FMRFusion: Frequency-Aware Multi-View Representation Learning for Heterogeneous Image Fusion
Pith reviewed 2026-06-27 20:17 UTC · model grok-4.3
The pith
FMRFusion fuses infrared and visible images by separating frequencies and modeling cross-view complementary features instead of stacking single modules.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
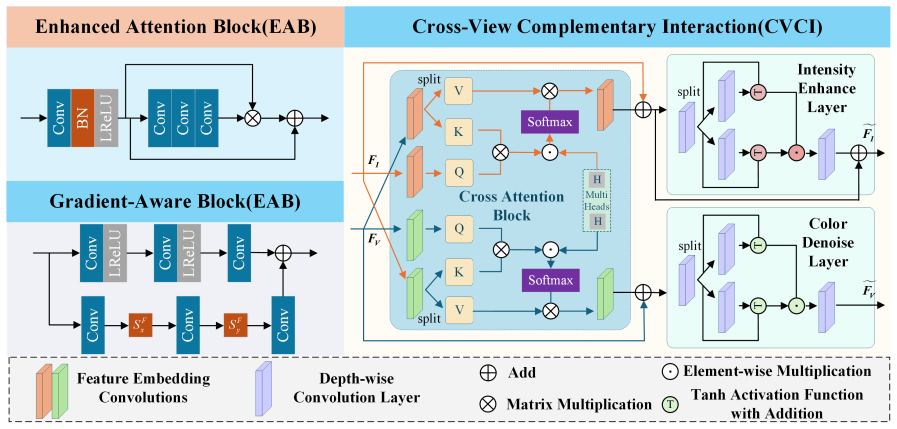
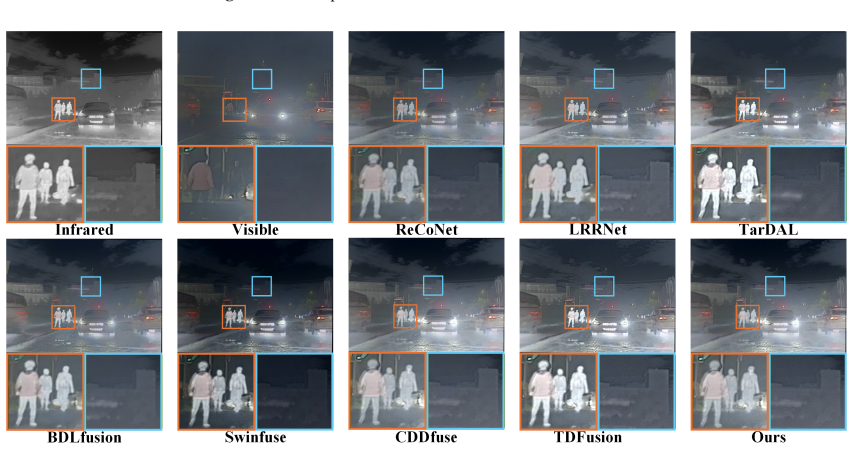
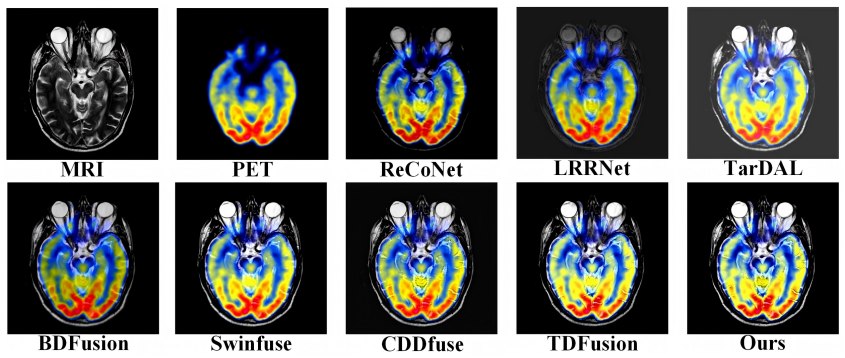
The central claim is that a frequency-aware multi-view network overcomes the incomplete feature learning of prior single-module stacking methods. The Multi-Scale Structural Perception Module extracts local and contextual structures, bilinear frequency decomposition jointly models high-frequency details and low-frequency global content, Cross-View Complementary Interaction fuses reflected-light and radiative-intensity information, and flow matching progressively improves the fused representation from coarse to high-quality output. Experiments on multiple datasets show this combination yields superior and consistent fusion results, particularly in nighttime conditions.
What carries the argument
The FMRFusion architecture built around the Multi-Scale Structural Perception Module, bilinear frequency decomposition, Cross-View Complementary Interaction module, and flow-matching refinement.
If this is right
- Fused images retain more target information from the infrared modality while preserving texture from the visible modality.
- Performance stays higher across varied real-world heterogeneous data than single-module baselines.
- Nighttime fusion quality improves noticeably because radiative and reflective cues are modeled together.
- Flow matching supplies a progressive refinement step that can be applied after initial feature fusion.
Where Pith is reading between the lines
- The same frequency-split and cross-view pattern could be tested on other paired sensor data such as RGB-depth or medical modalities.
- If the bilinear decomposition proves stable, it might replace hand-crafted frequency filters in other detail-preserving vision pipelines.
- Flow matching as a post-fusion step suggests a route to iterative quality improvement without retraining the entire encoder.
Load-bearing premise
Single-module stacking leaves the distinct characteristics of infrared and visible modalities incompletely learned, and the proposed multi-view modules will fix that gap.
What would settle it
An ablation that removes the frequency decomposition and cross-view interaction modules and measures whether fusion metrics on nighttime test sets remain unchanged or improve.
Figures







read the original abstract
Infrared and visible image fusion aims to generate a composite image that retains significant target information and preserves detailed textures, integrating two heterogeneous modalities. Previous image fusion methods typically adopt a single-module stacking approach to extract features from the two modalities. However, these approaches may result in incomplete learning of their distinct characteristics, thereby limiting the fusion effectiveness and constrain ing robustness in real-world heterogeneous data scenarios. To address these challenges, we propose FMRFusion, a frequency-aware multi-view representation learning network for Heterogeneous Image Fusion. A Multi-Scale Struc tural Perception Module is introduced to effectively capture discriminative structures, extracting fine-grained local structures and essential contextual information. A bilinear frequency decomposition mechanism is employed to sepa rate features into high-frequency and low-frequency components, enabling joint modeling of local details and global representations across different frequency domains. Moreover, a Cross-View Complementary Interaction is incorpo rated to explicitly model and fuse the complementary characteristics between reflected light information and radiative intensity responses, facilitating effective cross-view interaction. We further improve the Performance of the fused results by flow matching, which progressively refines the fused features by learning the transformation from coarse data to high-quality representations. Extensive experiments conducted on multiple benchmark datasets demonstrate that FMRFusion achieves superior and consistent performance across a range of fusion tasks, especially in nighttime scenarios
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FMRFusion, a frequency-aware multi-view representation learning network for infrared and visible image fusion. It introduces a Multi-Scale Structural Perception Module to capture discriminative structures, a bilinear frequency decomposition mechanism to separate high- and low-frequency components, a Cross-View Complementary Interaction module to model complementary characteristics between modalities, and flow matching to refine fused features. The central claim is that this architecture overcomes incomplete modality learning from prior single-module stacking approaches and achieves superior, consistent performance on benchmark datasets, especially in nighttime scenarios.
Significance. If the experimental claims hold, the explicit multi-view and frequency-aware design could advance heterogeneous fusion by better preserving both structural details and global context across modalities, with potential benefits for nighttime robustness in applications such as surveillance and autonomous navigation.
major comments (1)
- Abstract: performance claims of 'superior and consistent performance across a range of fusion tasks' are asserted without any quantitative results, baselines, error bars, dataset names, or experimental protocol, rendering the central claim that the proposed modules overcome single-module limitations impossible to evaluate from the provided text.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the abstract. We agree that incorporating specific quantitative highlights will strengthen the presentation of our claims while maintaining the abstract's conciseness.
read point-by-point responses
-
Referee: [—] Abstract: performance claims of 'superior and consistent performance across a range of fusion tasks' are asserted without any quantitative results, baselines, error bars, dataset names, or experimental protocol, rendering the central claim that the proposed modules overcome single-module limitations impossible to evaluate from the provided text.
Authors: The abstract is a high-level summary, with full quantitative support (including named datasets such as TNO and RoadScene, multiple baselines, metrics like PSNR/SSIM, and standard deviations) provided in Section 4 of the manuscript. We will revise the abstract to include 1-2 key quantitative results (e.g., average gains in nighttime scenarios) to directly address this point. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes an architectural framework (multi-scale structural perception, bilinear frequency decomposition, cross-view interaction, flow matching) to address limitations of prior single-module stacking methods. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided abstract or description. The central claims rest on empirical benchmark results rather than any self-referential reduction of outputs to inputs by construction. This is a standard empirical ML architecture paper with no load-bearing mathematical steps that collapse into tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
H. Xu, R. Nie, J. Cao, G. Xie, Z. Ding, Imqfusion: Infrared and visible image fusion via implicit multi-resolution preservation and query aggregation, Expert Systems with Applications 257 (2024) 125014
2024
-
[2]
J. Liu, G. Wu, Z. Liu, D. Wang, Z. Jiang, L. Ma, W. Zhong, X. Fan, R. Liu, Infrared and visible image fusion: From data compatibility to task adaption, IEEE Transactions on Pattern Analysis and Machine Intelligence 47 (2024) 2349–2369
2024
-
[3]
H. Zhao, T. Jiang, X. Li, J. Jin, Sfdfuse: A lightweight spatial-frequency fusion network for infrared-visible images, Pattern Recognition (2026) 113634
2026
-
[4]
H. Li, Z. Yang, Y . Zhang, W. Jia, Z. Yu, Y . Liu, Mulfs-cap: Multimodal fusion-supervised cross-modality alignment perception for unregistered infrared-visible image fusion, IEEE Transactions on Pattern Analysis and Machine Intelligence 47 (2025) 3673–3690. doi:10.1109/TPAMI.2025.3535617
-
[5]
J. Dong, W. Wu, J. Cheng, X. Tang, You sense only once beneath: Ultra-light real-time underwater object detection, arXiv preprint arXiv:2504.15694 (2025)
arXiv 2025
-
[6]
Qiang, Y
Z. Qiang, Y . Shen, Y . Yuan, G. Pei, Dwsfusion: Dual weight supervision for lightweight infrared and visible image fusion, Pattern Recognition (2026) 113520
2026
-
[7]
B. Tang, Z. Yang, D. Yao, B. Yang, L. Chen, R. Bi, Y . Zhao, J. Xie, Z. Guo, Loft-clip: Few-shot anomaly detection for railway fasteners based on large vision-language models, Pattern Recognition 180 (2026) 114099. doi:10.1016/j.patcog.2026.114099
-
[8]
Zhang, Z
Y . Zhang, Z. Wang, M. Huang, M. Li, J. Zhang, S. Wang, J. Zhang, H. Zhang, S2dbft: Spectral-spatial dual- branch fusion transformer for hyperspectral image classification, IEEE Transactions on Geoscience and Remote Sensing (2025). 18
2025
-
[9]
Zhang, J.-F
J. Zhang, J.-F. Nezan, J.-G. Cousin, Implementation of motion estimation based on heterogeneous parallel computing system with opencl, in: 2012 IEEE 14th International Conference on High Performance Computing and Communication & 2012 IEEE 9th International Conference on Embedded Software and Systems, IEEE, 2012, pp. 41–45
2012
-
[10]
Y . Feng, J. Zheng, M. Qin, C. Bai, J. Zhang, 3d octave and 2d vanilla mixed convolutional neural network for hyperspectral image classification with limited samples, Remote Sensing 13 (2021) 4407
2021
-
[11]
M. Gao, X. He, L. Chen, T. Liu, J. Zhang, A. Zhou, Learning vertex representations for bipartite networks, IEEE transactions on knowledge and data engineering 34 (2020) 379–393
2020
-
[12]
P. Zhu, Z. Zhu, Y . Wang, J. Zhang, S. Zhao, Multi-granularity episodic contrastive learning for few-shot learning, Pattern Recognition 131 (2022) 108820
2022
-
[13]
Z. Zhou, F. Zhang, H. Xiao, F. Wang, X. Hong, K. Wu, J. Zhang, A novel ground-based cloud image seg- mentation method by using deep transfer learning, IEEE Geoscience and Remote Sensing Letters 19 (2021) 1–5
2021
-
[14]
Y . Jia, D. Yao, J. Yang, L. Jia, T. Zhou, Q. Long, A multi-scale wavelet and spectral kurtosis-guided frame- work for noise-resistant rolling bearing fault diagnosis, Mechanical Systems and Signal Processing 242 (2026) 113662
2026
-
[15]
J. Chen, W. Yu, Z. Cheng, X. Tian, J. Ma, Tofusion: Text-guided and object-aware infrared and visible image fusion, Pattern Recognition (2026) 113569
2026
-
[16]
J. Ma, L. Tang, F. Fan, J. Huang, X. Mei, Y . Ma, Swinfusion: Cross-domain long-range learning for general image fusion via swin transformer, IEEE/CAA Journal of Automatica Sinica 9 (2022) 1200–1217
2022
-
[17]
Zhang, J
H. Zhang, J. Ma, Sdnet: A versatile squeeze-and-decomposition network for real-time image fusion, Interna- tional Journal of Computer Vision 129 (2021) 2761–2785
2021
-
[18]
Zhang, Y
Y . Zhang, Y . Liu, P. Sun, H. Yan, X. Zhao, L. Zhang, Ifcnn: A general image fusion framework based on convolutional neural network, Information Fusion 54 (2020) 99–118
2020
-
[19]
L. Qu, S. Liu, M. Wang, Z. Song, Transmef: A transformer-based multi-exposure image fusion framework using self-supervised multi-task learning, in: Proceedings of the AAAI conference on artificial intelligence, volume 36, 2022, pp. 2126–2134
2022
-
[20]
H. Xu, J. Ma, J. Yuan, Z. Le, W. Liu, Rfnet: Unsupervised network for mutually reinforcing multi-modal image registration and fusion, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 19679–19688
2022
-
[21]
Y . Long, H. Jia, Y . Zhong, Y . Jiang, Y . Jia, Rxdnfuse: A aggregated residual dense network for infrared and visible image fusion, Information Fusion 69 (2021) 128–141
2021
-
[22]
Y . Wang, X. Zhao, J. Pu, L. Zhang, D. Miao, Multi-scale frequency attention fusion network for infrared and visible image fusion, Engineering Applications of Artificial Intelligence 159 (2025) 111728
2025
-
[23]
C. Li, R. Zhu, H. Zhao, X. Li, X. Zhang, Atdfusion: Adapter-tuned dual-branch network for multimodal medical image fusion, Pattern Recognition (2026) 113848
2026
-
[24]
Zhang, P
J. Zhang, P. Liu, F. Zhang, H. Iwabuchi, A. A. d. H. e Ayres, V . H. C. De Albuquerque, et al., Ensemble meteorological cloud classification meets internet of dependable and controllable things, IEEE Internet of Things Journal 8 (2020) 3323–3330
2020
-
[25]
M. Miao, W. Hu, B. Xu, J. Zhang, J. J. Rodrigues, V . H. C. De Albuquerque, Automated cca-mwf algorithm for unsupervised identification and removal of eog artifacts from eeg, IEEE Journal of Biomedical and Health Informatics 26 (2021) 3607–3617. 19
2021
-
[26]
Q. Ma, C. Bai, J. Zhang, Z. Liu, S. Chen, Supervised learning based discrete hashing for image retrieval, Pattern Recognition 92 (2019) 156–164
2019
-
[27]
Y . Li, Y . Yang, K. Zhu, J. Zhang, Clothing sale forecasting by a composite gru–prophet model with an attention mechanism, IEEE Transactions on Industrial Informatics 17 (2021) 8335–8344
2021
-
[28]
Q. Chen, Z. Zhang, Z. Zhang, K. Zhang, D. Li, W. Wang, J. Zhang, C. Liu, Distilled large language model-driven dynamic sparse expert activation mechanism, Applied Soft Computing (2025) 114037
2025
-
[29]
Q. Chen, L. Wang, Z. Zhang, X. Wang, W. Liu, B. Xia, H. Ding, J. Zhang, S. Xu, X. Wang, Dual-path aggregation transformer network for super-resolution with images occlusions and variability, Engineering Applications of Artificial Intelligence 139 (2025)
2025
-
[30]
K. Cui, J. Cheng, Y . Pan, Fdafusion: A joint frequency decomposition and adaptive fusion network for nighttime infrared and visible image fusion, in: 2025 International Joint Conference on Neural Networks (IJCNN), 2025, pp. 1–8. doi:10.1109/IJCNN64981.2025.11229055
-
[31]
C. Pan, Q. Jiang, H. Zheng, H. Huang, X. Jin, K. Li, W. Zhou, Dmnet: A dense multi-scale feature extraction network with two-stage training for infrared-visible image fusion, IEEE Internet of Things Journal (2025)
2025
-
[32]
H. Xu, J. Ma, J. Jiang, X. Guo, H. Ling, U2fusion: A unified unsupervised image fusion network, IEEE Transactions on Pattern Analysis and Machine Intelligence 44 (2020) 502–518
2020
-
[33]
Li, X.-J
H. Li, X.-J. Wu, Densefuse: A fusion approach to infrared and visible images, IEEE Transactions on Image Processing 28 (2019) 2614–2623
2019
-
[34]
Li, X.-J
H. Li, X.-J. Wu, T. Durrani, Nestfuse: An infrared and visible image fusion architecture based on nest connection and spatial/channel attention models, IEEE Transactions on Instrumentation and Measurement 69 (2020) 9645– 9656
2020
-
[35]
Li, X.-J
H. Li, X.-J. Wu, J. Kittler, Rfn-nest: An end-to-end residual fusion network for infrared and visible images, Information Fusion 73 (2021) 72–86
2021
-
[36]
Y . Guo, R. Xu, R. Li, W. Su, Dae-fuse: An adaptive discriminative autoencoder for multi-modality image fusion, in: 2025 IEEE International Conference on Multimedia and Expo (ICME), IEEE, 2025, pp. 1234–1239
2025
-
[37]
H. Xu, H. Zhang, J. Ma, Classification saliency-based rule for visible and infrared image fusion, IEEE Transac- tions on Computational Imaging 7 (2021) 824–836
2021
-
[38]
Zhang, J
Z. Zhang, J. Zhou, J. Shi, J. Lu, Cpigan: Infrared and visible image fusion via cross-scale progressive interaction network with adversarial learning, Computers and Electrical Engineering 128 (2025) 110672
2025
-
[39]
J. Ma, H. Zhang, Z. Shao, P. Liang, H. Xu, Ganmcc: A generative adversarial network with multiclassification constraints for infrared and visible image fusion, IEEE Transactions on Instrumentation and Measurement 70 (2020) 1–14
2020
-
[40]
J. Ma, H. Xu, J. Jiang, X. Mei, X.-P. Zhang, Ddcgan: A dual-discriminator conditional generative adversarial network for multi-resolution image fusion, IEEE Transactions on Image Processing 29 (2020) 4980–4995
2020
-
[41]
J. Li, H. Huo, C. Li, R. Wang, Q. Feng, Attentionfgan: Infrared and visible image fusion using attention-based generative adversarial networks, IEEE Transactions on Multimedia 23 (2020) 1383–1396
2020
-
[42]
J. Liu, X. Fan, Z. Huang, G. Wu, R. Liu, W. Zhong, Z. Luo, Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 5802–5811
2022
-
[43]
Z. Ding, R. Hou, Y . Men, S. Luan, Y . Liu, K. He, S. Xie, Dskfuse: Passive-active distillation learning for multi-modal image fusion via dynamic sparse kansformer, Expert Systems with Applications (2025) 130610. 20
2025
-
[44]
Zhang, H
X. Zhang, H. Qin, J. Geng, J. Liu, Z. Liu, H. Li, Sfdfuse: Spatial and frequency feature decomposition for visible and infrared image fusion, Pattern Recognition (2026) 113949
2026
-
[45]
Q. Chen, Z. Zhang, H. Liu, J. Zhang, C. Bai, Kftd: Koopman-fourier time-differentiable network for continuous ocean spatiotemporal forecasting, in: Proceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 1, 2026, pp. 94–103
2026
-
[46]
Zhang, G
Z. Zhang, G. Li, H. Zhang, Q. Chen, Q. Zhang, J. Wan, M. Xiong, C. Bai, D. Li, W. Zhang, et al., A novel dataset and lightweight distillation baseline for highlight transparent object detection, International Journal of Computer Vision 134 (2026) 157
2026
-
[47]
Zhang, M
Z. Zhang, M. Zhou, H. Wan, M. Li, G. Li, D. Han, Idd-net: Industrial defect detection method based on deep-learning, Engineering Applications of Artificial Intelligence 123 (2023) 106390
2023
-
[48]
Zhang, Q
Z. Zhang, Q. Chen, M. Xiong, S. Ding, Z. Su, X. Yao, Y . Sun, C. Bai, J. Zhang, Zero-shot learning in industrial scenarios: New large-scale benchmark, challenges and baseline, in: Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, 2025, pp. 10357–10366
2025
-
[49]
Zhang, Z
J. Zhang, Z. Zhang, Q. Chen, G. Li, W. Li, S. Ding, M. Xiong, W. Zhang, S. Chen, Representation learning based on co-evolutionary combined with probability distribution optimization for precise defect location, IEEE Transactions on Neural Networks and Learning Systems 36 (2024) 11989–12003
2024
-
[50]
Zhang, J
Z. Zhang, J. Zhang, Q. Chen, G. Li, D. Chen, S. Jing, H. Wang, D. Li, C. Liu, C. Bai, et al., Unification of closed- open industrial detection scenarios: New large-scale benchmarks, challenges and baselines, IEEE Transactions on Pattern Analysis and Machine Intelligence (2026)
2026
-
[51]
H. Yan, S. Xiong, L. Wang, L. Jian, G. Vivone, Atfusion: An alternate cross-attention transformer network for infrared and visible image fusion, Infrared Physics & Technology 152 (2026) 106252
2026
-
[52]
Z. Wang, Y . Chen, W. Shao, H. Li, L. Zhang, Swinfuse: A residual swin transformer fusion network for infrared and visible images, IEEE Transactions on Instrumentation and Measurement 71 (2022) 1–12
2022
-
[53]
W. Tang, F. He, Y . Liu, Y . Duan, T. Si, Datfuse: Infrared and visible image fusion via dual attention transformer, IEEE Transactions on Circuits and Systems for Video Technology (2023)
2023
-
[54]
H. Bai, J. Zhang, Z. Zhao, Y . Wu, L. Deng, Y . Cui, T. Feng, S. Xu, Task-driven image fusion with learnable fusion loss, in: Proceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 7457–7468
2025
-
[55]
H. Zhao, R. Nie, Dndt: Infrared and visible image fusion via densenet and dual-transformer, in: 2021 Interna- tional Conference on Information Technology and Biomedical Engineering (ICITBE), IEEE, 2021, pp. 71–75
2021
-
[56]
J. Li, J. Zhu, C. Li, X. Chen, B. Yang, Cgtf: Convolution-guided transformer for infrared and visible image fusion, IEEE Transactions on Instrumentation and Measurement 71 (2022) 1–14
2022
-
[57]
X. Chen, H. Li, M. Li, J. Pan, Learning a sparse transformer network for effective image deraining, in: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 5896–5905
2023
-
[58]
Y . Jie, Y . Xu, X. Li, H. Tan, Tsjnet: A multi-modality target and semantic awareness joint-driven image fusion network, arXiv preprint arXiv:2402.01212 (2024). https://doi.org/10.1109/tgrs.2023.3243900
-
[59]
P. Wang, X. Wang, F. Wang, M. Lin, S. Chang, H. Li, R. Jin, Kvt: k-nn attention for boosting vision transformers, in: European conference on computer vision, Springer, 2022, pp. 285–302
2022
- [60]
-
[61]
H. Li, T. Xu, X.-J. Wu, J. Lu, J. Kittler, Lrrnet: A novel representation learning guided fusion network for infrared and visible images, IEEE transactions on pattern analysis and machine intelligence (2023). 21
2023
-
[62]
Z. Liu, J. Liu, G. Wu, L. Ma, X. Fan, R. Liu, Bi-level dynamic learning for jointly multi-modality image fusion and beyond, IJCAI (2023)
2023
-
[63]
S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, M.-H. Yang, Restormer: Efficient transformer for high-resolution image restoration, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 5728–5739
2022
-
[64]
H. Jung, Y . Kim, H. Jang, N. Ha, K. Sohn, Unsupervised deep image fusion with structure tensor representations, IEEE Transactions on Image Processing 29 (2020) 3845–3858
2020
-
[65]
X. Deng, P. L. Dragotti, Deep convolutional neural network for multi-modal image restoration and fusion, IEEE transactions on pattern analysis and machine intelligence 43 (2020) 3333–3348
2020
-
[66]
Liang, J
P. Liang, J. Jiang, X. Liu, J. Ma, Fusion from decomposition: A self-supervised decomposition approach for image fusion, in: European Conference on Computer Vision, Springer, 2022, pp. 719–735
2022
-
[67]
X. Hu, J. Jiang, X. Liu, J. Ma, Zmff: Zero-shot multi-focus image fusion, Information Fusion 92 (2023) 127–138
2023
-
[68]
Z. Zhao, L. Deng, H. Bai, Y . Cui, Z. Zhang, Y . Zhang, H. Qin, D. Chen, J. Zhang, P. Wang, et al., Image fusion via vision-language model, arXiv preprint arXiv:2402.02235 (2024). 22
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.