RAPID: Layer-Wise Redundancy-Aware Pruning and Importance-Driven Token Merging for Efficient ViT
Pith reviewed 2026-06-27 19:44 UTC · model grok-4.3
The pith
RAPID adapts token pruning and merging to layer depth in Vision Transformers, delivering higher accuracy at aggressive compression rates than uniform baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
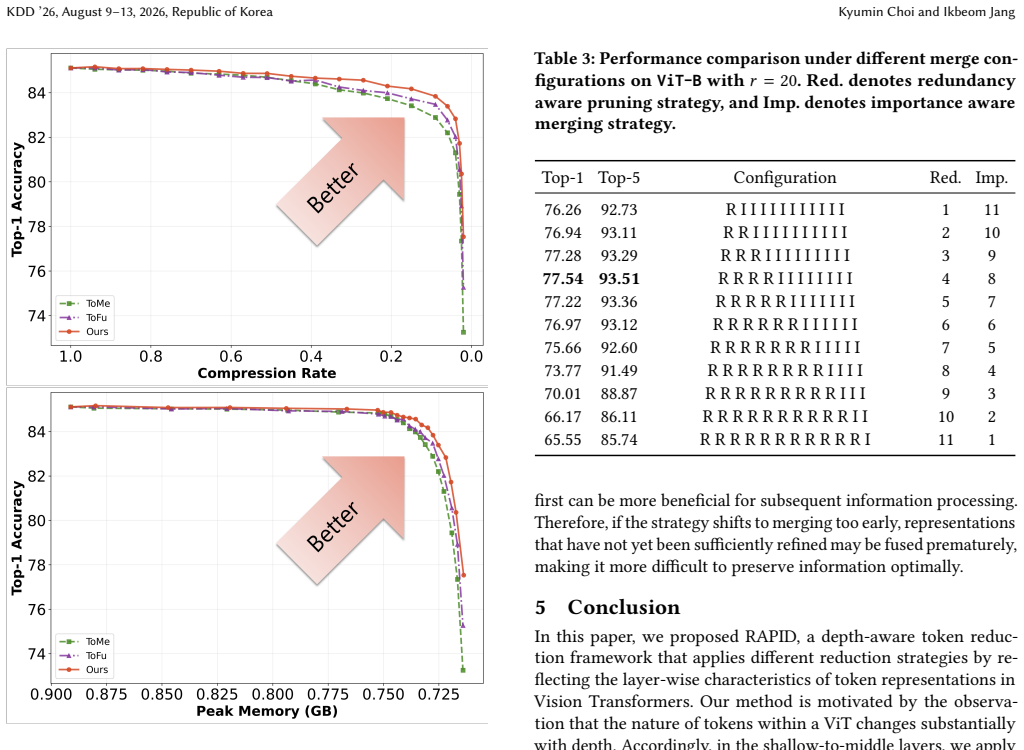
By employing redundancy-similarity-aware pruning in shallow-to-middle layers to remove over-represented local patterns and importance-similarity-aware merging in deeper layers that uses CLS-token attention weights to safeguard semantically critical tokens, RAPID produces a superior accuracy-compression Pareto frontier on ImageNet-1K for ViT and DeiT backbones and remains robust when token counts are reduced most aggressively.
What carries the argument
The bifurcated, depth-aware strategy that switches from redundancy-similarity pruning in early layers to CLS-attention-guided importance merging in later layers.
If this is right
- The method can be inserted into existing trained ViT models without any fine-tuning.
- Accuracy gains are largest precisely when the overall token budget is smallest.
- Reduction decisions become aligned with the progressive abstraction already present in the network's feature hierarchy.
Where Pith is reading between the lines
- Similar layer-dependent switches may improve token reduction in other transformer families where feature abstraction also increases with depth.
- The framework invites direct tests on detection and segmentation heads that also rely on ViT backbones.
- If the early-layer redundancy metric proves stable across datasets, it could serve as a lightweight diagnostic for where a given ViT first forms global concepts.
Load-bearing premise
Token representations change reliably from repeated local patterns early in the network to global semantic concepts later, and the chosen similarity and attention metrics correctly flag which tokens to remove or combine at each stage.
What would settle it
Running the same pruning or merging rule uniformly across all layers produces accuracy-compression curves that match or exceed RAPID's on ImageNet-1K and additional architectures.
Figures

read the original abstract
Vision Transformers (ViTs) achieve strong performance but suffer from high computational costs due to quadratic self-attention complexity. Although token reduction techniques such as pruning and merging mitigate this, they typically overlook how representations evolve across network depth. We propose RAPID, a depth-aware token reduction framework that adapts reduction strategies to the layer-wise characteristics of token representations. The primary methodological contribution is a bifurcated strategy: in shallow-to-middle layers, RAPID employs a redundancy-similarity aware pruning metric to eliminate over-represented local patterns. As features transition to global semantic concepts in deeper layers, the framework shifts to an importance-similarity aware merging mechanism. This stage leverages classification (CLS) token attention weights to protect semantically critical tokens while fusing less important but similar neighbors. Empirical validation on ImageNet-1K using ViT and DeiT architectures demonstrates that RAPID establishes a superior accuracy-compression Pareto frontier compared to plug-and-play baselines such as ToMe and ToFu. RAPID is particularly robust in aggressive compression regimes, achieving up to 4.29% higher accuracy than ToMe at extreme reduction rates. Our framework provides a training-free template for optimizing vision models by aligning reduction strategies with hierarchical feature evolution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RAPID, a training-free, depth-aware token reduction framework for Vision Transformers. It applies a redundancy-similarity aware pruning metric in shallow-to-middle layers to eliminate over-represented local patterns and shifts to an importance-similarity aware merging mechanism in deeper layers that uses CLS token attention weights to protect critical tokens while fusing similar neighbors. On ImageNet-1K with ViT and DeiT models, RAPID is claimed to achieve a superior accuracy-compression Pareto frontier over plug-and-play baselines such as ToMe and ToFu, with particular robustness at aggressive compression rates (up to 4.29% higher accuracy than ToMe).
Significance. If the reported gains are reproducible and attributable to the layer-wise adaptation rather than generic reduction, the work would offer a practical, training-free template for efficient ViT inference that aligns computational savings with the hierarchical evolution of features, which is relevant for deployment in compute-constrained environments.
major comments (1)
- [Method and Experiments sections (as described in abstract)] The central empirical claim (superior Pareto frontier and +4.29% accuracy at extreme rates) is load-bearing on the premise that the bifurcated strategy is justified by a shift from local redundancy (shallow-middle layers) to global semantics (deep layers) and that the chosen metrics correctly drive the decisions. However, the manuscript supplies no layer-wise diagnostics (token similarity histograms, CLS-attention entropy per layer, or correlation of the metrics with known local/global features) to validate this alignment. Without such evidence, the gains cannot be confidently attributed to depth-aware adaptation rather than non-specific token reduction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on validating the depth-aware adaptation. We agree that additional layer-wise diagnostics are needed to strengthen attribution of the gains to the bifurcated strategy rather than generic token reduction.
read point-by-point responses
-
Referee: [Method and Experiments sections (as described in abstract)] The central empirical claim (superior Pareto frontier and +4.29% accuracy at extreme rates) is load-bearing on the premise that the bifurcated strategy is justified by a shift from local redundancy (shallow-middle layers) to global semantics (deep layers) and that the chosen metrics correctly drive the decisions. However, the manuscript supplies no layer-wise diagnostics (token similarity histograms, CLS-attention entropy per layer, or correlation of the metrics with known local/global features) to validate this alignment. Without such evidence, the gains cannot be confidently attributed to depth-aware adaptation rather than non-specific token reduction.
Authors: We acknowledge that the manuscript does not currently provide explicit layer-wise diagnostics such as token similarity histograms, CLS-attention entropy per layer, or correlations with local/global features. In the revision, we will add these analyses to the Experiments section, including: token similarity distributions across layers (demonstrating higher redundancy in shallow-to-middle layers), CLS token attention entropy trends (showing increasing concentration in deeper layers), and metric correlations with known feature properties. These additions will directly support the rationale for the pruning-to-merging transition and help isolate the contribution of the depth-aware design. revision: yes
Circularity Check
No circularity; empirical training-free method with independent validation
full rationale
The paper describes a training-free, plug-and-play token reduction framework whose core decisions rest on explicitly defined metrics (redundancy-similarity pruning in shallow-middle layers, CLS-attention importance merging in deep layers) applied to observed layer-wise feature evolution. No equations, parameters, or performance claims are shown to be fitted to the target accuracy numbers or defined in terms of themselves. The reported Pareto improvements are obtained by direct comparison against external baselines (ToMe, ToFu) on ImageNet-1K; the derivation chain therefore remains self-contained and does not reduce to any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feicht- enhofer, and Judy Hoffman. 2023. Token Merging: Your ViT but Faster. InInter- national Conference on Learning Representations
2023
-
[2]
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition. Ieee, 248–255
2009
-
[3]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xi- aohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. 2021. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale.ICLR(2021)
2021
-
[4]
Ahmadreza Jeddi, Negin Baghbanzadeh, Elham Dolatabadi, and Babak Taati
- [5]
-
[6]
Minchul Kim, Shangqian Gao, Yen-Chang Hsu, Yilin Shen, and Hongxia Jin. 2024. Token fusion: Bridging the gap between token pruning and token merging. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 1383–1392
2024
-
[7]
Sehoon Kim, Sheng Shen, David Thorsley, Amir Gholami, Woosuk Kwon, Joseph Hassoun, and Kurt Keutzer. 2022. Learned token pruning for transformers. In Proceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining. 784–794
2022
-
[8]
Zhenglun Kong, Peiyan Dong, Xiaolong Ma, Xin Meng, Wei Niu, Mengshu Sun, Xuan Shen, Geng Yuan, Bin Ren, Hao Tang, et al. 2022. Spvit: Enabling faster vision transformers via latency-aware soft token pruning. InEuropean conference on computer vision. Springer, 620–640
2022
-
[9]
Youwei Liang, Chongjian Ge, Zhan Tong, Yibing Song, Jue Wang, and Pengtao Xie
-
[10]
InInternational Conference on Learning Representations
Not All Patches are What You Need: Expediting Vision Transformers via Token Reorganizations. InInternational Conference on Learning Representations. https://openreview.net/forum?id=BjyvwnXXVn_
-
[11]
Xinyu Liu, Houwen Peng, Ningxin Zheng, Yuqing Yang, Han Hu, and Yixuan Yuan. 2023. Efficientvit: Memory efficient vision transformer with cascaded group attention. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 14420–14430
2023
- [12]
-
[13]
Sachin Mehta and Mohammad Rastegari. 2022. MobileViT: Light-weight, General- purpose, and Mobile-friendly Vision Transformer. InInternational Conference on Learning Representations
2022
-
[14]
Namuk Park and Songkuk Kim. 2022. How Do Vision Transformers Work?. In International Conference on Learning Representations
2022
-
[15]
Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, and Cho-Jui Hsieh
-
[16]
Advances in neural information processing systems34 (2021), 13937–13949
Dynamicvit: Efficient vision transformers with dynamic token sparsification. Advances in neural information processing systems34 (2021), 13937–13949
2021
-
[17]
Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. 2021. Training data-efficient image transformers & distillation through attention. InInternational conference on machine learning. PMLR, 10347–10357
2021
-
[18]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
2017
-
[19]
Siyuan Wei, Tianzhu Ye, Shen Zhang, Yao Tang, and Jiajun Liang. 2023. Joint token pruning and squeezing towards more aggressive compression of vision transformers. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2092–2101
2023
-
[20]
Ross Wightman. 2019. PyTorch Image Models. https://github.com/rwightman/ pytorch-image-models. doi:10.5281/zenodo.4414861
-
[21]
Hongxu Yin, Arash Vahdat, Jose M Alvarez, Arun Mallya, Jan Kautz, and Pavlo Molchanov. 2022. A-vit: Adaptive tokens for efficient vision transformer. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10809–10818
2022
-
[22]
Qizhe Zhang, Aosong Cheng, Ming Lu, Renrui Zhang, Zhiyong Zhuo, Jiajun Cao, Shaobo Guo, Qi She, and Shanghang Zhang. 2025. Beyond text-visual attention: Exploiting visual cues for effective token pruning in vlms. InProceedings of the IEEE/CVF International Conference on Computer Vision. 20857–20867
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.