Frequency-Domain Latent Attention Gating for Cross-Domain Token Aggregation
Pith reviewed 2026-06-27 20:17 UTC · model grok-4.3
The pith
FLaG enhances token aggregation by processing representations in the frequency domain with latent queries and gating.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FLaG is a plug-in aggregation module that transforms token representations with the real FFT, summarizes spectral components with learnable latent queries, applies a channel-wise gate, and reconstructs enhanced time-domain tokens for final pooling. It delivers clearest gains on ESM2-8M antimicrobial peptide tasks and CIFAR-100 image classification while staying competitive on IMDB and GLUE text tasks.
What carries the argument
The FLaG module performs frequency-domain summarization of tokens using latent queries on FFT components followed by channel gating and reconstruction.
If this is right
- Performance improves on antimicrobial peptide activity prediction using ESM2 models.
- Gains appear on CIFAR-100 image classification with ResNet18.
- Results remain competitive on IMDB and GLUE text classification with RoBERTa.
- Low-frequency spectral bands contribute the most to overall performance.
Where Pith is reading between the lines
- Applying similar frequency processing might help in other domains like audio or time-series data where spectral features matter.
- The sample-specific nature of higher bands suggests potential for adaptive frequency selection per input.
Load-bearing premise
Learnable latent queries on FFT spectral components will capture aggregation information missed by standard time-domain pooling methods.
What would settle it
Running the same tasks with a version of FLaG that skips the FFT and latent query steps and observing no performance difference from the full module.
Figures
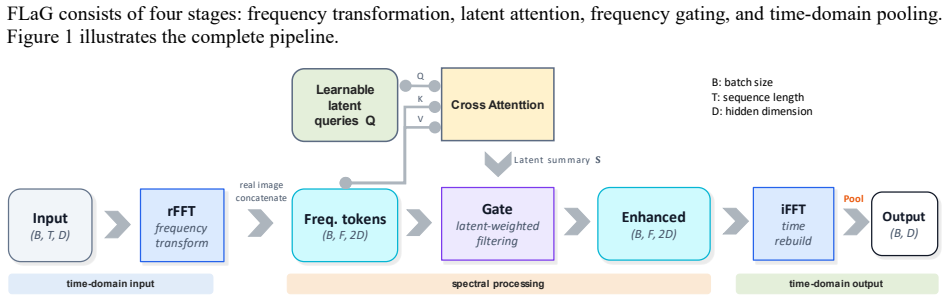


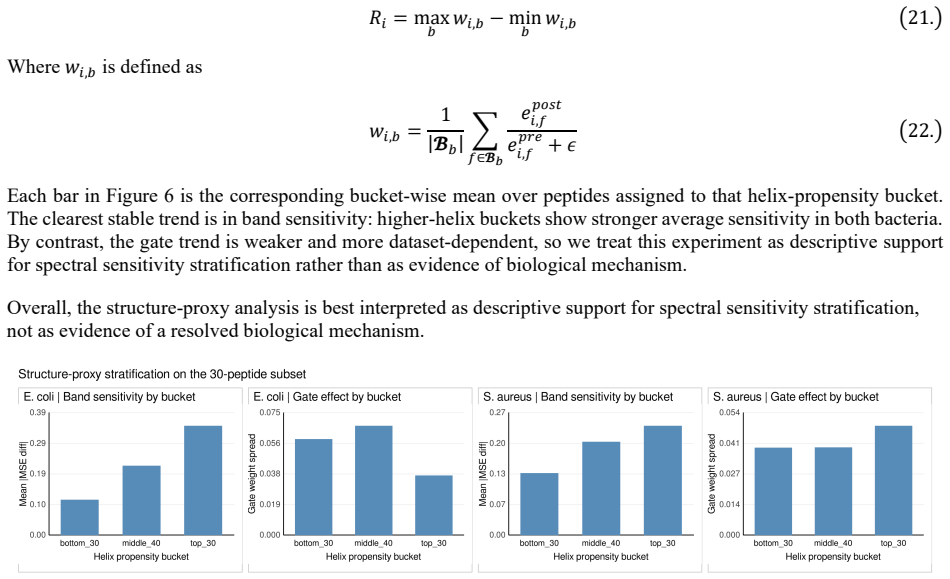
read the original abstract
Token aggregation is a common bottleneck in models that map token representations to sample-level predictions, yet most pooling methods operate only in the original token domain. We propose FLaG, a plug-in aggregation module that transforms token representations with the real FFT, summarizes spectral components with learnable latent queries, applies a channel-wise gate, and reconstructs enhanced time-domain tokens for final pooling. We evaluate FLaG on antimicrobial peptide (AMP) activity prediction with ESM2, image classification with ResNet18 on CIFAR-10 and CIFAR-100, and text classification with RoBERTa on IMDB and GLUE. FLaG achieves its clearest gains on the ESM2-8M antimicrobial peptide tasks and on CIFAR-100, while remaining competitive with strong text baselines on IMDB and GLUE. Then we probe its behavior on the AMP setting with band knockouts, gate summaries, residue perturbations, latent-query readouts, and structure-proxy stratification. We find that low-frequency bands contribute the most overall, and the remaining higher-band pattern is more sample-specific. The gate acts as a broadly shared spectral reweighting stage and the cross-attention patterns are sample-specific with mild query-wise differentiation, and higher-helix peptides exhibit stronger average spectral sensitivity in both bacteria. The supplementary materials, source code and data are released at https://www.healthinformaticslab.org/supp/ and https://github.com/Kewei2023/AMPCliff/tree/FLaG.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FLaG, a plug-in token aggregation module that applies the real FFT to token representations, summarizes spectral components using learnable latent queries via cross-attention, applies a channel-wise gate, and reconstructs enhanced time-domain tokens for final pooling. It reports empirical results on antimicrobial peptide activity prediction using ESM2, image classification with ResNet18 on CIFAR-10/100, and text classification with RoBERTa on IMDB and GLUE, with the clearest gains on the AMP tasks and CIFAR-100; additional probes on the AMP setting examine band contributions, gate behavior, and query patterns.
Significance. If the frequency-domain premise holds, FLaG could provide a new mechanism for improving sample-level aggregation in transformer pipelines across modalities. The release of code, data, and supplementary materials is a clear strength supporting reproducibility, as are the behavioral probes (band knockouts, gate summaries, latent-query readouts). Significance is tempered by the need to confirm that gains derive specifically from the FFT rather than the added learnable components.
major comments (2)
- [Experiments section] Experiments section: No direct ablation is presented comparing FLaG to an otherwise identical time-domain latent-query + channel-gate module (i.e., cross-attention and gating applied directly to the original token representations without the FFT). This is load-bearing for the central claim that the FFT step extracts aggregation-relevant information missed by standard time-domain pooling; the reported gains on ESM2-8M AMP and CIFAR-100 could arise from the added free parameters alone.
- [Results tables] Results tables (AMP, CIFAR, IMDB, GLUE): Performance differences are reported without error bars, multiple random seeds, or statistical tests, so it is unclear whether the observed improvements exceed typical hyperparameter variation or run-to-run noise.
minor comments (2)
- [Abstract] Abstract: The phrase 'clearest gains' is used without effect-size quantification or direct comparison to the strength of the baselines.
- [Method description] Method description: The precise definition of the real FFT, spectral bin handling, and inverse reconstruction step could be stated more formally (e.g., with explicit equations) to aid readers before consulting the released code.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments highlight important gaps in experimental validation and statistical reporting. We address each point below and commit to revisions that directly strengthen the manuscript without misrepresenting our current results.
read point-by-point responses
-
Referee: [Experiments section] Experiments section: No direct ablation is presented comparing FLaG to an otherwise identical time-domain latent-query + channel-gate module (i.e., cross-attention and gating applied directly to the original token representations without the FFT). This is load-bearing for the central claim that the FFT step extracts aggregation-relevant information missed by standard time-domain pooling; the reported gains on ESM2-8M AMP and CIFAR-100 could arise from the added free parameters alone.
Authors: We agree that an explicit time-domain ablation (identical latent queries and channel gating applied directly to token representations, without the FFT) is the most direct test of whether the frequency-domain transform contributes beyond added parameters. While our band-knockout, gate-behavior, and latent-query analyses already indicate that specific spectral components and their reweighting matter, these do not fully substitute for the requested control. We will add this ablation to the revised Experiments section, matching parameter counts and training protocols as closely as possible. revision: yes
-
Referee: [Results tables] Results tables (AMP, CIFAR, IMDB, GLUE): Performance differences are reported without error bars, multiple random seeds, or statistical tests, so it is unclear whether the observed improvements exceed typical hyperparameter variation or run-to-run noise.
Authors: We acknowledge that single-run point estimates limit confidence in the reported gains. The current tables reflect the primary experimental setting used throughout the paper. In revision we will rerun all main experiments with a minimum of three random seeds, report means and standard deviations, and add statistical significance tests (paired t-tests or Wilcoxon tests, as appropriate) between FLaG and baselines. revision: yes
Circularity Check
No significant circularity; method defined independently of results
full rationale
The paper defines FLaG explicitly as a plug-in module (real FFT transform of tokens, summarization via learnable latent queries, channel-wise gate, reconstruction to time-domain for pooling) without any equations or claims that reduce its reported gains on AMP, CIFAR, or GLUE tasks to quantities fitted on those same evaluation sets. No self-citations appear as load-bearing premises, no uniqueness theorems are imported from prior author work, and no ansatzes are smuggled via citation. The central design choices and empirical probes (band knockouts, gate summaries) are presented as independent of the benchmark outcomes, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- latent queries
- channel-wise gate weights
axioms (1)
- standard math The real FFT produces a valid frequency-domain representation of token sequences that preserves information for subsequent reconstruction.
Reference graph
Works this paper leans on
-
[1]
NV-embed: Improved techniques for training LLMs as generalist embedding models,
C. Lee et al., “NV-embed: Improved techniques for training LLMs as generalist embedding models,” arXiv.org. Accessed: May 26, 2026. [Online]. Available: https://arxiv.org/abs/2405.17428v3
Pith/arXiv arXiv 2026
-
[2]
A structured self -attentive sentence embedding,
Z. Lin et al. , “A structured self -attentive sentence embedding,” in Proc. 5th int. Conf. Learn. Represent. (ICLR), 2017. [Online]. Available: https://openreview.net/forum?id=BJC_jUqxe
2017
-
[3]
Set transformer: A framework for attention- based permutation-invariant neural networks,
J. Lee, Y. Lee, J. Kim, A. Kosiorek, S. Choi, and Y. W. Teh, “Set transformer: A framework for attention- based permutation-invariant neural networks,” in Proceedings of the 36th International Conference on Machine Learning, PMLR, May 2019, pp. 3744– 3753. Accessed: Mar. 17, 2026. [Online]. Available: https://proceedings.mlr.press/v97/lee19d.html
2019
-
[4]
Pooling and attention: What are effective designs for LLM -based embedding models?,
Y. Tang and Y. Yang, “Pooling and attention: What are effective designs for LLM -based embedding models?,” arXiv preprint arXiv:2409.02727, 2024, doi: 10.48550/arXiv.2409.02727
-
[5]
EvoPool: Evolution -guided pooling of protein language model embeddings,
N. NaderiAlizadeh and R. Singh, “EvoPool: Evolution -guided pooling of protein language model embeddings,” openRxiv, 2026, doi: 10.64898/2026.02.02.703349
-
[6]
Sliced and radon wasserstein barycenters of measures,
N. Bonneel, J. Rabin, G. Peyré, and H. Pfister, “Sliced and radon wasserstein barycenters of measures,” J. Math. Imaging Vis., vol. 51, no. 1, pp. 22–45, 2015, doi: 10.1007/s10851-014-0506-3
-
[7]
On the spectral bias of neural networks
N. Rahaman et al., “On the spectral bias of neural networks”
-
[8]
Semi- supervised classification with graph convolutional networks,
T. N. Kipf and M. Welling, “Semi- supervised classification with graph convolutional networks,” in Proc. 5th int. Conf. Learn. Represent. (ICLR) , 2017. [Online]. Available: https://openreview.net/forum?id=SJU4ayYgl
2017
-
[9]
FEDformer: Frequency enhanced decomposed transformer for long-term series forecasting,
T. Zhou, Z. Ma, Q. Wen, X. Wang, L. Sun, and R. Jin, “FEDformer: Frequency enhanced decomposed transformer for long-term series forecasting,” in Proc. 39th int. Conf. Mach. Learn. (ICML) , in Proc. Mach. Learn. Res., vol. 162. 2022, pp. 27268– 27286. [Online]. Available: https://proceedings.mlr.press/v162/zhou22g.html
2022
-
[10]
Z. Lin et al., “Evolutionary-scale prediction of atomic-level protein structure with a language model,” Science, vol. 379, no. 6637, pp. 1123–1130, 2023, doi: 10.1126/science.ade2574
-
[11]
Enzyme activity prediction of sequence variants on novel substrates using improved substrate encodings and convolutional pooling,
Z. Xu, J. Wu, Y. S. Song, and R. Mahadevan, “Enzyme activity prediction of sequence variants on novel substrates using improved substrate encodings and convolutional pooling,” in Proceedings of the 16th Machine Learning in Computational Biology meeting, PMLR, Jan. 2022, pp. 78 –87. Accessed: May 26, 2026. [Online]. Available: https://proceedings.mlr.press...
2022
-
[12]
A. Tartici, G. Nayar, and R. B. Altman, “Pool PaRTI: A PageRank-based pooling method for identifying critical residues and enhancing protein sequence representations, ” bioRxiv, p. 2024.10.04.616701, Mar. 2025, doi: 10.1101/2024.10.04.616701
-
[13]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Y. Liu et al. , “RoBERTa: A robustly optimized BERT pretraining approach,” arXiv preprint arXiv:1907.11692, 2019, doi: 10.48550/arXiv.1907.11692
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1907.11692 1907
-
[14]
Foundations of computer vision
“Foundations of computer vision.” Accessed: Jun. 02, 2026. [Online]. Available: https://mitpress.mit.edu/9780262048972/foundations-of-computer-vision/
arXiv 2026
-
[15]
Perceiver IO: A general architecture for structured inputs and outputs,
A. Jaegle et al. , “Perceiver IO: A general architecture for structured inputs and outputs,” in Proc. 10th int. Conf. Learn. R epresent. (ICLR), 2022. [Online]. Available: https://openreview.net/forum?id=fILj7WpI-g
2022
-
[16]
AMPCliff: Quantitative definition and benchmarking of activity cliffs in antimicrobial peptides,
K. Li et al. , “AMPCliff: Quantitative definition and benchmarking of activity cliffs in antimicrobial peptides,” Journal of Advanced Research, 2025
2025
-
[17]
Universal pooling – a new pooling method for convolutional neural networks,
J. Hyun, H. Seong, and E. Kim, “Universal pooling – a new pooling method for convolutional neural networks,” Expert Systems with Applications , vol. 180, p. 115084, Oct. 2021, doi: 10.1016/j.eswa.2021.115084
-
[18]
Deep Residual Learning for Image Recognition
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. IEEE conf. Comput. Vis. Pattern recognit. (CVPR), 2016, pp. 770–778. doi: 10.1109/CVPR.2016.90
-
[19]
Learning multiple layers of features from tiny images,
A. Krizhevsky, “Learning multiple layers of features from tiny images,” Univ. of Toronto, 2009. [Online]. Available: https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
2009
-
[20]
Learning word vectors for sentiment analysis,
A. L. Maas, R. E. Daly, P. T. Pham, D. Huang, A. Y. Ng, and C. Potts, “Learning word vectors for sentiment analysis,” in Proc. 49th annu. Meeting assoc. Comput. Linguist. (ACL), 2011, pp. 142–150. [Online]. Available: https://aclanthology.org/P11-1015/
2011
-
[21]
GLUE: A multi-task benchmark and analysis platform for natural language understanding,
A. Wang, A. Singh, J. Michael, F. Hill, O. Levy, and S. R. Bowman, “GLUE: A multi-task benchmark and analysis platform for natural language understanding,” in Proc. 2018 EMNLP workshop BlackboxNLP: Analyzing and interpreting neural networks for NLP , 2018, pp. 353 –355. doi: 10.18653/v1/W18- 5446
-
[22]
Language through a prism: A spectral approach for multiscale language representations,
A. Tamkin, D. Jurafsky, and N. Goodman, “Language through a prism: A spectral approach for multiscale language representations,” in Advances in Neural Information Processing Systems, Curran Associates, Inc., 2020, pp. 5492 –5504. Accessed: Oct. 24, 2025. [Online]. Available: https://proceedings.neurips.cc/paper_files/paper/2020/hash/3acb2a202ae4bea8840224...
2020
-
[23]
Accelerating the nonuniform fast fourier transform,
L. Greengard and J.-Y. Lee, “Accelerating the nonuniform fast fourier transform,” SIAM Rev., vol. 46, no. 3, pp. 443–454, 2004, doi: 10.1137/S003614450343200X
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.