RACT: Retrieval Augmented Column-Table Learning and Prediction for Multi-Table Schema Matching
Pith reviewed 2026-06-27 20:01 UTC · model grok-4.3
The pith
RACT retrieves candidate tables via referential context to constrain column candidates and raises multi-table schema matching precision and completeness by up to 70 percent over baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that exploiting referential context through probabilistic table retrieval allows the column search space to be reliably constrained in multi-table holistic schema matching, where similarity-based methods are inadequate, and that this constraint produces measurably higher matching precision and completeness.
What carries the argument
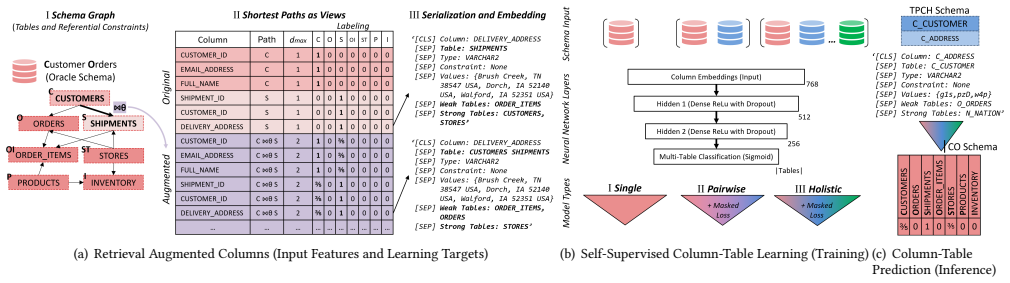
RACT learning and prediction, a self-supervised framework that performs probabilistic retrieval of candidate tables for source columns to constrain relevant column candidates.
If this is right
- The RACT framework outperforms similarity-based baselines on multi-table schema matching tasks.
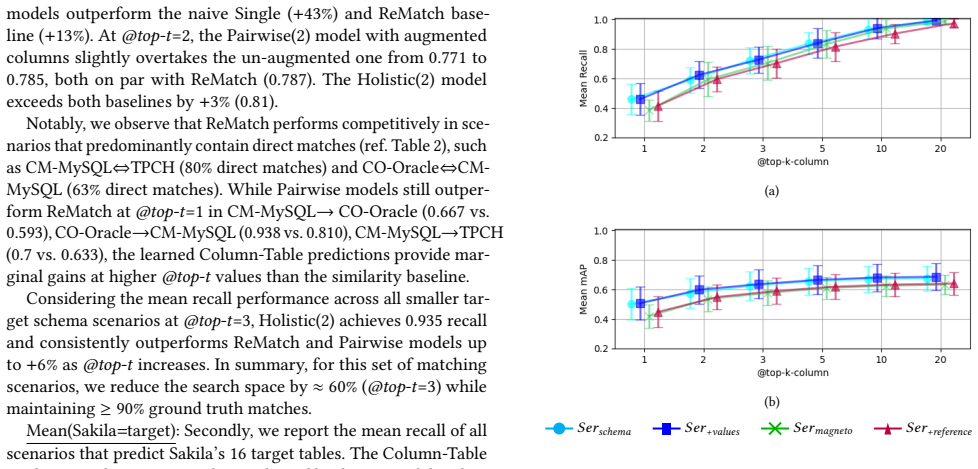
- Constraining column candidates to those inside top-t retrieved tables improves average matching precision and completeness by up to 70 percent.
- Referential context supplies useful signal when columns with similar semantics appear inside tables that have dissimilar surrounding structure.
- The self-supervised retrieval step can be applied before any downstream column matcher to reduce the effective search space.
Where Pith is reading between the lines
- The same retrieval-first pattern could be tested on other data-integration subtasks such as foreign-key discovery across multiple sources.
- If retrieval recall drops on schemas with very sparse referential links, the gains would shrink, suggesting a need for hybrid retrieval that also considers column-level signals early.
- The approach may reduce the amount of labeled column pairs needed for training because the table filter already removes most irrelevant candidates.
- Scaling the method to schemas with hundreds of tables would test whether the top-t constraint remains effective when table diversity grows.
- keywords:[
Load-bearing premise
Probabilistic retrieval of tables based on referential context will include the tables that contain the correct column matches without excluding them in heterogeneous schemas.
What would settle it
A dataset of multi-table schemas in which, for a substantial fraction of columns, the table containing the true match is ranked outside the top-t tables returned by the retrieval step, causing the subsequent matcher to miss correspondences.
Figures




read the original abstract
Schema matching, a critical task for integrating data from diverse sources, seeks to identify correspondences between columns across different schemas. In multi-table holistic schema matching, columns with similar semantic meaning may reside in tables with different contexts due to heterogeneous schema designs, where similarity-based techniques are inadequate. The focus of this paper is exploiting referential context into schema matching by introducing RACT learning and prediction, a self-supervised framework enabling the probabilistic retrieval of candidate tables for source columns to constrain relevant column candidates. Experiments demonstrate that this approach outperforms similarity-based baselines on matching multi-table schemas. In subsequent matching experiments, constraining the column search space via top-t tables improves both average matching precision and completeness by up to +70%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RACT, a self-supervised retrieval-augmented framework for multi-table schema matching that learns to probabilistically retrieve candidate tables using referential context (e.g., FK/PK patterns) in order to constrain the column search space. It claims this outperforms similarity-based baselines and that applying a top-t table constraint yields up to +70% gains in average matching precision and completeness.
Significance. If the central experimental claims hold after verification of recall and controls, the work could meaningfully advance holistic schema matching for heterogeneous multi-table sources by moving beyond pure column similarity. The self-supervised use of referential context is a plausible direction, but the absence of reported recall metrics for the table retriever leaves the robustness of the pipeline unproven.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the headline result that top-t table constraints improve precision and completeness by up to +70% is load-bearing for the central claim, yet no recall@ t figures, precision-recall curves, or analysis of ground-truth tables excluded by the retriever are provided. Without these, the reported gains may reflect an easier filtered problem rather than end-to-end robustness.
- [Abstract] Abstract: the empirical gains are stated without any description of the datasets used, the similarity-based baselines, statistical significance tests, or controls for confounding factors such as schema size or domain heterogeneity, preventing assessment of whether the +70% figure generalizes.
minor comments (2)
- [Method] Notation for the probabilistic table retriever and the self-supervised training objective on referential context should be introduced with explicit equations rather than prose descriptions.
- [Method / Experiments] The paper should clarify whether the top-t constraint is applied at inference only or also during training, and how t is chosen.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the experimental validation and clarity of the claims.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the headline result that top-t table constraints improve precision and completeness by up to +70% is load-bearing for the central claim, yet no recall@ t figures, precision-recall curves, or analysis of ground-truth tables excluded by the retriever are provided. Without these, the reported gains may reflect an easier filtered problem rather than end-to-end robustness.
Authors: We agree that the absence of recall metrics for the table retriever leaves the end-to-end robustness unproven. In the revised manuscript we will add recall@t results across multiple values of t, precision-recall curves for the retriever component, and an explicit analysis of ground-truth tables excluded by the top-t constraint. These additions will allow readers to assess whether the reported +70% gains in matching precision and completeness arise from an easier filtered sub-problem or from the retrieval-augmented pipeline itself. revision: yes
-
Referee: [Abstract] Abstract: the empirical gains are stated without any description of the datasets used, the similarity-based baselines, statistical significance tests, or controls for confounding factors such as schema size or domain heterogeneity, preventing assessment of whether the +70% figure generalizes.
Authors: We acknowledge that the abstract, while concise, does not provide sufficient context for the headline result. We will revise the abstract to briefly name the datasets (including schema counts and domains), identify the similarity-based baselines, note that statistical significance testing was performed, and indicate that controls for schema size and domain heterogeneity were applied. The Experiments section already contains these details; the abstract update will make the +70% claim more interpretable without lengthening the paper substantially. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper describes a self-supervised retrieval-augmented framework for multi-table schema matching and reports empirical gains from top-t table constraints, but the provided text contains no equations, fitted parameters, or derivation steps that reduce to their own inputs by construction. Claims rest on experimental comparisons against baselines rather than self-referential logic or self-citation load-bearing premises. No instances of self-definitional relations, fitted inputs renamed as predictions, or ansatz smuggling via citation are present.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ziawasch Abedjan, Patrick Schulze, and Felix Naumann. 2014. DFD: Efficient Functional Dependency Discovery. InProceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management (CIKM ’14). Association for Computing Machinery, New York, NY, USA, 949–958. https: //doi.org/10.1145/2661829.2661884
-
[2]
David Aumueller, Hong-Hai Do, Sabine Massmann, and Erhard Rahm. 2005. Schema and ontology matching with COMA++. InProceedings of the 2005 ACM SIGMOD international conference on Management of data. ACM, Baltimore Mary- land, 906–908. https://doi.org/10.1145/1066157.1066283
-
[3]
Daniel Ayala, Inma Hernández, David Ruiz, and Erhard Rahm. 2022. LEAPME: Learning-based Property Matching with Embeddings.Data & Knowledge Engi- neering137 (Jan. 2022), 101943. https://doi.org/10.1016/j.datak.2021.101943
-
[4]
Gilbert Badaro, Mohammed Saeed, and Paolo Papotti. 2023. Transformers for Tabular Data Representation: A Survey of Models and Applications.Transactions of the Association for Computational Linguistics11 (March 2023), 227–249. https: //doi.org/10.1162/tacl_a_00544
-
[5]
Zohra Bellahsene, Angela Bonifati, Fabien Duchateau, and Yannis Velegrakis
-
[6]
InSchema Matching and Mapping, Zohra Bellahsene, Angela Bonifati, and Erhard Rahm (Eds.)
On Evaluating Schema Matching and Mapping. InSchema Matching and Mapping, Zohra Bellahsene, Angela Bonifati, and Erhard Rahm (Eds.). Springer, Berlin, Heidelberg, 253–291. https://doi.org/10.1007/978-3-642-16518-4_9
-
[7]
Riccardo Cappuzzo, Paolo Papotti, and Saravanan Thirumuruganathan. 2020. Creating Embeddings of Heterogeneous Relational Datasets for Data Integra- tion Tasks. InProceedings of the 2020 ACM SIGMOD International Conference on Management of Data (SIGMOD ’20). Association for Computing Machinery, New York, NY, USA, 1335–1349. https://doi.org/10.1145/3318464.3389742
-
[8]
Raul Castro Fernandez, Essam Mansour, Abdulhakim A. Qahtan, Ahmed Elma- garmid, Ihab Ilyas, Samuel Madden, Mourad Ouzzani, Michael Stonebraker, and Nan Tang. 2018. Seeping Semantics: Linking Datasets Using Word Embeddings for Data Discovery. In2018 IEEE 34th International Conference on Data Engineering (ICDE). IEEE, Paris, 989–1000. https://doi.org/10.110...
-
[9]
Peter Pin-Shan Chen. 1976. The entity-relationship model—toward a unified view of data.ACM Trans. Database Syst.1, 1 (March 1976). https://doi.org/10. 1145/320434.320440
arXiv 1976
-
[10]
Hong-Hai Do and Erhard Rahm. 2002. COMA: a system for flexible combination of schema matching approaches. InProceedings of the 28th international conference on Very Large Data Bases (VLDB ’02). VLDB Endowment, Hong Kong, China, 610–621
2002
-
[11]
Kai Herrmann, Hannes Voigt, Andreas Behrend, Jonas Rausch, and Wolfgang Lehner. 2017. Living in Parallel Realities – Co-Existing Schema Versions with a Bidirectional Database Evolution Language. InProceedings of the 2017 ACM International Conference on Management of Data. 1101–1116. https://doi.org/10. 1145/3035918.3064046 arXiv:1608.05564 [cs]
arXiv 2017
-
[12]
Benjamin Hättasch, Michael Truong-Ngoc, Andreas Schmidt, and Carsten Bin- nig. 2022. It’s AI Match: A Two-Step Approach for Schema Matching Using Embeddings. https://doi.org/10.48550/arXiv.2203.04366 arXiv:2203.04366 [cs]
-
[13]
Jeff Johnson, Matthijs Douze, and Herve Jegou. 2021. Billion-Scale Similarity Search with GPUs.IEEE Transactions on Big Data7, 3 (July 2021), 535–547. https://doi.org/10.1109/TBDATA.2019.2921572
-
[14]
Aamod Khatiwada, Grace Fan, Roee Shraga, Zixuan Chen, Wolfgang Gatterbauer, Renée J. Miller, and Mirek Riedewald. 2023. SANTOS: Relationship-based Se- mantic Table Union Search.Proc. ACM Manag. Data1, 1 (May 2023), 9:1–9:25. https://doi.org/10.1145/3588689
-
[15]
Henning Koehler and Sebastian Link. 2025. Orthogonal Keys High Precision and Recall for Mining Database Keys From Inconsistent and Incomplete Relations. IEEE Transactions on Knowledge and Data Engineering37, 11 (Nov. 2025), 6550–
2025
-
[16]
https://doi.org/10.1109/TKDE.2025.3608680
-
[17]
Christos Koutras, George Siachamis, Andra Ionescu, Kyriakos Psarakis, Jerry Brons, Marios Fragkoulis, Christoph Lofi, Angela Bonifati, and Asterios Katsi- fodimos. 2021. Valentine: Evaluating Matching Techniques for Dataset Discovery. In2021 IEEE 37th International Conference on Data Engineering (ICDE). 468–479. https://doi.org/10.1109/ICDE51399.2021.0004...
-
[18]
Christos Koutras, Jiani Zhang, Xiao Qin, Chuan Lei, Vasileios Ioannidis, Chris- tos Faloutsos, George Karypis, and Asterios Katsifodimos. 2024. OmniMatch: Effective Self-Supervised Any-Join Discovery in Tabular Data Repositories. https://doi.org/doi:10.14778/3749646.3749715 Version Number: 1
-
[19]
Yangning Li, Weizhi Zhang, Yuyao Yang, Wei-Chieh Huang, Yaozu Wu, Junyu Luo, Yuanchen Bei, Henry Peng Zou, Xiao Luo, Yusheng Zhao, Chunkit Chan, Yankai Chen, Zhongfen Deng, Yinghui Li, Hai-Tao Zheng, Dongyuan Li, Renhe Jiang, Ming Zhang, Yangqiu Song, and Philip S. Yu. 2025. Towards Agentic RAG with Deep Reasoning: A Survey of RAG-Reasoning Systems in LLM...
-
[20]
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. 2020. Focal Loss for Dense Object Detection.IEEE Transactions on Pattern Analysis and Machine Intelligence42, 2 (Feb. 2020), 318–327. https://doi.org/10.1109/TPAMI. 2018.2858826
-
[21]
Yurong Liu, Eduardo H. M. Pena, Aécio Santos, Eden Wu, and Juliana Freire. 2025. Magneto: Combining Small and Large Language Models for Schema Matching. Proceedings of the VLDB Endowment18, 8 (April 2025), 2681–2694. https://doi. org/10.14778/3742728.3742757
-
[22]
Jayant Madhavan, Philip A Bernstein, and Erhard Rahm. 2001. Generic Schema Matching with Cupid.VLDB(2001)
2001
-
[23]
Marc Maynou, Sergi Nadal, Raquel Panadero, Javier Flores, Oscar Romero, and Anna Queralt. 2026. Freyja: Efficient Join Discovery in Data Lakes.IEEE Transactions on Knowledge and Data Engineering01 (Jan. 2026), 1–12. https: //doi.org/10.1109/TKDE.2026.3656786
-
[24]
Venkata Vamsikrishna Meduri, Abdul Quamar, Chuan Lei, Xiao Qin, and Berthold Reinwald. 2024. Alfa: active learning for graph neural network-based semantic schema alignment.The VLDB Journal33, 4 (July 2024), 981–1011. https://doi. org/10.1007/s00778-023-00822-z
-
[25]
S. Melnik, H. Garcia-Molina, and E. Rahm. 2002. Similarity flooding: a versatile graph matching algorithm and its application to schema matching. InProceedings 18th International Conference on Data Engineering. IEEE Comput. Soc, San Jose, CA, USA, 117–128. https://doi.org/10.1109/ICDE.2002.994702
-
[26]
Matteo Paganelli, Domenico Beneventano, Francesco Guerra, and Paolo Sottovia
-
[27]
Parallelizing Computations of Full Disjunctions.Big Data Research17 (Sept. 2019), 18–31. https://doi.org/10.1016/j.bdr.2019.07.002
-
[28]
Thorsten Papenbrock, Jens Ehrlich, Jannik Marten, Tommy Neubert, Jan-Peer Rudolph, Martin Schönberg, Jakob Zwiener, and Felix Naumann. 2015. Functional dependency discovery: an experimental evaluation of seven algorithms.Proc. VLDB Endow.8, 10 (June 2015), 1082–1093. https://doi.org/10.14778/2794367. 2794377
-
[29]
Erhard Rahm and Philip A. Bernstein. 2001. A survey of approaches to automatic schema matching.The VLDB Journal10, 4 (Dec. 2001), 334–350. https://doi.org/ 10.1007/s007780100057
-
[30]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. https://doi.org/10.48550/ARXIV.1908.10084 Version Number: 1
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1908.10084 2019
-
[31]
Adel Remadi, Karim El Hage, Yasmina Hobeika, and Francesca Bugiotti. 2024. To prompt or not to prompt: Navigating the use of Large Language Models for integrating and modeling heterogeneous data.Data & Knowledge Engineering 152 (July 2024), 102313. https://doi.org/10.1016/j.datak.2024.102313
-
[32]
Eitam Sheetrit, Menachem Brief, Moshik Mishaeli, and Oren Elisha. 2024. Re- Match: Retrieval Enhanced Schema Matching with LLMs. https://doi.org/10. 48550/arXiv.2403.01567 arXiv:2403.01567 [cs]
arXiv 2024
-
[33]
Roee Shraga and Avigdor Gal. 2021. PoWareMatch: a Quality-aware Deep Learn- ing Approach to Improve Human Schema Matching. https://doi.org/10.48550/ arXiv.2109.07321 arXiv:2109.07321 [cs]
arXiv 2021
-
[34]
Pranav Subramaniam, Udayan Khurana, Kavitha Srinivas, and Horst Samulowitz
-
[35]
InProceedings of the 32nd ACM International Conference on Information and Knowledge Management
NumJoin: Discovering Numeric Joinable Tables with Semantically Related Columns. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management. ACM, Birmingham United Kingdom, 5096–5100. https://doi.org/10.1145/3583780.3614750
-
[36]
Yoshihiko Suhara, Jinfeng Li, Yuliang Li, Dan Zhang, Çağatay Demiralp, Chen Chen, and Wang-Chiew Tan. 2022. Annotating Columns with Pre-trained Lan- guage Models. InProceedings of the 2022 International Conference on Management of Data (SIGMOD ’22). Association for Computing Machinery, New York, NY, USA, 1493–1503. https://doi.org/10.1145/3514221.3517906
-
[37]
Leonard Traeger, Andreas Behrend, and George Karabatis. 2025. SEALM: Seman- tically Enriched Attributes with Language Models for Linkage Recommendation:. InProceedings of the 27th International Conference on Enterprise Information Sys- tems. SCITEPRESS - Science and Technology Publications, Porto, Portugal, 39–50. https://doi.org/10.5220/0013217700003929
-
[38]
Leonard Traeger, Andreas Behrend, and George Karabatis. 2026. Collabora- tive Scoping: Self-Supervised Linkability Assessment for Schema Matching. In Proceedings 29th International Conference on Extending Database Technology (1, Vol. 29). OpenProceedings.org, Tampere, Finland. https://doi.org/10.48786/EDBT. 2026.03
-
[39]
Jianhong Tu, Ju Fan, Nan Tang, Peng Wang, Guoliang Li, Xiaoyong Du, Xiaofeng Jia, and Song Gao. 2023. Unicorn: A Unified Multi-tasking Model for Supporting Matching Tasks in Data Integration.Proceedings of the ACM on Management of Data1, 1 (May 2023), 1–26. https://doi.org/10.1145/3588938
-
[40]
Sha Wang, Yuchen Li, Hanhua Xiao, Bing Tian Dai, Roy Ka-Wei Lee, Yanfei Dong, and Lambert Deng. 2025. LLMATCH: A Unified Schema Matching Frame- work with Large Language Models. https://doi.org/10.48550/arXiv.2507.10897 arXiv:2507.10897 [cs]
-
[41]
Procopiuc, and Divesh Srivastava
Meihui Zhang, Marios Hadjieleftheriou, Beng Chin Ooi, Cecilia M. Procopiuc, and Divesh Srivastava. 2011. Automatic discovery of attributes in relational databases. InProceedings of the 2011 ACM SIGMOD International Conference on Management of data (SIGMOD ’11). Association for Computing Machinery, New York, NY, USA, 109–120. https://doi.org/10.1145/198932...
-
[42]
Müller, Dalitso Banda, Fotis Psallidas, and Jignesh M
Yunjia Zhang, Avrilia Floratou, Joyce Cahoon, Subru Krishnan, Andreas C. Müller, Dalitso Banda, Fotis Psallidas, and Jignesh M. Patel. 2023. Schema Matching using Pre-Trained Language Models. In2023 IEEE 39th International Conference on Data Engineering (ICDE). IEEE, Anaheim, CA, USA, 1558–1571. https://doi. org/10.1109/ICDE55515.2023.00123
-
[43]
Yu Zhang, Di Mei, Haozheng Luo, Chenwei Xu, and Richard Tzong-Han Tsai
-
[44]
SMUTF: Schema Matching Using Generative Tags and Hybrid Features. Information Systems133 (Aug. 2025), 102570. https://doi.org/10.1016/j.is.2025. 102570
-
[45]
Erkang Zhu, Dong Deng, Fatemeh Nargesian, and Renée J. Miller. 2019. JOSIE: Overlap Set Similarity Search for Finding Joinable Tables in Data Lakes. In Proceedings of the 2019 International Conference on Management of Data. ACM, Amsterdam Netherlands, 847–864. https://doi.org/10.1145/3299869.3300065
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.