SKILL.nb: Selective Formalization and Gated Execution for Durable Agent Workflows
Pith reviewed 2026-06-27 19:42 UTC · model grok-4.3
The pith
Selective formalization turns execution evidence into code gates that let agent workflows retain success across re-runs and version shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
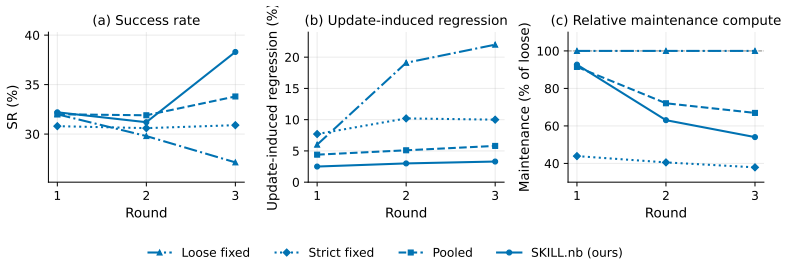
SKILL.nb achieves 53.7 percent single-round success on WebArena-Verified by using selective formalization to decide which workflow steps become executable code versus natural-language guidance, guided by execution evidence. Workflows are stored as versioned notebooks containing interleaved natural language, multi-language cells, validation gates, fallback paths, and multimodal traces. Gate-conditioned execution runs code only when gates validate and falls back locally on drift. The same system retains 91.7 percent of initial successes across three re-executions, recovers 72.9 percent of subsequent failures while limiting regressions to 4.2 percent, leads on Mind2Web splits, and preserves per
What carries the argument
Selective formalization that uses execution evidence to choose between code and natural-language realizations for each step, paired with gate-conditioned execution inside auditable versioned notebooks that carry multimodal evidence and fallback paths.
If this is right
- Raises single-round success to 53.7 percent on WebArena-Verified, 3.9 points above the strongest baseline.
- Retains 91.7 percent of initially successful tasks across three re-executions, 15.5 points above the next best method.
- Recovers 72.9 percent of subsequent failures under bounded repair while limiting regressions to 4.2 percent.
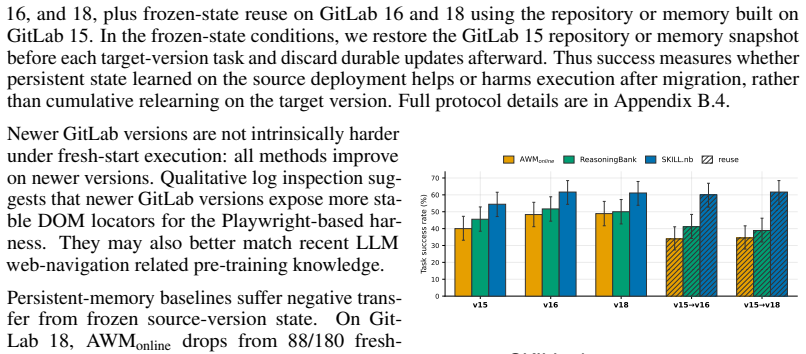
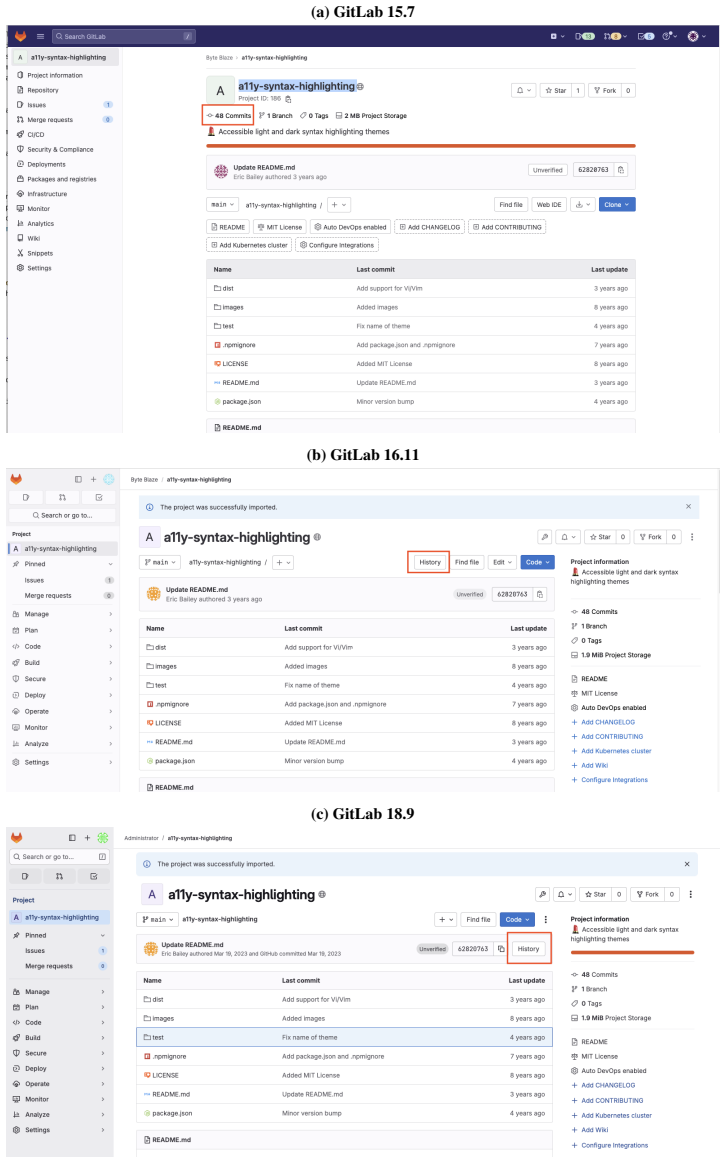
- Preserves performance when reusing frozen notebooks across GitLab version shifts with gaps of at most 1.7 points.
- Leads on both cross-website and cross-domain splits of Mind2Web.
Where Pith is reading between the lines
- The same evidence-driven choice between code and natural language could be applied to non-web agent domains that repeat tasks under uncertainty.
- Versioned notebooks with explicit gates offer a practical route to auditability for agents used in regulated settings.
- Low regression rates during repair suggest the method could support longer autonomous operation without frequent human intervention.
- Testing the same notebook reuse across larger distribution shifts would clarify how far the durability gains extend.
Load-bearing premise
Execution evidence can be used to make reliable decisions on which steps to formalize into code without the formalization process itself introducing new failure modes or requiring extensive manual tuning.
What would settle it
A controlled comparison in which a version of the system that never formalizes any steps outperforms SKILL.nb on a benchmark containing measurable environment drift.
Figures
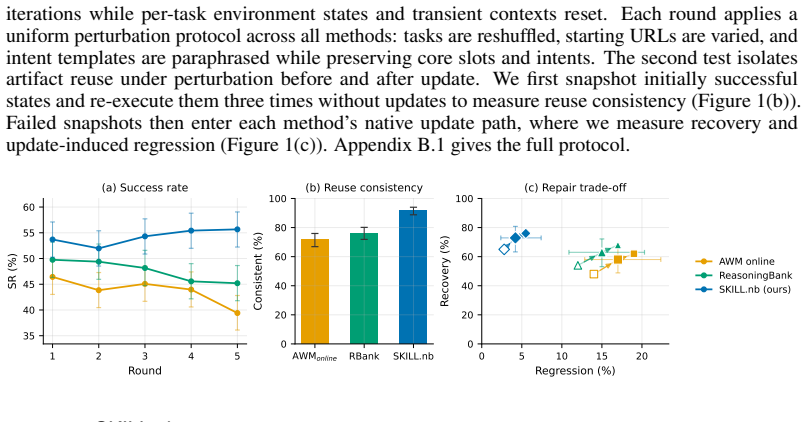


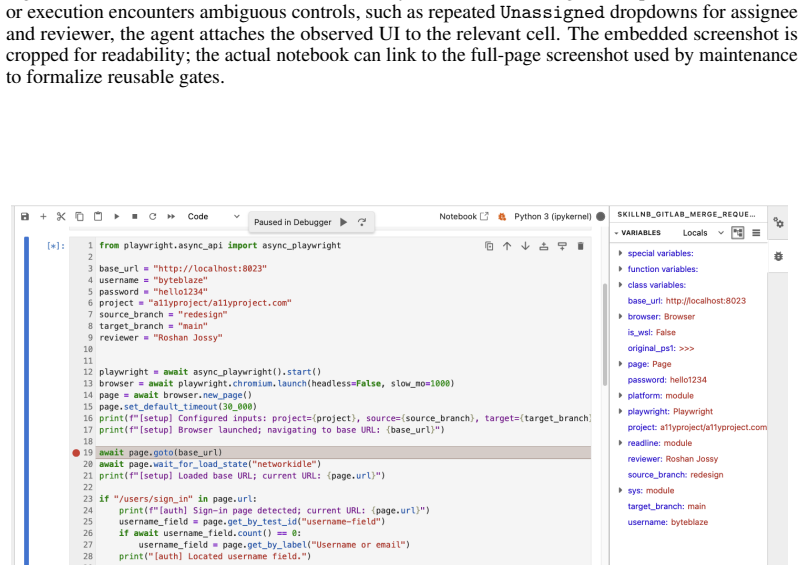
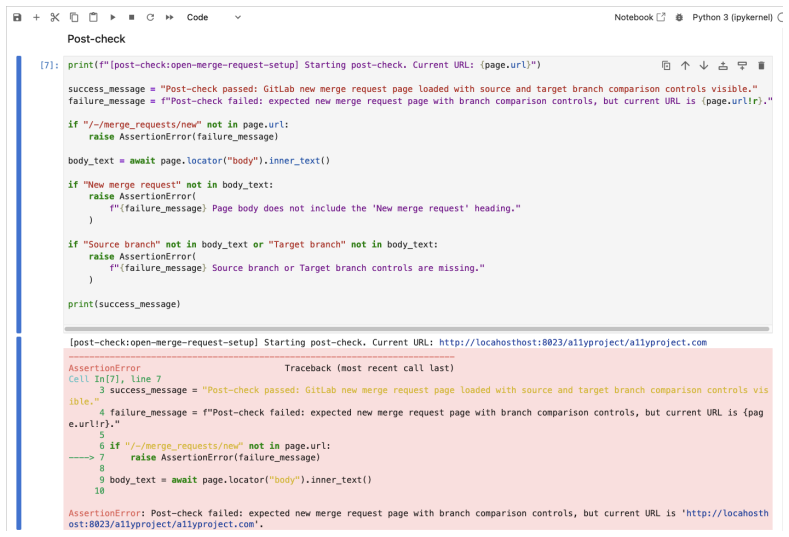
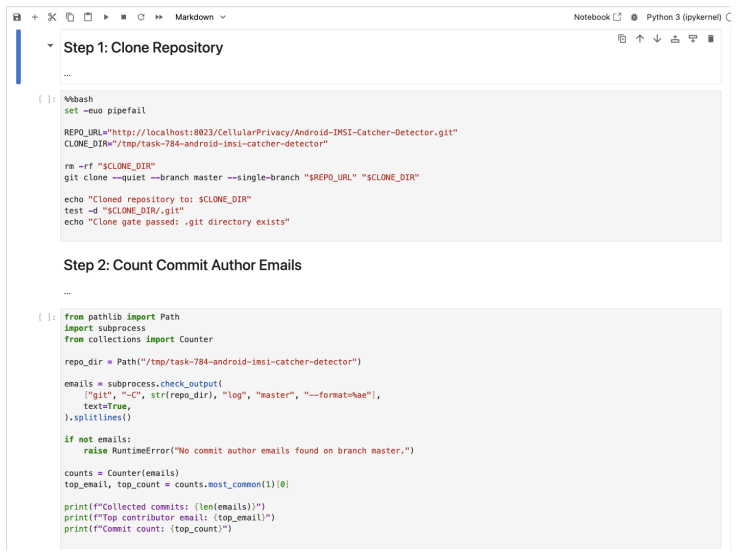

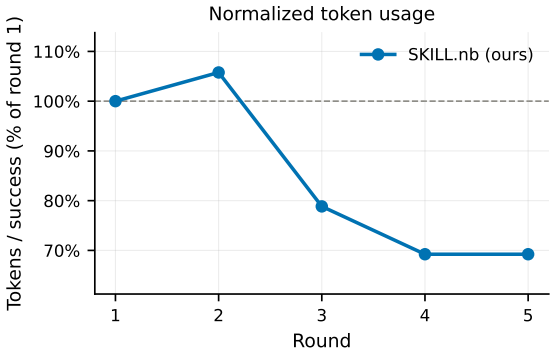
read the original abstract
AI agents increasingly turn past experience into reusable artifacts such as code, workflows, and procedural memories. Reuse can improve efficiency, but it also creates a lifecycle reliability problem: artifacts that succeed once may fail under environment drift, underspecified tasks, or changing task distributions, especially in web automation. We introduce SKILL.nb, a framework for governing reusable agent workflows with evidence-calibrated lifecycle policies. SKILL.nb uses selective formalization: execution evidence decides which workflow steps should become executable code, which should remain natural-language guided, and when those choices should be revised. Workflows are stored as auditable, versioned notebooks that interleave natural-language guidance, multi-language executable cells, validation gates, fallback paths, and multimodal evidence such as outputs, screenshots, and error traces. At runtime, gate-conditioned execution lets each step run code when its gates validate, or fall back locally when drift invalidates the executable realization. On WebArena-Verified, SKILL.nb achieves 53.7% single-round success, improving over the strongest baseline by 3.9 percentage points. Across three re-executions, it retains 91.7% of initially successful tasks, 15.5 points above the next best method. Under bounded repair, it recovers 72.9% of subsequent failures while limiting post-repair regressions to 4.2%, compared with 15.0% to 17.0% for persistent baselines. It also leads on Mind2Web cross-website and cross-domain splits. In a GitLab migration test, SKILL.nb preserves performance when reusing frozen state learned on GitLab 15.7, with frozen-versus-fresh target-version gaps of -1.7 points on GitLab 16.11 and +0.6 points on GitLab 18.9. These results identify lifecycle governance and gate-conditioned execution as reliability axes beyond one-shot task success.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SKILL.nb, a framework for durable AI agent workflows that employs selective formalization—using execution evidence to decide which steps become code versus natural-language guidance—and gate-conditioned execution within versioned, auditable notebooks. It reports empirical gains on WebArena-Verified (53.7% single-round success, +3.9pp over strongest baseline), 91.7% retention over three re-executions (+15.5pp), 72.9% recovery of failures with only 4.2% regressions, leadership on Mind2Web splits, and robustness to GitLab version shifts.
Significance. If the durability claims hold, the work meaningfully advances agent reliability research by treating lifecycle governance and evidence-driven formalization as first-class concerns rather than post-hoc fixes. The empirical identification of retention and bounded-repair metrics as distinct axes beyond one-shot success provides a concrete basis for future benchmarking in dynamic environments.
major comments (1)
- [Abstract] Abstract and evaluation sections: performance deltas (e.g., 3.9pp single-round success, 15.5pp retention) are reported without error bars, confidence intervals, number of runs, or statistical significance tests. This is load-bearing for the central claim that SKILL.nb improves durability, as the robustness of the gains cannot be assessed from the stated numbers alone.
minor comments (1)
- [Abstract] The abstract refers to 'evidence-calibrated lifecycle policies' and 'gate logic' without a high-level pseudocode or decision procedure; adding a compact diagram or algorithm box in the methods section would improve clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the need for statistical robustness in the reported results. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation sections: performance deltas (e.g., 3.9pp single-round success, 15.5pp retention) are reported without error bars, confidence intervals, number of runs, or statistical significance tests. This is load-bearing for the central claim that SKILL.nb improves durability, as the robustness of the gains cannot be assessed from the stated numbers alone.
Authors: We agree that the absence of error bars, confidence intervals, the number of runs, and statistical significance tests limits the ability to evaluate the robustness of the durability improvements. The current manuscript reports point estimates in the abstract and evaluation sections without these supporting details. In the revised manuscript we will add the number of independent runs performed for the WebArena-Verified and Mind2Web experiments, report standard deviations or confidence intervals where multiple runs were conducted, and include paired statistical significance tests against the strongest baselines. These additions will appear in both the abstract and the relevant evaluation subsections. revision: yes
Circularity Check
No significant circularity
full rationale
The paper reports purely empirical benchmark results on WebArena-Verified, Mind2Web, and GitLab version-shift tests. No equations, derivations, fitted parameters presented as predictions, or self-citation chains appear in the abstract or described mechanism. The central claims rest on direct experimental deltas (success rates, retention, repair rates) against external baselines, with no reduction of any result to its own inputs by construction. This is the expected non-finding for an empirical systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mem0: Building production-ready AI agents with scalable long-term memory, 2025
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready AI agents with scalable long-term memory, 2025. URL https: //arxiv.org/abs/2504.19413
Pith/arXiv arXiv 2025
-
[2]
WATER: Web application test repair
Shauvik Roy Choudhary, Dan Zhao, Husayn Versee, and Alessandro Orso. WATER: Web application test repair. InProceedings of the First International Workshop on End-to-End Test Script Engineering, 2011
2011
-
[3]
The lean 4 theorem prover and programming language
Leonardo de Moura and Sebastian Ullrich. The lean 4 theorem prover and programming language. InAutomated Deduction – CADE 28, pages 625–635. Springer, 2021
2021
-
[4]
Mind2Web: Towards a generalist agent for the web.Advances in Neural Information Processing Systems, 36:28091–28114, December 2023
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2Web: Towards a generalist agent for the web.Advances in Neural Information Processing Systems, 36:28091–28114, December 2023
2023
-
[5]
WebArena Verified: Reliable evaluation for web agents
Amine El Hattami, Megh Thakkar, Nicolas Chapados, and Christopher Pal. WebArena Verified: Reliable evaluation for web agents. InWorkshop on Scalable and Efficient Agents at NeurIPS, 2025
2025
-
[6]
Bridging the prototype-production gap: A multi-agent system for notebooks transformation, 2025
Hanya Elhashemy, Youssef Lotfy, and Yongjian Tang. Bridging the prototype-production gap: A multi-agent system for notebooks transformation, 2025. URL https://arxiv.org/abs/ 2511.07257
arXiv 2025
-
[7]
MemP: Exploring agent procedural memory, 2025
Runnan Fang, Yuan Liang, Xiaobin Wang, Jialong Wu, Shuofei Qiao, Pengjun Xie, Fei Huang, Huajun Chen, and Ningyu Zhang. MemP: Exploring agent procedural memory, 2025. URL https://arxiv.org/abs/2508.06433
Pith/arXiv arXiv 2025
-
[8]
Huan-ang Gao, Jiayi Geng, Wenyue Hua, Mengkang Hu, Xinzhe Juan, Hongzhang Liu, Shilong Liu, Jiahao Qiu, Xuan Qi, Yiran Wu, Hongru Wang, Han Xiao, Yuhang Zhou, Shaokun Zhang, Jiayi Zhang, Jinyu Xiang, Yixiong Fang, Qiwen Zhao, Dongrui Liu, Qihan Ren, Cheng Qian, Zhenhailong Wang, Minda Hu, Huazheng Wang, Qingyun Wu, Heng Ji, and Mengdi Wang. A survey of se...
Pith/arXiv arXiv 2025
-
[9]
Carlin, Hal S
Andrew Gelman, John B. Carlin, Hal S. Stern, David B. Dunson, Aki Vehtari, and Donald B. Rubin.Bayesian Data Analysis. Chapman and Hall/CRC, 3rd edition, 2013
2013
-
[10]
Alas: Transactional and dynamic multi-agent llm planning.arXiv preprint arXiv:2511.03094, 2025
Longling Geng and Edward Y Chang. Alas: Transactional and dynamic multi-agent llm planning.arXiv preprint arXiv:2511.03094, 2025
arXiv 2025
-
[11]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[12]
HiA- gent: Hierarchical working memory management for solving long-horizon agent tasks with large language model
Mengkang Hu, Tianxing Chen, Qiguang Chen, Yao Mu, Wenqi Shao, and Ping Luo. HiA- gent: Hierarchical working memory management for solving long-horizon agent tasks with large language model. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 32779–32798, Vienna, Austria,
-
[13]
doi: 10.18653/v1/2025.acl-long.1575
Association for Computational Linguistics. doi: 10.18653/v1/2025.acl-long.1575. URL https://aclanthology.org/2025.acl-long.1575/
-
[14]
Xu, Tianyue Ou, Shuyan Zhou, Jeffrey P
Faria Huq, Zora Zhiruo Wang, Frank F. Xu, Tianyue Ou, Shuyan Zhou, Jeffrey P. Bigham, and Graham Neubig. Cowpilot: A framework for autonomous and human-agent collabora- tive web navigation. InProceedings of the 2025 Conference of the Nations of the Amer- icas Chapter of the Association for Computational Linguistics: Human Language Tech- nologies (System D...
-
[15]
Jiang, Wenda Li, Szymon Tworkowski, Konrad Czechowski, Tomasz Odrzygó´ zd´ z, Piotr Miło´s, Yuhuai Wu, and Mateja Jamnik
Albert Q. Jiang, Wenda Li, Szymon Tworkowski, Konrad Czechowski, Tomasz Odrzygó´ zd´ z, Piotr Miło´s, Yuhuai Wu, and Mateja Jamnik. Draft, sketch, and prove: Guiding formal theorem provers with informal proofs. InInternational Conference on Learning Representations, 2023. 10
2023
-
[16]
Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, Yuling Gu, Saumya Malik, Victoria Graf, Jena D
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V . Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, Yuling Gu, Saumya Malik, Victoria Graf, Jena D. Hwang, Jiangjiang Yang, Ronan Le Bras, Oyvind Tafjord, Chris Wilhelm, Luca Soldaini, Noah A. Smith, Yizhong Wang, Pradeep Dasigi, and Hannaneh Hajishirz...
Pith/arXiv arXiv 2024
-
[17]
Visual vs
Maurizio Leotta, Diego Clerissi, Filippo Ricca, and Paolo Tonella. Visual vs. DOM-based web locators: An empirical study. InInternational Conference on Web Engineering, 2014
2014
-
[18]
ROBULA+: An algorithm for generating robust XPath locators for web testing.Journal of Software: Evolution and Process, 2016
Maurizio Leotta, Diego Clerissi, Filippo Ricca, and Paolo Tonella. ROBULA+: An algorithm for generating robust XPath locators for web testing.Journal of Software: Evolution and Process, 2016
2016
-
[19]
Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems.arXiv preprint arXiv:2005.01643, 2020
Pith/arXiv arXiv 2005
-
[20]
ST- WebAgentBench: A Benchmark for Evaluating Safety and Trustworthiness in Web Agents, May
Ido Levy, Ben Wiesel, Sami Marreed, Alon Oved, Avi Yaeli, and Segev Shlomov. ST- WebAgentBench: A Benchmark for Evaluating Safety and Trustworthiness in Web Agents, May
- [21]
-
[22]
Yang Li, Siqi Ping, Xiyu Chen, Xiaojian Qi, Zigan Wang, Ye Luo, and Xiaowei Zhang. Agentgit: A version control framework for reliable and scalable llm-powered multi-agent systems.arXiv preprint arXiv:2511.00628, 2025
arXiv 2025
-
[23]
Self-evolving agents with reflective and memory-augmented abilities, 2024
Xuechen Liang, Yangfan He, Yinghui Xia, Xinyuan Song, Jianhui Wang, Meiling Tao, Li Sun, Xinhang Yuan, Jiayi Su, Keqin Li, Jiaqi Chen, Jinsong Yang, Siyuan Chen, and Tianyu Shi. Self-evolving agents with reflective and memory-augmented abilities, 2024. URL https: //arxiv.org/abs/2409.00872
arXiv 2024
-
[24]
Junwei Liu, Kaixin Wang, Yixuan Chen, Xin Peng, Zhenpeng Chen, Lingming Zhang, and Yiling Lou. Large language model-based agents for software engineering: A survey.arXiv preprint arXiv:2409.02977, 2024
Pith/arXiv arXiv 2024
-
[25]
Yimeng Liu, Misha Sra, Jeevana Priya Inala, and Chenglong Wang. Reuseit: Synthesizing reusable ai agent workflows for web automation.arXiv preprint arXiv:2510.14308, 2025
arXiv 2025
-
[26]
Yitao Liu, Chenglei Si, Karthik R. Narasimhan, and Shunyu Yao. Contextual experience replay for self-improvement of language agents. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14179–14198, Vienna, Austria, 2025. Association for Computational Linguistics. doi: 10.18653/v1/2025. a...
-
[27]
CLIN: A continually learning language agent for rapid task adaptation and generalization, 2023
Bodhisattwa Prasad Majumder, Bhavana Dalvi Mishra, Peter Jansen, Oyvind Tafjord, Niket Tandon, Li Zhang, Chris Callison-Burch, and Peter Clark. CLIN: A continually learning language agent for rapid task adaptation and generalization, 2023. URL https://arxiv.org/ abs/2310.10134
arXiv 2023
-
[28]
Bardia Mohammadi, Nearchos Potamitis, Lars Klein, Akhil Arora, and Laurent Bindschaedler. Atomix: Timely, transactional tool use for reliable agentic workflows.arXiv preprint arXiv:2602.14849, 2026
Pith/arXiv arXiv 2026
-
[29]
Le, Samira Daruki, Xiangru Tang, Vishy Tirumalashetty, George Lee, Mahsan Rofouei, Hangfei Lin, Jiawei Han, Chen-Yu Lee, and Tomas Pfister
Siru Ouyang, Jun Yan, I-Hung Hsu, Yanfei Chen, Ke Jiang, Zifeng Wang, Rujun Han, Long T. Le, Samira Daruki, Xiangru Tang, Vishy Tirumalashetty, George Lee, Mahsan Rofouei, Hangfei Lin, Jiawei Han, Chen-Yu Lee, and Tomas Pfister. ReasoningBank: Scaling agent self-evolving with reasoning memory, 2025
2025
-
[30]
Patil, Ion Stoica, and Joseph E
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. MemGPT: Towards LLMs as operating systems, 2023. URL https: //arxiv.org/abs/2310.08560
Pith/arXiv arXiv 2023
-
[31]
Yun Piao, Hongbo Min, Hang Su, Leilei Zhang, Lei Wang, Yue Yin, Xiao Wu, Zhejing Xu, Liwei Qu, Hang Li, et al. Agentbay: A hybrid interaction sandbox for seamless human-ai intervention in agentic systems.arXiv preprint arXiv:2512.04367, 2025. 11
arXiv 2025
-
[32]
Investigate-consolidate-exploit: A general strategy for inter-task agent self-evolution, 2024
Cheng Qian, Shihao Liang, Yujia Qin, Yining Ye, Xin Cong, Yankai Lin, Yesai Wu, Zhiyuan Liu, and Maosong Sun. Investigate-consolidate-exploit: A general strategy for inter-task agent self-evolution, 2024. URLhttps://arxiv.org/abs/2401.13996
arXiv 2024
-
[33]
Albarrak, and Sultan Noman Qasem
Hanif Ur Rahman, Asaad Alzayed, Muhammad Ismail Mohmand, Abdullah M. Albarrak, and Sultan Noman Qasem. Application maintenance offshoring using hci based framework and simple multi attribute rating technique (smart).IEEE Access, 11:107068–107084, 2023. doi: 10.1109/ACCESS.2023.3320941
-
[34]
Visual web test repair
Andrea Stocco, Maurizio Leotta, Filippo Ricca, and Paolo Tonella. Visual web test repair. In Proceedings of the ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, 2018
2018
-
[35]
Hongjin Su, Ruoxi Sun, Jinsung Yoon, Pengcheng Yin, Tao Yu, and Sercan O. Arik. Learn- by-interact: A data-centric framework for self-adaptive agents in realistic environments. In The Thirteenth International Conference on Learning Representations, 2025. URL https: //openreview.net/forum?id=3UKOzGWCVY
2025
-
[36]
In prospect and retrospect: Reflective memory management for long-term personalized dialogue agents
Zhen Tan, Jun Yan, I-Hung Hsu, Rujun Han, Zifeng Wang, Long Le, Yiwen Song, Yanfei Chen, Hamid Palangi, George Lee, Anand Rajan Iyer, Tianlong Chen, Huan Liu, Chen-Yu Lee, and Tomas Pfister. In prospect and retrospect: Reflective memory management for long-term personalized dialogue agents. InProceedings of the 63rd Annual Meeting of the Association for C...
-
[37]
doi: 10.18653/v1/2025.acl-long.413
Association for Computational Linguistics. doi: 10.18653/v1/2025.acl-long.413. URL https://aclanthology.org/2025.acl-long.413/
-
[38]
ChemAgent: Self-updating memories in large language models improves chemical reason- ing
Xiangru Tang, Tianyu Hu, Muyang Ye, Yanjun Shao, Xunjian Yin, Siru Ouyang, Wangchun- shu Zhou, Pan Lu, Zhuosheng Zhang, Yilun Zhao, Arman Cohan, and Mark Gerstein. ChemAgent: Self-updating memories in large language models improves chemical reason- ing. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net...
2025
-
[39]
Wenyu Tao, Xiaofen Xing, Yirong Chen, Linyi Huang, and Xiangmin Xu. Treerag: Unleashing the power of hierarchical storage for enhanced knowledge retrieval in long documents. In Findings of the Association for Computational Linguistics: ACL 2025, pages 356–371, Vienna, Austria, 2025. Association for Computational Linguistics. doi: 10.18653/v1/2025.findings-acl
-
[40]
URLhttps://aclanthology.org/2025.findings-acl.20/
2025
-
[41]
Thomas, Georgios Theocharous, and Mohammad Ghavamzadeh
Philip S. Thomas, Georgios Theocharous, and Mohammad Ghavamzadeh. High confidence policy improvement. InInternational Conference on Machine Learning, 2015
2015
-
[42]
V oyager: An open-ended embodied agent with large language models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. Transactions on Machine Learning Research, November 2023. ISSN 2835-8856
2023
-
[43]
Executable code actions elicit better LLM agents
Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, and Heng Ji. Executable code actions elicit better LLM agents. InInternational Conference on Machine Learning, 2024
2024
-
[44]
TroVE: Inducing verifiable and efficient toolboxes for solving programmatic tasks
Zhiruo Wang, Graham Neubig, and Daniel Fried. TroVE: Inducing verifiable and efficient toolboxes for solving programmatic tasks. InForty-First International Conference on Machine Learning, 2024. URLhttps://openreview.net/forum?id=DCNCwaMJjI
2024
-
[45]
Agent workflow memory
Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. Agent workflow memory. InInternational Conference on Learning Representations, 2025
2025
-
[46]
Jiang, Wenda Li, Markus N
Yuhuai Wu, Albert Q. Jiang, Wenda Li, Markus N. Rabe, Charles Staats, Mateja Jamnik, and Christian Szegedy. Autoformalization with large language models. InAdvances in Neural Information Processing Systems, 2022
2022
-
[47]
OS-Copilot: Towards generalist computer agents with self- improvement
Zhiyong Wu, Chengcheng Han, Zichen Ding, Zhoumianze Weng, Zhenmin Liu, Shunyu Yao, Tao Yu, and Lingpeng Kong. OS-Copilot: Towards generalist computer agents with self- improvement. InICLR 2024 Workshop on Large Language Model (LLM) Agents, March 2025. 12
2024
-
[48]
A-MEM: Agentic memory for LLM agents, 2025
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-MEM: Agentic memory for LLM agents, 2025. URLhttps://arxiv.org/abs/2502.12110
Pith/arXiv arXiv 2025
-
[49]
Ziming You, Yumiao Zhang, Dexuan Xu, Yiwei Lou, Yandong Yan, Wei Wang, Huaming Zhang, and Yu Huang. Datawiseagent: A notebook-centric llm agent framework for adaptive and robust data science automation, 2025. URLhttps://arxiv.org/abs/2503.07044
arXiv 2025
-
[50]
A survey on the memory mechanism of large language model based agents,
Zeyu Zhang, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Quanyu Dai, Jieming Zhu, Zhenhua Dong, and Ji-Rong Wen. A survey on the memory mechanism of large language model based agents,
-
[51]
URLhttps://arxiv.org/abs/2404.13501
-
[52]
You only look at screens: Multimodal chain-of-action agents, June 2024
Zhuosheng Zhang and Aston Zhang. You only look at screens: Multimodal chain-of-action agents, June 2024
2024
-
[53]
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. ExpeL: LLM agents are experiential learners.Proceedings of the AAAI Conference on Artificial Intelligence, 38(17):19632–19642, 2024. doi: 10.1609/aaai.v38i17.29936. URL https: //doi.org/10.1609/aaai.v38i17.29936
-
[54]
Boyuan Zheng, Michael Y . Fatemi, Xiaolong Jin, Zora Zhiruo Wang and Apurva Gandhi, Yueqi Song, Yu Gu, Jayanth Srinivasa, Gaowen Liu, Graham Neubig, and Yu Su. SkillWeaver: Web Agents can Self-Improve by Discovering and Honing Skills, 2025. URL https://arxiv. org/abs/2504.07079
Pith/arXiv arXiv 2025
-
[55]
Synapse: Trajectory-as-exemplar prompting with memory for computer control
Longtao Zheng, Rundong Wang, Xinrun Wang, and Bo An. Synapse: Trajectory-as-exemplar prompting with memory for computer control. InThe Twelfth International Conference on Learning Representations, October 2023
2023
-
[56]
Get name(s) of reviewer(s) who mention {{description}} for the product on the current page,
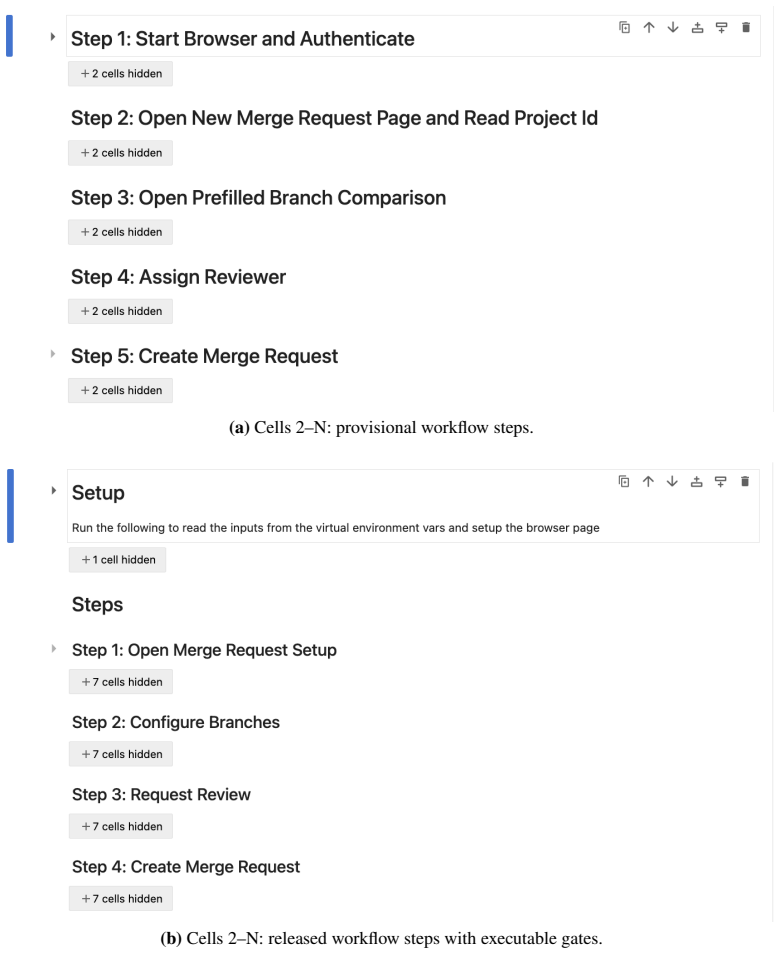
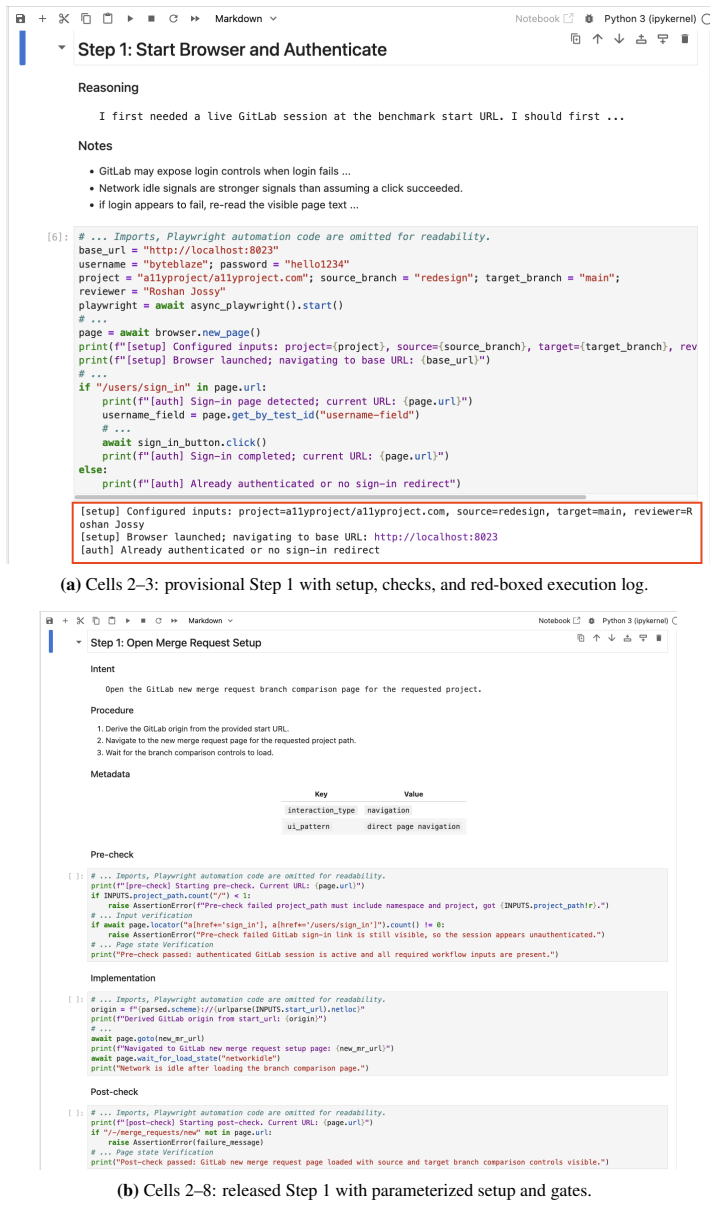
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. MemoryBank: Enhancing large language models with long-term memory.Proceedings of the AAAI Conference on Artificial Intelligence, 38(17):19724–19731, March 2024. ISSN 2374-3468. doi: 10.1609/aaai. v38i17.29946. 13 A Method Details A.1 From Provisional Trace to Released Workflow Artifact (a)Cell...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.