Quantifying and Defending against the Privacy Risk in Logit-based Federated Learning
Pith reviewed 2026-06-27 19:15 UTC · model grok-4.3
The pith
A semi-honest server in logit-based federated learning can steal clients' private models from transmitted logits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that logit-based FL carries an inherent privacy risk because historical logits enable an adaptive model stealing attack that recovers private client models, with the risk persisting independently of any relation between public and private data; the authors bound this risk and show that a targeted logit perturbation defends against it.
What carries the argument
The Adaptive Model Stealing Attack (AdaMSA), which reconstructs a client's private model by adaptively combining logits transmitted over successive training rounds.
If this is right
- The privacy leakage can be bounded theoretically for any sequence of transmitted logits.
- Perturbing logits in the direction that minimizes estimated stealing risk preserves training performance.
- The attack succeeds regardless of whether public data overlaps with private data distributions.
- Logit-based FL therefore requires explicit privacy mechanisms beyond the standard federated assumption of a semi-honest server.
Where Pith is reading between the lines
- Similar output-sharing schemes in other collaborative learning settings may inherit comparable reconstruction risks.
- The defense perturbation could be tuned per round based on observed logit variance to further balance utility and privacy.
- Deployment of logit-based methods on real networks would benefit from measuring how quickly the attack converges as the number of training rounds grows.
Load-bearing premise
The server can collect and use a sequence of historical logits transmitted across training rounds to perform the adaptive model stealing attack.
What would settle it
An experiment in which the server, given the same historical logits, recovers client model parameters with accuracy no better than random guessing or a non-adaptive baseline.
Figures


read the original abstract
Federated learning aims to protect data privacy by collaboratively learning a model without sharing private data among clients. Unlike traditional parameter-based FL methods that exchange model weights or gradients during training, emerging logit-based FL approaches share model outputs (logits) on public data. This strategy promotes model heterogeneity, reduces communication overhead, and enhances clients' privacy. However, the potential privacy risks associated with these logit-based methods have been largely overlooked. This research presents the first theoretical and empirical analysis of a hidden privacy risk in logit-based FL methods - the risk that a semi-honest server (adversary) may learn clients' private models from logits. To quantify and address this threat, we develop the Adaptive Model Stealing Attack (AdaMSA) by leveraging historical logits during training. Notably, we observe that this inherent privacy risk persists even when public data is unrelated to private data, emphasizing the urgency to address privacy vulnerabilities in logit-based FL methods. Moreover, our theoretical analysis establishes the bounds of this privacy risk. We then propose a simple but effective defense strategy that perturbs the transmitted logits in the direction that minimizes the privacy risk while maximally preserving the training performance. The experimental results validate our analysis and demonstrate the effectiveness of AdaMSA and our defense strategy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to provide the first theoretical and empirical analysis of a privacy risk in logit-based federated learning: a semi-honest server can recover clients' private models via an Adaptive Model Stealing Attack (AdaMSA) that exploits historical logits transmitted over training rounds. The risk is asserted to persist even when the public data used for logits is unrelated to the clients' private data. The work derives bounds on the risk, proposes a defense that perturbs transmitted logits to reduce the risk while preserving utility, and validates both the attack and defense empirically.
Significance. If the central claims hold, the result would be significant for the design of logit-based FL systems, which are promoted precisely for reduced communication, model heterogeneity, and improved privacy. The combination of a new attack construction, theoretical risk bounds, and a lightweight defense would directly inform whether these methods can be deployed safely in privacy-sensitive settings.
major comments (2)
- [AdaMSA description (method section)] The central claim that AdaMSA can reliably recover private models rests on the server collecting and using a sequence of historical logits. Because client models are updated after each round, logits from round t are generated by a different model than those from round t+1. The manuscript must specify (in the AdaMSA construction) how the attack compensates for this non-stationarity—e.g., via incremental learning, round-specific weighting, or restriction to the final snapshot—otherwise the recovered model is trained on inconsistent output distributions and the quantified privacy risk is undermined.
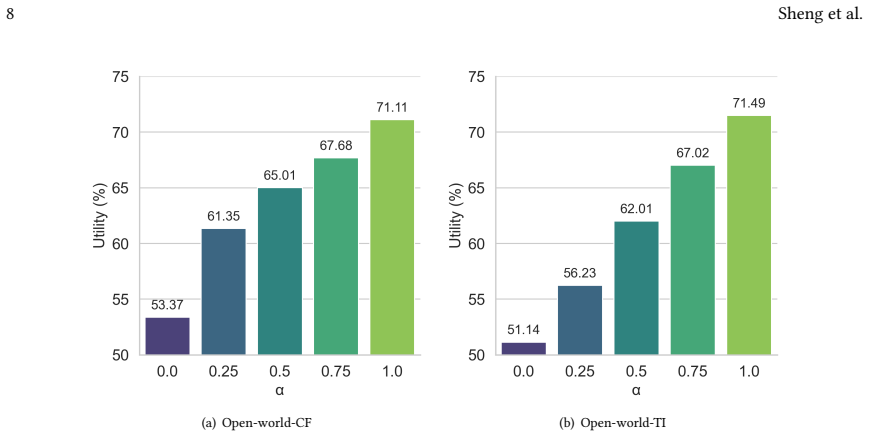
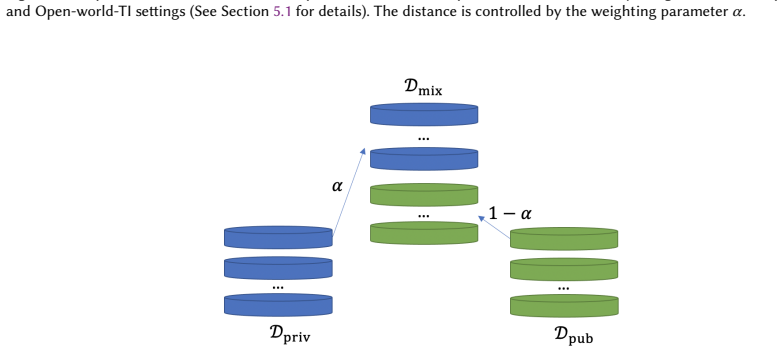
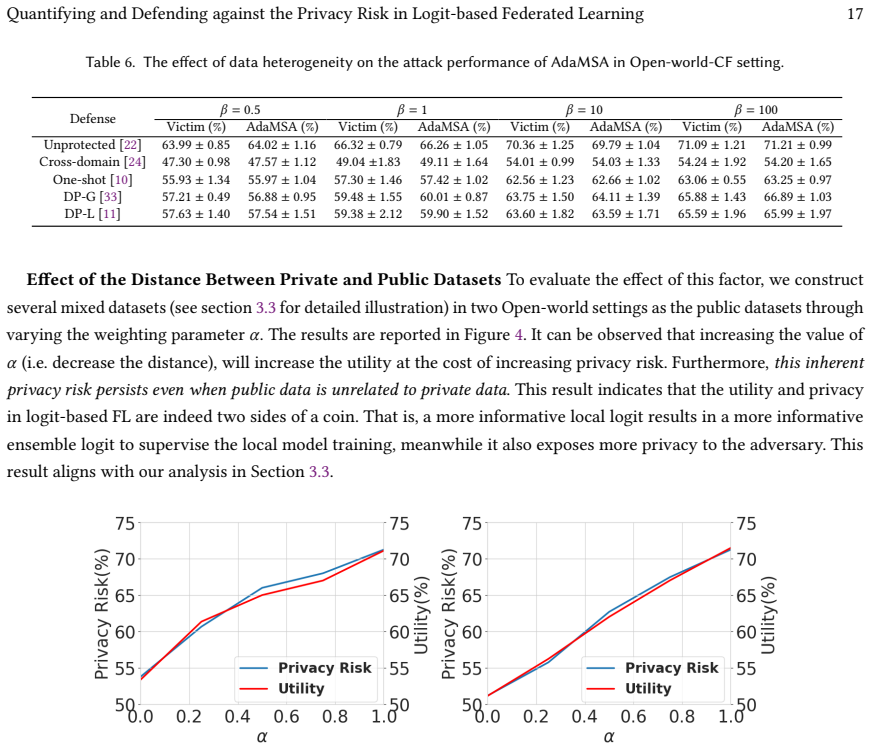
- [Experimental evaluation] The claim that the privacy risk 'persists even when public data is unrelated to private data' is load-bearing for the practical relevance of the result. The experimental section must include an explicit ablation that isolates the effect of public-data distribution shift (e.g., reporting attack success rate or recovered-model fidelity as a function of distribution distance) with the same controls used for the main results; without this, the persistence claim cannot be evaluated.
minor comments (2)
- [Theoretical analysis] Notation for the theoretical bounds should be introduced with explicit definitions of all variables before the bound statements are presented.
- [Defense strategy] The abstract states that the defense 'minimally perturbs' logits; the precise optimization objective and the hyper-parameter controlling the privacy-utility trade-off should be stated in the main text with a reference to the corresponding equation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify the AdaMSA construction and strengthen the empirical support for our claims. We address each major comment below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [AdaMSA description (method section)] The central claim that AdaMSA can reliably recover private models rests on the server collecting and using a sequence of historical logits. Because client models are updated after each round, logits from round t are generated by a different model than those from round t+1. The manuscript must specify (in the AdaMSA construction) how the attack compensates for this non-stationarity—e.g., via incremental learning, round-specific weighting, or restriction to the final snapshot—otherwise the recovered model is trained on inconsistent output distributions and the quantified privacy risk is undermined.
Authors: We agree that the current description of AdaMSA in the method section does not explicitly detail compensation for non-stationarity arising from client model updates across rounds. The manuscript emphasizes leveraging historical logits but leaves the handling of evolving output distributions implicit. In the revised version, we will expand the AdaMSA construction subsection to specify that the attack restricts training to logits from the final few rounds (where models have largely converged) combined with incremental learning on the sequence to mitigate distribution shifts. This addition will directly address the concern and ensure the quantified risk bounds apply to a consistent recovered model. revision: yes
-
Referee: [Experimental evaluation] The claim that the privacy risk 'persists even when public data is unrelated to private data' is load-bearing for the practical relevance of the result. The experimental section must include an explicit ablation that isolates the effect of public-data distribution shift (e.g., reporting attack success rate or recovered-model fidelity as a function of distribution distance) with the same controls used for the main results; without this, the persistence claim cannot be evaluated.
Authors: We acknowledge that while the manuscript reports experiments with unrelated public data and states the persistence observation, it does not include an explicit ablation plotting attack success or fidelity against a quantified measure of distribution shift (e.g., Wasserstein distance or domain discrepancy) under the same controls. We will add this ablation study to the experimental section in the revision, using the same evaluation metrics and settings as the main results, to provide direct empirical support for the claim. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper introduces AdaMSA as a new attack leveraging historical logits and proposes a defense with theoretical bounds on privacy risk, all formulated directly from the stated threat model of a semi-honest server in logit-based FL. No equations or claims reduce by construction to fitted parameters, self-citations, or prior ansatzes from the authors; the central results (attack construction, risk persistence with unrelated data, and defense) are presented as independent contributions without load-bearing self-references or renaming of known results. The provided abstract and description contain no self-definitional steps or fitted-input predictions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Martin Abadi, Andy Chu, Ian Goodfellow, H Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. 2016. Deep learning with differential privacy. InProceedings of the 2016 ACM SIGSAC conference on computer and communications security. 308–318
2016
- [2]
-
[3]
Zeyuan Allen-Zhu and Yuanzhi Li. 2023. Towards Understanding Ensemble, Knowledge Distillation and Self-Distillation in Deep Learning. InThe Eleventh International Conference on Learning Representations. https://openreview.net/forum?id=Uuf2q9TfXGA
2023
-
[4]
John Blitzer, Koby Crammer, Alex Kulesza, Fernando Pereira, and Jennifer Wortman. 2007. Learning bounds for domain adaptation.NeurIPS20 (2007)
2007
-
[5]
Gregory Cohen, Saeed Afshar, Jonathan Tapson, and Andre Van Schaik. 2017. EMNIST: Extending MNIST to handwritten letters. InIJCNN. IEEE, 2921–2926
2017
-
[6]
Koby Crammer, Michael Kearns, and Jennifer Wortman. 2008. Learning from Multiple Sources.JMLR9, 8 (2008)
2008
-
[7]
Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam Smith. 2006. Calibrating noise to sensitivity in private data analysis. InTheory of Cryptography: Third Theory of Cryptography Conference. Springer, 265–284
2006
-
[8]
Cynthia Dwork, Aaron Roth, et al. 2014. The algorithmic foundations of differential privacy.Foundations and Trends®in Theoretical Computer Science9, 3–4 (2014), 211–407
2014
-
[9]
Jonas Geiping, Hartmut Bauermeister, Hannah Dröge, and Michael Moeller. 2020. Inverting gradients-how easy is it to break privacy in federated learning?NeurIPS33 (2020), 16937–16947
2020
-
[10]
Xuan Gong et al. 2021. Ensemble attention distillation for privacy-preserving federated learning. InICCV. 15076–15086
2021
-
[11]
Xuan Gong et al. 2022. Preserving privacy in federated learning with ensemble cross-domain knowledge distillation. InAAAI, Vol. 36. 11891–11899
2022
-
[12]
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531(2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[13]
Tzu-Ming Harry Hsu, Hang Qi, and Matthew Brown. 2019. Measuring the effects of non-identical data distribution for federated visual classification. arXiv preprint arXiv:1909.06335(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [14]
-
[15]
Peter Kairouz, H Brendan McMahan, Brendan Avent, Aurélien Bellet, Mehdi Bennis, Arjun Nitin Bhagoji, Kallista Bonawitz, Zachary Charles, et al
- [16]
-
[17]
Sai Praneeth Karimireddy, Satyen Kale, Mehryar Mohri, Sashank Reddi, Sebastian Stich, and Ananda Theertha Suresh. 2020. SCAFFOLD: Stochastic Controlled Averaging for Federated Learning. InICML (PMLR, Vol. 119). PMLR, 5132–5143. https://proceedings.mlr.press/v119/karimireddy20a.html Manuscript submitted to ACM 20 Sheng et al
2020
-
[18]
Alex Krizhevsky et al. 2009. Learning multiple layers of features from tiny images. (2009)
2009
-
[19]
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. 2017. Imagenet classification with deep convolutional neural networks.Commun. ACM60, 6 (2017), 84–90
2017
-
[20]
Ya Le and Xuan Yang. 2015. Tiny imagenet visual recognition challenge.CS 231N7, 7 (2015), 3
2015
-
[21]
Yann LeCun, Bernhard Boser, John Denker, Donnie Henderson, Richard Howard, Wayne Hubbard, and Lawrence Jackel. 1989. Handwritten digit recognition with a back-propagation network.Advances in neural information processing systems2 (1989)
1989
-
[22]
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. 1998. Gradient-based learning applied to document recognition.Proc. IEEE86, 11 (1998), 2278–2324
1998
- [23]
- [24]
-
[25]
Tao Lin et al. 2020. Ensemble distillation for robust model fusion in federated learning.NeurIPS33 (2020), 2351–2363
2020
-
[26]
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. 2017. Communication-efficient learning of deep networks from decentralized data. InArtificial intelligence and statistics. PMLR, 1273–1282
2017
-
[27]
Luca Melis, Congzheng Song, Emiliano De Cristofaro, and Vitaly Shmatikov. 2019. Exploiting unintended feature leakage in collaborative learning. In2019 IEEE symposium on security and privacy (SP). IEEE, 691–706
2019
-
[28]
Ilya Mironov. 2017. Rényi Differential Privacy. In2017 IEEE 30th Computer Security Foundations Symposium (CSF). 263–275. https://doi.org/10.1109/ CSF.2017.11
2017
-
[29]
Milad Nasr, Reza Shokri, and Amir Houmansadr. 2019. Comprehensive privacy analysis of deep learning: Passive and active white-box inference attacks against centralized and federated learning. In2019 IEEE symposium on security and privacy (SP). IEEE, 739–753
2019
-
[30]
Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and Andrew Y Ng. 2011. Reading digits in natural images with unsupervised feature learning. (2011)
2011
-
[31]
Kyrylo Oliinyk. 2020. First-Order Optimization (Training) Algorithms in Deep Learning. (2020)
2020
-
[32]
Tribhuvanesh Orekondy, Bernt Schiele, and Mario Fritz. 2019. Knockoff nets: Stealing functionality of black-box models. InCVPR. 4954–4963
2019
-
[33]
Nicolas Papernot, Patrick McDaniel, Ian Goodfellow, Somesh Jha, Z Berkay Celik, and Ananthram Swami. 2017. Practical black-box attacks against machine learning. InACM ASIACCS. 506–519
2017
-
[34]
Felix Sattler, Tim Korjakow, Roman Rischke, and Wojciech Samek. 2021. Fedaux: Leveraging unlabeled auxiliary data in federated learning.IEEE TNNLS(2021)
2021
-
[35]
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. 2017. Membership Inference Attacks Against Machine Learning Models. In 2017 IEEE Symposium on Security and Privacy (SP). 3–18. https://doi.org/10.1109/SP.2017.41
-
[36]
Hideaki Takahashi, Jingjing Liu, and Yang Liu. 2023. Breaching FedMD: Image Recovery via Paired-Logits Inversion Attack. InCVPR. 12198–12207
2023
-
[37]
Florian Tramèr, Fan Zhang, Ari Juels, Michael K Reiter, and Thomas Ristenpart. 2016. Stealing Machine Learning Models via Prediction APIs.. In USENIX security symposium, Vol. 16. 601–618
2016
-
[38]
Zhibo Wang et al. 2019. Beyond inferring class representatives: User-level privacy leakage from federated learning. InIEEE INFOCOM. IEEE, 2512–2520
2019
-
[39]
Ligeng Zhu, Zhijian Liu, and Song Han. 2019. Deep leakage from gradients.NeurIPS32 (2019). Received 20 May 2024 Manuscript submitted to ACM
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.