IntentNav: Learning Spatial-Visual Object Navigation from Human Demonstrations
Pith reviewed 2026-06-27 19:53 UTC · model grok-4.3
The pith
IntentNav extracts high-level search intent from human demonstrations by labeling frontiers and trains a VLM to select among spatial-visual candidates, reaching state-of-the-art object navigation that transfers zero-shot across robot bodies
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
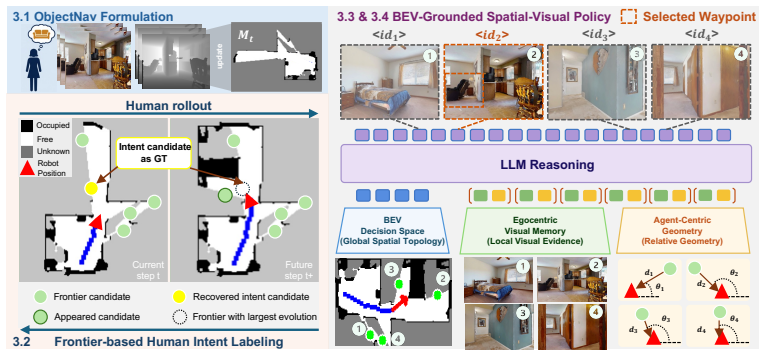
IntentNav introduces Frontier-based Human-Intent Labeling that looks ahead in human demonstrations to assign each action sequence to the frontier that best accounts for the demonstrator's future search direction. It constructs a spatial-visual candidate space in which BEV memory records explored regions, unexplored frontiers and trajectory history while egocentric visual memory supplies semantic information for each candidate; a VLM policy is then trained on these candidates under an Intent-Aligned Objective that favors consistent, human-like selections. The resulting system attains state-of-the-art success rates on the MP3D, HM3D-v1 and HM3D-v2 ObjectNav benchmarks and its candidate-level i
What carries the argument
Frontier-based Human-Intent Labeling, which looks ahead in demonstrations to assign search intent to the frontier that explains future direction and supplies these labels to a spatial-visual candidate space for VLM policy training.
If this is right
- State-of-the-art performance on the MP3D, HM3D-v1 and HM3D-v2 ObjectNav benchmarks.
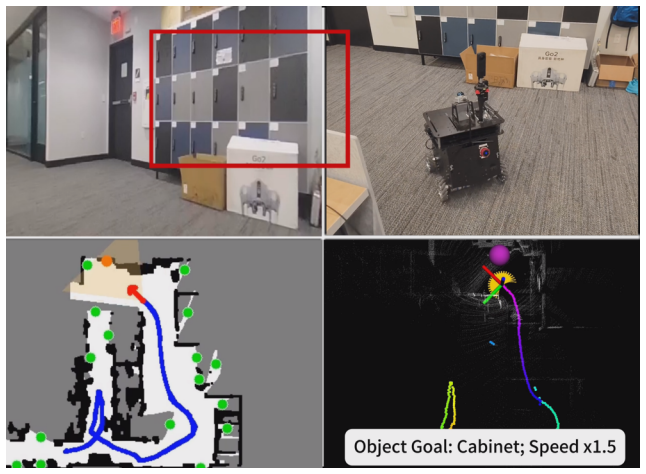
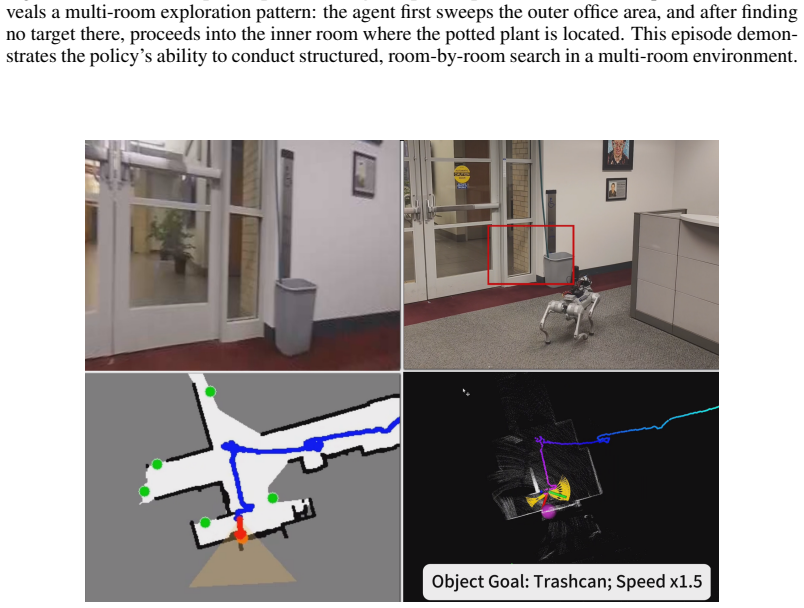
- The candidate-level navigation interface transfers zero-shot to wheeled, quadruped, and humanoid robots without further VLM fine-tuning.
- Exploration avoids redundant revisits by maintaining spatial memory of explored regions while using visual cues to probe promising frontiers.
- Imitation from human demonstrations produces policies whose high-level choices remain consistent across different robot bodies.
Where Pith is reading between the lines
- The separation of intent labeling from low-level control may let the same trained policy serve new robot platforms by swapping only the low-level executor.
- Frontier-based intent extraction could extend to other partially observable search tasks such as mapping or inspection without requiring embodiment-specific retraining.
- Grounding VLM decisions in an explicit spatial-visual candidate space may reduce hallucinated exploration paths compared with purely visual end-to-end policies.
Load-bearing premise
Frontier labels derived from looking ahead in human demonstrations accurately capture transferable high-level search intent that generalizes from human data to robot execution across different embodiments.
What would settle it
A controlled experiment that replaces the human-intent frontier labels with random or heuristic labels during training and measures whether the resulting VLM policy still achieves the reported state-of-the-art success rates on HM3D-v2.
Figures





read the original abstract
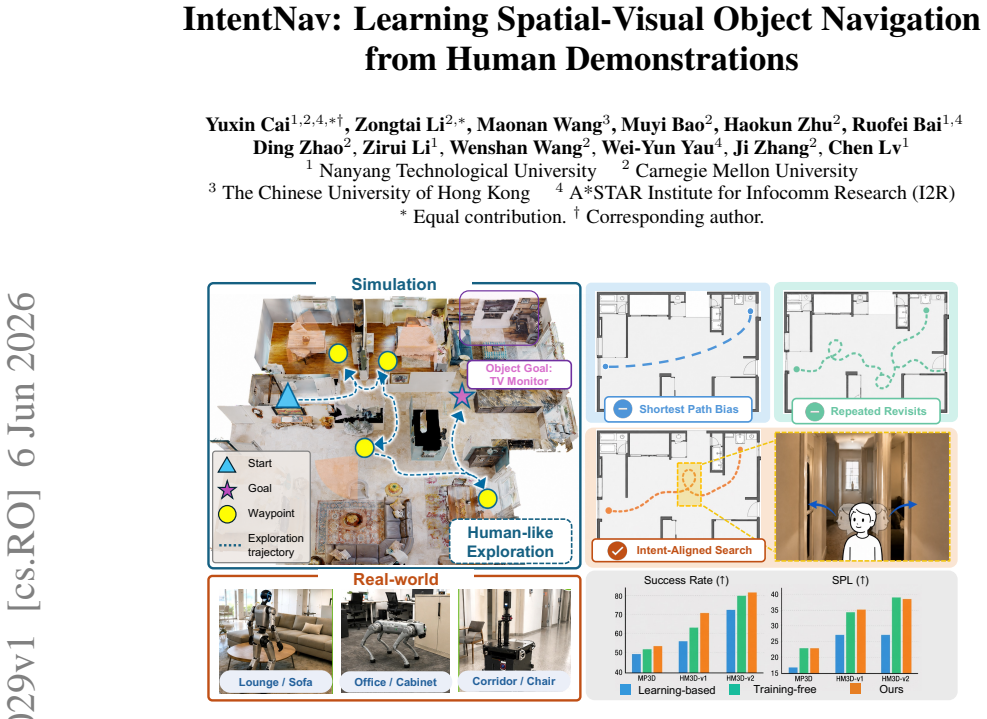
Object navigation requires a robot to search for an unobserved target in an unknown environment by deciding where to explore next under partial observability. Effective search resembles human-like exploration: selectively probing visually promising frontiers while relying on spatial memory to avoid redundant revisits. We propose IntentNav, a spatial-visual imitation framework that learns human-like ObjectNav policies from human demonstrations. To infer high-level search intent from low-level human actions, we introduce Frontier-based Human-Intent Labeling, which looks ahead in human demonstrations and labels the frontier that best explains the demonstrator's future search direction. We construct a spatial-visual candidate space, where BEV memory tracks explored regions, unexplored frontiers, and trajectory history, while egocentric visual memory provides semantic cues for each candidate. A VLM policy is trained to select among these grounded candidates, using Intent-Aligned Objective to encourage consistent and human-like exploration. IntentNav achieves state-of-the-art performance on the MP3D, HM3D-v1 and HM3D-v2 ObjectNav benchmarks. The proposed candidate-level navigation interface transfers zero-shot to wheeled, quadruped, and humanoid robots without further VLM fine-tuning. \href{https://anonymous.4open.science/w/IntentNav/}{Project page}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces IntentNav, a spatial-visual imitation learning framework for object navigation that infers high-level search intent from human demonstrations via Frontier-based Human-Intent Labeling (looking ahead in trajectories to label explanatory frontiers). It constructs a candidate space combining BEV memory (for explored regions, frontiers, and history) with egocentric visual memory (for semantic cues), then trains a VLM policy to select among candidates using an Intent-Aligned Objective. The manuscript claims state-of-the-art performance on the MP3D, HM3D-v1, and HM3D-v2 ObjectNav benchmarks along with zero-shot transfer of the candidate-level interface to wheeled, quadruped, and humanoid robots without further VLM fine-tuning.
Significance. If the results hold, particularly the zero-shot embodiment transfer, the work would be significant for robot navigation by showing how human demonstration data can yield VLM policies that generalize across platforms without robot-specific retraining. The frontier-labeling procedure and structured spatial-visual candidate space offer a concrete mechanism for grounding high-level intent, which could lower data collection costs and improve sim-to-real transfer in partial-observability search tasks.
major comments (2)
- [Abstract] Abstract: The assertion of state-of-the-art performance on MP3D, HM3D-v1 and HM3D-v2 is presented without any quantitative metrics, baseline comparisons, ablation results, or evaluation protocol details, which is load-bearing for the central claim of superiority over prior methods.
- [Abstract] Abstract: The zero-shot transfer claim to wheeled, quadruped, and humanoid robots without VLM fine-tuning relies on the untested assumption that the spatial-visual candidate space (BEV + egocentric) plus Intent-Aligned Objective produces decisions invariant to kinematics, sensor placement, and reachable frontiers; no quantitative ablation or measurement of the embodiment gap or viewpoint shift is supplied, directly undermining validation of the transfer result.
Simulated Author's Rebuttal
We thank the referee for highlighting issues in the abstract that affect the clarity of our central claims. We agree that the abstract requires strengthening with concrete metrics and will revise it accordingly. We address each comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion of state-of-the-art performance on MP3D, HM3D-v1 and HM3D-v2 is presented without any quantitative metrics, baseline comparisons, ablation results, or evaluation protocol details, which is load-bearing for the central claim of superiority over prior methods.
Authors: We agree that the abstract should include supporting quantitative evidence. In the revised manuscript we will add concise performance numbers (e.g., success-rate gains over the strongest baselines on each benchmark) and a brief reference to the standard ObjectNav evaluation protocol and main baselines. Full tables, ablations, and protocol details remain in the experiments section. revision: yes
-
Referee: [Abstract] Abstract: The zero-shot transfer claim to wheeled, quadruped, and humanoid robots without VLM fine-tuning relies on the untested assumption that the spatial-visual candidate space (BEV + egocentric) plus Intent-Aligned Objective produces decisions invariant to kinematics, sensor placement, and reachable frontiers; no quantitative ablation or measurement of the embodiment gap or viewpoint shift is supplied, directly undermining validation of the transfer result.
Authors: The manuscript already reports successful zero-shot deployments on the three platforms using the same candidate interface and policy. We acknowledge that explicit quantitative ablations isolating the embodiment gap or viewpoint shift are not present. The revision will (1) reference the transfer experiments in the abstract and (2) add a short discussion of the design choices intended to promote embodiment invariance. We do not plan new experiments for this revision. revision: partial
Circularity Check
No circularity in derivation chain; method is standard imitation learning with empirical claims
full rationale
The paper presents a spatial-visual imitation learning framework using Frontier-based Human-Intent Labeling on human demonstrations to train a VLM policy for candidate selection. No equations, derivations, or parameter-fitting steps are described that reduce by construction to their own inputs. Claims of SOTA performance and zero-shot transfer are empirical assertions, not self-referential definitions or predictions forced by fitted parameters. No self-citation load-bearing or uniqueness theorems are invoked in the provided text. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
On Evaluation of Embodied Navigation Agents
P. Anderson, A. Chang, D. S. Chaplot, A. Dosovitskiy, S. Gupta, V . Koltun, J. Kosecka, J. Ma- lik, R. Mottaghi, M. Savva, et al. On evaluation of embodied navigation agents.arXiv preprint arXiv:1807.06757, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
J. Sun, J. Wu, Z. Ji, and Y .-K. Lai. A survey of object goal navigation.IEEE Transactions on Automation Science and Engineering, 2024
2024
- [4]
-
[5]
Yokoyama, S
N. Yokoyama, S. Ha, D. Batra, J. Wang, and B. Bucher. Vlfm: Vision-language frontier maps for zero-shot semantic navigation. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 42–48. IEEE, 2024
2024
-
[6]
Kuang, H
Y . Kuang, H. Lin, and M. Jiang. Openfmnav: Towards open-set zero-shot object navigation via vision-language foundation models. InFindings of the Association for Computational Linguistics: NAACL 2024, pages 338–351, 2024
2024
-
[7]
H. Yin, X. Xu, Z. Wu, J. Zhou, and J. Lu. Sg-nav: Online 3d scene graph prompting for llm- based zero-shot object navigation.Advances in neural information processing systems, 37: 5285–5307, 2024
2024
- [8]
- [9]
- [10]
-
[11]
B. Chen, Z. Xu, S. Kirmani, B. Ichter, D. Sadigh, L. Guibas, and F. Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14455–14465, 2024
2024
- [12]
- [13]
- [14]
-
[15]
NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation
J. Zhang, K. Wang, R. Xu, G. Zhou, Y . Hong, X. Fang, Q. Wu, Z. Zhang, and H. Wang. Navid: Video-based vlm plans the next step for vision-and-language navigation, 2024. URL https://arxiv.org/abs/2402.15852
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Uni-NaVid: A Video-based Vision-Language-Action Model for Unifying Embodied Navigation Tasks
J. Zhang, K. Wang, S. Wang, M. Li, H. Liu, S. Wei, Z. Wang, Z. Zhang, and H. Wang. Uni- navid: A video-based vision-language-action model for unifying embodied navigation tasks. arXiv preprint arXiv:2412.06224, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [17]
- [18]
- [19]
-
[20]
Majumdar, G
A. Majumdar, G. Aggarwal, B. Devnani, J. Hoffman, and D. Batra. Zson: Zero-shot object- goal navigation using multimodal goal embeddings.Advances in Neural Information Process- ing Systems, 35:32340–32352, 2022
2022
-
[21]
B. Yu, H. Kasaei, and M. Cao. L3mvn: Leveraging large language models for visual target navigation. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3554–3560. IEEE, 2023
2023
-
[22]
Zhang, Y
M. Zhang, Y . Du, C. Wu, J. Zhou, Z. Qi, J. Ma, and B. Zhou. Apexnav: An adaptive exploration strategy for zero-shot object navigation with target-centric semantic fusion.IEEE Robotics and Automation Letters, 2025
2025
- [23]
-
[24]
Ramrakhya, E
R. Ramrakhya, E. Undersander, D. Batra, and A. Das. Habitat-web: Learning embodied object- search strategies from human demonstrations at scale. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 5173–5183, 2022
2022
-
[25]
Matterport3D: Learning from RGB-D Data in Indoor Environments
A. Chang, A. Dai, T. Funkhouser, M. Halber, M. Niessner, M. Savva, S. Song, A. Zeng, and Y . Zhang. Matterport3d: Learning from rgb-d data in indoor environments.arXiv preprint arXiv:1709.06158, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [26]
-
[27]
Z. Chen, W. Wang, Y . Cao, Y . Liu, Z. Gao, E. Cui, J. Zhu, S. Ye, H. Tian, Z. Liu, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Yadav, S
K. Yadav, S. K. Ramakrishnan, J. Turner, A. Gokaslan, O. Maksymets, R. Jain, R. Ramrakhya, A. X. Chang, A. Clegg, M. Savva, E. Undersander, D. S. Chaplot, and D. Batra. Habitat challenge 2022.https://aihabitat.org/challenge/2022/, 2022
2022
-
[29]
Yadav, R
K. Yadav, R. Ramrakhya, S. K. Ramakrishnan, T. Gervet, J. Turner, A. Gokaslan, N. Maestre, A. X. Chang, D. Batra, M. Savva, et al. Habitat-matterport 3d semantics dataset. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4927–4936, 2023. 10
2023
- [30]
- [31]
- [32]
-
[33]
C. Peng, Z. Zhang, C. Chi, X. Wei, Y . Zhang, H. Wang, P. Wang, Z. Wang, J. Liu, and S. Zhang. Pigeon: Vlm-driven object navigation via points of interest selection.arXiv preprint arXiv:2511.13207, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
E. Wijmans, A. Kadian, A. Morcos, S. Lee, I. Essa, D. Parikh, M. Savva, and D. Batra. Dd-ppo: Learning near-perfect pointgoal navigators from 2.5 billion frames.arXiv preprint arXiv:1911.00357, 2019
-
[35]
W. Cai, S. Huang, G. Cheng, Y . Long, P. Gao, C. Sun, and H. Dong. Bridging zero-shot object navigation and foundation models through pixel-guided navigation skill. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 5228–5234. IEEE, 2024
2024
-
[36]
S. K. Ramakrishnan, D. S. Chaplot, Z. Al-Halah, J. Malik, and K. Grauman. Poni: Po- tential functions for objectgoal navigation with interaction-free learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18890–18900, 2022
2022
-
[37]
D. S. Chaplot, D. P. Gandhi, A. Gupta, and R. R. Salakhutdinov. Object goal navigation using goal-oriented semantic exploration.Advances in Neural Information Processing Systems, 33: 4247–4258, 2020
2020
-
[38]
H. Yin, X. Xu, L. Zhao, Z. Wang, J. Zhou, and J. Lu. Unigoal: Towards universal zero-shot goal-oriented navigation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19057–19066, 2025. 11 Appendix A BEV Map Construction from RGB-D Observations This section describes the BEV mapping procedure used to construct the spatial input...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.