Closing the Sim-to-Real Gap: An Evaluation Framework for Autonomous Cyber Defense Configuration of Commercial EDR
Pith reviewed 2026-06-27 19:22 UTC · model grok-4.3
The pith
Autonomous defense agents hardening commercial EDR need a dedicated evaluation framework because black-box tools behave differently than simulations predict.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
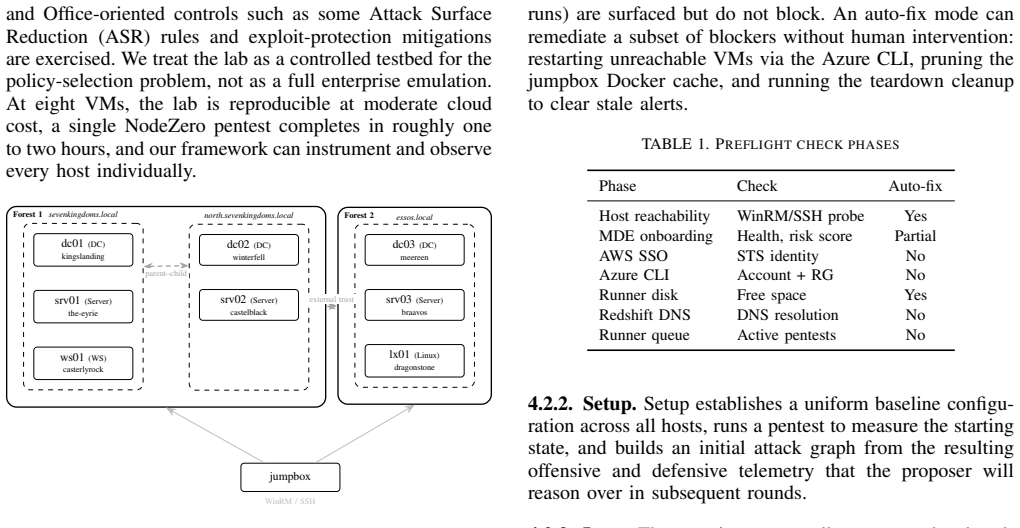
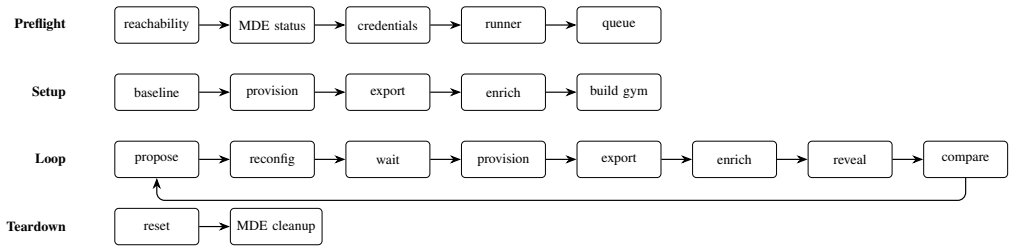
Autonomous defense agents using commercial EDR as their hardening tool are configuring a black-box autonomous system rather than a passive tool. The first evaluation framework, instantiated with NodeZero as pentester and Microsoft Defender XDR as EDR and benchmarked with Claude Sonnet 4.6 and Cisco Foundation-Sec-8B, surfaces three lessons: commercial EDR telemetry targets SOC workflows instead of scientific benchmarking, per-policy attribution is required to separate defense agent actions from autonomous EDR actions, and EDR autonomous behavior varies during the evaluation window. These findings highlight a sim-to-real gap for enterprise defense and motivate evaluation methodology for bench
What carries the argument
The evaluation framework for autonomous defense agents hardening commercial EDR, which requires per-policy attribution and captures variable autonomous behavior of the black-box EDR during testing.
If this is right
- Commercial EDR telemetry is engineered for Security Operations Center analyst workflows rather than scientific benchmarking.
- Per-policy attribution is required to separate defense agent actions from autonomous EDR actions.
- The EDR's autonomous behavior varies during the evaluation window.
- Evaluation methodology must be developed specifically for benchmarking autonomous defense agents against black-box autonomous tools.
Where Pith is reading between the lines
- The framework's emphasis on attribution and telemetry may apply when evaluating autonomous agents against other commercial security products that contain their own AI decision components.
- Standardized testbeds that include multiple vendor EDR products could strengthen claims about the generality of the observed gap.
- Similar evaluation challenges are likely to appear when autonomous agents interact with black-box tools in adjacent domains such as cloud access security or network segmentation.
Load-bearing premise
The lessons observed with NodeZero as pentester, Microsoft Defender XDR as EDR, and the two chosen LLM backbones generalize beyond this specific commercial product and lab setup to other EDR systems.
What would settle it
Running the same benchmark against a different commercial EDR product that produces consistent, benchmark-friendly telemetry and shows no behavioral variation during the evaluation window would falsify the claimed sim-to-real gap.
Figures

read the original abstract
Leading commercial endpoint detection and response (EDR) products have shifted from operator-configured rule sets to multi-component systems where autonomous AI components operate alongside, and increasingly in place of, operator-deployed policies. Autonomous defense agents using commercial EDR as their hardening tool are no longer tuning a passive tool, but a black-box autonomous system capable of making vendor-specific decisions. We present the first evaluation framework for autonomous defense agents hardening commercial EDR. We instantiate it in a Game of Active Directory (GOAD) lab with Horizon3.ai's NodeZero as the autonomous pentester and Microsoft Defender XDR as the EDR. We run a sample benchmark of defense agents with two large language model (LLM) backbones (Claude Sonnet 4.6 and Cisco Foundation-Sec-8B). We report three lessons learned that neither simulation nor open-source-EDR evaluation can surface: (i) commercial EDR telemetry is engineered for Security Operations Center (SOC) analyst workflows rather than scientific benchmarking; (ii) the importance of per-policy attribution to separate defense agent actions from autonomous EDR actions; and (iii) the EDR's autonomous behavior varies during the evaluation window. Together, these findings highlight a sim-to-real gap for enterprise defense and motivate evaluation methodology for benchmarking autonomous defense agents in environments with black-box, autonomous tools.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to present the first evaluation framework for autonomous defense agents that harden commercial EDR systems. It instantiates the framework in a GOAD lab with Horizon3.ai NodeZero as the autonomous pentester and Microsoft Defender XDR as the EDR, running a sample benchmark with two LLM backbones (Claude Sonnet 4.6 and Cisco Foundation-Sec-8B). From this single instantiation the authors extract three lessons—(i) commercial EDR telemetry is engineered for SOC workflows rather than benchmarking, (ii) per-policy attribution is required to separate agent actions from autonomous EDR actions, and (iii) EDR autonomous behavior varies over the evaluation window—and argue that these demonstrate a sim-to-real gap for enterprise defense while motivating new benchmarking methodology for black-box autonomous tools.
Significance. If the framework and the three lessons prove representative of commercial EDRs beyond the single product tested, the work would supply a concrete methodology for evaluating autonomous cyber-defense agents against real black-box enterprise tools, an area where both pure simulation and open-source EDR studies are known to be insufficient. The explicit focus on attribution and time-varying behavior is a useful contribution to evaluation design.
major comments (2)
- [Abstract] Abstract: The central claim that the three lessons demonstrate a sim-to-real gap 'for enterprise defense' and for 'commercial EDRs as a class' rests on observations from only one EDR (Microsoft Defender XDR) and one autonomous pentester (NodeZero). No cross-vendor data, no argument that the SOC-oriented telemetry design or time-varying policy engine are representative properties of other black-box commercial EDRs, and no discussion of why the lessons must generalize are supplied; this directly affects the load-bearing generalization in the paper's contribution statement.
- [Abstract] Abstract and reported lessons: The three lessons are derived from a single lab configuration and two LLM backbones with no reported replication across vendors, alternative autonomous pentesters, or controlled variations in EDR policy engines. Without such controls or an explicit scope limitation, the lessons cannot be treated as properties of the broader class of commercial EDRs rather than artifacts of the chosen instantiation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need to carefully scope our claims. The primary contribution is the evaluation framework, which we will clarify is demonstrated via a single instantiation; we will revise the abstract and add scope discussion to address generalization concerns without overstating the lessons.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the three lessons demonstrate a sim-to-real gap 'for enterprise defense' and for 'commercial EDRs as a class' rests on observations from only one EDR (Microsoft Defender XDR) and one autonomous pentester (NodeZero). No cross-vendor data, no argument that the SOC-oriented telemetry design or time-varying policy engine are representative properties of other black-box commercial EDRs, and no discussion of why the lessons must generalize are supplied; this directly affects the load-bearing generalization in the paper's contribution statement.
Authors: We agree the lessons derive from one EDR and one pentester, with no cross-vendor data or explicit representativeness argument provided. The framework is intended as a general methodology for black-box commercial tools, and the lessons illustrate challenges (SOC-oriented telemetry, attribution needs, time-varying behavior) that simulation cannot capture. To address this, we will revise the abstract to qualify the lessons as arising from this instantiation, add a limitations paragraph on generalization, and note that the framework enables future multi-vendor studies. This adjusts the claims to match the evidence while preserving the motivation for the framework. revision: yes
-
Referee: [Abstract] Abstract and reported lessons: The three lessons are derived from a single lab configuration and two LLM backbones with no reported replication across vendors, alternative autonomous pentesters, or controlled variations in EDR policy engines. Without such controls or an explicit scope limitation, the lessons cannot be treated as properties of the broader class of commercial EDRs rather than artifacts of the chosen instantiation.
Authors: The reported benchmark serves to demonstrate framework usage rather than to statistically establish class-wide properties. We accept that without replications or controls, the lessons should not be generalized. We will add explicit scope limitations in the abstract and discussion sections, clarifying that the three lessons are observations from the Microsoft Defender XDR + NodeZero setup and that broader validation is future work enabled by the framework. This revision ensures the claims align with the single-instantiation design. revision: yes
Circularity Check
No significant circularity; empirical evaluation paper with no derivations
full rationale
The paper presents an evaluation framework instantiated in a GOAD lab with NodeZero and Microsoft Defender XDR, reporting three empirical lessons from LLM-based defense agents. No equations, derivations, fitted parameters, or predictive models appear in the abstract or described content. The central claims rest on direct experimental observations rather than any chain that reduces by construction to inputs, self-citations, or ansatzes. This is a standard empirical methodology paper whose argument is self-contained against external benchmarks and does not invoke the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gartner magic quadrant for endpoint protection platforms,
Gartner, “Gartner magic quadrant for endpoint protection platforms,” Jul. 2025, accessed: May 26, 2026. [Online]. Available: https: //www.sentinelone.com/lp/gartnermq/
2025
-
[2]
Microsoft ranked number one in modern endpoint security market share third year in a row,
R. Lefferts, “Microsoft ranked number one in modern endpoint security market share third year in a row,” Aug. 2025, accessed: May 26, 2026. [Online]. Available: https://www.microsoft.com/en-us/ security/blog/2025/08/27/microsoft-ranked-number-one-in-modern- endpoint-security-market-share-third-year-in-a-row/
2025
-
[3]
Cyborg: A gym for the development of autonomous cyber agents,
M. Standen, M. Lucas, D. Bowman, T. J. Richer, J. Kim, and D. Marriott, “Cyborg: A gym for the development of autonomous cyber agents,” Aug. 2021. [Online]. Available: https: //arxiv.org/abs/2108.09118
arXiv 2021
-
[4]
Cage challenge 4: A scalable multi-agent reinforcement learning gym for autonomous cyber defence,
M. Kiely, M. Ahiskali, E. Borde, B. Bowman, D. Bowman, D. Van Bruggen, K. Cowan, P. Dasgupta, E. Devendorf, B. Edwards et al., “Cage challenge 4: A scalable multi-agent reinforcement learning gym for autonomous cyber defence,”AI Magazine, vol. 46, no. 3, p. e70021, 2025
2025
-
[5]
Nasimemu: Network attack simula- tor & emulator for training agents generalizing to novel scenarios,
J. Janisch, T. Pevn `y, and V . Lis`y, “Nasimemu: Network attack simula- tor & emulator for training agents generalizing to novel scenarios,” in European Symposium on Research in Computer Security. Springer, 2023, pp. 589–608
2023
-
[6]
Mine the gap: Open-source tools for measuring the ai offense-defense gap,
Dreadnode, “Mine the gap: Open-source tools for measuring the ai offense-defense gap,” 2026, accessed:2026-05-26. [Online]. Available: https://dreadnode.io/research/mine-the-gap-open-source- tools-for-measuring-the-ai-offense-defense-gap/
2026
-
[7]
V . Mayoral-Vilches, M. Sanz-G ´omez, F. Balassone, M. D. M. D. Torres, G. Nicolaou, S. R. Borines, A. Graziano, P. Zabalegui, and E. Gil-Uriarte, “Dynamic cyber ranges,” Apr. 2026. [Online]. Available: https://arxiv.org/abs/2604.24184
Pith/arXiv arXiv 2026
-
[8]
Microsoft defender xdr,
Microsoft, “Microsoft defender xdr,” webpage, accessed: May 26,
-
[9]
Available: https://www.microsoft.com/en-us/security/ business/siem-and-xdr/microsoft-defender-xdr
[Online]. Available: https://www.microsoft.com/en-us/security/ business/siem-and-xdr/microsoft-defender-xdr
-
[10]
Crowdstrike falcon insight xdr,
CrowdStrike, “Crowdstrike falcon insight xdr,” webpage, accessed: May 26, 2026. [Online]. Available: https://www.crowdstrike.com/en- us/platform/endpoint-security/falcon-insight-xdr/
2026
-
[11]
Singularity endpoint,
SentinelOne, “Singularity endpoint,” webpage, accessed: May 26,
-
[12]
Available: https://www.sentinelone.com/platform/ endpoint-security/
[Online]. Available: https://www.sentinelone.com/platform/ endpoint-security/
-
[13]
Goad: Game of active directory,
Orange Cyberdefense, “Goad: Game of active directory,” GitHub repository, accessed: May 26, 2026. [Online]. Available: https: //github.com/Orange-Cyberdefense/GOAD
2026
-
[14]
Nodezero platform,
Horizon3.ai, “Nodezero platform,” accessed: May 26, 2026. [Online]. Available: https://horizon3.ai/nodezero/
2026
-
[15]
Mitre att&ck,
The MITRE Corporation, “Mitre att&ck,” accessed: May 24, 2026. [Online]. Available: https://attack.mitre.org/
2026
-
[16]
X. Shen, Z. Li, G. Burleigh, L. Wang, and Y . Chen, “Decoding the mitre engenuity att&ck enterprise evaluation: An analysis of edr performance in real-world environments,” inProc. of the 19th ACM Asia Conf. on Comput. and Commun. Secur . (ASIA CCS ’24), Jul. 2024, pp. 96–111. [Online]. Available: https://dl.acm.org/doi/10.1145/3634737.3645012
-
[17]
Tactical provenance analysis for endpoint detection and response systems,
W. U. Hassan, A. Bates, and D. Marino, “Tactical provenance analysis for endpoint detection and response systems,” in2020 IEEE Symp. on Secur . and Privacy (SP), San Francisco, CA, USA, 2020, pp. 1172–1189. [Online]. Available: https://ieeexplore.ieee.org/ document/9152771
arXiv 2020
-
[18]
How does endpoint detection use the mitre att&ck framework?
A. Virkud, M. A. Inam, A. Riddle, J. Liu, G. Wang, and A. Bates, “How does endpoint detection use the mitre att&ck framework?” inProc. of the 33rd USENIX Conf. on Secur . Symp. (SEC ’24). USENIX Association, 2024, pp. 3891–3908. [Online]. Available: https://dl.acm.org/doi/10.5555/3698900.3699118
-
[19]
An empirical assessment of endpoint detection and response systems against advanced persistent threats attack vectors,
G. Karantzas and C. Patsakis, “An empirical assessment of endpoint detection and response systems against advanced persistent threats attack vectors,”J. Cybersecur . Priv., Jul. 2021. [Online]. Available: https://www.mdpi.com/2624-800X/1/3/21
2021
-
[20]
Edr telemetry,
K. Tsales, “Edr telemetry,” GitHub repository, accessed: May 24,
-
[21]
Available: https://github.com/tsale/EDR-Telemetry
[Online]. Available: https://github.com/tsale/EDR-Telemetry
-
[22]
L. Yanget al., “True attacks, attack attempts, or benign triggers? an empirical measurement of network alerts in a security operations center,” inProc. of the 33rd USENIX Conf. on Secur . Symp. (SEC ’24). USENIX Association, Aug. 2024, pp. 1525–1542. [Online]. Available: https://dl.acm.org/doi/10.5555/3698900.3698986
-
[23]
Alert fatigue in security operations centres: Research challenges and opportunities,
S. Tariq, M. B. Chhetri, S. Nepal, and C. Paris, “Alert fatigue in security operations centres: Research challenges and opportunities,” ACM Computing Surveys, vol. 57, no. 9, pp. 1–38, Apr. 2025. [Online]. Available: https://dl.acm.org/doi/full/10.1145/3723158
-
[24]
99% false positives: A qualitative study of soc analysts’ perspectives on security alarms,
B. A. Alahmadi, L. Axon, and I. Martinovic, “99% false positives: A qualitative study of soc analysts’ perspectives on security alarms,” in Proc. of the 31st USENIX Conf. on Secur . Symp. (SEC ’22). USENIX Association, Aug. 2022, pp. 2783–2800. [Online]. Available: https: //www.usenix.org/conference/usenixsecurity22/presentation/alahmadi
2022
-
[25]
Microsoft defender for endpoint security baseline settings reference for microsoft intune,
Microsoft, “Microsoft defender for endpoint security baseline settings reference for microsoft intune,” May 2026, accessed: May 24, 2026. [Online]. Available: https://learn.microsoft.com/en-us/intune/device- security/security-baselines/ref-defender-settings?pivots=mde-v24h1
2026
-
[26]
Attack surface reduction rules deployment guide,
——, “Attack surface reduction rules deployment guide,” May 2026, accessed: May 26, 2026. [On- line]. Available: https://learn.microsoft.com/en-us/defender-endpoint/ attack-surface-reduction-rules-deployment
2026
-
[27]
Attack surface reduction frequently asked questions (faq),
——, “Attack surface reduction frequently asked questions (faq),” May 2026, accessed: May 26, 2026. [Online]. Available: https://learn. microsoft.com/en-us/defender-endpoint/attack-surface-reduction-faq
2026
-
[28]
Automation levels in automated investigation and remedi- ation,
Microsoft, “Automation levels in automated investigation and remedi- ation,” Jan. 2026, accessed: May 26, 2026. [Online]. Available: https: //learn.microsoft.com/en-us/defender-endpoint/automation-levels
2026
-
[29]
G. Brockman, V . Cheung, L. Pettersson, J. Schneider, J. Schul- man, J. Tang, and W. Zaremba, “Openai gym,”arXiv preprint arXiv:1606.01540, Jun. 2016
Pith/arXiv arXiv 2016
-
[30]
Mitre att&ck evaluations,
MITRE Engenuity, “Mitre att&ck evaluations,” accessed: May 26,
-
[31]
Available: https://evals.mitre.org/
[Online]. Available: https://evals.mitre.org/
-
[32]
Defender policy evaluation and resource allocation using mitre att&ck evaluations data,
A. V . Outkin, P. V . Schulz, T. Schulz, T. D. Tarman, and A. Pinar, “Defender policy evaluation and resource allocation using mitre att&ck evaluations data,” Jul. 2021. [Online]. Available: https://arxiv.org/abs/2107.04075
arXiv 2021
-
[33]
Dreadgoad,
Dreadnode, “Dreadgoad,” GitHub, 2026, accessed:2026-05-26. [Online]. Available: https://github.com/dreadnode/DreadGOAD
2026
-
[34]
[Online]
Wazuh, “Wazuh,” GitHub repository, accessed: May 26, 2026. [Online]. Available: https://github.com/wazuh/wazuh
2026
-
[35]
Rapid7 velociraptor,
Rapid7, “Rapid7 velociraptor,” webpage, accessed: May 26, 2026. [Online]. Available: https://docs.velociraptor.app/
2026
-
[36]
Stable agentic control: Tool-mediated llm architecture for autonomous cyber defense,
K. Prinos, L. Brush, C. Denton, Z. Wang, J. Knox, S. Antani, A. Foltz, and A. Villase ˜nor, “Stable agentic control: Tool-mediated llm architecture for autonomous cyber defense,” May 2026. [Online]. Available: https://arxiv.org/abs/2605.03034
Pith/arXiv arXiv 2026
-
[37]
Credential guard overview,
Microsoft, “Credential guard overview,” Apr. 2026, accessed: May 26, 2026. [Online]. Avail- able: https://learn.microsoft.com/en-us/windows/security/identity- protection/credential-guard/credential-guard-requirements
2026
-
[38]
Attack surface reduction rules reference,
——, “Attack surface reduction rules reference,” May 2026, accessed: May 26, 2026. [Online]. Available: https://learn.microsoft.com/en- us/defender-endpoint/attack-surface-reduction-rules-reference
2026
-
[39]
Claude sonnet 4.6 system card,
Anthropic, “Claude sonnet 4.6 system card,” Mar. 2026, accessed: May 26, 2026. [Online]. Available: https://www-cdn.anthropic.com/ bbd8ef16d70b7a1665f14f306ee88b53f686aa75.pdf
2026
-
[40]
Llama-3.1-foundationai- securityllm-base-8b technical report,
P. Kassianik, B. Saglam, A. Chen, B. Nelson, A. Vellore, M. Aufiero, F. Burch, D. Kedia, A. Zohary, S. Weerawardhena, A. Priyanshu, A. Swanda, A. Chang, H. Anderson, K. Oshiba, O. Santos, Y . Singer, and A. Karbasi, “Llama-3.1-foundationai- securityllm-base-8b technical report,” Apr. 2025. [Online]. Available: https://arxiv.org/abs/2504.21039
arXiv 2025
-
[41]
Monitor asr rule activity,
Microsoft, “Monitor asr rule activity,” May 2026, accessed: May 26, 2026. [Online]. Available: https://learn.microsoft.com/en-us/ defender-endpoint/attack-surface-reduction-rules-monitor
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.