Neutrality Bites: Gender Representation in AI-Generated Animal Stories
Pith reviewed 2026-06-27 20:11 UTC · model grok-4.3
The pith
Large language models assign masculine gender to animal characters far more often than feminine when they assign gender at all.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
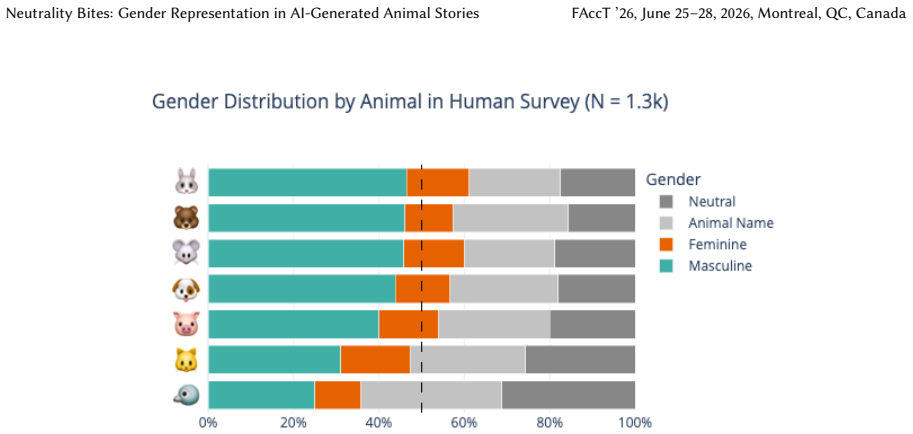
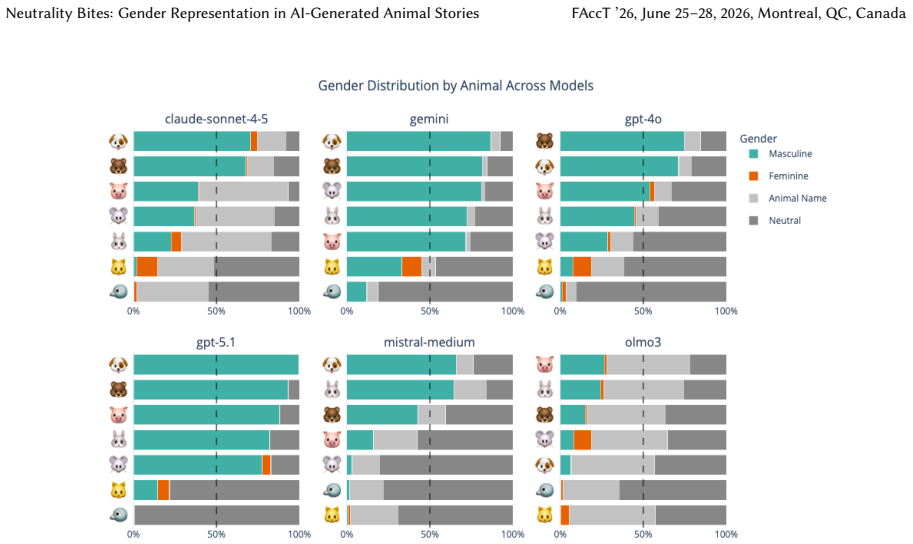
Across 23.8K stories, models avoid gendering the animal character in 19 percent of cases on average and use gender-neutral language in 38.2 percent, yet assign masculine gender in 40.6 percent and feminine gender in 2.2 percent when gender is assigned; the authors therefore claim that neutrality in LLMs contributes to the erasure of marginalized perspectives and identities.
What carries the argument
Prompting LLMs to complete English-language stories about anthropomorphic animals with unstated gender, then measuring the resulting patterns of gender assignment versus neutrality.
Load-bearing premise
The six chosen LLMs, seven animals, four settings, and temperature values are representative enough to support general claims about how LLMs assign gender in ambiguous narrative contexts.
What would settle it
A larger study using additional models or prompts that finds feminine animal characters appearing at rates equal to or higher than masculine ones when gender is assigned.
Figures




read the original abstract
Gender bias in AI-generated stories is a well-documented problem. While much attention has been paid to reducing or mitigating this bias, it is not always clear whether interventions produce genuinely fairer results. To investigate this issue, we examine how large language models (LLMs) handle gender assignment in a narrative context that is popular, highly ambiguous, and also known to closely reproduce human stereotypes: stories about talking animals. We prompt six leading LLMs to complete an English-language story about seven different anthropomorphic animal characters whose gender is unstated. We additionally iterate with four different narrative settings and a range of model temperatures. Across the 23.8K stories, we find that models frequently avoid gendering the animal character in the story (19% on average) or use gender-neutral language like "it" or "its" (38.2% on average). However, when gender is assigned, there is a significant masculine bias. Feminine animal characters are virtually absent, present in just 2.2% of stories vs. 40.6% that feature masculine characters. Our findings point to a broader argument: neutrality bites. In other words, models that prioritize neutrality to address social bias may actually contribute to the erasure of marginalized perspectives and identities. We suggest that alternative strategies beyond neutrality need to be pursued, such as ones that more equally distribute social possibilities across imagined subjects.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs prompted to generate stories about seven anthropomorphic animals with unstated gender (across six models, four narrative settings, and varied temperatures, yielding 23.8K stories) frequently avoid explicit gendering (19% average) or use neutral pronouns (38.2% average). When gender is assigned, a strong masculine bias appears (40.6% masculine characters vs. 2.2% feminine). The authors argue this shows that neutrality-focused approaches can erase marginalized identities and call for alternative strategies.
Significance. If the gender classification procedure proves reliable, the scale of the empirical counts provides concrete evidence that LLMs default to masculine or neutral representations in ambiguous narrative contexts, supporting the broader claim that neutrality can contribute to underrepresentation. The direct generation of 23.8K stories without fitted parameters is a methodological strength for reproducibility.
major comments (3)
- [Methodology] Methodology section: The procedure for classifying generated stories as masculine, feminine, neutral, or ungendered is not described, including any annotation guidelines, inter-annotator agreement scores, validation against human judgments, or handling of ambiguous cases. This directly affects the reliability of the headline 2.2% and 40.6% figures.
- [Results] Results section: No per-model, per-animal, or per-setting breakdowns or variance measures are reported for the gender assignment rates. Without these, it is impossible to determine whether the masculine bias generalizes beyond the specific choice of six LLMs and seven animals or is driven by particular combinations.
- [Abstract] Abstract and Results: The reported percentages lack error bars, confidence intervals, or robustness checks across temperature values, leaving the central claim of 'significant masculine bias' vulnerable to unexamined measurement and sampling choices.
minor comments (1)
- [Abstract] The abstract states the total story count but provides no details on the exact prompting template or how stories were deduplicated or filtered.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important areas for improving the clarity and robustness of our manuscript. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Methodology] Methodology section: The procedure for classifying generated stories as masculine, feminine, neutral, or ungendered is not described, including any annotation guidelines, inter-annotator agreement scores, validation against human judgments, or handling of ambiguous cases. This directly affects the reliability of the headline 2.2% and 40.6% figures.
Authors: We agree that the classification procedure must be described in detail for the results to be interpretable. The current version of the manuscript does not include this information. In the revision, we will add a dedicated subsection to the methodology that specifies the exact rules for classifying stories (based on pronoun usage and explicit gender markers), how ambiguous cases were resolved, the annotation guidelines provided to any human coders, inter-annotator agreement statistics, and the results of a validation exercise against human judgments on a held-out sample. revision: yes
-
Referee: [Results] Results section: No per-model, per-animal, or per-setting breakdowns or variance measures are reported for the gender assignment rates. Without these, it is impossible to determine whether the masculine bias generalizes beyond the specific choice of six LLMs and seven animals or is driven by particular combinations.
Authors: The referee is correct that aggregate figures alone are insufficient to assess generalizability. We will revise the results section to include tables or supplementary figures with per-model, per-animal, and per-narrative-setting breakdowns of the gender assignment rates. We will also report variance measures (e.g., standard deviations across temperature settings) to allow readers to evaluate consistency. revision: yes
-
Referee: [Abstract] Abstract and Results: The reported percentages lack error bars, confidence intervals, or robustness checks across temperature values, leaving the central claim of 'significant masculine bias' vulnerable to unexamined measurement and sampling choices.
Authors: We accept this criticism. The revised manuscript will include error bars or confidence intervals for the key percentages in both the abstract and results. We will also add a short robustness subsection that reports gender assignment rates across the range of temperature values used, confirming that the masculine bias pattern is stable. revision: yes
Circularity Check
No circularity: direct empirical counts from generated text
full rationale
The paper performs an empirical study by prompting six LLMs to generate stories about seven animals in four settings, then manually or automatically classifying the 23.8K outputs for gender assignment (masculine, feminine, neutral, or avoided). The headline percentages (40.6% masculine, 2.2% feminine when gendered) are simple frequency counts of observed tokens and pronouns in the generated text; no equations, fitted parameters, predictions, or self-citations are used to derive these figures from the inputs. The central claim is therefore a direct report of the experimental data rather than a reduction of the data to itself by construction. The selection of models/animals/settings is a methodological choice whose representativeness can be debated on external grounds, but it does not create a circular derivation chain.
Axiom & Free-Parameter Ledger
free parameters (2)
- temperature values
- selection of seven animal characters
axioms (2)
- domain assumption LLMs produce text from which gender references can be reliably extracted and counted
- domain assumption The tested models and settings are representative of typical LLM narrative behavior
Reference graph
Works this paper leans on
-
[1]
Amin Abolghasemi, Leif Azzopardi, Arian Askari, Maarten de Rijke, and Suzan Verberne. 2024. Measuring Bias in a Ranked List Using Term-Based Representations. InAdvances in Information Retrieval: 46th European Conference on Information Retrieval, ECIR 2024, Glasgow, UK, March 24–28, 2024, Proceedings, Part V(Glasgow, United Kingdom). Springer-Verlag, Berli...
-
[2]
Anjali Adukia, Alex Eble, Emileigh Harrison, Hakizumwami Birali Runesha, and Teodora Szasz. 2023. What We Teach About Race and Gender: Representation in Images and Text of Children’s Books*.The Quarterly Journal of Economics138, 4 (Nov. 2023), 2225–2285. doi:10.1093/qje/qjad028
-
[3]
Anthropic. 2025. System Card: Claude Sonnet 4.5. https://assets.anthropic.com/m/12f214efcc2f457a/original/Claude-Sonnet-4-5-System- Card.pdf
2025
-
[4]
Stuart G. Baker. 1994. The Multinomial-Poisson Transformation.Journal of the Royal Statistical Society. Series D (The Statistician)43, 4 (1994), 495–504. http://www.jstor.org/stable/2348134
arXiv 1994
-
[5]
and Gebru, Timnit and McMillan-Major, Angelina and Shmitchell, Shmargaret
Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. 2021. On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?. InProceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency(Virtual Event, Canada)(FAccT ’21). Association for Computing Machinery, New York, NY, USA, 610–623. doi:10.114...
-
[6]
Taylor Berry and Julia Wilkins. 2017. The Gendered Portrayal of Inanimate Characters in Children’s Books. 43, 2 (2017). FAccT ’26, June 25–28, 2026, Montreal, QC, Canada Imani Finkley, Yuanxi Li, and Melanie Walsh
2017
-
[7]
Su Lin Blodgett, Solon Barocas, Hal Daumé III, and Hanna Wallach. 2020. Language (Technology) Is Power: A Critical Survey of “Bias” in NLP. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault (Eds.). Association for Computational Linguistics, Online, 5454...
-
[8]
Yang Trista Cao and Hal Daumé. 2021. Toward Gender-Inclusive Coreference Resolution: An Analysis of Gender and Bias Throughout the Machine Learning Lifecycle.Computational Linguistics47, 3 (Nov. 2021), 615–661. doi:10.1162/coli_a_00413
-
[9]
Sarah Caré. 2024. Female Animal Characters in Roald Dahl’s Children’s Books: A Misogynistic Portrayal.Miscelánea: A Journal of English and American Studies69 (June 2024), 111–130. doi:10.26754/ojs_misc/mj.20248807
-
[10]
Kennedy Casey, Kylee Novick, and Stella Lourenco. 2021. Sixty Years of Gender Representation in Children’s Books: Conditions Associated with Overrepresentation of Male versus Female Protagonists.PLOS ONE16 (Dec. 2021), e0260566. doi:10.1371/journal.pone.0260566
-
[11]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al . 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261(2025)
Pith/arXiv arXiv 2025
-
[12]
Hannah Devinney, Jenny Björklund, and Henrik Björklund. 2022. Theories of “Gender” in NLP Bias Research. InProceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’22). Association for Computing Machinery, New York, NY, USA, 2083–2102. doi:10.1145/3531146.3534627
-
[13]
Dimgba, Sharon Oba, Ameeta Agrawal, and Philippe J
Martha O. Dimgba, Sharon Oba, Ameeta Agrawal, and Philippe J. Giabbanelli. 2025. Mitigation of Gender and Ethnicity Bias in AI-Generated Stories through Model Explanations. arXiv:2509.04515 [cs] doi:10.48550/arXiv.2509.04515
-
[14]
Bufan Gao and Elisa Kreiss. 2025. Measuring Bias or Measuring the Task: Understanding the Brittle Nature of LLM Gender Biases. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (Eds.). Association for Computational Linguistics, Suzhou, Ch...
2025
-
[15]
Somayeh Ghanbarzadeh, Yan Huang, Hamid Palangi, Radames Cruz Moreno, and Hamed Khanpour. 2023. Gender-tuning: Empowering Fine-tuning for Debiasing Pre-trained Language Models. InFindings of the Association for Computational Linguistics: ACL 2023, Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (Eds.). Association for Computational Linguistics, Toronto...
-
[16]
Tarleton Gillespie. 2024. Generative AI and the Politics of Visibility.Big Data & Society11, 2 (June 2024), 20539517241252131. doi:10.1177/20539517241252131
-
[17]
Google. [n. d.]. Gemini Storybook — for the Stories Only You Could Imagine. https://gemini.google/overview/storybook/
-
[18]
Liz Grauerholz and Bernice Pescosolido. 1989. Gender Representation in Children’s Literature: 1900-1984.Gender & Society - GENDER SOC3 (March 1989), 113–125. doi:10.1177/089124389003001008
-
[19]
Zhiting He, Jiayi Su, Li Chen, Tianqi Wang, and Ray Lc. 2025. ’I Recall the Past’: Exploring How People Collaborate with Generative AI to Create Cultural Heritage Narratives.Proc. ACM Hum.-Comput. Interact.9, 2, Article CSCW108 (May 2025), 30 pages. doi:10.1145/3711006
-
[20]
Thomas M. Hill and Katrina Bartow Jacobs. 2020. “The Mouse Looks Like a Boy”: Young Children’s Talk About Gender Across Human and Nonhuman Characters in Picture Books.Early Childhood Education Journal48, 1 (Jan. 2020), 93–102. doi:10.1007/s10643-019-00969-x
-
[21]
Sture Holm. 1979. A Simple Sequentially Rejective Multiple Test Procedure.Scandinavian Journal of Statistics6, 2 (1979), 65–70. http://www.jstor.org/stable/4615733
arXiv 1979
-
[22]
Tamanna Hossain, Sunipa Dev, and Sameer Singh. 2023. MISGENDERED: Limits of Large Language Models in Understanding Pronouns. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (Eds.). Association for Computational Linguistics, Toronto, Canad...
-
[23]
Ting-Yao Hsu, Yen-Chia Hsu, and Ting-Hao (Kenneth) Huang. 2019. On How Users Edit Computer-Generated Visual Stories. InExtended Abstracts of the 2019 CHI Conference on Human Factors in Computing Systems(Glasgow, Scotland Uk)(CHI EA ’19). Association for Computing Machinery, New York, NY, USA, 1–6. doi:10.1145/3290607.3312965
-
[24]
Hadas Kotek, Rikker Dockum, and David Sun. 2023. Gender bias and stereotypes in Large Language Models. InProceedings of The ACM Collective Intelligence Conference(Delft, Netherlands)(CI ’23). Association for Computing Machinery, New York, NY, USA, 12–24. doi:10.1145/3582269.3615599
-
[25]
Mina Lee, Percy Liang, and Qian Yang. 2022. CoAuthor: Designing a Human-AI Collaborative Writing Dataset for Exploring Language Model Capabilities. InCHI Conference on Human Factors in Computing Systems (CHI ’22). ACM, 1–19. doi:10.1145/3491102.3502030
-
[26]
Molly Lewis, Matt Cooper Borkenhagen, Ellen Converse, Gary Lupyan, and Mark S Seidenberg. 2021. What Might Books Be Teaching Young Children About Gender? (2021)
2021
-
[27]
Li Lucy and David Bamman. 2021. Gender and Representation Bias in GPT-3 Generated Stories. InProceedings of the Third Workshop on Narrative Understanding, Nader Akoury, Faeze Brahman, Snigdha Chaturvedi, Elizabeth Clark, Mohit Iyyer, and Lara J. Martin (Eds.). Association for Computational Linguistics, Virtual, 48–55. doi:10.18653/v1/2021.nuse-1.5
-
[28]
Janice McCabe, Emily Fairchild, Liz Grauerholz, Bernice Pescosolido, and Daniel Tope. 2011. Gender in Twentieth-Century Children’s Books.Gender & Society - GENDER SOC25 (March 2011), 197–226. doi:10.1177/0891243211398358 Neutrality Bites: Gender Representation in AI-Generated Animal Stories FAccT ’26, June 25–28, 2026, Montreal, QC, Canada
-
[29]
Jennifer Mickel, Maria De-Arteaga, Liu Leqi, and Kevin Tian. 2026. More of the Same: Persistent Representational Harms Under Increased Representation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id= R9k13fTGP0
2026
-
[30]
MistralAI. 2025. Mistral Medium 3.1 - Mistral AI. https://docs.mistral.ai/models/mistral-medium-3-1-25-08
2025
-
[31]
Joao Neves, Inês Costa, Joao Oliveira, Bruno Silva, and Joana Maia. 2023. Can Gender Nouns Influence the Stereotypes of Animals? Animals : an Open Access Journal from MDPI13, 16 (Aug. 2023), 2604. doi:10.3390/ani13162604
-
[32]
Team Olmo, :, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, Jacob Morrison, Jake Poznanski, Kyle Lo, Luca Soldaini, Matt Jordan, Mayee Chen, Michael Noukhovitch, Nathan Lambert, Pete Walsh, Pradeep Dasigi, Robert Berry, Saumya Malik, Saurabh Shah, Scott Geng, S...
-
[33]
arXiv:2512.13961 [cs.CL] https://arxiv.org/abs/2512.13961
Olmo 3. arXiv:2512.13961 [cs.CL] https://arxiv.org/abs/2512.13961
-
[34]
OpenAI. 2024. GPT-4o System Card. https://cdn.openai.com/gpt-4o-system-card.pdf
2024
-
[35]
OpenAI. 2025. GPT-5 System Card. https://cdn.openai.com/gpt-5-system-card.pdf
2025
-
[36]
Joanne O’Sullivan. 2025. Google Launches Personalized Gemini Storybook App to Industry Concern. https://www.publishersweekly. com/pw/by-topic/childrens/childrens-industry-news/article/98452-google-launches-personalized-gemini-storybook-app-to- industry-concern.html
2025
-
[37]
Shon Otmazgin, Arie Cattan, and Yoav Goldberg. 2022. F-coref: Fast, Accurate and Easy to Use Coreference Resolution. InProceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing: System Demonstrations, Wray Buntine and Maria Liaka...
-
[38]
Amifa Raj and Michael D. Ekstrand. 2022. Fire Dragon and Unicorn Princess; Gender Stereotypes and Children’s Products in Search Engine Responses. arXiv. doi:10.48550/ARXIV.2206.13747 Version Number: 1
-
[39]
2022.Alice and Sparkle
Ammaar Reshi. 2022.Alice and Sparkle. Independently published. Text generated using ChatGPT; Illustrations generated using Midjourney
2022
-
[40]
Donya Rooein, Vilém Zouhar, Debora Nozza, and Dirk Hovy. 2025. Biased Tales: Cultural and Topic Bias in Generating Children’s Stories. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (Eds.). Association for Computational Linguistics, Su...
-
[41]
Shirin Seyedsalehi. 2025. Mitigating Gender Bias in Information Retrieval Systems. InAdvances in Information Retrieval, Claudia Hauff, Craig Macdonald, Dietmar Jannach, Gabriella Kazai, Franco Maria Nardini, Fabio Pinelli, Fabrizio Silvestri, and Nicola Tonellotto (Eds.). Vol. 15576. Springer Nature Switzerland, Cham, 227–232. doi:10.1007/978-3-031-88720-...
-
[42]
Emily Sheng, Kai-Wei Chang, Premkumar Natarajan, and Nanyun Peng. 2019. The Woman Worked as a Babysitter: On Biases in Language Generation. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Kentaro Inui, Jing Jiang, Vincent Ng, ...
-
[43]
Sugimoto, and Thema Monroe-White
Evan Shieh, Faye Marie Vassel, Cassidy R. Sugimoto, and Thema Monroe-White. 2025. Laissez-Faire Harms: Algorithmic Biases in Generative Language Models (Extended Abstract).Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society8, 3 (Oct. 2025), 2373–2374. doi:10.1609/aies.v8i3.36722
-
[44]
Laura Spillner. 2024. Unexpected Gender Stereotypes in AI-generated Stories: Hairdressers Are Female, but so Are Doctors. InProceedings of the Text2Story’24 Workshop. Glasgow, Scotland. https://ceur-ws.org/Vol-3671/paper10.pdf
2024
-
[45]
Goya van Boven, Yupei Du, and Dong Nguyen. 2024. Transforming Dutch: Debiasing Dutch Coreference Resolution Systems for Non-binary Pronouns. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’24). Association for Computing Machinery, New York, NY, USA, 2470–2483. doi:10.1145/3630106.3659049
-
[46]
Melanie Walsh, Russell Samora, Michelle Pera-McGhee, and Jan Diehm. 2025. Bears Will Be Boys: A data analysis of animal gender in children’s books. https://pudding.cool/2025/07/kids-books/.The Pudding(July 2025)
2025
-
[47]
Jules Watson, Xi Wang, Raymond Liu, Suzanne Stevenson, and Barend Beekhuizen. 2025. Analyzing values about gendered language reform in LLMs’ revisions. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (Eds.). Association for Computationa...
-
[48]
Jennie Yabroff. 2016. Why Are There so Few Girls in Children’s Books?The Washington Post(Jan. 2016). FAccT ’26, June 25–28, 2026, Montreal, QC, Canada Imani Finkley, Yuanxi Li, and Melanie Walsh
2016
-
[49]
Tao Zhang, Ziqian Zeng, YuxiangXiao YuxiangXiao, Huiping Zhuang, Cen Chen, James R. Foulds, and Shimei Pan. 2025. GenderAlign: An Alignment Dataset for Mitigating Gender Bias in Large Language Models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Wanxiang Che, Joyce Nabende, Ekaterina Sh...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.