Aligned but Not Partner-Specific: Distinguishing How Multimodal LLM Agents Succeed in Reference Games Without Human-Like Conventions
Pith reviewed 2026-06-27 20:01 UTC · model grok-4.3
The pith
Multimodal LLM agents align on labels in reference games without forming partner-specific conventions like humans.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
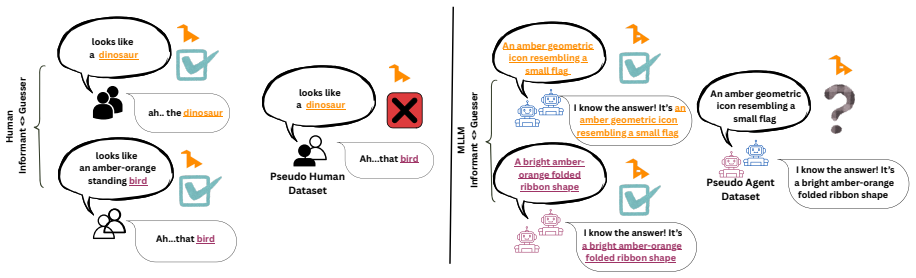
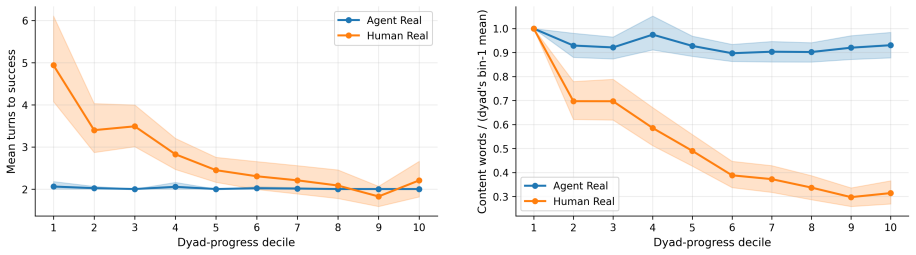
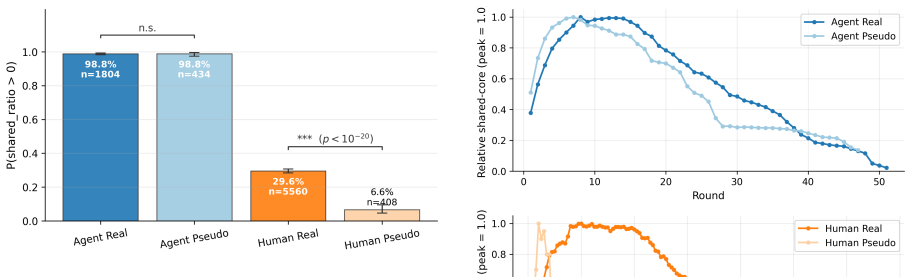
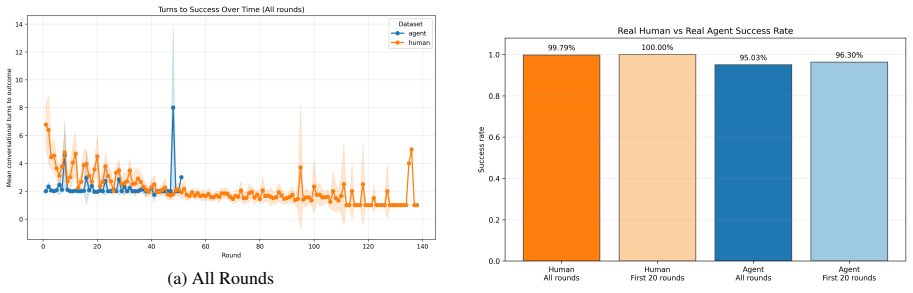
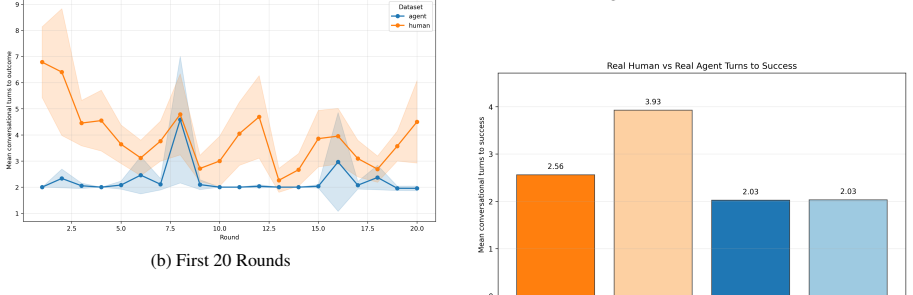
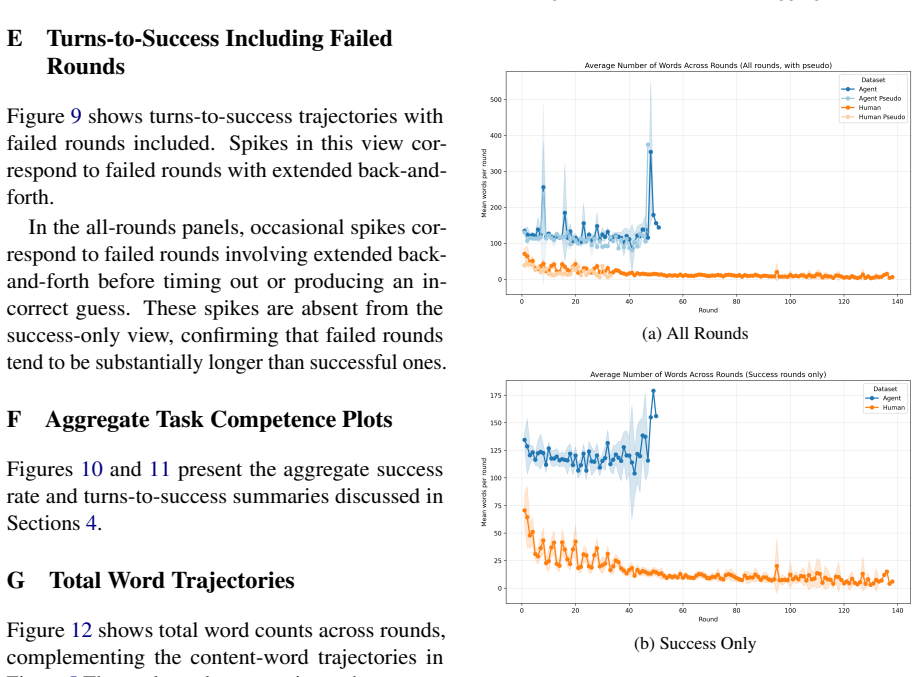
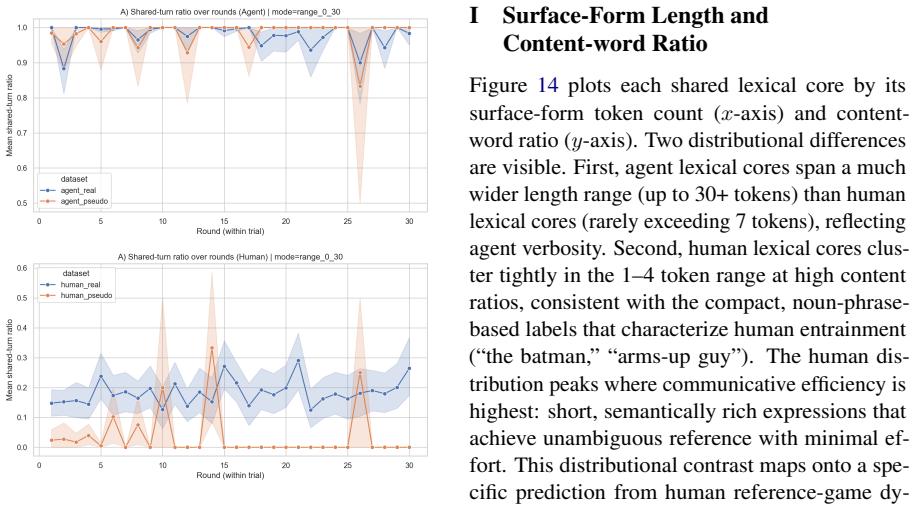
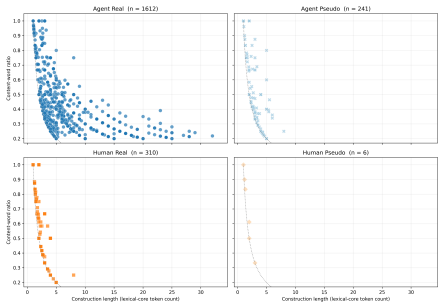
The central claim is that MLLMs succeed in reference games by maintaining verbose descriptions that produce high label alignment, and this alignment does not depend on interaction with a specific partner. The constrained pseudo-dyad baseline shows label overlap remains indistinguishable from real dyads, while humans demonstrably reduce effort and increase entrainment. Thus MLLMs coordinate without convention, relying instead on consistent verbose output rather than history-dependent compression.
What carries the argument
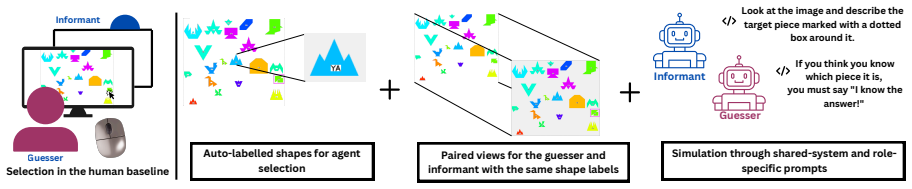
The constrained pseudo-dyad baseline, which matches the referential task structure but breaks partner-specific interaction history.
If this is right
- Humans reduce description length and increase partner-specific label alignment across rounds via entrainment.
- MLLM agents hold effort constant, producing verbose descriptions from round one.
- Agent label alignment stays near ceiling and does not differ between real and pseudo-dyads.
- MLLM coordination therefore occurs without the compact, history-dependent referring expressions seen in humans.
Where Pith is reading between the lines
- The distinction implies that current MLLM training does not induce mechanisms for building compact shared history with a partner.
- The pseudo-dyad method could be extended to test whether alignment in other multimodal tasks also stems from shared vocabulary rather than interaction history.
- If models were given explicit memory of prior partner turns, they might begin to show human-like compression, providing a testable prediction.
- Alignment metrics alone cannot be taken as evidence of grounding when they persist without partner history.
Load-bearing premise
The constrained pseudo-dyad baseline successfully isolates the absence of partner history without changing other task elements or adding confounds.
What would settle it
A finding that MLLM label overlap drops substantially in the pseudo-dyad condition relative to real dyads, while human patterns remain unchanged, would falsify the claim that agent alignment is not partner-specific.
Figures


read the original abstract
Repeated reference games test whether interlocutors replace their initially long descriptions with shorter, partner-specific conventions grounded in shared interaction history. Prior work shows that multimodal LLMs fail to become more efficient across rounds, although they align on the labels they use. How can we determine whether this alignment reflects partner-specific grounding rather than a shared task vocabulary? We address this question by comparing capable multimodal agent dyads with human dyads from the KTH Tangrams corpus. Our novel methodological contribution is a constrained pseudo-dyad baseline that matches the original referential task structure, but breaks partner history. This baseline enables us to test whether the observed label alignment depends on interaction with a specific partner. Across three analytic layers (task competence, description strategy, alignment dynamics), we find clear differences. Humans reduce effort through entrainment, compressing descriptions and increasing label alignment with partners. Agents instead maintain fixed effort levels, producing verbose descriptions from round one, with near-ceiling label overlap that is statistically indistinguishable between real and pseudo dyads. MLLMs thus achieve coordination without convention, succeeding by verbose description rather than by forming the compact, history-dependent referring expressions characteristic of human dialogue.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper compares multimodal LLM agent dyads to human dyads from the KTH Tangrams corpus in repeated reference games. It introduces a constrained pseudo-dyad baseline that preserves referential task structure while breaking partner-specific interaction history. Across task competence, description strategy, and alignment dynamics, the work claims humans reduce effort via entrainment and form compact partner-specific conventions, whereas MLLMs maintain fixed verbose descriptions with near-ceiling label overlap that is statistically indistinguishable between real and pseudo-dyads, indicating coordination without convention.
Significance. If the baseline construction is shown to be free of confounds, the result would provide a clear empirical distinction between human convention formation and MLLM alignment mechanisms, with implications for interactive agent design. The methodological innovation of the pseudo-dyad baseline is a strength if its validity can be demonstrated with quantitative controls.
major comments (2)
- [Abstract / Methods (baseline construction)] The central claim that MLLM label alignment is non-partner-specific rests on the finding of statistically indistinguishable near-ceiling overlap between real dyads and the constrained pseudo-dyad baseline. The abstract asserts that the baseline 'matches the original referential task structure, but breaks partner history,' yet supplies no quantitative verification that description length distributions, lexical diversity, or other generation statistics remain matched, nor any statistical test confirming the absence of new confounds from model-internal priors.
- [Results (alignment dynamics layer)] The three analytic layers (task competence, description strategy, alignment dynamics) are presented as showing clear differences, but without reported effect sizes, exact p-values for the indistinguishability claim, or power analysis for the pseudo-dyad comparison, it is not possible to assess whether the null result on partner-specificity is robust or underpowered.
minor comments (1)
- [Abstract] The abstract refers to 'near-ceiling label overlap' without defining the overlap metric or reporting the precise values for real vs. pseudo conditions.
Simulated Author's Rebuttal
We thank the referee for these detailed comments on the baseline validation and statistical reporting. Both points identify areas where the current manuscript is under-specified, and we will revise accordingly to provide the requested quantitative controls and effect-size reporting. No standing objections remain after these revisions.
read point-by-point responses
-
Referee: [Abstract / Methods (baseline construction)] The central claim that MLLM label alignment is non-partner-specific rests on the finding of statistically indistinguishable near-ceiling overlap between real dyads and the constrained pseudo-dyad baseline. The abstract asserts that the baseline 'matches the original referential task structure, but breaks partner history,' yet supplies no quantitative verification that description length distributions, lexical diversity, or other generation statistics remain matched, nor any statistical test confirming the absence of new confounds from model-internal priors.
Authors: We agree that the manuscript currently lacks explicit quantitative checks confirming that the pseudo-dyad baseline preserves description-length and lexical-diversity distributions. In the revision we will add (i) side-by-side histograms and Kolmogorov-Smirnov tests comparing token length, type-token ratio, and bigram entropy between real and pseudo dyads, and (ii) a table of p-values for these auxiliary statistics. These additions will directly test for the absence of new generation confounds and will be reported in a new subsection of Methods. revision: yes
-
Referee: [Results (alignment dynamics layer)] The three analytic layers (task competence, description strategy, alignment dynamics) are presented as showing clear differences, but without reported effect sizes, exact p-values for the indistinguishability claim, or power analysis for the pseudo-dyad comparison, it is not possible to assess whether the null result on partner-specificity is robust or underpowered.
Authors: We accept that effect sizes, exact p-values, and a power analysis are missing. The revision will report (a) exact two-sided p-values and 95% confidence intervals for all label-overlap comparisons, (b) Cohen’s d (or appropriate non-parametric equivalents) for the real-vs-pseudo contrasts, and (c) a post-hoc power calculation (using the observed variance and sample size) to quantify the sensitivity of the null result. These statistics will be inserted into the Results section and the associated figure captions. revision: yes
Circularity Check
No circularity: empirical comparison with independent baseline
full rationale
The paper is an empirical study that introduces a constrained pseudo-dyad baseline and compares it directly to real dyads from an existing human corpus (KTH Tangrams) and to MLLM agents. No mathematical derivations, fitted parameters renamed as predictions, or self-citation chains are present. The central claim (MLLMs coordinate via verbose description rather than partner-specific conventions) rests on observable differences in effort reduction, label overlap, and alignment dynamics across conditions. The baseline construction is described as a methodological contribution that severs history while preserving task structure; its validity is an empirical question, not a definitional reduction. This matches the default expectation of a non-circular empirical paper.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Statistical tests can reliably detect whether label alignment differs between real and pseudo-dyads.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[2]
2024 , howpublished =
Hello. 2024 , howpublished =
2024
-
[3]
2025 , howpublished =
Introducing. 2025 , howpublished =
2025
-
[4]
Rublee, Ethan and Rabaud, Vincent and Konolige, Kurt and Bradski, Gary , booktitle =
-
[5]
Naval Research Logistics Quarterly , volume=
The Hungarian method for the assignment problem , author=. Naval Research Logistics Quarterly , volume=. 1955 , publisher=
1955
-
[6]
Cognition , volume=
Referring as a collaborative process , author=. Cognition , volume=
-
[7]
Journal of Experimental Psychology: Learning, Memory, and Cognition , volume=
Conceptual pacts and lexical choice in conversation , author=. Journal of Experimental Psychology: Learning, Memory, and Cognition , volume=
-
[8]
Behavioral and Brain Sciences , volume=
Toward a mechanistic psychology of dialogue , author=. Behavioral and Brain Sciences , volume=
-
[9]
Contexts of Accommodation , editor=
Accommodation theory: Communication, context, and consequence , author=. Contexts of Accommodation , editor=. 1991 , publisher=
1991
-
[10]
Language Sciences , volume =
Communication Accommodation Theory: Past Accomplishments, Current Trends, and Future Prospects , author =. Language Sciences , volume =. 2023 , doi =
2023
-
[11]
Talk Less, Interact Better: Evaluating In-context Conversational Adaptation in Multimodal
Hua, Yilun and Artzi, Yoav , booktitle =. Talk Less, Interact Better: Evaluating In-context Conversational Adaptation in Multimodal. 2024 , url =
2024
-
[12]
arXiv preprint arXiv:2510.24023 , year =
Success and Cost Elicit Convention Formation for Efficient Communication , author =. arXiv preprint arXiv:2510.24023 , year =
-
[13]
Cognitive Science , volume=
Characterizing the dynamics of learning in repeated reference games , author=. Cognitive Science , volume=
-
[14]
and Franke, Michael and Frank, Michael C
Hawkins, Robert D. and Franke, Michael and Frank, Michael C. and Goldberg, Adele E. and Smith, Kenny and Griffiths, Thomas L. and Goodman, Noah D. , journal=. From partners to populations: A hierarchical
-
[15]
1996 , publisher=
Using Language , author=. 1996 , publisher=
1996
-
[16]
2018 , address=
Shore, Todd and Androulakaki, Theofronia and Skantze, Gabriel , booktitle=. 2018 , address=
2018
-
[17]
Cognitive Science , volume=
Can large language models simulate spoken human conversations? , author=. Cognitive Science , volume=
-
[18]
Proceedings of NAACL 2024 , pages=
Grounding gaps in language model generations , author=. Proceedings of NAACL 2024 , pages=
2024
-
[19]
arXiv preprint arXiv:2404.02039 , year =
A Survey on Large Language Model-Based Game Agents , author =. arXiv preprint arXiv:2404.02039 , year =
-
[20]
Chen, Weize and Su, Yusheng and Zuo, Jingwei and Yang, Cheng and Yuan, Chenfei and Chan, Chi-Min and Yu, Heyang and Lu, Yaxi and Hung, Yi-Hsin and Qian, Chen and Qin, Yujia and Cong, Xin and Xie, Ruobing and Liu, Zhiyuan and Sun, Maosong and Zhou, Jie , booktitle=
-
[21]
2026 , url =
Zeng, Peter and Li, Weiling and Paige, Amie and Wang, Zhengxiang and Kaliosis, Panagiotis and Samaras, Dimitris and Zelinsky, Gregory and Brennan, Susan and Rambow, Owen , journal =. 2026 , url =
2026
-
[22]
and Alikhani, Malihe , booktitle =
Imai, Saki and Inan, Mert and Sicilia, Anthony B. and Alikhani, Malihe , booktitle =. Measuring How (Not Just Whether). 2025 , url =
2025
-
[23]
Evaluating Behavioral Alignment in Conflict Dialogue: A Multi-Dimensional Comparison of
Kwon, Deuksin and Shrestha, Kaleen and Han, Bin and Lee, Elena Hayoung and Lucas, Gale , booktitle =. Evaluating Behavioral Alignment in Conflict Dialogue: A Multi-Dimensional Comparison of. 2025 , doi =
2025
-
[24]
2025 , doi =
Wang, Zhengxiang and Li, Weiling and Kaliosis, Panagiotis and Rambow, Owen and Brennan, Susan , booktitle =. 2025 , doi =
2025
-
[25]
LEEET s-Dial: Linguistic Entrainment in End-to-End Task-oriented Dialogue systems
Kumar, Nalin and Dusek, Ondrej. LEEET s-Dial: Linguistic Entrainment in End-to-End Task-oriented Dialogue systems. Findings of the Association for Computational Linguistics: NAACL 2024. 2024. doi:10.18653/v1/2024.findings-naacl.46
-
[26]
Nature Human Behaviour , volume=
Playing repeated games with large language models , author=. Nature Human Behaviour , volume=
-
[27]
and Onizuka, Makoto and Tang, Shaojie and Xiao, Chuan , booktitle =
Wu, Zengqing and Peng, Run and Zheng, Shuyuan and Liu, Qianying and Han, Xu and Kwon, Brian I. and Onizuka, Makoto and Tang, Shaojie and Xiao, Chuan , booktitle =. Shall We Team Up: Exploring Spontaneous Cooperation of Competing. 2024 , doi =
2024
-
[28]
arXiv preprint arXiv:2509.05882 , year=
Collaborate, Deliberate, Evaluate: How LLM Alignment Affects Coordinated Multi-Agent Outcomes , author=. arXiv preprint arXiv:2509.05882 , year=
-
[29]
arXiv preprint arXiv:1605.07133 , year=
Towards multi-agent communication-based language learning , author=. arXiv preprint arXiv:1605.07133 , year=
-
[30]
arXiv preprint arXiv:2006.02419 , year=
Emergent multi-agent communication in the deep learning era , author=. arXiv preprint arXiv:2006.02419 , year=
arXiv 2006
-
[31]
arXiv preprint arXiv:2507.08610 , year =
Emergent Natural Language with Communication Games for Improving Image Captioning Capabilities without Additional Data , author =. arXiv preprint arXiv:2507.08610 , year =
-
[32]
Computer Speech and Language , volume=
Measuring and implementing lexical alignment: A systematic literature review , author=. Computer Speech and Language , volume=
-
[33]
PLoS ONE , volume=
Divergence in dialogue , author=. PLoS ONE , volume=
-
[34]
, booktitle =
Doyle, Gabriel and Yurovsky, Daniel and Frank, Michael C. , booktitle =. A Robust Framework for Estimating Linguistic Alignment in. 2016 , doi =
2016
-
[35]
and Paxton, Alexandra and Fusaroli, Riccardo , journal=
Duran, Nicholas D. and Paxton, Alexandra and Fusaroli, Riccardo , journal=
-
[36]
Linguistics Vanguard , volume=
Efficiency in human languages: Corpus evidence for universal principles , author=. Linguistics Vanguard , volume=
-
[37]
2022 , publisher=
Communicative Efficiency: Language Structure and Use , author=. 2022 , publisher=
2022
-
[38]
Proceedings of the Annual Meeting of the Cognitive Science Society , volume =
Analysing Cross-Speaker Convergence in Face-to-Face Dialogue through the Lens of Automatically Detected Shared Linguistic Constructions , author =. Proceedings of the Annual Meeting of the Cognitive Science Society , volume =. 2024 , url =
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.