Larch: Learned Query Optimization for Semantic Predicates
Pith reviewed 2026-06-27 19:19 UTC · model grok-4.3
The pith
Larch learns filter evaluation orders for semantic predicates in AI SQL queries using embeddings and graph models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Larch encodes arbitrary semantic filter expression trees using an embedding-augmented Gated Graph Neural Network and formulates the filter evaluation order as a Markov decision process in Larch-A2C; Larch-Sel instead leverages a supervised learning model to predict filter selectivities and applies dynamic programming to find a near-optimal evaluation order for each input row. Both variants reduce total token cost overhead by 3x-19x compared with Palimpzest and Quest across diverse real-world datasets and synthetic workloads.
What carries the argument
Embedding-augmented Gated Graph Neural Network combined with Markov decision process formulation for Larch-A2C, and supervised selectivity prediction followed by dynamic programming for Larch-Sel, to determine low-cost orders of semantic filter applications.
If this is right
- Semantic filters can be treated as optimizable operators rather than black boxes in database engines.
- Query planners gain the ability to reorder AI predicates at both expression-tree and per-row levels.
- Token costs for analytical queries over text, images, and video become low enough for larger datasets.
- The same learned ordering approach can be applied to other high-latency semantic operators.
Where Pith is reading between the lines
- If embeddings can be generated on the fly at modest cost, the framework could be extended to data without pre-existing vectors.
- The selectivity predictor in Larch-Sel might be replaced by online learning that adapts during query execution.
- The MDP formulation in Larch-A2C could incorporate latency and accuracy trade-offs beyond token count.
Load-bearing premise
Unstructured data are accompanied by semantic embeddings that allow efficient comparisons between AI filter prompts and data values.
What would settle it
Run the same queries on a dataset whose embeddings show no correlation with actual semantic filter outcomes and measure whether token usage still drops by 3x-19x.
Figures

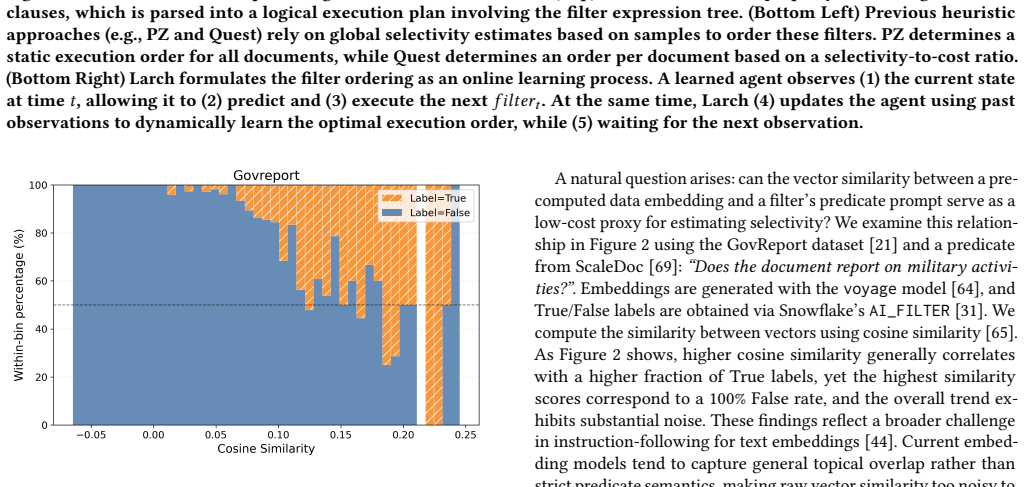
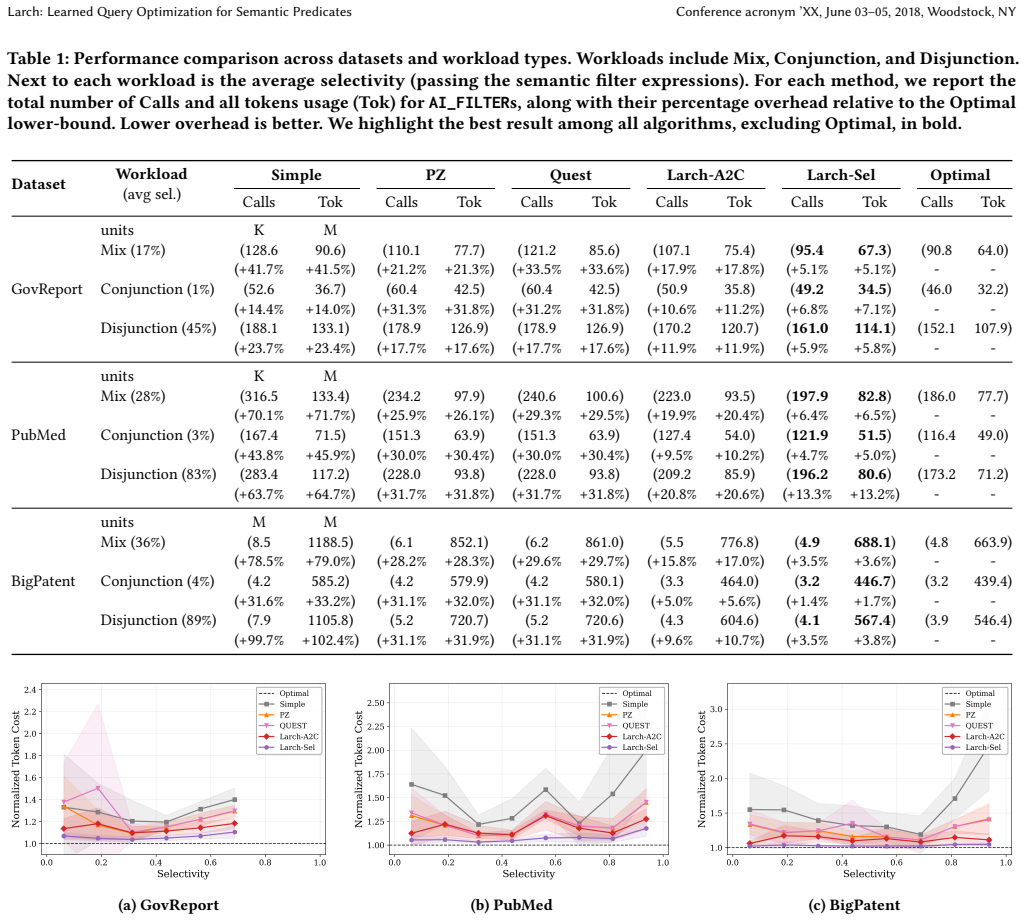

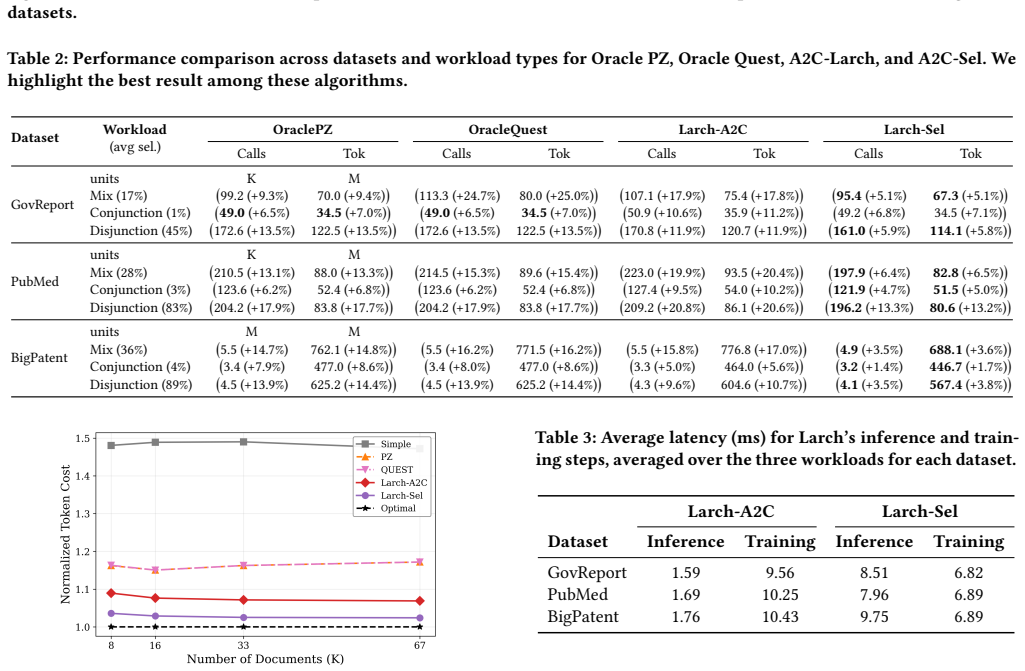
read the original abstract
With the advent of Large Language Models (LLMs), many database systems introduced semantic operators that enabled analytical queries over unstructured data (e.g. text, images, videos). Semantic operators typically incur high inference costs and latencies making semantic (AI) SQL queries challenging to apply on large scale datasets. At the same time, their semantic nature leads database engines to treat them as black boxes, making AISQL queries difficult to optimize. In this paper, we introduce Larch, a framework for optimizing the execution of semantic filters in AI SQL queries. Larch was inspired by two key observations: i) the high latency of semantic operators leaves significant room for computationally-heavy runtime optimization techniques, ii) unstructured data are typically accompanied by semantic information in the form of embeddings allowing for efficient semantic comparisons between AI_FILTER prompts and data values. Based on these two key observations, we present two Larch variants: Larch-A2C and Larch-Sel. Larch-A2C encodes arbitrary semantic filters expression tree using an embedding-augmented Gated Graph Neural Network and formulates the filter evaluation order as a Markov decision process. In contrast, Larch-Sel leverages a supervised learning model to predict filter selectivities, subsequently applying dynamic programming to find a near-optimal evaluation order for each input row. Evaluated across diverse real-world datasets and comprehensive synthetic workloads, both Larch variants always outperform existing semantic filter optimization techniques in terms of token usage. Our results demonstrate that Larch is robust across diverse workloads, reducing total token cost overhead by 3x-19x compared to Palimpzest and Quest.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Larch, a framework for optimizing semantic (AI) filters in database queries over unstructured data. It is motivated by the high latency of semantic operators (allowing heavy optimization) and the typical availability of embeddings for semantic comparisons. Two variants are presented: Larch-A2C encodes filter expression trees with an embedding-augmented Gated Graph Neural Network and casts ordering as an MDP; Larch-Sel trains a supervised selectivity model and uses dynamic programming for per-row ordering. The central empirical claim is that both variants consistently outperform Palimpzest and Quest, reducing token-cost overhead by 3x–19x across real-world datasets and synthetic workloads.
Significance. If the reported gains are reproducible and generalize, the work would meaningfully advance practical deployment of semantic operators by lowering LLM inference costs. The embedding-based precondition and the two learned-ordering strategies constitute a concrete technical contribution to AI-SQL optimization. The paper explicitly states the embedding assumption rather than hiding it.
major comments (1)
- [Abstract / Evaluation] Abstract (and Evaluation section referenced therein): the central claim of consistent 3x–19x token-cost reduction is presented without any description of workloads, training procedures, number of runs, error bars, or exact definitions of 'token cost overhead.' This information is load-bearing for assessing whether the reported gains reflect generalization rather than fitting.
Simulated Author's Rebuttal
We thank the referee for their review. We agree that the abstract would benefit from greater specificity on experimental details and will revise it (and cross-references to the evaluation section) to address this.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract (and Evaluation section referenced therein): the central claim of consistent 3x–19x token-cost reduction is presented without any description of workloads, training procedures, number of runs, error bars, or exact definitions of 'token cost overhead.' This information is load-bearing for assessing whether the reported gains reflect generalization rather than fitting.
Authors: We agree the abstract is too terse on these points. In revision we will expand it to name the real-world datasets, characterize the synthetic workloads, state that results are averaged over multiple runs with error bars shown in Section 5, and give a concise definition of token-cost overhead (extra LLM tokens incurred by non-optimal filter ordering relative to the per-row minimum). The evaluation section already specifies training procedures for both Larch-A2C and Larch-Sel, the number of runs, and reports error bars; we will add explicit forward references from the abstract. These changes improve readability without changing any empirical claims. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's core contribution consists of two learned components (GNN-based MDP policy in Larch-A2C; supervised selectivity model + DP in Larch-Sel) that are trained on data and then applied to optimize filter ordering on held-out workloads. The reported 3x-19x token reductions are measured empirical outcomes on real-world and synthetic datasets, not quantities that reduce by definition or construction to the training inputs. No self-definitional equations, fitted-input-renamed-as-prediction, or load-bearing self-citations appear in the provided text; the embedding precondition is stated explicitly rather than smuggled. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Artificial Analysis. 2026. LLM Leaderboard - Comparison of over 100 AI models from OpenAI, Google, DeepSeek & others. https://artificialanalysis. ai/leaderboards/models/prompt-options/multiple/medium
2026
-
[2]
Ron Avnur and Joseph M. Hellerstein. 2000. Eddies: Continuously Adaptive Query Processing. InProceedings of the 2000 ACM SIGMOD International Conference on Management of Data. ACM, 261–272. doi:10.1145/342009.335420
-
[3]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. 2016. Layer Normaliza- tion. arXiv:1607.06450 [stat.ML] https://arxiv.org/abs/1607.06450
Pith/arXiv arXiv 2016
-
[4]
Stable Baselines. [n. d.]. A2C — Stable Baselines documentation. https://stable- baselines.readthedocs.io/en/master/modules/a2c.html
-
[5]
Peter W. Battaglia, Jessica B. Hamrick, Victor Bapst, Alvaro Sanchez-Gonzalez, Vinicius Zambaldi, Mateusz Malinowski, Andrea Tacchetti, David Raposo, Adam Santoro, Ryan Faulkner, Caglar Gulcehre, Francis Song, Andrew Ballard, Justin Gilmer, George Dahl, Ashish Vaswani, Kelsey Allen, Charles Nash, Victoria Langston, Chris Dyer, Nicolas Heess, Daan Wierstra...
Pith/arXiv arXiv 2018
-
[6]
Richard Bellman. 1957. A Markovian decision process.Journal of mathematics and mechanics6, 5 (1957), 679–684
1957
-
[7]
Lee, and Deepti Raghavan
Ugur Cetintemel, Shu Chen, Alexander W. Lee, and Deepti Raghavan
-
[8]
arXiv:2508.05012 [cs.DB] https://arxiv.org/abs/2508.05012
Making Prompts First-Class Citizens for Adaptive LLM Pipelines. arXiv:2508.05012 [cs.DB] https://arxiv.org/abs/2508.05012
-
[9]
Jin Chen, Guanyu Ye, Yan Zhao, Shuncheng Liu, Liwei Deng, Xu Chen, Rui Zhou, and Kai Zheng. 2022. Efficient Join Order Selection Learning with Graph-based Representation. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining(Washington DC, USA)(KDD ’22). Association for Computing Machinery, New York, NY, USA, 97–107. doi:1...
-
[10]
Lingjiao Chen, Matei Zaharia, and James Zou. 2023. FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance. arXiv:2305.05176 [cs.LG] https://arxiv.org/abs/2305.05176
Pith/arXiv arXiv 2023
-
[11]
Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Yoshua Bengio. 2014. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv:1412.3555 [cs.NE] https://arxiv.org/abs/1412.3555 Larch: Learned Query Optimization for Semantic Predicates Conference acronym ’XX, June 03–05, 2018, Woodstock, NY
Pith/arXiv arXiv 2014
-
[12]
Franck Dernoncourt and Ji Young Lee. 2017. PubMed 200k RCT: a Dataset for Sequential Sentence Classification in Medical Abstracts. InProceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Greg Kondrak and Taro Watanabe (Eds.). Asian Federation of Natural Language Processing, Taipei, Taiwan, 308–31...
2017
-
[13]
Amol Deshpande and Joseph M. Hellerstein. 2004. An Initial Study of Overheads of Eddies.ACM SIGMOD Record33, 1 (2004), 44–49. doi:10.1145/974121.974129
-
[14]
Benedikt Didrich, Haralampos Gavriilidis, Vasilis Gkolemis, Matthias Boehm, and Volker Markl. 2025. Learning to Accelerate: Tuning Data Transfer Parameters. Proceedings of the VLDB Endowment. ISSN2150 (2025), 8097
2025
-
[15]
Philippe Flajolet, Éric Fusy, Olivier Gandouet, and Frédéric Meunier. 2007. Hy- perLogLog: The Analysis of a Near-Optimal Cardinality Estimation Algorithm. Proceedings of the International Conference on Analysis of Algorithms (AofA)(2007), 127–146. https://algo.inria.fr/flajolet/Publications/FlFuGaMe07.pdf
2007
-
[16]
Yao Fu, Leyang Xue, Yeqi Huang, Andrei-Octavian Brabete, Dmitrii Ustiugov, Yuvraj Patel, and Luo Mai. 2024. {ServerlessLLM}:{Low-Latency} serverless inference for large language models. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 135–153
2024
-
[17]
Vasilis Giannakouris, Murat Koc, Konstantinos Gkoutzis, and Jan Rellermeyer
-
[18]
InProceedings of the ACM SIGMOD International Conference on Man- agement of Data
SwellDB: Dynamic Query-Driven Table Generation with Large Language Models. InProceedings of the ACM SIGMOD International Conference on Man- agement of Data. Association for Computing Machinery, New York, NY, USA. doi:10.1145/3722212.3725136
-
[19]
Parker Glenn, Parag Pravin Dakle, Liang Wang, and Preethi Raghavan. 2024. BlendSQL: A Scalable Dialect for Unifying Hybrid Question Answering in Rela- tional Algebra. arXiv:2402.17882 [cs.CL] https://arxiv.org/abs/2402.17882
arXiv 2024
-
[20]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, and et al. 2024. The Llama 3 Herd of Models. arXiv:2407.21783 [cs.AI] https://arxiv.org/ abs/2407.21783
Pith/arXiv arXiv 2024
-
[21]
Ivo Grondman, Lucian Busoniu, Gabriel A. D. Lopes, and Robert Babuska. 2012. A Survey of Actor-Critic Reinforcement Learning: Standard and Natural Policy Gra- dients.IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews)42, 6 (2012), 1291–1307. doi:10.1109/TSMCC.2012.2218595
-
[22]
2021.Tapping the power of unstructured data
Tam Harbert. 2021.Tapping the power of unstructured data. MIT Sloan School of Management. https://mitsloan.mit.edu/ideas-made-to-matter/tapping-power- unstructured-data
2021
-
[23]
Luyang Huang, Shuyang Cao, Nikolaus Parulian, Heng Ji, and Lu Wang. 2021. Efficient Attentions for Long Document Summarization. arXiv:2104.02112 [cs.CL] https://arxiv.org/abs/2104.02112
arXiv 2021
-
[24]
Toshihide Ibaraki and Tiko Kameda. 1984. Optimal Weighted Ancestor Systems and Their Application to Testing Membership in Context-Free Languages and Their Subsets.J. Comput. System Sci.28, 2 (1984), 232–249
1984
-
[25]
David Justen, Daniel Ritter, Campbell Fraser, Andrew Lamb, Allison Lee, Thomas Bodner, Mhd Yamen Haddad, Steffen Zeuch, Volker Markl, and Matthias Boehm
-
[26]
Polar: Adaptive and non-invasive join order selection via plans of least resistance.Proceedings of the VLDB Endowment17, 6 (2024), 1350–1363
2024
-
[27]
Daniel Kang, Edward Gan, Peter Bailis, Tatsunori Hashimoto, and Matei Zaharia. 2022. Approximate Selection with Guarantees using Proxies. arXiv:2004.00827 [cs.DB] https://arxiv.org/abs/2004.00827
arXiv 2022
-
[28]
Andrej Karpathy. 2019. A recipe for training neural networks. https://karpathy. github.io/2019/04/25/recipe/
2019
-
[29]
Ferdi Kossmann, Ziniu Wu, Alex Turk, Nesime Tatbul, Lei Cao, and Samuel Madden. 2024. CascadeServe: Unlocking Model Cascades for Inference Serving. arXiv:2406.14424 [cs.DC] https://arxiv.org/abs/2406.14424
arXiv 2024
-
[30]
Ravi Krishnamurthy, Haran Boral, and Carlo Zaniolo. 1986. Optimization of Nonrecursive Queries. InProceedings of the 12th International Conference on Very Large Data Bases (VLDB). 128–137
1986
-
[31]
Quoc V. Le and Tomas Mikolov. 2014. Distributed Representations of Sentences and Documents. arXiv:1405.4053 [cs.CL] https://arxiv.org/abs/1405.4053
Pith/arXiv arXiv 2014
-
[32]
Quanzhong Li, Minglong Shao, Volker Markl, Kevin S. Beyer, Latha Colby, and Guy M. Lohman. 2007. Adaptively Reordering Joins during Query Execution. In Proceedings of the 23rd International Conference on Data Engineering (ICDE). IEEE, 26–35. doi:10.1109/ICDE.2007.367848
-
[33]
Yiming Lin, Madelon Hulsebos, Ruiying Ma, Shreya Shankar, Sepanta Zeigham, Aditya G. Parameswaran, and Eugene Wu. 2024. Towards Accurate and Efficient Document Analytics with Large Language Models. arXiv:2405.04674 [cs.DB] https://arxiv.org/abs/2405.04674
arXiv 2024
-
[34]
Paweł Liskowski, Benjamin Han, Paritosh Aggarwal, Bowei Chen, Boxin Jiang, Nitish Jindal, Zihan Li, Aaron Lin, Kyle Schmaus, Jay Tayade, Weicheng Zhao, Anupam Datta, Nathan Wiegand, and Dimitris Tsirogiannis. 2025. Cortex AISQL: A Production SQL Engine for Unstructured Data. arXiv:2511.07663 [cs.DB] https://arxiv.org/abs/2511.07663
Pith/arXiv arXiv 2025
-
[35]
Paweł Liskowski and Kyle Schmaus. 2026. Streaming Model Cascades for Seman- tic SQL. arXiv:2604.00660 [cs.DB] https://arxiv.org/abs/2604.00660
arXiv 2026
-
[36]
Chunwei Liu, Matthew Russo, Michael Cafarella, Lei Cao, Peter Baile Chen, Zui Chen, Michael Franklin, Tim Kraska, Samuel Madden, Rana Shahout, et al. 2025. Palimpzest: Optimizing ai-powered analytics with declarative query processing. InProceedings of the Conference on Innovative Database Research (CIDR). 2
2025
-
[37]
Ilya Loshchilov and Frank Hutter. 2017. SGDR: Stochastic Gradient Descent with Warm Restarts. arXiv:1608.03983 [cs.LG] https://arxiv.org/abs/1608.03983
Pith/arXiv arXiv 2017
-
[38]
Samuel Madden, Michael Cafarella, Michael Franklin, and Tim Kraska. 2024. Databases unbound: Querying all of the world’s bytes with AI.Proceedings of the VLDB Endowment17, 12 (2024), 4546–4554
2024
-
[39]
Hongzi Mao, Malte Schwarzkopf, Shaileshh Bojja Venkatakrishnan, Zili Meng, and Mohammad Alizadeh. 2019. Learning Scheduling Algorithms for Data Pro- cessing Clusters. arXiv:1810.01963 [cs.LG] https://arxiv.org/abs/1810.01963
arXiv 2019
-
[40]
Volker Markl, Peter J Haas, Marcel Kutsch, Nimrod Megiddo, Utkarsh Srivastava, and Tam Minh Tran. 2007. Consistent selectivity estimation via maximum entropy.The VLDB journal16, 1 (2007), 55–76
2007
-
[41]
Markl, N
V. Markl, N. Megiddo, M. Kutsch, T. M. Tran, P. Haas, and U. Srivastava. 2005. Consistently estimating the selectivity of conjuncts of predicates. InProceedings of the 31st International Conference on Very Large Data Bases(Trondheim, Norway) (VLDB ’05). VLDB Endowment, 373–384
2005
-
[42]
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Efficient Estimation of Word Representations in Vector Space. arXiv:1301.3781 [cs.CL] https://arxiv.org/abs/1301.3781
Pith/arXiv arXiv 2013
-
[43]
2026.API Pricing
OpenAI. 2026.API Pricing. https://platform.openai.com/docs/pricing Accessed: 2026-02
2026
-
[44]
James Jie Pan, Jianguo Wang, and Guoliang Li. 2023. Survey of Vector Database Management Systems. arXiv:2310.14021 [cs.DB] https://arxiv.org/abs/2310.14021
arXiv 2023
-
[45]
Liana Patel, Siddharth Jha, Melissa Pan, Harshit Gupta, Parth Asawa, Carlos Guestrin, and Matei Zaharia. 2025. Semantic Operators: A Declarative Model for Rich, AI-based Data Processing. arXiv:2407.11418 [cs.DB] https://arxiv.org/abs/ 2407.11418
arXiv 2025
-
[46]
Daniela Pavlenco. 2026. How to Load Embedding Models into Oracle AI Database in 2026. https://blogs.oracle.com/developers/how-to-load-embedding-models- into-oracle-ai-database-in-2026
2026
-
[47]
Letian Peng, Yuwei Zhang, Zilong Wang, Jayanth Srinivasa, Gaowen Liu, Zihan Wang, and Jingbo Shang. 2024. Answer is All You Need: Instruction-following Text Embedding via Answering the Question. arXiv:2402.09642 [cs.CL] https: //arxiv.org/abs/2402.09642
arXiv 2024
-
[48]
Lorien Y Pratt. 1992. Discriminability-based transfer between neural networks. Advances in neural information processing systems5 (1992)
1992
-
[49]
Stephen Robertson, Hugo Zaragoza, et al . 2009. The probabilistic relevance framework: BM25 and beyond.Foundations and Trends®in Information Retrieval 3, 4 (2009), 333–389
2009
-
[50]
Mushtari Sadia, Amrita Roy Chowdhury, and Ang Chen. 2025. A Case for Computing on Unstructured Data. arXiv:2509.14601 [cs.DB] https://arxiv.org/ abs/2509.14601
arXiv 2025
-
[51]
Dario Satriani, Enzo Veltri, Donatello Santoro, Sara Rosato, Simone Varriale, and Paolo Papotti. 2025. Logical and Physical Optimizations for SQL Query Execution over Large Language Models.Proc. ACM Manag. Data3, 3, Article 181 (June 2025), 28 pages. doi:10.1145/3725411
-
[52]
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel
-
[53]
arXiv:1506.02438 [cs.LG] https://arxiv.org/abs/1506.02438
High-Dimensional Continuous Control Using Generalized Advantage Estimation. arXiv:1506.02438 [cs.LG] https://arxiv.org/abs/1506.02438
-
[54]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov
-
[55]
arXiv:1707.06347 [cs.LG] https: //arxiv.org/abs/1707.06347
Proximal Policy Optimization Algorithms. arXiv:1707.06347 [cs.LG] https: //arxiv.org/abs/1707.06347
-
[56]
Shreya Shankar, Tristan Chambers, Tarak Shah, Aditya G. Parameswaran, and Eugene Wu. 2025. DocETL: Agentic Query Rewriting and Evaluation for Complex Document Processing. arXiv:2410.12189 [cs.DB] https://arxiv.org/abs/2410.12189
arXiv 2025
-
[57]
Eva Sharma, Chen Li, and Lu Wang. 2019. BIGPATENT: A Large-Scale Dataset for Abstractive and Coherent Summarization. arXiv:1906.03741 [cs.CL] https: //arxiv.org/abs/1906.03741
Pith/arXiv arXiv 2019
-
[58]
2025.AI_EMBED | Snowflake Documentation
Snowflake Inc. 2025.AI_EMBED | Snowflake Documentation. Snowflake Inc. https://docs.snowflake.com/en/sql-reference/functions/ai_embed Accessed: 2025- 03-30
2025
-
[59]
2025.AI_FILTER | Snowflake Documentation
Snowflake Inc. 2025.AI_FILTER | Snowflake Documentation. Snowflake Inc. https://docs.snowflake.com/en/sql-reference/functions/ai_filter Accessed: 2025- 03-30
2025
-
[60]
Ji Sun, Guoliang Li, James Pan, Jiang Wang, Yongqing Xie, Ruicheng Liu, and Wen Nie. 2025. GaussDB-Vector: A Large-Scale Persistent Real-Time Vector Database for LLM Applications.Proceedings of the VLDB Endowment18, 12 (2025), 4951–4963
2025
-
[61]
Zhaoze Sun, Qiyan Deng, Chengliang Chai, Kaisen Jin, Xinyu Guo, Han Han, Ye Yuan, Guoren Wang, and Lei Cao. 2025. Quest: Query optimization in unstruc- tured document analysis.arXiv preprint arXiv:2507.06515(2025)
arXiv 2025
-
[62]
Richard S. Sutton. 1988. Learning to Predict by the Methods of Temporal Differ- ences.Mach. Learn.3, 1 (Aug. 1988), 9–44. doi:10.1023/A:1022633531479
-
[63]
Sutton and Andrew G
Richard S. Sutton and Andrew G. Barto. 1998.Reinforcement Learning: An Intro- duction. Vol. 135. MIT Press, Cambridge, MA
1998
-
[64]
Jan Vincent Szlang, Sebastian Bress, Sebastian Cattes, Jonathan Dees, Florian Funke, Max Heimel, Michel Oleynik, Ismail Oukid, and Tobias Maltenberger. 2025. Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Fuheng Zhao, Paweł Liskowski, Zihan Li, Benjamin Han, Puxuan Yu, Varich Boonsanong, Dimitris Tsirogiannis, and Anupam Datta Workload Insights f...
-
[65]
Dixin Tang, Zechao Shang, Aaron J Elmore, Sanjay Krishnan, and Michael J Franklin. 2020. CrocodileDB in action: resource-efficient query execution by exploiting time slackness.Proceedings of the VLDB Endowment13, 12 (2020), 2937–2940
2020
-
[66]
Immanuel Trummer. 2025. Implementing Semantic Join Operators Efficiently. arXiv:2510.08489 [cs.DB] https://arxiv.org/abs/2510.08489
arXiv 2025
-
[67]
Immanuel Trummer, Junxiong Wang, Deepak Maram, Samuel Moseley, Saehan Jo, and Joseph Antonakakis. 2019. SkinnerDB: Regret-Bounded Query Evaluation via Reinforcement Learning. InProceedings of the 2019 International Conference on Management of Data (SIGMOD/PODS ’19). ACM, 1153–1170. doi:10.1145/3299869. 3300088
-
[68]
Kostas Tzoumas, Timos Sellis, and Christian S Jensen. 2008. A reinforcement learning approach for adaptive query processing.History(2008), 1–25
2008
-
[69]
Voyage AI. 2025. Voyage-3-Large: A State-of-the-Art General-Purpose Embedding Model. https://blog.voyageai.com/2025/01/07/voyage-3-large/. Accessed: 2026- 02-09
2025
-
[70]
Xubo Wang, Lu Qin, Xuemin Lin, Ying Zhang, and Lijun Chang. 2017. Leveraging set relations in exact set similarity join.Proc. VLDB Endow.10, 9 (May 2017), 925–936. doi:10.14778/3099622.3099624
-
[71]
2022.Graph Neural Networks: Foundations, Frontiers, and Applications
Lingfei Wu, Peng Cui, Jian Pei, and Liang Zhao (Eds.). 2022.Graph Neural Networks: Foundations, Frontiers, and Applications. Springer Nature Singapore. doi:10.1007/978-981-16-6054-2
-
[72]
2026.Inside OpenAI’s in-house data agent
Bonnie Xu, Aravind Suresh, and Emma Tang. 2026.Inside OpenAI’s in-house data agent. OpenAI. https://openai.com/index/inside-our-in-house-data-agent/
2026
-
[73]
Puxuan Yu, Luke Merrick, Gaurav Nuti, and Daniel Campos. 2024. Arctic-Embed 2.0: Multilingual Retrieval Without Compromise. arXiv:2412.04506 [cs.CL] https: //arxiv.org/abs/2412.04506
arXiv 2024
-
[74]
Hengrui Zhang, Yulong Hui, Yihao Liu, and Huanchen Zhang. 2025. ScaleDoc: Scaling LLM-based Predicates over Large Document Collections. arXiv:2509.12610 [cs.DB] https://arxiv.org/abs/2509.12610
Pith/arXiv arXiv 2025
-
[75]
Xinyi Zhang, Hong Wu, Yang Li, Zhengju Tang, Jian Tan, Feifei Li, and Bin Cui
-
[76]
An efficient transfer learning based configuration adviser for database tuning.Proceedings of the VLDB Endowment17, 3 (2023), 539–552
2023
-
[77]
Fuheng Zhao, Divyakant Agrawal, and Amr El Abbadi. 2024. Hybrid Querying Over Relational Databases and Large Language Models. arXiv:2408.00884 [cs.DB] https://arxiv.org/abs/2408.00884
arXiv 2024
-
[78]
Fuheng Zhao, Jiayue Chen, Yiming Pan, Tahseen Rabbani, Sohaib, Divyakant Agrawal, Amr El Abbadi, Paritosh Aggarwal, Anupam Datta, and Dimitris Tsirogiannis. 2025. Access Paths for Efficient Ordering with Large Language Models. arXiv:2509.00303 [cs.DB] https://arxiv.org/abs/2509.00303
Pith/arXiv arXiv 2025
-
[79]
Jianqiao Zhu, Navneet Potti, Saket Saurabh, and Jignesh M Patel. 2017. Looking ahead makes query plans robust: Making the initial case with in-memory star schema data warehouse workloads.Proceedings of the VLDB Endowment10, 8 (2017), 889–900
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.