From `May' to `Is': Certainty Distortion in Language Model Rewriting
Pith reviewed 2026-06-27 20:15 UTC · model grok-4.3
The pith
Language models increase expressed certainty in most rewrites of scientific and medical text.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
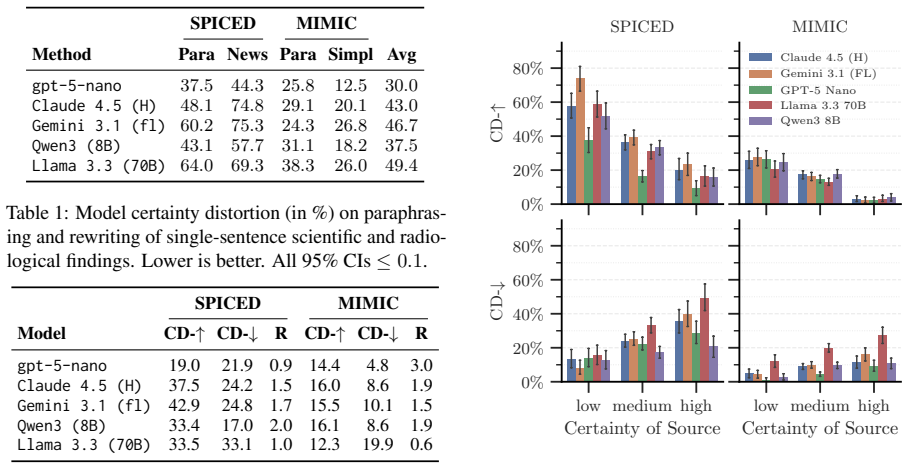
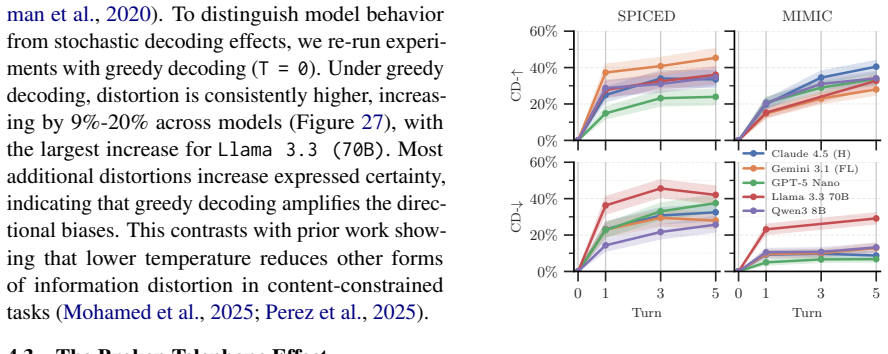
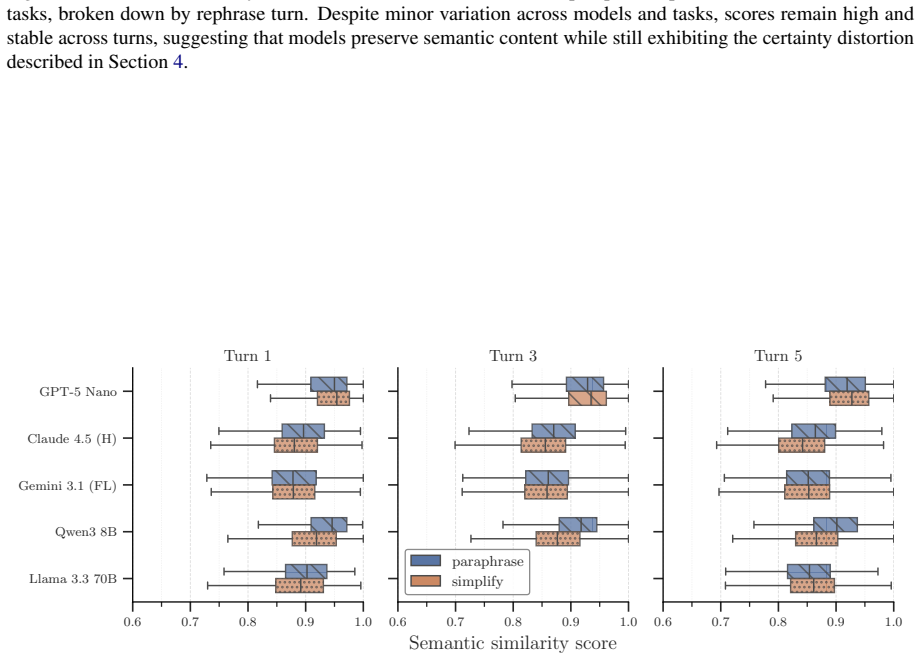
Certainty distortion, defined as meaningful changes in expressed certainty when semantic content is preserved, affects up to 75% of LM outputs and is systematically asymmetric in rewriting tasks, with most LMs being 1.5-2× more likely to increase the expressed certainty than to decrease it. These effects can compound over repeated paraphrasing: in the medical domain, one model increases certainty of 20% of examples after a single iteration, rising to 40% after five iterations. Prompt-based interventions reduce overall distortion but do not eliminate it.
What carries the argument
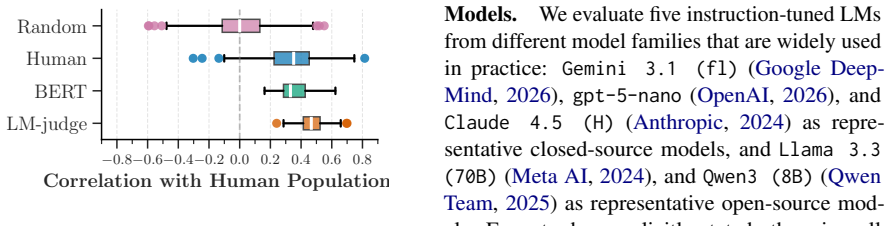
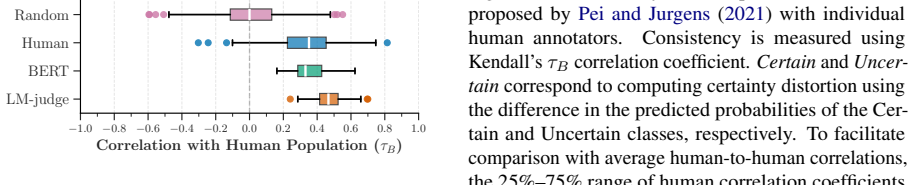
An LM-based evaluation metric for expressed certainty that aligns with population-level human judgments, used to measure changes during rewriting tasks that preserve semantic content.
If this is right
- Repeated paraphrasing of the same medical or scientific text can steadily raise the certainty readers encounter.
- Prompt interventions lower the rate of distortion across model sizes but leave a residual bias toward higher certainty.
- Users who rely on model outputs for decisions in medicine or science may base those decisions on inflated confidence levels.
- The asymmetry holds across different model families and persists even when the task is only to rewrite while keeping meaning constant.
Where Pith is reading between the lines
- Systems that chain multiple rewrites or summaries may need separate certainty checks at each step to avoid progressive inflation.
- Training objectives that explicitly penalize unprompted certainty shifts could be tested as a direct countermeasure.
- Public readers may benefit from seeing both the original and rewritten versions side by side when certainty matters.
Load-bearing premise
The LM-based metric accurately reflects human population judgments of certainty and that rewrites preserve the underlying facts while only shifting how confidently those facts are stated.
What would settle it
A controlled test in which human raters assign certainty scores to original and rewritten texts that contradict the LM metric on a majority of examples, or a rewriting setup where models show no net increase in certainty when semantic content is held fixed.
Figures

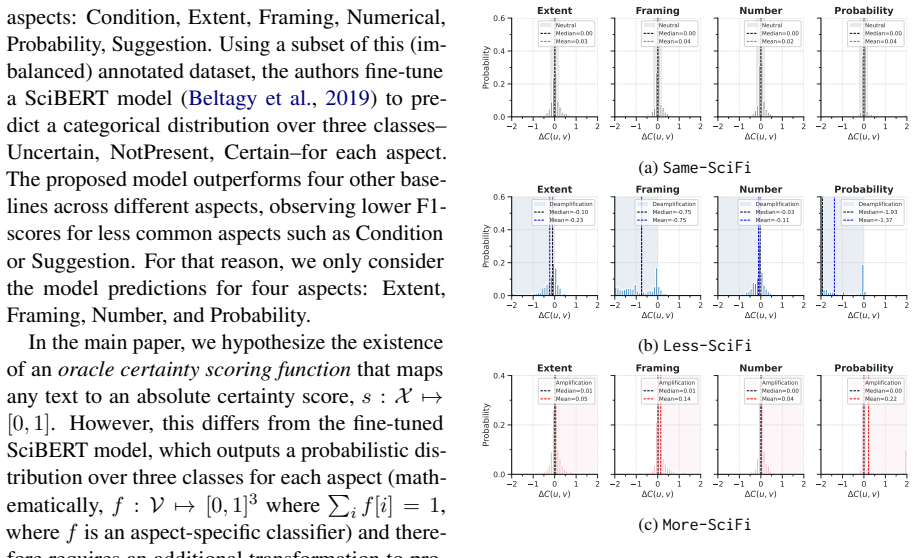

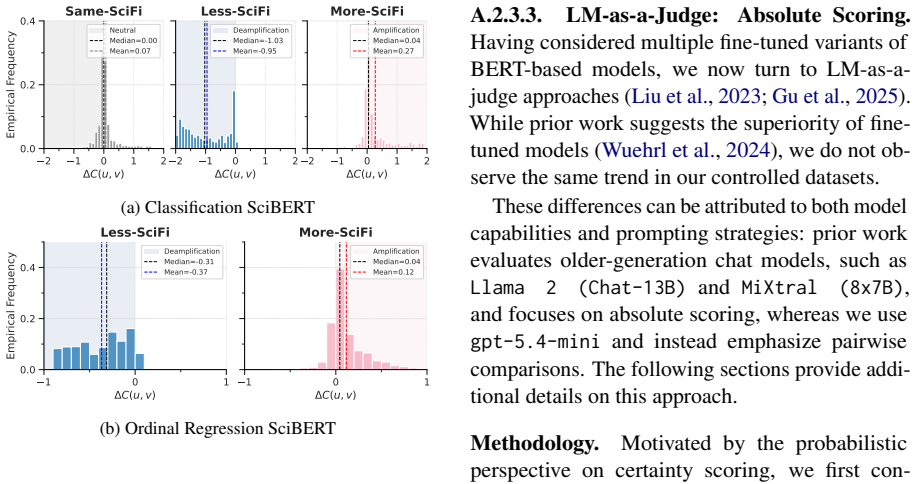


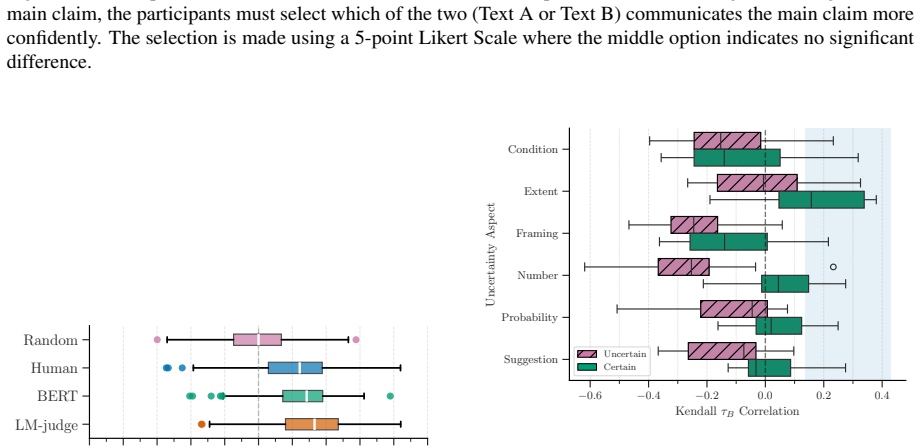









read the original abstract
Humans increasingly turn to Language Models (LMs) in ways that shape beliefs and drive decisions, including discussing, rewriting, and summarizing information from scientific articles, news, and medical reports. However, in these domains, where how confidently a claim is expressed matters, little is known about whether LMs faithfully preserve it. In this work, we investigate certainty distortion in LMs, defined as meaningful changes in expressed certainty when semantic content is preserved. We propose an LM-based evaluation metric that is consistent with population-level judgments of certainty. Using this metric, we characterize certainty distortion across different sizes and families of models in the context of scientific and medical communication tasks. Our results show that certainty distortion affects up to 75\% of LM outputs and is systematically asymmetric in rewriting tasks with most LMs being 1.5-2$\times$ more likely to increase the expressed certainty than to decrease it. These effects can compound over repeated paraphrasing: in the medical domain, claude-haiku-4-5 increases certainty of 20\% examples after a single iteration, increasing to 40\% after five iterations. Prompt-based interventions reduce overall certainty distortion but do not eliminate it. Together, these findings reveal a general bias toward inflating expressed certainty, with direct implications for users who rely on LMs in high-stakes domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates certainty distortion in language models (LMs) during rewriting tasks, defined as meaningful changes in expressed certainty while preserving semantic content. It proposes an LM-based evaluation metric claimed to be consistent with population-level human judgments of certainty. Using this metric on scientific and medical communication tasks, the work reports that distortion affects up to 75% of LM outputs, with systematic asymmetry (most models 1.5-2× more likely to increase than decrease certainty), compounding effects over repeated paraphrasing (e.g., Claude Haiku from 20% to 40% after five iterations in medical domain), and partial mitigation via prompt interventions.
Significance. If the metric and semantic-preservation assumptions hold, the results identify a general bias toward certainty inflation in LMs with direct relevance to high-stakes domains where expressed certainty affects belief formation and decisions. The empirical scope across model families/sizes and the compounding analysis add value; the prompt-intervention results provide a starting point for mitigation.
major comments (3)
- [Abstract / metric description] Abstract and metric-validation section: The headline claims (75% distortion rate, 1.5-2× asymmetry, compounding percentages) rest on an LM-based evaluator treated as ground truth, yet the manuscript provides no correlation coefficient with human judgments, no human-study sample size, no inter-annotator agreement, and no controls for the evaluator LM's own certainty bias. Without these, the quantitative results and directionality are uninterpretable.
- [Task setup / evaluation protocol] Task-setup and evaluation sections: The central assumption that rewrites preserve semantic content while altering only certainty is stated but not quantified; no semantic-similarity thresholds, human validation rates for content preservation, or controls for unintended meaning shifts are reported, making it impossible to isolate certainty distortion from other changes.
- [Results on asymmetry and multi-iteration experiments] Results sections on asymmetry and compounding: The reported 1.5-2× increase bias and iteration-wise increases (e.g., 20% → 40%) are presented without error bars, statistical significance tests against a null of no distortion, or ablation on the choice of 'meaningful change' threshold in the metric, leaving the load-bearing percentages vulnerable to metric-definition choices.
minor comments (2)
- [Metric definition] Notation for the certainty metric should be introduced with an explicit equation or pseudocode rather than prose description only.
- [Figures] Figure captions for model-family comparisons should include the exact number of examples per condition and the precise threshold used for 'meaningful change'.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback. We address each major comment below, acknowledging where the manuscript requires additional detail and committing to revisions that strengthen transparency without altering the core findings.
read point-by-point responses
-
Referee: [Abstract / metric description] Abstract and metric-validation section: The headline claims (75% distortion rate, 1.5-2× asymmetry, compounding percentages) rest on an LM-based evaluator treated as ground truth, yet the manuscript provides no correlation coefficient with human judgments, no human-study sample size, no inter-annotator agreement, and no controls for the evaluator LM's own certainty bias. Without these, the quantitative results and directionality are uninterpretable.
Authors: We agree that the current manuscript would benefit from explicit quantitative reporting of the human validation. While the abstract states that the metric is consistent with population-level judgments, we did not include the correlation coefficient, sample size, inter-annotator agreement, or explicit controls for the evaluator LM's bias. In the revised version we will add a dedicated validation subsection reporting these details (including the human study design and any bias controls), which will make the metric's grounding fully transparent and address the interpretability concern. revision: yes
-
Referee: [Task setup / evaluation protocol] Task-setup and evaluation sections: The central assumption that rewrites preserve semantic content while altering only certainty is stated but not quantified; no semantic-similarity thresholds, human validation rates for content preservation, or controls for unintended meaning shifts are reported, making it impossible to isolate certainty distortion from other changes.
Authors: We acknowledge that the manuscript states the semantic-preservation assumption without supporting quantitative evidence. No similarity thresholds, human validation rates, or explicit controls for meaning shifts are reported. We will revise the task-setup and evaluation sections to include the semantic similarity thresholds used, human validation results on content preservation, and any filtering steps applied to exclude unintended meaning changes, thereby better isolating certainty distortion. revision: yes
-
Referee: [Results on asymmetry and multi-iteration experiments] Results sections on asymmetry and compounding: The reported 1.5-2× increase bias and iteration-wise increases (e.g., 20% → 40%) are presented without error bars, statistical significance tests against a null of no distortion, or ablation on the choice of 'meaningful change' threshold in the metric, leaving the load-bearing percentages vulnerable to metric-definition choices.
Authors: We agree that the reported percentages would be strengthened by statistical support and sensitivity checks. The current results lack error bars, significance tests, and threshold ablations. In revision we will add bootstrap error bars, statistical tests against a null of no distortion or symmetry, and an ablation varying the 'meaningful change' threshold to demonstrate robustness of the asymmetry and compounding findings. revision: yes
Circularity Check
Empirical measurement study with external human validation; no circularity
full rationale
The paper defines certainty distortion empirically as changes detected by an LM-based metric that is stated to be consistent with independent population-level human judgments. No equations, fitted parameters, self-citations, or ansatzes reduce the reported percentages, asymmetry ratios, or compounding effects to the inputs by construction. The measurement chain relies on observed model outputs evaluated against an externally benchmarked metric rather than any self-definitional or self-referential step.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption An LM-based scorer can be constructed that is consistent with population-level human judgments of expressed certainty
- domain assumption Rewriting tasks can be performed such that semantic content remains fixed while only certainty expression varies
Reference graph
Works this paper leans on
-
[1]
Measuring Sentence-Level and Aspect-Level (Un)certainty in Science Communications
Pei, Jiaxin and Jurgens, David. Measuring Sentence-Level and Aspect-Level (Un)certainty in Science Communications. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.784
-
[2]
Measuring and Modifying the Readability of E nglish Texts with GPT -4
Trott, Sean and Rivi \`e re, Pamela. Measuring and Modifying the Readability of E nglish Texts with GPT -4. Proceedings of the Third Workshop on Text Simplification, Accessibility and Readability (TSAR 2024). 2024. doi:10.18653/v1/2024.tsar-1.13
-
[3]
M ini C heck: Efficient Fact-Checking of LLM s on Grounding Documents
Tang, Liyan and Laban, Philippe and Durrett, Greg. M ini C heck: Efficient Fact-Checking of LLM s on Grounding Documents. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.499
-
[4]
Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems , pages=
A design space for intelligent and interactive writing assistants , author=. Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems , pages=
2024
-
[5]
Extended Abstracts of the 2018 CHI Conference on Human Factors in Computing Systems , pages=
Using Vocabularies to Collaboratively Create Better Plans for Writing Tasks , author=. Extended Abstracts of the 2018 CHI Conference on Human Factors in Computing Systems , pages=
2018
-
[6]
Proceedings of the 7th international conference on Intelligent user interfaces , pages=
A writer's collaborative assistant , author=. Proceedings of the 7th international conference on Intelligent user interfaces , pages=
-
[7]
arXiv preprint arXiv:2404.01268 , year=
Mapping the increasing use of LLMs in scientific papers , author=. arXiv preprint arXiv:2404.01268 , year=
-
[8]
arXiv preprint arXiv:2307.15337 , year=
Skeleton-of-thought: Prompting llms for efficient parallel generation , author=. arXiv preprint arXiv:2307.15337 , year=
-
[9]
LLM as a Broken Telephone: Iterative Generation Distorts Information
Mohamed, Amr and Geng, Mingmeng and Vazirgiannis, Michalis and Shang, Guokan. LLM as a Broken Telephone: Iterative Generation Distorts Information. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.371
-
[10]
J. When. The Thirteenth International Conference on Learning Representations , year=
-
[11]
arXiv preprint arXiv:2406.01860 , year=
Eliciting the priors of large language models using iterated in-context learning , author=. arXiv preprint arXiv:2406.01860 , year=
-
[12]
Proceedings of the 28th annual conference of the Cognitive Science Society , volume=
Revealing priors on category structures through iterated learning , author=. Proceedings of the 28th annual conference of the Cognitive Science Society , volume=
-
[13]
arXiv preprint arXiv:2504.12585 , year=
Identifying and Mitigating the Influence of the Prior Distribution in Large Language Models , author=. arXiv preprint arXiv:2504.12585 , year=
-
[14]
2025 , eprint=
Accumulating Context Changes the Beliefs of Language Models , author=. 2025 , eprint=
2025
-
[15]
2025 , eprint=
How Overconfidence in Initial Choices and Underconfidence Under Criticism Modulate Change of Mind in Large Language Models , author=. 2025 , eprint=
2025
-
[16]
Transactions on Machine Learning Research , issn=
Teaching Models to Express Their Uncertainty in Words , author=. Transactions on Machine Learning Research , issn=. 2022 , url=
2022
-
[17]
Miao Xiong and Zhiyuan Hu and Xinyang Lu and YIFEI LI and Jie Fu and Junxian He and Bryan Hooi , booktitle=. Can. 2024 , url=
2024
-
[18]
doi: 10.18653/v1/2023.emnlp-main.330
Tian, Katherine and Mitchell, Eric and Zhou, Allan and Sharma, Archit and Rafailov, Rafael and Yao, Huaxiu and Finn, Chelsea and Manning, Christopher. Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine-Tuned with Human Feedback. Proceedings of the 2023 Conference on Empirical Methods in Natural Langua...
-
[19]
2022 , eprint=
Language Models (Mostly) Know What They Know , author=. 2022 , eprint=
2022
-
[20]
Detecting hallucinations in large language models using semantic entropy
Farquhar, Sebastian and Kossen, Jannik and Kuhn, Lorenz and Gal, Yarin. Detecting hallucinations in large language models using semantic entropy. Nature
-
[21]
2025 , eprint=
SteerConf: Steering LLMs for Confidence Elicitation , author=. 2025 , eprint=
2025
-
[22]
2025 , eprint=
Uncertainty as Feature Gaps: Epistemic Uncertainty Quantification of LLMs in Contextual Question-Answering , author=. 2025 , eprint=
2025
-
[23]
The internal state of an LLM knows when it’s lying
Azaria, Amos and Mitchell, Tom. The Internal State of an LLM Knows When It ' s Lying. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.68
-
[24]
Duan, Jinhao and Cheng, Hao and Wang, Shiqi and Zavalny, Alex and Wang, Chenan and Xu, Renjing and Kailkhura, Bhavya and Xu, Kaidi. Shifting Attention to Relevance: Towards the Predictive Uncertainty Quantification of Free-Form Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa...
-
[25]
International Conference on Learning Representations , year=
Uncertainty Estimation in Autoregressive Structured Prediction , author=. International Conference on Learning Representations , year=
-
[26]
2024 , eprint=
Rethinking Uncertainty Estimation in Natural Language Generation , author=. 2024 , eprint=
2024
-
[27]
Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =
Qiu, Xin and Miikkulainen, Risto , title =. Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
2024
-
[28]
C o T - UQ : Improving Response-wise Uncertainty Quantification in LLM s with Chain-of-Thought
Zhang, Boxuan and Zhang, Ruqi. C o T - UQ : Improving Response-wise Uncertainty Quantification in LLM s with Chain-of-Thought. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1339
-
[29]
2025 , eprint=
Beyond Binary Rewards: Training LMs to Reason About Their Uncertainty , author=. 2025 , eprint=
2025
-
[30]
2025 , eprint=
Scalable Best-of-N Selection for Large Language Models via Self-Certainty , author=. 2025 , eprint=
2025
-
[31]
The Twelfth International Conference on Learning Representations , year=
Language Model Cascades: Token-Level Uncertainty And Beyond , author=. The Twelfth International Conference on Learning Representations , year=
-
[32]
2025 , url=
Hadas Orgad and Michael Toker and Zorik Gekhman and Roi Reichart and Idan Szpektor and Hadas Kotek and Yonatan Belinkov , booktitle=. 2025 , url=
2025
-
[33]
2024 , url=
Elias Stengel-Eskin and Peter Hase and Mohit Bansal , booktitle=. 2024 , url=
2024
-
[34]
Taming Overconfidence in
Jixuan Leng and Chengsong Huang and Banghua Zhu and Jiaxin Huang , booktitle=. Taming Overconfidence in. 2025 , url=
2025
-
[35]
S ay S elf: Teaching LLM s to Express Confidence with Self-Reflective Rationales
Xu, Tianyang and Wu, Shujin and Diao, Shizhe and Liu, Xiaoze and Wang, Xingyao and Chen, Yangyi and Gao, Jing. S ay S elf: Teaching LLM s to Express Confidence with Self-Reflective Rationales. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.343
-
[36]
2025 , eprint=
Rewarding Doubt: A Reinforcement Learning Approach to Calibrated Confidence Expression of Large Language Models , author=. 2025 , eprint=
2025
-
[37]
Peter Clark and Isaac Cowhey and Oren Etzioni and Tushar Khot and Ashish Sabharwal and Carissa Schoenick and Oyvind Tafjord , title =. arXiv:1803.05457v1 , year =
-
[38]
ARC `Challenge' Is Not That Challenging
Borchmann, ukasz. ARC `Challenge' Is Not That Challenging. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.144
-
[39]
B iz B ench: A Quantitative Reasoning Benchmark for Business and Finance
Krumdick, Michael and Koncel-Kedziorski, Rik and Lai, Viet Dac and Reddy, Varshini and Lovering, Charles and Tanner, Chris. B iz B ench: A Quantitative Reasoning Benchmark for Business and Finance. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.452
-
[40]
2025 , eprint=
Measuring and Analyzing Subjective Uncertainty in Scientific Communications , author=. 2025 , eprint=
2025
-
[41]
Bowman , booktitle=
David Rein and Betty Li Hou and Asa Cooper Stickland and Jackson Petty and Richard Yuanzhe Pang and Julien Dirani and Julian Michael and Samuel R. Bowman , booktitle=. 2024 , url=
2024
-
[42]
Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =
Wang, Yubo and Ma, Xueguang and Zhang, Ge and Ni, Yuansheng and Chandra, Abhranil and Guo, Shiguang and Ren, Weiming and Arulraj, Aaran and He, Xuan and Jiang, Ziyan and Li, Tianle and Ku, Max and Wang, Kai and Zhuang, Alex and Fan, Rongqi and Yue, Xiang and Chen, Wenhu , title =. Proceedings of the 38th International Conference on Neural Information Proc...
2024
-
[43]
Guha, Neel and Nyarko, Julian and Ho, Daniel E. and R\'. LEGALBENCH: a collaboratively built benchmark for measuring legal reasoning in large language models , year =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
-
[44]
2025 , eprint=
Kimi K2: Open Agentic Intelligence , author=. 2025 , eprint=
2025
-
[45]
International Conference on Learning Representations , year=
BERTScore: Evaluating Text Generation with BERT , author=. International Conference on Learning Representations , year=
-
[46]
2026 , eprint=
Belief Offloading in Human-AI Interaction , author=. 2026 , eprint=
2026
-
[47]
Green, Ben and Chen, Yiling , title =. 2019 , issue_date =. doi:10.1145/3359152 , journal =
-
[48]
Holistic Agent Leaderboard: The Missing Infrastructure for
Sayash Kapoor and Benedikt Stroebl and Peter Kirgis and Nitya Nadgir and Zachary S Siegel and Boyi Wei and Tianci Xue and Ziru Chen and Felix Chen and Saiteja Utpala and Franck Ndzomga and Dheeraj Oruganty and Sophie Luskin and Kangheng Liu and Botao Yu and Amit Arora and Dongyoon Hahm and Harsh Trivedi and Huan Sun and Juyong Lee and Tengjun Jin and Yifa...
2026
-
[49]
and Yue, Summer and Xing, Chen
Deshpande, Kaustubh and Sirdeshmukh, Ved and Mols, Johannes Baptist and Jin, Lifeng and Hernandez-Cardona, Ed-Yeremai and Lee, Dean and Kritz, Jeremy and Primack, Willow E. and Yue, Summer and Xing, Chen. M ulti C hallenge: A Realistic Multi-Turn Conversation Evaluation Benchmark Challenging to Frontier LLM s. Findings of the Association for Computational...
-
[50]
Vincze, Veronika and Szarvas, Gy\". The BioScope corpus: biomedical texts annotated for uncertainty, negation and their scopes , volume =. BMC Bioinformatics , publisher =. doi:10.1186/1471-2105-9-s11-s9 , number =
-
[51]
2019 , month =
Perception of Probability words , author =. 2019 , month =
2019
-
[52]
and Weinberg, Shalva and Wallsten, Thomas S
Budescu, David V. and Weinberg, Shalva and Wallsten, Thomas S. , year =. Decisions based on numerically and verbally expressed uncertainties. , volume =. Journal of Experimental Psychology: Human Perception and Performance , publisher =. doi:10.1037/0096-1523.14.2.281 , number =
-
[53]
Windschitl and Gary L
Paul D. Windschitl and Gary L. Wells , doi =. Measuring Psychological Uncertainty: Verbal Versus Numeric Methods , volume =. Journal of Experimental Psychology: Applied , number =
-
[54]
Verbal versus numerical probabilities: Efficiency, biases, and the preference paradox , volume =
Erev, Ido and Cohen, Brent L , year =. Verbal versus numerical probabilities: Efficiency, biases, and the preference paradox , volume =. Organizational Behavior and Human Decision Processes , publisher =. doi:10.1016/0749-5978(90)90002-q , number =
-
[55]
Wallsten, Thomas S. and Budescu, David V. and Zwick, Rami and Kemp, Steven M. , year =. Preferences and reasons for communicating probabilistic information in verbal or numerical terms , volume =. Bulletin of the Psychonomic Society , publisher =. doi:10.3758/bf03334162 , number =
-
[56]
Simon, Jon , year =. Interpretation of probability expressions by financial directors and auditors of UK companies , volume =. European Accounting Review , publisher =. doi:10.1080/09638180220125599 , number =
-
[57]
Karelitz, Tzur M. and Budescu, David V. , year =. You Say “Probable” and I Say “Likely”: Improving Interpersonal Communication With Verbal Probability Phrases. , volume =. Journal of Experimental Psychology: Applied , publisher =. doi:10.1037/1076-898x.10.1.25 , number =
-
[58]
Dhami, Mandeep K. and Wallsten, Thomas S. , year =. Interpersonal comparison of subjective probabilities: Toward translating linguistic probabilities , volume =. Memory & Cognition , publisher =. doi:10.3758/bf03193213 , number =
-
[59]
Exploring intelligence analysts' selection and interpretation of probability terms: Final Report for Research Contract ‘Expressing Probability in Intelligence Analysis’ , author=
-
[60]
Hwang, Xiang Ren, and Maarten Sap
Zhou, Kaitlyn and Hwang, Jena D. and Ren, Xiang and Sap, Maarten. Relying on the Unreliable: The Impact of Language Models' Reluctance to Express Uncertainty. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.198
-
[61]
Navigating the grey area: How expressions of uncertainty and overconfidence affect language models
Zhou, Kaitlyn and Jurafsky, Dan and Hashimoto, Tatsunori. Navigating the Grey Area: How Expressions of Uncertainty and Overconfidence Affect Language Models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.335
-
[62]
Modeling Information Change in Science Communication with Semantically Matched Paraphrases
Wright, Dustin and Pei, Jiaxin and Jurgens, David and Augenstein, Isabelle. Modeling Information Change in Science Communication with Semantically Matched Paraphrases. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.117
-
[63]
Understanding Fine-grained Distortions in Reports of Scientific Findings
Wuehrl, Amelie and Wright, Dustin and Klinger, Roman and Augenstein, Isabelle. Understanding Fine-grained Distortions in Reports of Scientific Findings. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.369
-
[64]
Learning Disentangled Representations of Negation and Uncertainty
Vasilakes, Jake and Zerva, Chrysoula and Miwa, Makoto and Ananiadou, Sophia. Learning Disentangled Representations of Negation and Uncertainty. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.574
-
[65]
Partalidou, Eleni and Passali, Tatiana and Zerva, Chrysoula and Tsoumakas, Grigorios and Ananiadou, Sophia. Towards Trustworthy Summarization of Cardiovascular Articles: A Factuality-and-Uncertainty-Aware Biomedical LLM Approach. Proceedings of the 2nd Workshop on Uncertainty-Aware NLP (UncertaiNLP 2025). 2025. doi:10.18653/v1/2025.uncertainlp-main.18
-
[66]
FactBank: a corpus annotated with event factuality , volume =
Saurí, Roser and Pustejovsky, James , year =. FactBank: a corpus annotated with event factuality , volume =. Language Resources and Evaluation , publisher =. doi:10.1007/s10579-009-9089-9 , number =
-
[67]
Honnibal, Matthew and Montani, Ines and Van Landeghem, Sofie and Boyd, Adriane , doi =
-
[68]
Proceedings of the Second Workshop on Statistical Machine Translation , pages =
Callison-Burch, Chris and Fordyce, Cameron and Koehn, Philipp and Monz, Christof and Schroeder, Josh , title =. Proceedings of the Second Workshop on Statistical Machine Translation , pages =. 2007 , publisher =
2007
-
[69]
2024 , url=
Ibraheem Muhammad Moosa and Rui Zhang and Wenpeng Yin , booktitle=. 2024 , url=
2024
-
[70]
Estimating Summary Quality with Pairwise Preferences
Zopf, Markus. Estimating Summary Quality with Pairwise Preferences. Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). 2018. doi:10.18653/v1/N18-1152
-
[71]
P ref S core: Pairwise Preference Learning for Reference-free Summarization Quality Assessment
Luo, Ge and Li, Hebi and He, Youbiao and Bao, Forrest Sheng. P ref S core: Pairwise Preference Learning for Reference-free Summarization Quality Assessment. Proceedings of the 29th International Conference on Computational Linguistics. 2022
2022
-
[72]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[73]
2025 , eprint=
LEAF: Knowledge Distillation of Text Embedding Models with Teacher-Aligned Representations , author=. 2025 , eprint=
2025
-
[74]
SciBERT: A Pretrained Language Model for Scientific Text
Beltagy, Iz and Lo, Kyle and Cohan, Arman. SciBERT: A Pretrained Language Model for Scientific Text. EMNLP. 2019
2019
-
[75]
Stating with Certainty or Stating with Doubt: Intercoder Reliability Results for Manual Annotation of Epistemically Modalized Statements
Rubin, Victoria L. Stating with Certainty or Stating with Doubt: Intercoder Reliability Results for Manual Annotation of Epistemically Modalized Statements. Human Language Technologies 2007: The Conference of the North A merican Chapter of the Association for Computational Linguistics; Companion Volume, Short Papers. 2007
2007
-
[76]
2025 , eprint=
A Survey on LLM-as-a-Judge , author=. 2025 , eprint=
2025
-
[77]
G- eval: NLG evaluation using gpt-4 with better human alignment
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang. G -Eval: NLG Evaluation using Gpt-4 with Better Human Alignment. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.153
-
[78]
2025 , eprint=
On Fact and Frequency: LLM Responses to Misinformation Expressed with Uncertainty , author=. 2025 , eprint=
2025
-
[79]
M isinfo B ench: A Multi-Dimensional Benchmark for Evaluating LLM s' Resilience to Misinformation
Yang, Ye and Li, Donghe and Li, Zuchen and Li, Fengyuan and Liu, Jingyi and Sun, Li and Yang, Qingyu. M isinfo B ench: A Multi-Dimensional Benchmark for Evaluating LLM s' Resilience to Misinformation. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.540
-
[80]
Psychological bulletin76(5), 378 (1971)
Fleiss, Joseph L. , year =. Measuring nominal scale agreement among many raters. , volume =. Psychological Bulletin , publisher =. doi:10.1037/h0031619 , number =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.