LogNEO: A GPT-Neo Reinforcement Learning Framework for Accurate Real-Time Log Anomaly Detection
Pith reviewed 2026-06-27 20:25 UTC · model grok-4.3
The pith
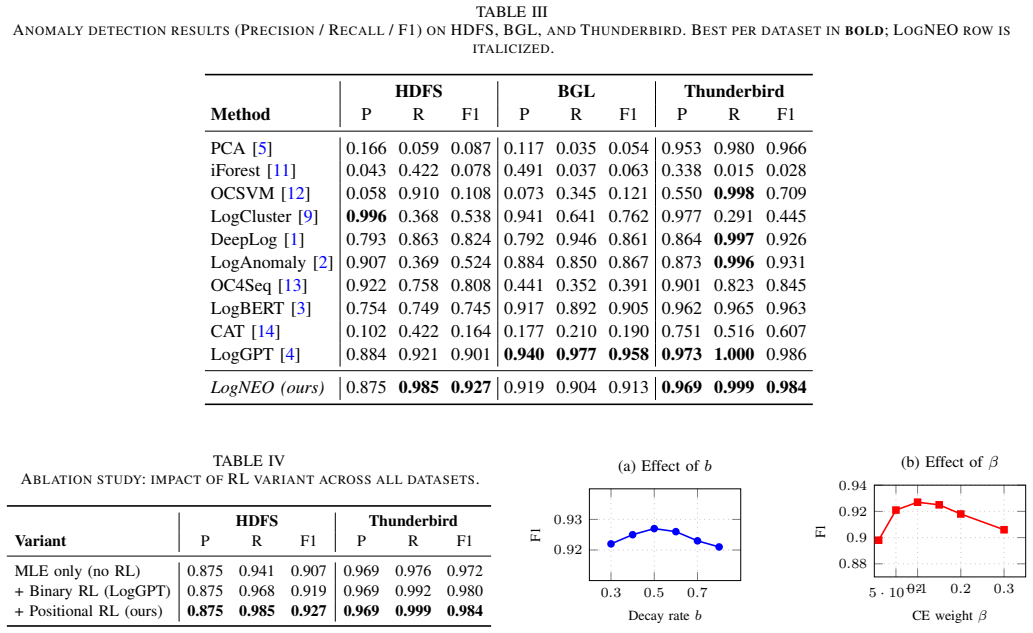
A position-aware reward in reinforcement learning fine-tunes GPT-Neo to raise recall in log anomaly detection while supporting real-time throughput.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LogNEO shows that fine-tuning GPT-Neo with a partial-credit, exponentially decaying position-aware reward plus cross-entropy regularisation via PPO produces higher recall on HDFS, BGL and Thunderbird log anomaly benchmarks than prior language-model approaches, while the resulting model meets the latency and throughput requirements of a live microservice deployment.
What carries the argument
The partial-credit, exponentially decaying position-aware reward scheme combined with cross-entropy regularisation inside Proximal Policy Optimisation (PPO) applied to GPT-Neo.
If this is right
- Higher recall reduces the fraction of missed anomalies that could lead to outages or security breaches.
- Comparable precision keeps the volume of false alerts from overwhelming operators.
- Sub-50 ms latency at 15 k events per second allows the detector to be inserted directly into existing log pipelines without buffering delays.
- The same fine-tuning recipe could be applied to other autoregressive models of similar size.
Where Pith is reading between the lines
- The position-aware reward might transfer to other sequence-labeling tasks where early tokens are easier to predict than later ones.
- Production teams could test whether the same latency numbers hold when the model is quantized further or run on different accelerators.
- If the reward scheme proves robust, it offers a way to adapt large language models to domain-specific anomaly tasks without full retraining from scratch.
Load-bearing premise
The reported accuracy gains are caused mainly by the new reward function rather than by dataset preprocessing, hyper-parameter choices, or benchmark-specific tuning.
What would settle it
An ablation that trains the identical GPT-Neo model on the same data with ordinary next-token rewards instead of the position-aware scheme and still matches or exceeds the published F1 scores.
Figures


read the original abstract
Detecting anomalies in large-scale system logs is critical for the reliability and security of modern computing infrastructure. We present LogNEO, a log anomaly detector built on EleutherAI's GPT-Neo (1.3B parameters) and fine-tuned with a novel partial-credit, exponentially decaying position-aware reward scheme combined with cross-entropy regularisation via Proximal Policy Optimisation (PPO). The position-aware reward explicitly models prediction difficulty: early positions receive higher rewards for correct predictions, while later positions incur stronger penalties for errors. LogNEO attains F1-scores of 0.927, 0.913, and 0.984 on the HDFS, BGL, and Thunderbird benchmarks, improving recall by up to 6 percentage points over the prior state-of-the-art LogGPT while maintaining comparable precision. A production microservice deployment over Apache Kafka, Redis, and TensorRT-accelerated inference demonstrates 45 ms end-to-end latency at 15,000 events per second.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LogNEO, a log anomaly detector that fine-tunes EleutherAI's GPT-Neo (1.3B parameters) via Proximal Policy Optimization (PPO) using a novel partial-credit, exponentially decaying position-aware reward scheme combined with cross-entropy regularisation. It reports F1-scores of 0.927 on HDFS, 0.913 on BGL, and 0.984 on Thunderbird, claiming up to 6 percentage point recall gains over LogGPT at comparable precision, and demonstrates a production deployment achieving 45 ms end-to-end latency at 15,000 events per second using Apache Kafka, Redis, and TensorRT inference.
Significance. If the performance gains hold and are attributable to the proposed reward formulation, the work would offer a practical advance in reinforcement-learning-based anomaly detection for large-scale system logs, with added value from the demonstrated real-time microservice deployment.
major comments (3)
- [Abstract / §4 (Experiments)] Abstract and experimental results: the manuscript reports specific F1-scores and a 6pp recall improvement but supplies no ablation studies, error bars, data-split details, or verification that the reward scheme was not tuned on test data, leaving the attribution of gains to the partial-credit exponentially decaying position-aware reward unverified.
- [§3 (Method) / §4.3 (Ablations)] Methods / reward formulation: no results are shown comparing the novel reward against standard PPO, supervised fine-tuning of GPT-Neo, or alternative reward designs, which is load-bearing for the central claim that this component drives the reported improvements rather than preprocessing or hyperparameter choices.
- [§4.2 (Benchmarks)] Table 2 or equivalent benchmark table: the cross-benchmark claim of consistent gains lacks controls for known sensitivities of HDFS/BGL/Thunderbird to parsing, windowing, and negative sampling, undermining isolation of the reward scheme's contribution.
minor comments (2)
- [§5 (Deployment)] The abstract and deployment description omit details on model quantization, batching strategy, or exact TensorRT configuration used to achieve the 45 ms / 15k eps figure.
- [§3.2 (Reward)] Notation for the position-aware reward (e.g., the exponential decay parameter and partial-credit function) is introduced without an explicit equation or pseudocode in the provided text.
Simulated Author's Rebuttal
We thank the referee for their thorough and constructive review. We address each major comment point by point below, indicating revisions where the manuscript will be updated to strengthen the evidence for our claims.
read point-by-point responses
-
Referee: [Abstract / §4 (Experiments)] Abstract and experimental results: the manuscript reports specific F1-scores and a 6pp recall improvement but supplies no ablation studies, error bars, data-split details, or verification that the reward scheme was not tuned on test data, leaving the attribution of gains to the partial-credit exponentially decaying position-aware reward unverified.
Authors: We acknowledge that the current version lacks these supporting elements. In the revised manuscript we will add: (i) ablation studies isolating reward components, (ii) error bars computed over at least three random seeds, (iii) explicit documentation of the train/validation/test splits used for each benchmark (following the standard protocols cited in LogGPT and related works), and (iv) a statement confirming that reward hyperparameters were selected solely on validation performance. These additions will provide clearer attribution of gains to the proposed reward formulation. revision: yes
-
Referee: [§3 (Method) / §4.3 (Ablations)] Methods / reward formulation: no results are shown comparing the novel reward against standard PPO, supervised fine-tuning of GPT-Neo, or alternative reward designs, which is load-bearing for the central claim that this component drives the reported improvements rather than preprocessing or hyperparameter choices.
Authors: We agree that direct comparisons are essential to isolate the contribution of the partial-credit exponentially decaying position-aware reward. The revised manuscript will include a dedicated ablation subsection reporting F1 scores for: (1) standard PPO with a simple binary reward, (2) supervised fine-tuning of the same GPT-Neo backbone, and (3) two alternative reward designs (non-decaying position-aware and uniform partial credit). These results will demonstrate the incremental benefit of our specific formulation. revision: yes
-
Referee: [§4.2 (Benchmarks)] Table 2 or equivalent benchmark table: the cross-benchmark claim of consistent gains lacks controls for known sensitivities of HDFS/BGL/Thunderbird to parsing, windowing, and negative sampling, undermining isolation of the reward scheme's contribution.
Authors: Our experimental setup follows the exact preprocessing pipelines, windowing, and negative-sampling procedures reported in LogGPT and the original benchmark papers to ensure comparability. To further address sensitivity concerns, the revision will add a dedicated paragraph discussing these factors together with, where feasible, supplementary runs that vary window size and sampling ratio while keeping the reward fixed. This will help confirm robustness of the observed gains. revision: partial
Circularity Check
No circularity; empirical results on benchmarks with no derivation chain
full rationale
The paper presents LogNEO as an empirical RL fine-tuning framework (PPO on GPT-Neo with a described reward scheme) and reports F1 scores on HDFS/BGL/Thunderbird as experimental outcomes. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claims rest on benchmark measurements rather than any self-referential reduction, satisfying the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
DeepLog: Anomaly detection and diagnosis from system logs through deep learning,
M. Du, F. Li, G. Zheng, and V . Srikumar, “DeepLog: Anomaly detection and diagnosis from system logs through deep learning,” inProc. ACM SIGSAC CCS, Dallas, TX, 2017, pp. 1285–1298
2017
-
[2]
LogAnomaly: Unsupervised detection of sequential and quantitative anomalies in unstructured logs,
W. Menget al., “LogAnomaly: Unsupervised detection of sequential and quantitative anomalies in unstructured logs,” inProc. IJCAI, 2019, pp. 4739–4745
2019
-
[3]
LogBERT: Log anomaly detection via BERT,
H. Guo, S. Yuan, and X. Wu, “LogBERT: Log anomaly detection via BERT,” inProc. IJCNN, 2021, pp. 1–8
2021
-
[4]
LogGPT: Log anomaly detection via GPT,
X. Han, S. Yuan, and M. Trabelsi, “LogGPT: Log anomaly detection via GPT,” inProc. IEEE BigData, 2023, pp. 1117–1122
2023
-
[5]
Detecting large-scale system problems by mining console logs,
W. Xuet al., “Detecting large-scale system problems by mining console logs,” inProc. ACM SOSP, Big Sky, MT, 2009, pp. 117–132
2009
-
[6]
Drain: An online log parsing approach with fixed depth tree,
P. He, J. Zhu, Z. Zheng, and M. R. Lyu, “Drain: An online log parsing approach with fixed depth tree,” inProc. IEEE ICWS, 2017, pp. 33–40
2017
-
[7]
Proximal Policy Optimization Algorithms
J. Schulmanet al., “Proximal policy optimization algorithms,” arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[8]
Attention is all you need,
A. Vaswaniet al., “Attention is all you need,” inProc. NeurIPS, 2017
2017
-
[9]
Log clustering based problem identification for online service systems,
Q. Linet al., “Log clustering based problem identification for online service systems,” inProc. ICSE Companion, 2016, pp. 102–111
2016
-
[10]
Adam: A method for stochastic optimization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” inProc. ICLR, 2015
2015
-
[11]
Isolation forest,
F. T. Liu, K. M. Ting, and Z.-H. Zhou, “Isolation forest,” inProc. IEEE ICDM, 2008, pp. 413–422
2008
-
[12]
Estimating the support of a high-dimensional distribution,
B. Sch ¨olkopfet al., “Estimating the support of a high-dimensional distribution,”Neural Computation, vol. 13, no. 7, pp. 1443–1471, 2001
2001
-
[13]
Unsupervised detection of anomalous sequences in network traffic,
X. Zhanget al., “Unsupervised detection of anomalous sequences in network traffic,” inProc. ICDM, 2021
2021
-
[14]
CAT: Beyond efficient transformer for content-aware anomaly detection in event sequences,
H. Guoet al., “CAT: Beyond efficient transformer for content-aware anomaly detection in event sequences,” inProc. KDD, 2021
2021
-
[15]
Microservices: Yesterday, today, and tomorrow,
N. Dragoniet al., “Microservices: Yesterday, today, and tomorrow,” in Present and Ulterior Software Engineering. Springer, 2017, pp. 195–216
2017
-
[16]
LogPrompt: Prompt engineering towards zero-shot and interpretable log analysis,
Y . Liuet al., “LogPrompt: Prompt engineering towards zero-shot and interpretable log analysis,” inProc. ICSE Companion, 2024, pp. 364–365
2024
-
[17]
LogLLaMA: Transformer-based log anomaly detection with LLaMA,
Z. Yang and I. G. Harris, “LogLLaMA: Transformer-based log anomaly detection with LLaMA,”arXiv:2503.14849, 2025
-
[18]
MetaLog: Generalizable cross-system anomaly detection from logs with meta-learning,
C. Zhanget al., “MetaLog: Generalizable cross-system anomaly detection from logs with meta-learning,” inProc. ICSE, Lisbon, Portugal, 2024
2024
-
[19]
An evaluation study of log parsing with a large-scale operating system dataset,
P. Heet al., “An evaluation study of log parsing with a large-scale operating system dataset,” inProc. IEEE/IFIP DSN, 2020
2020
-
[20]
Sequential anomaly detection using inverse reinforcement learning,
M.-h. Oh and G. Iyengar, “Sequential anomaly detection using inverse reinforcement learning,” inProc. ACM SIGKDD, Anchorage, AK, 2019, pp. 1480–1490
2019
-
[21]
Policy-based reinforcement learning for time series anomaly detection,
M. Yu and S. Sun, “Policy-based reinforcement learning for time series anomaly detection,”Eng. Appl. Artif. Intell., vol. 95, p. 103919, 2020
2020
-
[22]
ADT: Time series anomaly detection for cyber-physical systems via deep reinforcement learning,
X. Yang, E. Howley, and M. Schukat, “ADT: Time series anomaly detection for cyber-physical systems via deep reinforcement learning,” Computers & Security, vol. 141, p. 103825, 2024
2024
-
[23]
Revisiting design choices in proximal policy optimization,
C. C.-Y . Hsu, C. Mendler-D ¨unner, and M. Hardt, “Revisiting design choices in proximal policy optimization,”arXiv:2009.10897, 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.