A case study of evaluating AI agents on a neuroscience data-to-discovery pipeline
Pith reviewed 2026-06-27 21:54 UTC · model grok-4.3
The pith
Coding agents solve isolated stages of a neuroscience data pipeline but cannot complete the full end-to-end task.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
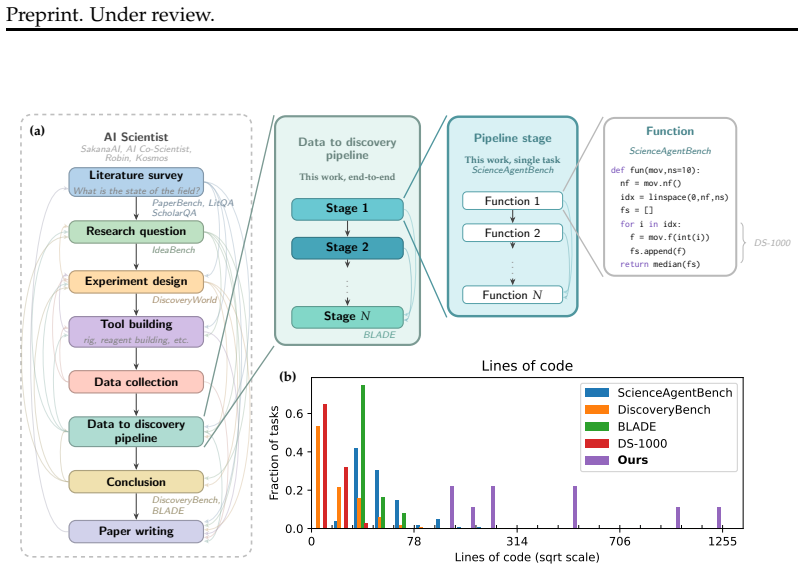
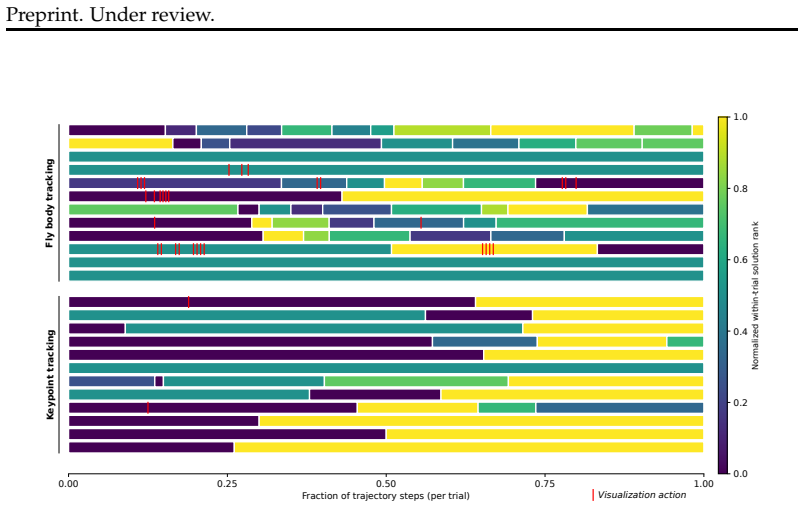
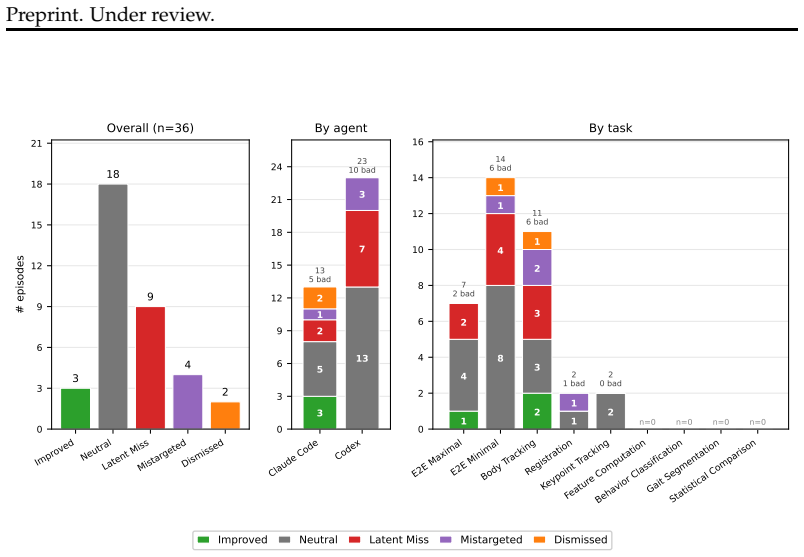
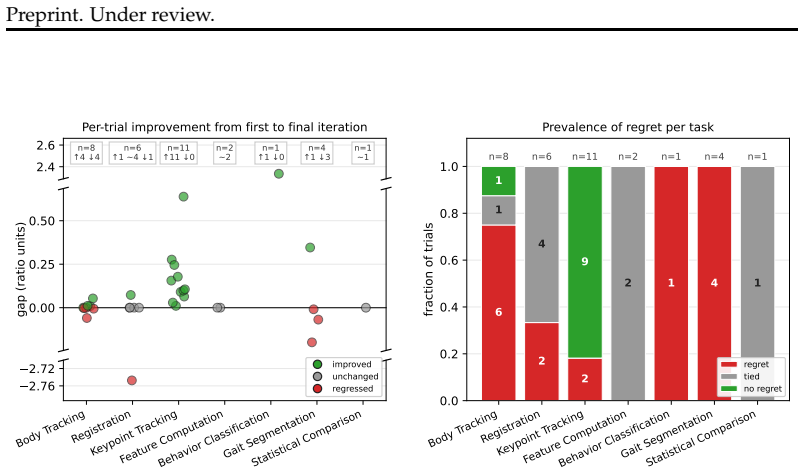
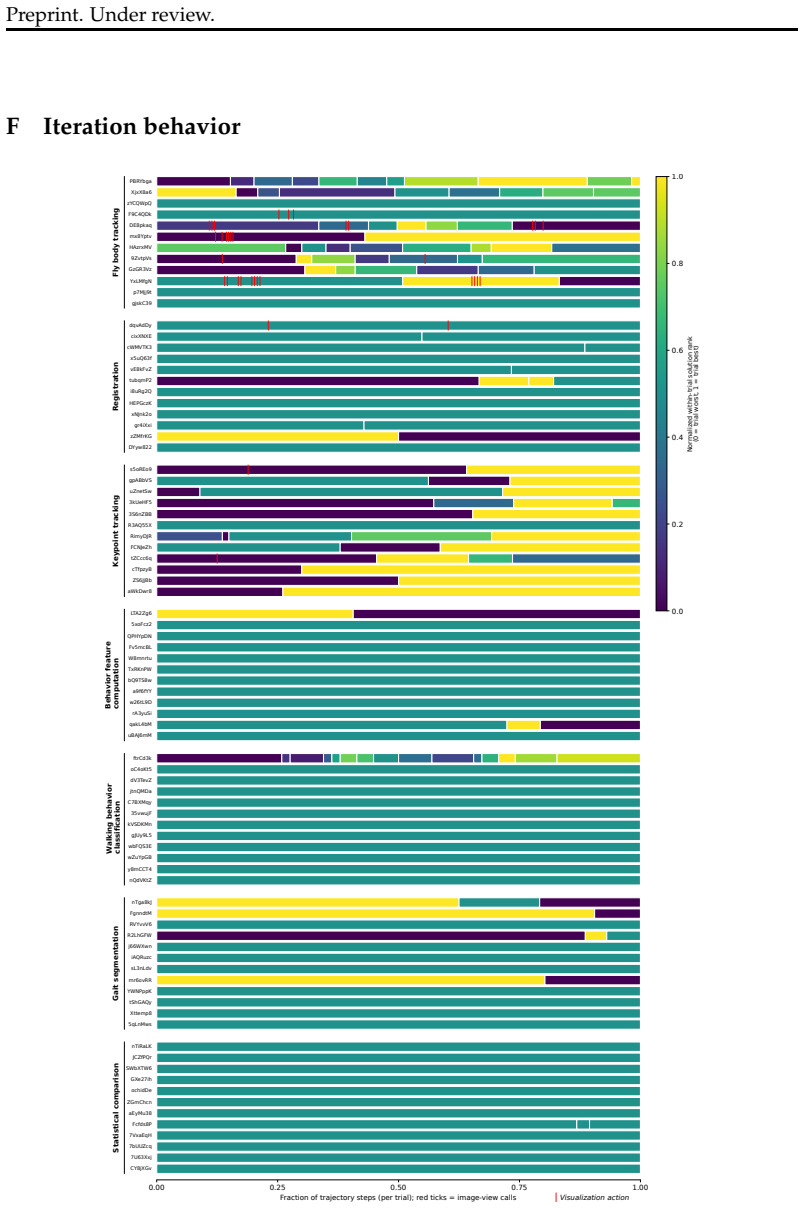
Agents can solve several individual pipeline stages in the fly optogenetics data-to-discovery pipeline, suggesting stage-level automation is tractable, yet solving the end-to-end pipeline correctly requires stringing together successes across all stages and remains beyond agents' current abilities; the primary difficulty arises when no pre-defined criterion exists for iteration and agents must instead use scientific judgment to assess their own solutions, including largely failing to interpret visual outputs appropriately.
What carries the argument
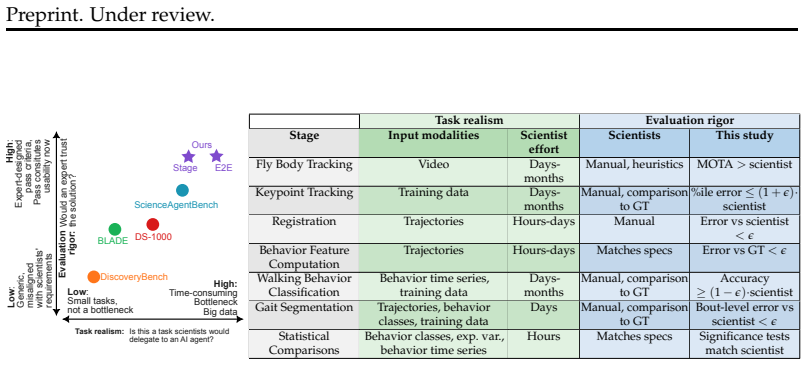
The fly optogenetics data-to-discovery pipeline, with its sequence of stages evaluated against domain-expert standards on large datasets.
If this is right
- Stage-level automation of scientific pipelines is tractable with current agents.
- Agents struggle most when no pre-defined criterion exists and they must apply scientific judgment.
- Agents attempt visual inspection of intermediate outputs for self-evaluation but largely fail to interpret or act on what they see.
- New challenges absent from existing benchmarks include computational resource management and generalization to large held-out data collections.
- Principles for constructing scientific tasks and rigorous evaluation criteria for open-ended problems can be distilled from the case study.
Where Pith is reading between the lines
- The same stage-versus-end-to-end gap may appear in pipelines from other scientific domains.
- Training or prompting agents to generate their own evaluation criteria could address the self-judgment bottleneck.
- Benchmarks that explicitly test resource management and large-data generalization would better reflect real scientific workloads.
Load-bearing premise
The selected pipeline stages, datasets, and domain-expert evaluation criteria are representative of the bottlenecks and standards that matter in actual neuroscience research practice.
What would settle it
Running the same agents on the identical pipeline and checking whether they produce a correct end-to-end solution on held-out large data collections, or whether success rates drop when visual self-evaluation is required.
Figures



read the original abstract
Agentic AI tools offer a promising path to automating software development bottlenecks in scientific research pipelines, particularly for stages that take domain experts days to months to build, where scientists care about correctness and robustness, not implementation details. We present an empirical study of general-purpose coding agents on a fly optogenetics data-to-discovery pipeline. We assess agents on tasks substantially larger than existing benchmarks, datasets orders of magnitude bigger, and evaluation criteria grounded in domain expert standards. We show that agents can solve several individual pipeline stages, suggesting stage-level automation is tractable. By analyzing agents' code iterations, we show that they struggle most when there is not a pre-defined criterion to iterate on, and they must instead use their scientific judgment to assess their current solution, a key open challenge. Mirroring scientific practice, they sometimes attempt visual inspection of intermediate outputs for self-evaluation, but largely fail to interpret what they see or act on it appropriately. Solving the end-to-end pipeline correctly requires stringing together successes across all pipeline stages, and this is beyond agents' current abilities. We identify challenges largely absent from existing benchmarks, including computational resource management and generalization to large held-out data collections. Finally, we distill principles for constructing scientific tasks and rigorous evaluation criteria for open-ended problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical case study evaluating general-purpose coding agents on a fly optogenetics data-to-discovery pipeline. It claims that agents succeed on several individual pipeline stages when clear iteration criteria are available, indicating that stage-level automation is tractable, but fail to solve the end-to-end pipeline. Key difficulties include lack of pre-defined criteria requiring scientific judgment for self-evaluation, visual inspection of outputs, computational resource management, and generalization to large held-out datasets. The work distills principles for constructing scientific tasks and rigorous evaluation criteria for open-ended problems, using domain-expert standards and tasks larger than existing benchmarks.
Significance. If the results hold under the stated evaluation criteria, the study supplies concrete, domain-grounded evidence on the gap between stage-wise and end-to-end agent performance in a real scientific workflow. Strengths include the use of substantially larger datasets and tasks than typical benchmarks, explicit domain-expert evaluation, and identification of challenges (self-judgment without ground truth, resource management) largely absent from current agent benchmarks. These observations could usefully inform the design of future agent benchmarks and scientific automation efforts.
major comments (1)
- [Abstract] Abstract and the distillation of principles section: the central claim that the findings bear on 'scientific research pipelines' in general and that 'stage-level automation is tractable' is advanced from results on a single fly optogenetics pipeline whose stages, dataset sizes, and expert criteria are not shown to be representative of the distribution of bottlenecks or standards in neuroscience practice. No comparison to other pipelines or external validation is provided, so the generalization step is load-bearing for the broader implications yet unsupported.
minor comments (1)
- The manuscript would benefit from an explicit limitations subsection that states the single-pipeline scope and the absence of cross-pipeline validation, rather than leaving this implicit.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below and will revise the manuscript accordingly to clarify scope.
read point-by-point responses
-
Referee: [Abstract] Abstract and the distillation of principles section: the central claim that the findings bear on 'scientific research pipelines' in general and that 'stage-level automation is tractable' is advanced from results on a single fly optogenetics pipeline whose stages, dataset sizes, and expert criteria are not shown to be representative of the distribution of bottlenecks or standards in neuroscience practice. No comparison to other pipelines or external validation is provided, so the generalization step is load-bearing for the broader implications yet unsupported.
Authors: We agree that the work is a single case study and provides no comparisons to other pipelines or external validation of representativeness. The manuscript title explicitly frames the contribution as a case study, and the abstract uses 'suggesting' rather than asserting generality. The distilled principles are offered as observations from this pipeline that may inform future benchmark design. To prevent overgeneralization, we will revise the abstract and principles section to state more explicitly that the findings derive from one pipeline, that stage-level tractability is observed here rather than proven broadly, and that the principles constitute hypotheses requiring validation across additional domains and pipelines. revision: yes
Circularity Check
No circularity: empirical case study with observational results only
full rationale
The paper is an empirical case study reporting agent performance on specific neuroscience pipeline tasks. It contains no derivations, equations, fitted parameters, predictions derived from first principles, or self-referential claims. All results are direct observations from running agents on chosen tasks and evaluating outputs against domain-expert criteria. No load-bearing step reduces to a self-citation, ansatz, or input by construction. The distillation of principles is presented as post-hoc guidance rather than a derived result. This matches the default expectation of no significant circularity for observational work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
LAB-Bench: Measuring Capabilities of Language Models for Biology Research
URLhttps://arxiv.org/abs/2407.10362. Chris Lu, Cong Lu, Robert Tjarko Lange, Yutaro Yamada, Shengran Hu, Jakob Foerster, David Ha, and Jeff Clune. Towards end-to-end automation of AI research.Nature, 651 (8107):914–919, 2026. ISSN 1476-4687. doi: 10.1038/s41586-026-10265-5. URL https: //doi.org/10.1038/s41586-026-10265-5. Bodhisattwa Prasad Majumder, Hars...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s41586-026-10265-5 2026
-
[2]
PaperBench: Evaluating AI's Ability to Replicate AI Research
URLhttps://arxiv.org/abs/2504.01848. Carsen Stringer and Marius Pachitariu. Analysis methods for large-scale neuronal recordings.Science, 386(6722):eadp7429, 2024. doi: 10.1126/science.adp7429. URL https://www.science.org/doi/abs/10.1126/science.adp7429. Sijun Tan, Siyuan Zhuang, Kyle Montgomery, William Yuan Tang, Alejandro Cuadron, Chenguang Wang, Raluc...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1126/science.adp7429 2024
-
[3]
TusoAI: Agentic Optimization for Scientific Methods
URLhttps://openreview.net/forum?id=G0dksFayVq. Aman Singh Thakur, Kartik Choudhary, Venkat Srinik Ramayapally, Sankaran Vaidyanathan, and Dieuwke Hupkes. Judging the judges: Evaluating alignment and vulnerabilities in LLMs-as-judges. In Ofir Arviv, Miruna Clinciu, Kaustubh Dhole, Rotem Dror, Sebastian Gehrmann, Eliya Habba, Itay Itzhak, Simon Mille, Yotam...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Let me just run the analysis fresh
I removed the tracks saving in my rewrite. Let me just run the analysis fresh. Actually, the process experiment function doesn’t save tracks anymore b... 132.Bash: Check orientation of crops and keypoints→Det 3 orient 1: head y=77, abd y=110, head on top=True 133.Read(crop 0 orient0.png) 134.Read(crop 0 orient1.png)
-
[5]
So when the orienta- tion is correct (orient 0, fly pointing up), the head keypoint is correctly at the top
OK interesting - the model predicts head at top in both orientations. So when the orienta- tion is correct (orient 0, fly pointing up), the head keypoint is correctly at the top. When the orientation is flipped (orient 1, fly pointing down), the model still predicts head at top of the image, but the actual head is at the bottom. So the model is being ”tri...
-
[6]
acceptable
The orientation matters - the model needs the fly pointing up. I need to resolve the 180° ambiguity. Let me use velocity direction. 137.Read(fly pipeline.py)→334→def interpolate gaps(arr, max gap=10): 138.Edit(fly pipeline.py)→The file /workspace/fly pipeline.py has been updated successfully. ... G.1.3 Visual Latent Miss (codex/gpt-5.4) The agent attempte...
-
[7]
I’m checking a rotated crop from the arena video now to make sure a fixed-size affine crop is sufficient
The raw fly size matches the training crop scale more closely than I expected: the ellipse major axis is about 45 to 56 px, which is in the same ballpark as the annotated head-to- abdomen span in the 192 px training crops. I’m checking a rotated crop from the arena video now to make sure a fixed-size affine crop is sufficient. 67.Bash: python3 - <<’PY’ im...
-
[8]
I’m tightening the ellipse fit to the darker body core so the crop alignment is closer to the training distribution before I start training the pose model
A fixed 192 px affine crop is viable, but the raw silhouette orientation is being pulled around by wings. I’m tightening the ellipse fit to the darker body core so the crop alignment is closer to the training distribution before I start training the pose model. 70.Bash: python3 - <<’PY’ import cv2, sys, numpy as np from pathlib i...→ saved 6 71.view image...
-
[9]
I’ve got the crop geometry into an acceptable range, so I’m doing the critical viability check now: a very small coordinate-regression network on the ... ... 31 Preprint. Under review. G.1.4 Dependency installation (terminus-2/gpt-5.4) Registration: TrajectoryzZMfrKG
-
[10]
However, for local testing now, relying on cv2 blocks progress
The script currently fails because cv2 is not installed in the current environment, though requirements.txt should handle this during evaluation. However, for local testing now, relying on cv2 blocks progress. To make the solution more robust and reduce dependencies, we should remove the OpenCV requirement entirely and reimplement arena detection using on...
-
[11]
That’s reasonable but let me quickly retrain with faster settings to get better quality
3.54px mean error. That’s reasonable but let me quickly retrain with faster settings to get better quality. 74.Bash: python3 << ’PYEOF’ # Fast retrain with better settings import json, os, cv2, numpy as np, ...→Command running in background with ID: b8zoyk509. Output is being written to: /t... 75.While the model trains, let me build the full pipeline scri...
-
[12]
Something seems very slow
The training has been running for 458 minutes (7.6 hours), but it only needs to run 80 epochs. Something seems very slow. Let me check what’s happening. Actually, the process has been running since 04:24 and it’s currently much later. The issue might... 81.Bash: kill 3578 2>/dev/null; sleep 1; echo "done"→done 82.Bash: python3 << ’PYEOF’ # Quick retrain -...
-
[13]
This is far from the target and suggests the current architecture/loss setup is not adequate
Training has reached epoch 3 and has plateaued around mean percentile error 6.6 px with p50 between 1.3 and 1.6 px. This is far from the target and suggests the current architecture/loss setup is not adequate. Continuing to 25 epochs is unlikely to achieve subpixel accuracy. Because the images are standardized 192x192 grayscale fly crops with limited pose...
-
[14]
: 9.124578475952148,
The first epoch of the coordinate-regression model is worse than the heatmap model (mean percentile error ˜7.57 px, p50 ˜2.44 px). This may improve over more epochs, but the initial result is not promising. We should still gather a few more epochs before deciding, since pretrained backbones sometimes need several epochs to settle. No artifacts are ready y...
-
[15]
: 8.04142951965332,
The regression model is improving rapidly: by epoch 3 it beats the prior heatmap baseline, reaching mean percentile error ˜5.04 px, p50 ˜1.61 px, p95 ˜6.82 px. This is still far from target but trending in the right direction. Since training is only 20 epochs and each epoch is ˜19-20 seconds, it’s cheap to let it continue and see whether it approaches a p...
-
[16]
Let me wait for explore7.py to finish, or cancel
The previous explore6.py script is still running (the smoothed dfwd with minbout section was slow). Let me wait for explore7.py to finish, or cancel ... Bash→if result[i] != result[i-1]:
-
[17]
Let me wait for it to finish executing
The script output seems to be still displaying the file content. Let me wait for it to finish executing. Bash→if result[i] != result[i-1]:
-
[18]
Let me cancel it and try a more efficient approach
It seems like the terminal is stuck or the script is taking very long. Let me cancel it and try a more efficient approach. Bash: C-c→if result[i] != result[i-1]:
-
[19]
Let me try sending Ctrl+C again more forcefully
The terminal seems stuck. Let me try sending Ctrl+C again more forcefully. Bash: C-c, Bash: C-c, Bash:→if result[i] != result[i-1]:
-
[20]
Let me try to end the heredoc and get back to a prompt
The terminal is stuck, possibly still in the heredoc or waiting for input. Let me try to end the heredoc and get back to a prompt. Bash: PYEOF→if result[i] != result[i-1]:
-
[21]
Let me try sending Ctrl+D to end input, or try other escape sequences
The terminal is completely stuck. Let me try sending Ctrl+D to end input, or try other escape sequences. Bash: C-d, Bash: C-c→if result[i] != result[i-1]:
-
[22]
The terminal is completely unrespon- sive
I’ve been stuck for an extremely long time. The terminal is completely unrespon- sive. I need to try a completely different approach. Let me try to see ... Bash→if result[i] != result[i-1]:
-
[23]
The heredoc for explore7.py was interrupted by Ctrl+C
FINALLY! The terminal has recovered! I can see the shell prompt ‘root@39263b0b5319:/workspace#‘. The heredoc for explore7.py was interrupted by Ctrl+C... Bash: echo ’numpyscipypandas’ > /workspace/requirements.txt, Bash: cat /workspace/requirements.txt→root@39263b0b5319:/workspace# ... G.1.8 Self-termination (claude-code/claude-opus-4-6) In two Claude Cod...
-
[24]
Let me think about what else could help
OK so the bout-level metric doesn’t really benefit much from smoothing in this small labeled dataset. Let me think about what else could help. Actually, let me try a different approach. ...Let me try a few more things: 1. Using body-speed-relative threshold 2. Using distance from body center (during stance, leg extends backward; during swing, it’s closer ...
-
[25]
Let me read the current tracking code
Let me work on improving the fly tracking while the keypoint model trains. Let me read the current tracking code. ... 178.Edit(fly pipeline.py)→The file /workspace/fly pipeline.py has been updated successfully. ... 181.Bash: python3 -c " import sys sys.path.insert(0, ’helpers’) from fly pipeline import track flies...→Command running in background with ID:...
-
[26]
video path
15 tracks now, with the top 5 being 10K+ frames (out of 21866). Much better — close to 8-10 real flies. The merge step is working. Now let me run Step 2 on this and continue. ... H Token usage and runtimes Agent BodyTracking Registration KeypointTracking FeatureComputationBehaviorClassifier GaitSegmentationStatisticalComparison Wall-clock time (hours)clau...
-
[29]
Under review
Length and width (a, b) 5.Track identitiesacross frames to maintain consistent fly IDs 6.Output in trx formatwith all required fields correctly populated Expected Challenges • Multiple flies are present (need identity tracking) • Flies may touch 40 Preprint. Under review. Dependencies YouMUSTprovide a requirements.txt file listing any Python packages your...
-
[30]
Takes aJSON config file pathas its only CLI argument: python register.py config.json
-
[31]
video path
The config file contains a JSON array of objects, each with: 3."video path": path to a.ufmfvideo file 4."trx path": path to atrx.pkltrajectory file 5."output path": path where the output registered trx.pkl should be saved
-
[32]
Processeseach experimentin the config and saves a registered trx.pkl at the specified output path
-
[33]
video_path
Works onany number of experiments(not just the 3 reference experiments) Example config: [ { " video_path " : " / data / exp_1 / movie . ufmf " , " trx_path " : " / data / exp_1 / trx . pkl " , " output_path " : " / workspace / out / exp_1 / registered_trx . pkl " } , { " video_path " : " / data / exp_2 / movie . ufmf " , " trx_path " : " / data / exp_2 / ...
-
[36]
Note: This step ONLY computes the * mm fields; it does NOT modify the pixel-based fields 6.x mm,y mm: The ellipse center in millimeters 7.a mm,b mm: Ellipse quarter-major and quarter-minor axes in millimeters 8.theta mm: Same astheta(orientation in radians is scale-invariant) 9.Removes NaN gaps from trajectories
-
[39]
Under review
Split trajectories at long gaps (¿5 frames) into separate segments 13.Note: This step modifies all relevant pixel-based fields Script Input Trajectory FormatThe input trajectory dictionary contains these fields (all position/size values in pixel units), among others: 42 Preprint. Under review. Field Type Description xlist of arrays x-coordinate in pixels ...
-
[40]
Load the Multifly Dataset
-
[41]
Train a keypoint tracker or pose estimation model
-
[42]
Save your model class definition tomodel.py
-
[43]
trx_path
Save the trained model instance tomodel.pkl Model Interface Your model.py must define a class called KeypointTracker with the following inter- face: classKeypointTracker : def__init__ ( self , num_keypoints =21) : self . model = None # Your trained model deftrack ( self , X : np . ndarray ) -> np . ndarray : ' ' ' Track fly keypoints on a cropped image of...
-
[44]
All 16 feature files are created for each experiment
-
[47]
Feature values match ground truth within numerical tolerance
-
[48]
Save all output files here
Your script will be evaluated onmultiple unseen experimentsbeyond the reference data provided J.5 Walking Behavior Classification prompt Agent Prompt Fly Movement Behavior Classification Working directory: Your working directory is /workspace. Save all output files here. Input data is located at/data/. Time limit: You have a maximum of6 hoursto complete t...
-
[49]
Load the per-frame features and training labels
-
[51]
Save your classifier class definition tomodel.py
-
[52]
perframe
Save the trained model instance tomodel.pkl Model Interface Your model.py must define a class called WalkingClassifier with the following interface: classW alk in gC la ss ifi er : def__init__ ( self ) : self . model = None # your trained model self . feature_names = [] # list of feature names used , e . g . ['velmag','dtheta', ...] defpredict ( self , X ...
-
[53]
T uning Data (shared across all experiments) 3
walk preds.pkl • Walking behavior classification for the flies inkeypoints.npz • Only compute swing/stance for frames where the fly is walking • Pickle file containing a list of length n targets, where each element is a 1D ndarray of per-frame walking predictions for that fly • Arrays are globally aligned (index 0 = frame 0), but may be truncated at the e...
-
[54]
keypoints_path
groundcontact labels.csv • Ground truth swing/stance labels corresponding to keypoints for labels.npz • Columns:frame,fly,leg,ground contact(all indices are 0-based) • The ground contact column is 1 when the leg is on the ground (stance) and 0when off the ground (swing) • Use these labels along with keypoints for labels.npz to tune your algo- rithm. • Loc...
-
[55]
swing stance.npy • Contains swing/stance classifications for all flies, frames, and legs • Represented as a numpy array with shape(n flies, total frames, n legs) where: •n flies: number of trajectories •total frames: total number of video frames (indexed from frame 0) •n legs: 6 (in increasing order of keypoint index: 11, 12, 13, 14, 15, 16) •swing stance...
-
[56]
trx[‘x mm’][fly] etc
registered trx.pkl • Trajectory data for each fly • Contains the following metadata for temporal alignment between different data files: •trx[firstframe][fly]is the start of the first frame of trajectoryfly •trx[endframe][fly]is the last frame of trajectoryfly(inclusive) •trx[nframes][fly]is the number of frames in trajectoryfly • Full list of fields: Fie...
-
[57]
•velocity[fly][i] corresponds to frame trx[fly][firstframe]+i of the video
velmag ctr.pkl • Instantaneous velocity magnitude for each fly and frame • Pickle file containing a list of length n flies, where each element velocity[fly] is an ndarray representing a velocity time series of shape (trx[nframes][fly]-1). •velocity[fly][i] corresponds to frame trx[fly][firstframe]+i of the video. • Velocity values are in mm/s 56 Preprint....
-
[58]
c o n t r o l _ e x p e r i m e n t s
indicatordata.mat • Information about when lights ON periods occur. • The useful variables in this file are: •data[‘indicatorLED’][‘startframe’][i,0] : Start frame of optogenetic per- turbation periodi(1-indexed) •data[‘indicatorLED’][‘endframe’][i,0] : End frame of optogenetic pertur- bation periodi(1-indexed, inclusive) • Outside of ON periods are OFF p...
-
[59]
Load the keypoint tracker and walking classifier from the config paths (training them first if they don’t exist)
-
[60]
Processallexperiments (control and experimental) through Steps 1–8, saving intermediate outputs to each experiment’soutput dir
-
[61]
For each experimental line, run Step 9 (stance analysis) comparing to the shared control group, saving results toanalysis output path
-
[62]
pkl # Step 1: Body tracking |-- - registered_trx
Handle any number of lines and any number of replicates per line Per-Experiment Output StructureFor each experiment, the script must produce the following files in the experiment’soutput dir: { output_dir }/ |-- - trx . pkl # Step 1: Body tracking |-- - registered_trx . pkl # Step 2: Registration |-- - keypoints . npz # Step 4: Keypoint inference |-- - pe...
-
[63]
Centroid Position (x, y)
-
[64]
Abdomen to head orientation (theta)
-
[65]
Under review
Length and width (a, b) 5.Track identitiesacross frames to maintain consistent fly IDs 65 Preprint. Under review. 6.Output in trx formatwith all required fields correctly populated Body Tracking Output FormatEach tracking output file {output dir}/trx.pkl must be asingle dictionary. All frame indices are0-indexed. It must contain the following fields: Requ...
-
[66]
Transform the trajectories so that (0,0) corresponds to the arena center
-
[67]
Transform the trajectories so that the units are in millimeters
-
[68]
Note: This step ONLY computes the * mm fields; it does NOT modify the pixel-based fields 6.x mm,y mm: The ellipse center in millimeters 7.a mm,b mm: Ellipse quarter-major and quarter-minor axes in millimeters 8.theta mm: Same astheta(orientation in radians is scale-invariant) 9.Remove NaN gaps from trajectories
-
[69]
Interpolate short gaps (≤5 frames) using linear interpolation
-
[70]
Crop leading and trailing NaN values
-
[71]
Split trajectories at long gaps (>5 frames) into separate segments 13.Note: This step modifies all relevant pixel-based fields Registered Trajectory Output FormatThe output must contain all input fields (possibly modified by NaN removal) plus the registered* mmfields: Field Type Description x mmlist of arrays x-coordinate in mm, arena-centered (per fly) y...
-
[72]
All 16 feature files are created in {output dir}/perframe/ for each experi- ment
-
[73]
Each file contains a list withntargetsarrays
-
[74]
Array lengths match expected dimensions per feature type
-
[75]
Walking Behavior Classification - Training • Train abinary classifierto detect ”walking” behavior in fruit flies (Drosophila) using pre-computed per-frame movement features
Feature values match ground truth within numerical tolerance Step 6. Walking Behavior Classification - Training • Train abinary classifierto detect ”walking” behavior in fruit flies (Drosophila) using pre-computed per-frame movement features. • To define the walking behavior, we provide a training dataset in which positive labels (1) correspond to walking...
-
[76]
Load the labels from/data/walking labels/
-
[77]
Use your code for computing per-frame features from [Step 5](#step-5-per-frame-feature-computation) to transform /data/walking labels/{sample}/registered trx.pkl into per-frame features
-
[78]
not walking (0)
Train a classifier to predict walking behavior (1) vs. not walking (0)
-
[79]
Save your classifier class definition to /workspace/walking classifier/model.py
-
[80]
Walking Classifier Model Output FormatYour model.py must define a class called WalkingClassifierwith the following interface: 71 Preprint
Save the trained model instance to/workspace/walking classifier/model.pkl This step is run once; the trained model will be applied to all experiments in Step 7. Walking Classifier Model Output FormatYour model.py must define a class called WalkingClassifierwith the following interface: 71 Preprint. Under review. classW alk in gC la ss ifi er : def__init__...
-
[82]
J.9 End-to-End Minimal prompt Agent Prompt Fly Optogenetics Locomotion Analysis Working directory: Your working directory is /workspace
Validation: Evidence your methods work correctly (e.g., performance on labeled data, sanity checks, representative examples) This should allow someone to understand and reproduce your analysis. J.9 End-to-End Minimal prompt Agent Prompt Fly Optogenetics Locomotion Analysis Working directory: Your working directory is /workspace. Save all output files here...
-
[83]
Processallexperiments (control and experimental) through the full pipeline, saving intermediate outputs to each experiment’soutput dir
-
[84]
For each experimental line, run stance analysis comparing to the shared control group, saving results toanalysis output path
-
[85]
Handle any number of lines and any number of replicates per line Any trained models or other dependencies your script needs must be saved in /workspaceso they are available when the script is run on new data. Stance Duration Analysis Output FormatSave results to the analysis output path specified in the config for each line, with the follow- ing format: m...
-
[86]
Approach: Each step of your analysis, algorithms used, and key parameters
-
[87]
Validation: Evidence your methods work correctly (e.g., performance on labeled data, sanity checks, representative examples) This should allow someone to understand and reproduce your analysis. 82
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.