ConSteer-RL: Steering Reasoning Capabilities in Large Language Models via Confidence-Aware Reinforcement Learning
Pith reviewed 2026-06-27 19:54 UTC · model grok-4.3
The pith
ConSteer-RL adds model confidence signals to reward shaping in RL training to improve LLM reasoning performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
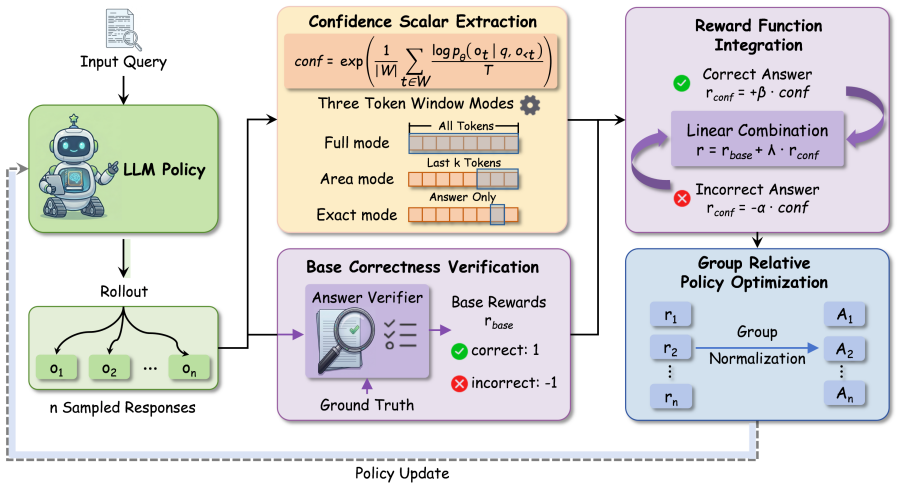
Building on GRPO, ConSteer-RL aggregates per-token probabilities into a scalar confidence score and folds it into reward shaping that penalizes overconfident errors while reinforcing correct and confident reasoning, yielding consistent gains over baseline GRPO training.
What carries the argument
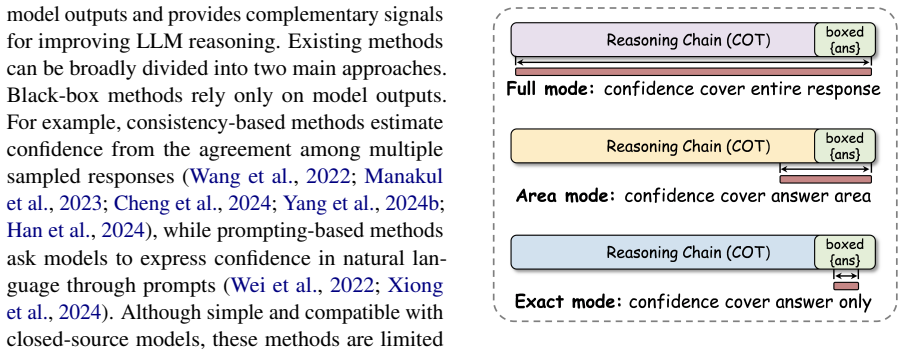
The confidence-aware reward shaping mechanism that turns per-token log-probabilities into a scalar score for penalizing overconfident errors and reinforcing confident correct outputs.
If this is right
- The method produces 2.3% to 4.0% average gains over GRPO baselines across different model scales.
- The same confidence integration can be applied to other RLVR setups that currently rely on sparse binary rewards.
- Training becomes sensitive to internal model uncertainty rather than treating all correct answers equally.
- Overconfident errors receive explicit negative shaping during policy updates.
Where Pith is reading between the lines
- The approach could be tested on tasks where overconfidence leads to cascading errors, such as multi-step planning.
- If the scalar score works, similar aggregation might help in other uncertainty-aware training regimes beyond reasoning.
- Future work could measure whether the gains persist when the base model is already well-calibrated.
Load-bearing premise
Aggregating per-token log-probabilities into one scalar confidence score produces a usable reward signal that does not create training instability or offsetting biases.
What would settle it
Training a model with ConSteer-RL on a standard reasoning benchmark and observing no improvement or a performance drop relative to plain GRPO would falsify the central claim.
Figures






read the original abstract
Reinforcement Learning from Verifiable Rewards (RLVR) has recently become a key paradigm for improving the reasoning abilities of Large Language Models (LLMs), yet it remains limited by sparse binary rewards and its ignorance of model-internal uncertainty. In this paper, we propose ConSteer-RL, a simple yet effective framework that integrates token-level confidence signals derived from model log-probabilities into RLVR training. Specifically, building upon the Group Relative Policy Optimization (GRPO) framework, we construct a confidence-aware reward by aggregating per-token probabilities into a scalar confidence score and incorporating it into an awareness-based reward shaping mechanism that penalizes overconfident errors while reinforcing correct and confident reasoning. Experimental results demonstrate that ConSteer-RL consistently outperforms strong GRPO baselines, achieving average improvements of 2.3%-4.0% across different model scales.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ConSteer-RL, an extension to Group Relative Policy Optimization (GRPO) within Reinforcement Learning from Verifiable Rewards (RLVR). It derives a scalar confidence score by aggregating per-token log-probabilities and incorporates this into an awareness-based reward shaping mechanism that penalizes overconfident errors while reinforcing confident correct paths. The central claim is that this yields consistent average improvements of 2.3%-4.0% over strong GRPO baselines across different model scales.
Significance. If validated with rigorous experiments, the approach offers a lightweight way to leverage model-internal uncertainty for reward shaping without new parameters or external supervision. This could improve reasoning reliability in LLMs under the RLVR paradigm. The construction appears non-circular and avoids obvious self-referential definitions.
major comments (2)
- [Abstract] Abstract: the central empirical claim of 2.3%-4.0% average improvements is asserted without any description of experimental setup, benchmarks, model scales, baselines, number of runs, statistical tests, ablation studies, or error bars. This directly undermines verification of the performance claim.
- [Abstract] Abstract: the aggregation of per-token log-probabilities into the scalar confidence score and its precise insertion into the reward function (e.g., the functional form of the awareness-based shaping) are described only at a high level. Without the explicit formula, it is impossible to assess whether the construction introduces instability or offsetting biases, which is load-bearing for the method's validity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment point by point below and will revise the abstract accordingly in the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim of 2.3%-4.0% average improvements is asserted without any description of experimental setup, benchmarks, model scales, baselines, number of runs, statistical tests, ablation studies, or error bars. This directly undermines verification of the performance claim.
Authors: We agree that the abstract is high-level and would benefit from additional context to support the reported gains. In the revised manuscript, we will expand the abstract to briefly note the benchmarks (mathematical reasoning tasks), model scales tested, GRPO baselines, and that results include multiple runs with error bars and ablations as detailed in Sections 4 and 5. revision: yes
-
Referee: [Abstract] Abstract: the aggregation of per-token log-probabilities into the scalar confidence score and its precise insertion into the reward function (e.g., the functional form of the awareness-based shaping) are described only at a high level. Without the explicit formula, it is impossible to assess whether the construction introduces instability or offsetting biases, which is load-bearing for the method's validity.
Authors: We agree that the abstract's description is high-level. The explicit formulas for the per-token aggregation into the scalar confidence score and its incorporation into the awareness-based reward shaping are given in Section 3 (Equations 2 and 3). We will revise the abstract to include a concise statement of the functional forms or direct equation references so that potential issues such as instability or bias can be assessed without consulting the body text. revision: yes
Circularity Check
No significant circularity
full rationale
The paper extends the existing GRPO framework by constructing a reward term from per-token log-probabilities already produced by the model during training. This is a direct, non-circular use of model outputs for shaping, not a self-definition, fitted-input prediction, or self-citation chain that forces the result. The central claim consists of empirical accuracy gains on external benchmarks; no equation or premise reduces by construction to the inputs or to prior work by the same authors. The derivation remains self-contained against external evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Reinforcement learning for reasoning in large language models with one training example , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
arXiv preprint arXiv:2504.11456 , year=
Deepmath-103k: A large-scale, challenging, decontaminated, and verifiable mathematical dataset for advancing reasoning , author=. arXiv preprint arXiv:2504.11456 , year=
-
[3]
arXiv preprint arXiv:2503.18470 , volume=
Code-r1: Reproducing r1 for code with reliable rewards , author=. arXiv preprint arXiv:2503.18470 , volume=
-
[4]
arXiv preprint arXiv:2510.18471 , year=
CodeRL+: Improving Code Generation via Reinforcement with Execution Semantics Alignment , author=. arXiv preprint arXiv:2510.18471 , year=
-
[5]
arXiv preprint arXiv:2601.18533 , year=
From Verifiable Dot to Reward Chain: Harnessing Verifiable Reference-based Rewards for Reinforcement Learning of Open-ended Generation , author=. arXiv preprint arXiv:2601.18533 , year=
-
[6]
arXiv preprint arXiv:2601.18207 , year=
PaperSearchQA: Learning to Search and Reason over Scientific Papers with RLVR , author=. arXiv preprint arXiv:2601.18207 , year=
-
[7]
arXiv preprint arXiv:2501.12948 , year=
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
-
[8]
arXiv preprint arXiv:2601.03525 , year=
VeRPO: Verifiable Dense Reward Policy Optimization for Code Generation , author=. arXiv preprint arXiv:2601.03525 , year=
-
[9]
arXiv preprint arXiv:2601.18984 , year=
Save the Good Prefix: Precise Error Penalization via Process-Supervised RL to Enhance LLM Reasoning , author=. arXiv preprint arXiv:2601.18984 , year=
-
[10]
arXiv preprint arXiv:2402.13213 , year=
Probabilities of chat llms are miscalibrated but still predict correctness on multiple-choice q&a , author=. arXiv preprint arXiv:2402.13213 , year=
-
[11]
Advances in Neural Information Processing Systems , volume=
Calibrating translation decoding with quality estimation on llms , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Calibrating language models with adaptive temperature scaling , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[13]
arXiv preprint arXiv:2203.11171 , year=
Self-consistency improves chain of thought reasoning in language models , author=. arXiv preprint arXiv:2203.11171 , year=
-
[14]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[15]
arXiv preprint arXiv:2401.13275 , year=
Can AI assistants know what they don't know? , author=. arXiv preprint arXiv:2401.13275 , year=
-
[16]
Advances in Neural Information Processing Systems , volume=
Alignment for honesty , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
arXiv preprint arXiv:2404.10315 , year=
Enhancing confidence expression in large language models through learning from past experience , author=. arXiv preprint arXiv:2404.10315 , year=
-
[18]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[19]
International Conference on Learning Representations , volume=
Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms , author=. International Conference on Learning Representations , volume=
-
[20]
Findings of the Association for Computational Linguistics: ACL 2024 , year=
Findings of the Association for Computational Linguistics: ACL 2024 , author=. Findings of the Association for Computational Linguistics: ACL 2024 , year=
2024
-
[21]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Towards mitigating LLM hallucination via self reflection , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[22]
arXiv preprint arXiv:2503.02623 , year=
Rewarding doubt: A reinforcement learning approach to calibrated confidence expression of large language models , author=. arXiv preprint arXiv:2503.02623 , year=
-
[23]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Beyond Correctness: Confidence-Aware Reward Modeling for Enhancing Large Language Model Reasoning , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[24]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
The internal state of an LLM knows when it’s lying , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[25]
arXiv preprint arXiv:2302.09664 , year=
Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation , author=. arXiv preprint arXiv:2302.09664 , year=
-
[26]
arXiv preprint arXiv:2307.10236 , year=
Look before you leap: An exploratory study of uncertainty measurement for large language models , author=. arXiv preprint arXiv:2307.10236 , year=
-
[27]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Shifting attention to relevance: Towards the predictive uncertainty quantification of free-form large language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[28]
arXiv preprint arXiv:2508.15260 , year=
Deep think with confidence , author=. arXiv preprint arXiv:2508.15260 , year=
-
[29]
arXiv preprint arXiv:2601.20614 , year=
Harder Is Better: Boosting Mathematical Reasoning via Difficulty-Aware GRPO and Multi-Aspect Question Reformulation , author=. arXiv preprint arXiv:2601.20614 , year=
-
[30]
arXiv preprint arXiv:2503.20783 , year=
Understanding r1-zero-like training: A critical perspective , author=. arXiv preprint arXiv:2503.20783 , year=
-
[31]
Advances in Neural Information Processing Systems , volume=
Dapo: An open-source llm reinforcement learning system at scale , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
arXiv preprint arXiv:2507.18071 , year=
Group sequence policy optimization , author=. arXiv preprint arXiv:2507.18071 , year=
-
[33]
arXiv preprint arXiv:2511.20347 , year=
Soft adaptive policy optimization , author=. arXiv preprint arXiv:2511.20347 , year=
-
[34]
arXiv preprint arXiv:2601.05242 , year=
Gdpo: Group reward-decoupled normalization policy optimization for multi-reward rl optimization , author=. arXiv preprint arXiv:2601.05242 , year=
-
[35]
arXiv preprint arXiv:1707.06347 , year=
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
-
[36]
Dapo: An open-source llm reinforcement learning system at scale, 2025 , author=. URL https://arxiv. org/abs/2503.14476 , volume=
Pith/arXiv arXiv 2025
-
[37]
Proceedings of the Twentieth European Conference on Computer Systems , pages=
Hybridflow: A flexible and efficient rlhf framework , author=. Proceedings of the Twentieth European Conference on Computer Systems , pages=
-
[38]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[39]
5-math technical report: Toward mathematical expert model via self-improvement , author=
Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement , author=. arXiv preprint arXiv:2409.12122 , year=
-
[40]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[41]
arXiv preprint arXiv:2009.03300 , year=
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
Pith/arXiv arXiv 2009
-
[42]
Advances in neural information processing systems , volume=
Solving quantitative reasoning problems with language models , author=. Advances in neural information processing systems , volume=
-
[43]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[44]
arXiv preprint arXiv:2503.18892 , year=
Simplerl-zoo: Investigating and taming zero reinforcement learning for open base models in the wild , author=. arXiv preprint arXiv:2503.18892 , year=
-
[45]
arXiv preprint arXiv:2503.17736 , year=
V2p-bench: Evaluating video-language understanding with visual prompts for better human-model interaction , author=. arXiv preprint arXiv:2503.17736 , year=
-
[46]
arXiv preprint arXiv:2504.07956 , year=
Vcr-bench: A comprehensive evaluation framework for video chain-of-thought reasoning , author=. arXiv preprint arXiv:2504.07956 , year=
-
[47]
arXiv preprint arXiv:2602.02185 , year=
Vision-deepresearch benchmark: Rethinking visual and textual search for multimodal large language models , author=. arXiv preprint arXiv:2602.02185 , year=
-
[48]
arXiv preprint arXiv:2510.01304 , year=
Agentic Jigsaw Interaction Learning for Enhancing Visual Perception and Reasoning in Vision-Language Models , author=. arXiv preprint arXiv:2510.01304 , year=
-
[49]
arXiv preprint arXiv:2605.16079 , year=
VideoSeeker: Incentivizing Instance-level Video Understanding via Native Agentic Tool Invocation , author=. arXiv preprint arXiv:2605.16079 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.