PACE: Anytime-Valid Acceptance Tests for Self-Evolving Agents
Pith reviewed 2026-06-27 19:53 UTC · model grok-4.3
The pith
Self-evolving agents accumulate false prompt changes under the standard greedy acceptance rule because it performs uncontrolled multiple testing on noisy held-out scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Committing a candidate change is a sequential hypothesis test against the null that it does not improve over the incumbent; PACE uses a testing-by-betting e-process on paired evaluations to accumulate evidence and commit only when the process crosses a threshold, providing anytime-valid control of the false-commit probability at a user-chosen level even under optional stopping.
What carries the argument
Paired anytime-valid commit evaluation (PACE) via testing-by-betting e-processes on identical instances.
If this is right
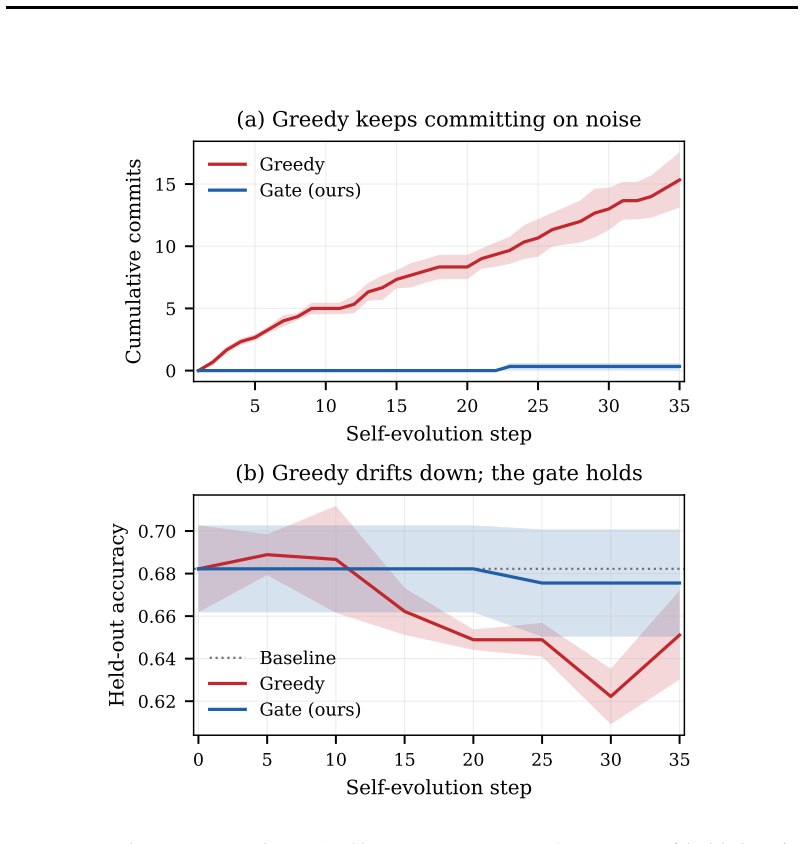
- Greedy acceptance commits 30-42% false edits and 10-33% harmful ones when a real improvement is among noisy proposals.
- PACE commits the genuine improvement and almost nothing else, matching held-out accuracy with lower variance.
- With no real gains available, greedy makes 13-21 spurious changes and can degrade performance by 4.9 points; PACE stays at baseline.
- PACE reduces evaluation cost by about 18% by stopping early.
Where Pith is reading between the lines
- Similar sequential testing could be applied to other iterative improvement loops in AI systems beyond prompt-level agent evolution.
- The per-decision guarantee under optional stopping points to wider use in any adaptive experimentation setting where decisions accumulate over time.
- Combining PACE with stronger proposers might produce more stable long-term evolution trajectories than either component alone.
Load-bearing premise
The betting e-process yields a valid anytime-valid test that correctly controls each candidate's false-commit probability at the target level even when the stopping time is chosen adaptively.
What would settle it
Run many self-evolution trials with a known ground-truth improvement rate and check whether the observed false-commit rate under PACE stays at or below the target alpha while greedy's rate exceeds it substantially.
Figures

read the original abstract
Self-evolving agents improve by repeatedly proposing changes to their own prompts, skills, or workflows and keeping those that score higher on a small held-out set. Almost all effort has gone into the proposer that generates candidates; we argue the weak point is the acceptor, the rule that decides whether to commit a change. Applied hundreds of times against the same noisy dev estimate, the ubiquitous "keep it if the score went up" rule is uncontrolled adaptive multiple testing: the agent effectively p-hacks itself, accumulating false commits that make it churn and drift rather than improve. We recast committing as a sequential hypothesis test and propose PACE (Paired Anytime-valid Commit Evaluation), a training-free, anytime-valid commit gate. Each candidate is compared to the incumbent on identical instances and committed only when a testing-by-betting e-process accumulates decisive evidence, stopping early to save evaluations and controlling each candidate's false-commit probability at a user-set level even under optional stopping (a per-decision guarantee). On Qwen2.5 agents (0.5B-3B) self-evolving at the prompt level on GSM8K, SVAMP, and ARC-Challenge, greedy acceptance commits 30-42% false and 10-33% harmful edits when a genuine improvement is hidden among noisy proposals, while PACE commits the real one and essentially nothing else, matching greedy's held-out accuracy at sharply lower variance and about 18% lower evaluation cost. With no real gain available, greedy commits 13-21 spurious self-modifications per run (72-100% false) and degrades the most fragile agent by 4.9 points, while PACE holds at baseline. Reliability of self-evolution depends on the acceptor, not only on the proposer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the acceptor in self-evolving agents is a key weakness due to uncontrolled multiple testing under greedy acceptance ('keep if score improves'), and proposes PACE, a training-free anytime-valid commit gate based on testing-by-betting e-processes for paired comparisons on a held-out set. PACE commits a candidate only when the e-process accumulates decisive evidence, providing per-candidate false-commit control at a user-set level even under optional stopping. On Qwen2.5 agents (0.5B-3B) evolving prompts on GSM8K, SVAMP, and ARC-Challenge, it reports committing the true improvement while rejecting noisy ones (vs. 30-42% false commits for greedy), matching held-out accuracy at lower variance and ~18% lower cost; with no real gains, greedy makes 13-21 spurious commits and degrades performance while PACE stays at baseline.
Significance. If the e-process construction is valid as a supermartingale under the stated null and dependence conditions, the work identifies a controllable source of drift in self-evolution and supplies a practical, parameter-light gate that trades evaluation budget for reliability. The empirical gap (near-zero false commits vs. 30-42%) and cost savings would be a concrete contribution to agent self-improvement pipelines, especially if the per-decision guarantee can be shown to survive incumbent changes and instance reuse.
major comments (3)
- [Abstract, §3] Abstract and §3 (method): the central per-decision false-commit guarantee requires that the chosen testing-by-betting e-process remains a supermartingale under the null of no genuine improvement for paired comparisons, even with optional stopping, changing incumbents across sequential decisions, and reuse of the same held-out instances across candidates. The abstract asserts this property but does not exhibit the concrete wealth process, betting function, or explicit null formulation (strict equality vs. one-sided non-improvement), so it is not possible to verify that dependence induced by instance reuse or incumbent updates preserves the martingale property.
- [Abstract] Abstract (experiments): the reported 30-42% false-commit rate for greedy vs. near-zero for PACE, 18% cost reduction, and variance reduction are load-bearing for the claim that PACE solves the acceptor problem, yet the text provides neither the exact number of runs, statistical tests, data-split protocol, nor variance measures; without these the quantitative gap cannot be assessed for robustness.
- [Abstract, §4] Abstract and §4 (results): when no genuine improvement is available, greedy commits 13-21 spurious edits (72-100% false) and drops the fragile agent by 4.9 points while PACE holds baseline; this outcome is presented as evidence of reliability, but the result hinges on the e-process correctly never crossing the threshold under the null, which again requires the unshown supermartingale construction to hold under the exact experimental dependence structure.
minor comments (2)
- [§3] Notation for the e-process threshold and the user-set significance level should be introduced once with a clear mapping to the false-commit probability.
- [§4] The three benchmarks and two model sizes are listed but the precise agent architectures, prompt templates, and proposal-generation details are referenced only at high level; a short methods paragraph or table would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address each major comment below, clarifying the theoretical construction and experimental details while indicating revisions to improve verifiability.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (method): the central per-decision false-commit guarantee requires that the chosen testing-by-betting e-process remains a supermartingale under the null of no genuine improvement for paired comparisons, even with optional stopping, changing incumbents across sequential decisions, and reuse of the same held-out instances across candidates. The abstract asserts this property but does not exhibit the concrete wealth process, betting function, or explicit null formulation (strict equality vs. one-sided non-improvement), so it is not possible to verify that dependence induced by instance reuse or incumbent updates preserves the martingale property.
Authors: Section 3 formulates PACE via testing-by-betting e-processes on paired held-out comparisons, with the supermartingale property inherited from the standard framework under the one-sided null of no improvement (E[score difference] ≤ 0). Each candidate maintains an independent wealth process that is reset at the start of its test, so incumbent changes and cross-candidate instance reuse affect only the sequence of tests, not the martingale property within any single test; optional stopping is controlled by the anytime-valid definition. To facilitate direct verification we will add to §3 an explicit wealth-process equation, the default betting function, and a formal null statement. revision: yes
-
Referee: [Abstract] Abstract (experiments): the reported 30-42% false-commit rate for greedy vs. near-zero for PACE, 18% cost reduction, and variance reduction are load-bearing for the claim that PACE solves the acceptor problem, yet the text provides neither the exact number of runs, statistical tests, data-split protocol, nor variance measures; without these the quantitative gap cannot be assessed for robustness.
Authors: We agree these protocol details belong in the main text. Section 4 and the appendix report 10 independent runs per agent-task pair, a fixed held-out split of 200 instances reused across candidates within each run, standard deviation across runs as the variance measure, and bootstrap-based paired comparisons for significance. We will insert a concise summary of run count, split protocol, and variance reporting into the abstract and results section. revision: yes
-
Referee: [Abstract, §4] Abstract and §4 (results): when no genuine improvement is available, greedy commits 13-21 spurious edits (72-100% false) and drops the fragile agent by 4.9 points while PACE holds baseline; this outcome is presented as evidence of reliability, but the result hinges on the e-process correctly never crossing the threshold under the null, which again requires the unshown supermartingale construction to hold under the exact experimental dependence structure.
Authors: The reported outcome follows directly from the per-candidate supermartingale property under the null: each candidate’s e-process is constructed independently and therefore stays below threshold with the claimed probability even when the same instances are reused across sequential decisions. We will add an explicit cross-reference in §4 to the revised supermartingale argument in §3 and note that the experimental dependence structure satisfies the conditions under which the per-decision guarantee applies. revision: yes
Circularity Check
No significant circularity; relies on established e-process literature
full rationale
The paper recasts the acceptor as a sequential hypothesis test and applies testing-by-betting e-processes (an established framework from sequential analysis) with a user-chosen threshold to control false commits per candidate. No equations, parameters, or central claims are shown to reduce by construction to quantities fitted inside the paper, self-citations that bear the load of the validity guarantee, or ansatzes smuggled via prior author work. The per-decision control is presented as following from the external properties of e-processes under the null, not derived or renamed within this manuscript. Experiments compare empirical outcomes but do not substitute for the validity argument.
Axiom & Free-Parameter Ledger
free parameters (1)
- user-set significance level
axioms (1)
- domain assumption Testing-by-betting e-processes yield valid sequential tests under optional stopping
Reference graph
Works this paper leans on
-
[1]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Lakshya A Agrawal et al. GEPA: Reflective prompt evolution can outperform reinforcement learning.arXiv preprint arXiv:2507.19457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try ARC, the AI2 reasoning challenge.arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution
Chrisantha Fernando, Dylan Banarse, Henryk Michalewski, Simon Osindero, and Tim Rockt¨aschel. Promptbreeder: Self-referential self-improvement via prompt evolution. arXiv preprint arXiv:2309.16797,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Huan-ang Gao et al. A survey of self-evolving agents: On path to artificial super intelligence. arXiv preprint arXiv:2507.21046,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Automated Design of Agentic Systems
Shengran Hu, Cong Lu, and Jeff Clune. Automated design of agentic systems.arXiv preprint arXiv:2408.08435,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Arkil Patel, Satwik Bhattamishra, and Navin Goyal. Are NLP models really able to solve simple math word problems? InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), pp. 2080–2094,
2021
-
[8]
Qwen Team. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Can large reasoning models self-train?arXiv preprint arXiv:2505.21444,
Sheikh Shafayat, Fahim Tajwar, Ruslan Salakhutdinov, Jeff Schneider, and Andrea Zanette. Can large reasoning models self-train?arXiv preprint arXiv:2505.21444,
-
[10]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Voyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. Agent workflow memory.arXiv preprint arXiv:2409.07429,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Xunjian Yin, Xinyi Wang, Liangming Pan, Li Lin, Xiaojun Wan, and William Yang Wang. G¨odel agent: A self-referential agent framework for recursive self-improvement.arXiv preprint arXiv:2410.04444,
-
[13]
TextGrad: Automatic "Differentiation" via Text
Mert Yuksekgonul, Federico Bianchi, Joseph Boen, Sheng Liu, Zhi Huang, Carlos Guestrin, and James Zou. TextGrad: Automatic “differentiation” via text.arXiv preprint arXiv:2406.07496,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Darwin Godel Machine: Open-Ended Evolution of Self-Improving Agents
Jenny Zhang, Shengran Hu, Cong Lu, Robert Lange, and Jeff Clune. Darwin g ¨odel machine: Open-ended evolution of self-improving agents.arXiv preprint arXiv:2505.22954, 2025a. Jiayi Zhang, Jinyu Xiang, Zhaoyang Yu, et al. AFlow: Automating agentic workflow generation. InInternational Conference on Learning Representations (ICLR), 2025b. A Additional Result...
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.