for heterogeneous clients,”arXiv 2010.01264, 2021
-
[14]
J. Yu, L. Yang, N. Xu, J. Yang, and T. Huang, “Slimmable neural networks,”arXiv 1812.08928, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[15]
Edge computing: Vision and challenges,
W. Shi, J. Cao, Q. Zhang, Y . Li, and L. Xu, “Edge computing: Vision and challenges,”IEEE Internet of Things Journal, vol. 3, no. 5, pp. 637–646, 2016
2016
-
[16]
The emergence of edge computing,
M. Satyanarayanan, “The emergence of edge computing,”IEEE Com- puter, vol. 50, no. 1, pp. 30–39, 2017
2017
-
[17]
Mitigating malicious model fusion in federated learning via confidence-aware defense,
Q. Li, P. Papageorgiou, G. Liu, M. Gao, L. You, C. Wan, and A. M. Abdelmoniem, “Mitigating malicious model fusion in federated learning via confidence-aware defense,”Information Fusion, vol. 126, 2025
2025
-
[18]
Discovering latent knowledge proto- types for heterogeneous federated learning,
Q. Li and A. M. Abdelmoniem, “Discovering latent knowledge proto- types for heterogeneous federated learning,” inProceedings of the 28th European Conference on Artificial Intelligence (ECAI), 2025
2025
-
[19]
Hierarchical knowledge structuring for effective federated learning in heterogeneous environ- ments,
W. F. Tam, Q. Li, and A. M. Abdelmoniem, “Hierarchical knowledge structuring for effective federated learning in heterogeneous environ- ments,” inProceedings of IEEE IJCNN, 2025
2025
-
[20]
Fedrolex: model- heterogeneous federated learning with rolling sub-model extraction,
S. Alam, L. Liu, M. Yan, and M. Zhang, “Fedrolex: model- heterogeneous federated learning with rolling sub-model extraction,” in Proceedings of NeurIPS, 2022
2022
-
[21]
Scalefl: Resource-adaptive federated learning with heterogeneous clients,
F. Ilhan, G. Su, and L. Liu, “Scalefl: Resource-adaptive federated learning with heterogeneous clients,” inIEEE/CVF CVPR, 2023
2023
-
[22]
H. Cai, C. Gan, T. Wang, Z. Zhang, and S. Han, “Once-for-all: Train one network and specialize it for efficient deployment,”arXiv 1908.09791, 2020
-
[23]
SlimFL: Federated Learning With Superposition Coding Over Slimmable Neural Networks ,
W. J. Yun, Y . Kwak, H. Baek, S. Jung, M. Ji, M. Bennis, J. Park, and J. Kim, “ SlimFL: Federated Learning With Superposition Coding Over Slimmable Neural Networks ,”IEEE/ACM Transactions on Networking, vol. 31, no. 06, pp. 2499–2514, 2023
2023
-
[24]
arXiv preprint arXiv:1910.03581 , year=
D. Li and J. Wang, “Fedmd: Heterogenous federated learning via model distillation,”arXiv 1910.03581, 2019
-
[25]
Boyi Liu, Lujia Wang, and Ming Liu
T. Lin, L. Kong, S. U. Stich, and M. Jaggi, “Ensemble distillation for robust model fusion in federated learning,”arXiv 2006.07242, 2021
-
[26]
M. Mohri, G. Sivek, and A. T. Suresh, “Agnostic federated learning,” arXiv 1902.00146, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[27]
Fair resource allocation in federated learning,
T. Li, M. Sanjabi, A. Beirami, and V . Smith, “Fair resource allocation in federated learning,”arXiv 1905.10497, 2020
-
[28]
An efficient framework for clustered federated learning,
A. Ghosh, J. Chung, D. Yin, and K. Ramchandran, “An efficient framework for clustered federated learning,” inProceedings of the 34th NeurIPS, 2020
2020
-
[29]
Medium articles dataset (2019, 7 publications),
D. Lazar, “Medium articles dataset (2019, 7 publications),” Kaggle dataset, 2019, accessed 2026-01-29. [Online]. Available: https: //www.kaggle.com/datasets/dorianlazar/medium-articles-dataset
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.