Neuro-Symbolic Injection of LTLf Constraints in Autoregressive Reinforcement Learning Policies
Pith reviewed 2026-06-27 19:22 UTC · model grok-4.3
The pith
LTLf background knowledge injected via DFA progression into transformer RL policies raises constraint satisfaction while preserving competitive returns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Compiling LTLf formulas into DFAs, representing them differentiably, and using DFA progression signals as a logic-based regularization term during training of transformer-based RL policies yields higher constraint satisfaction on safety-reachability specification suites while keeping returns competitive with vanilla baselines.
What carries the argument
Differentiable DFA progression that supplies a satisfaction signal used as a regularization term in the policy training loss.
If this is right
- Constraint satisfaction rises on combinations of safety and reachability properties compared with purely reward-driven training.
- The method applies without modification to different autoregressive transformer architectures used for offline RL.
- Return performance remains competitive, indicating the regularization does not impose a large reward penalty.
- The framework operates in the offline setting and requires only the ability to evaluate DFA progression on observed traces.
Where Pith is reading between the lines
- The same injection technique could be tested on continuous control or online RL settings where the DFA signal might interact differently with exploration.
- If the progression approximation remains faithful, the approach could extend to other finite-trace logics whose automata admit differentiable state updates.
- In safety-critical domains the method might allow specification changes at training time without retraining the base policy from scratch.
Load-bearing premise
The differentiable approximation of DFA progression supplies a faithful and unbiased satisfaction signal that can be added as regularization without distorting LTLf semantics or creating harmful optimization artifacts.
What would settle it
Training runs in which the regularized policies violate the target LTLf formulas at equal or higher rates than the vanilla baselines, or achieve materially lower returns on the same navigation tasks, would falsify the central performance claim.
Figures

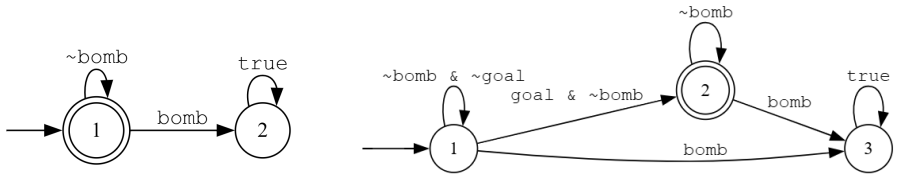



read the original abstract
In this work we study offline reinforcement learning (RL) under temporally extended task constraints expressed in Linear Temporal Logic over finite traces (LTLf). Recently, transformer-based approaches such as Trajectory Transformers and Decision Transformers have been adopted to address RL as a sequence modeling problem. However, these methods optimize purely for reward and do not account for high-level temporal requirements. Here, we introduce a neurosymbolic framework that injects LTLf background knowledge into such transformer-based RL policies. Our approach compiles LTLf formulas into deterministic finite automata (DFAs) and integrates them into the learning process through a differentiable representation and a logic-based loss function. In particular, we derive differentiable satisfaction signals from DFA progression and use them as a regularization term during training. The resulting method is architecture-agnostic across different models. We evaluate the proposed framework on navigation environments with specification suites covering combinations of safety and reachability temporal properties. Experimental results show that incorporating background knowledge not only improves constraint satisfaction, but also maintains competitive return compared to vanilla baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a neuro-symbolic framework for offline RL with LTLf constraints in transformer-based autoregressive policies (e.g., Decision Transformers). LTLf formulas are compiled to DFAs; differentiable satisfaction signals are derived from DFA progression and added as a regularization term in the training loss. The method is claimed to be architecture-agnostic. Experiments on navigation environments with safety/reachability specifications report improved constraint satisfaction while maintaining competitive returns versus vanilla baselines.
Significance. If the differentiable DFA-progression signals preserve LTLf semantics sufficiently closely, the framework would offer a practical, architecture-agnostic route to injecting temporal-logic background knowledge into sequence-modeling RL policies, addressing a gap between purely reward-driven transformers and constrained RL.
major comments (2)
- [Abstract, §3] Abstract and §3 (method description): the central claim that 'differentiable satisfaction signals derived from DFA progression' can be used as a regularization term without distorting LTLf semantics or introducing optimization artifacts rests on an unexamined approximation step. No derivation of the differentiable signal, no error bounds relative to exact DFA progression, and no formal equivalence to the original LTLf semantics are provided; this directly affects interpretability of both the satisfaction and return results.
- [Experiments] Experimental section (results and ablations): the headline result (improved constraint satisfaction at competitive return) lacks an ablation isolating the effect of the differentiable surrogate versus exact progression or versus a non-differentiable baseline. Without this, it is impossible to rule out that reported gains are artifacts of the surrogate loss rather than faithful background-knowledge injection.
minor comments (2)
- [§3] Notation for DFA states and progression function is introduced without a compact reference table; readers must cross-reference the compilation step with the loss definition.
- [Abstract, §4] The claim of being 'architecture-agnostic' is stated but only demonstrated on one transformer variant; a brief note on applicability to other autoregressive models would strengthen the presentation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. Below we respond point-by-point to the major comments, indicating revisions that will be incorporated to address the concerns raised.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (method description): the central claim that 'differentiable satisfaction signals derived from DFA progression' can be used as a regularization term without distorting LTLf semantics or introducing optimization artifacts rests on an unexamined approximation step. No derivation of the differentiable signal, no error bounds relative to exact DFA progression, and no formal equivalence to the original LTLf semantics are provided; this directly affects interpretability of both the satisfaction and return results.
Authors: We thank the referee for this observation. Section 3 does describe the compilation of LTLf formulas to DFAs and the construction of differentiable satisfaction signals via DFA progression for use in the regularization loss. However, we agree that the manuscript would benefit from a more explicit derivation, discussion of approximation properties, and analysis of how the signals relate to exact LTLf semantics. In the revision we will expand §3 with these details, including a qualitative discussion of potential distortion and optimization effects, to improve interpretability. revision: yes
-
Referee: [Experiments] Experimental section (results and ablations): the headline result (improved constraint satisfaction at competitive return) lacks an ablation isolating the effect of the differentiable surrogate versus exact progression or versus a non-differentiable baseline. Without this, it is impossible to rule out that reported gains are artifacts of the surrogate loss rather than faithful background-knowledge injection.
Authors: We acknowledge the value of such an ablation for isolating the contribution of the differentiable surrogate. The current experiments compare against vanilla baselines on navigation tasks, but do not include an explicit comparison to exact (non-differentiable) progression or a non-differentiable baseline. In the revised manuscript we will add an ablation study that directly compares the differentiable loss against a non-differentiable counterpart where feasible, and we will clarify in the text why exact progression cannot be used directly in gradient-based training of the autoregressive policy. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's method compiles LTLf formulas to DFAs (an external step) and adds a differentiable satisfaction signal as a regularization loss term during training. No equations reduce a claimed prediction or result to a fitted parameter or self-defined quantity by construction. No load-bearing self-citations, uniqueness theorems from the authors, or ansatzes smuggled via prior work are present in the provided text. Experimental claims compare against vanilla baselines on navigation tasks and do not rely on internal redefinitions of the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LTLf formulas can be compiled into equivalent deterministic finite automata whose progression semantics can be approximated differentiably.
Reference graph
Works this paper leans on
-
[1]
R. S. Sutton, A. G. Barto, et al., Reinforcement learning: An introduction, volume 1, MIT press Cambridge, 1998
1998
-
[2]
A. Kushwaha, K. Ravish, P. Lamba, P. Kumar, A survey of safe reinforcement learning and constrained mdps: A technical survey on single-agent and multi-agent safety, CoRR abs/2505.17342 (2025). URL: https://doi.org/10.48550/arXiv.2505.17342. doi: 10.48550/ARXIV. 2505.17342.arXiv:2505.17342
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.17342 2025
-
[3]
R. F. Prudencio, M. R. O. A. Máximo, E. L. Colombini, A survey on offline reinforcement learning: Taxonomy, review, and open problems, IEEE Trans. Neural Networks Learn. Syst. 35 (2024) 10237– 10257. URL: https://doi.org/10.1109/TNNLS.2023.3250269. doi:10.1109/TNNLS.2023.3250269
-
[4]
E. H.-D. Le Court, F. Belardinelli, A. W. Goodall, Probabilistic shielding for safe reinforcement learning, in: Proceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence and Fifteenth Symposium on Educational Advances in Artificial Intelligence, AAAI Press, 2025
2025
-
[5]
Janner, Q
M. Janner, Q. Li, S. Levine, Offline reinforcement learning as one big sequence modeling problem, in: M. Ranzato, A. Beygelzimer, Y. N. Dauphin, P. Liang, J. W. Vaughan (Eds.), Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, 2021, pp. 1273–1286
2021
-
[6]
L. Chen, K. Lu, A. Rajeswaran, K. Lee, A. Grover, M. Laskin, P. Abbeel, A. Srinivas, I. Mordatch, Decision transformer: reinforcement learning via sequence modeling, in: Proceedings of the 35th International Conference on Neural Information Processing Systems, NIPS ’21, Curran Associates Inc., Red Hook, NY, USA, 2021
2021
-
[7]
Umili, G
E. Umili, G. P. Licks, F. Patrizi, Enhancing deep sequence generation with logical temporal knowledge, in: Proceedings of the 3rd International Workshop on Process Management in the AI Era (PMAI 2024) co-located with 27th European Conference on Artificial Intelligence (ECAI 2024), Santiago de Compostela, Spain, October 19, 2024, 2024, pp. 23–34. URL: http...
2024
-
[8]
A. Mezini, E. Umili, I. Donadello, F. M. Maggi, M. Mancanelli, F. Patrizi, Neuro-symbolic predictive process monitoring, arXiv preprint arXiv:2509.00834 (2025)
Pith/arXiv arXiv 2025
-
[9]
De Giacomo, M
G. De Giacomo, M. Y. Vardi, Linear temporal logic and linear dynamic logic on finite traces, in: F. Rossi (Ed.), IJCAI 2013, Proceedings of the 23rd International Joint Conference on Artificial Intelligence, Beijing, China, August 3-9, 2013, IJCAI/AAAI, 2013, pp. 854–860. URL: http://www. aaai.org/ocs/index.php/IJCAI/IJCAI13/paper/view/6997
2013
-
[10]
A. Pnueli, The temporal logic of programs, in: 18th Annual Symposium on Foundations of Computer Science, Providence, Rhode Island, USA, 31 October - 1 November 1977, IEEE Computer Society, 1977, pp. 46–57. URL: https://doi.org/10.1109/SFCS.1977.32. doi:10.1109/SFCS.1977. 32
-
[11]
Kumar, A
A. Kumar, A. Zhou, G. Tucker, S. Levine, Conservative q-learning for offline reinforcement learning, Advances in neural information processing systems 33 (2020) 1179–1191
2020
-
[12]
Rama-Maneiro, F
E. Rama-Maneiro, F. Patrizi, J. C. Vidal, M. Lama, Towards learning the optimal sampling strategy for suffix prediction in predictive monitoring, in: G. Guizzardi, F. M. Santoro, H. Mouratidis, P. Soffer (Eds.), Advanced Information Systems Engineering - 36th International Conference, CAiSE 2024, Limassol, Cyprus, June 3-7, 2024, Proceedings, volume 14663...
2024
-
[13]
I. Kostrikov, A. Nair, S. Levine, Offline reinforcement learning with implicit q-learning, arXiv preprint arXiv:2110.06169 (2021)
Pith/arXiv arXiv 2021
-
[14]
A. V. Nair, V. Pong, M. Dalal, S. Bahl, S. Lin, S. Levine, Visual reinforcement learning with imagined goals, Advances in neural information processing systems 31 (2018)
2018
-
[15]
Y. Ding, C. Florensa, P. Abbeel, M. Phielipp, Goal-conditioned imitation learning, Advances in neural information processing systems 32 (2019)
2019
- [16]
-
[17]
R. K. Srivastava, P. Shyam, F. Mutz, W. Jaśkowski, J. Schmidhuber, Training agents using upside- down reinforcement learning, arXiv preprint arXiv:1912.02877 (2019)
arXiv 1912
- [18]
-
[19]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, I. Polosukhin, Attention is all you need, in: I. Guyon, U. von Luxburg, S. Bengio, H. M. Wallach, R. Fergus, S. V. N. Vishwanathan, R. Garnett (Eds.), Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Dece...
2017
-
[20]
Yamagata, A
T. Yamagata, A. Khalil, R. Santos-Rodriguez, Q-learning decision transformer: Leveraging dynamic programming for conditional sequence modelling in offline rl, in: International Conference on Machine Learning, PMLR, 2023, pp. 38989–39007
2023
-
[21]
Zheng, A
Q. Zheng, A. Zhang, A. Grover, Online decision transformer, in: international conference on machine learning, PMLR, 2022, pp. 27042–27059
2022
-
[22]
M. Xu, Y. Shen, S. Zhang, Y. Lu, D. Zhao, J. Tenenbaum, C. Gan, Prompting decision transformer for few-shot policy generalization, in: international conference on machine learning, PMLR, 2022, pp. 24631–24645
2022
-
[23]
Badrinath, Y
A. Badrinath, Y. Flet-Berliac, A. Nie, E. Brunskill, Waypoint transformer: Reinforcement learning via supervised learning with intermediate targets, Advances in Neural Information Processing Systems 36 (2023) 78006–78027
2023
-
[24]
Huang, Y
R. Huang, Y. Pei, G. Wang, Y. Zhang, Y. Yang, P. Wang, H. Shen, Diffusion models as optimizers for efficient planning in offline rl, in: European Conference on Computer Vision, Springer, 2024, pp. 1–17
2024
-
[25]
Achiam, D
J. Achiam, D. Held, A. Tamar, P. Abbeel, Constrained policy optimization, in: International conference on machine learning, Pmlr, 2017, pp. 22–31
2017
-
[26]
C. Tessler, D. J. Mankowitz, S. Mannor, Reward constrained policy optimization, arXiv preprint arXiv:1805.11074 (2018)
Pith/arXiv arXiv 2018
-
[27]
H. Xu, X. Zhan, X. Zhu, Constraints penalized q-learning for safe offline reinforcement learning, in: Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, 2022, pp. 8753–8760
2022
- [28]
-
[29]
Z. Liu, Z. Guo, Y. Yao, Z. Cen, W. Yu, T. Zhang, D. Zhao, Constrained decision transformer for offline safe reinforcement learning, in: International conference on machine learning, PMLR, 2023, pp. 21611–21630
2023
-
[30]
R. Wang, D. Zhou, Safe decision transformer with learning-based constraints, in: Neurips Safe Generative AI Workshop 2024, 2024
2024
-
[31]
Z. Guo, W. Zhou, W. Li, Temporal logic specification-conditioned decision transformer for offline safe reinforcement learning, arXiv preprint arXiv:2402.17217 (2024)
arXiv 2024
- [32]
-
[33]
D. Tian, H. Fang, Q. Yang, H. Yu, W. Liang, Y. Wu, Reinforcement learning under temporal logic constraints as a sequence modeling problem, Robotics and Autonomous Systems 161 (2023) 104351
2023
-
[34]
Alshiekh, R
M. Alshiekh, R. Bloem, R. Ehlers, B. Könighofer, S. Niekum, U. Topcu, Safe reinforcement learning via shielding, in: Proceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
- [35]
-
[36]
Belardinelli, A
F. Belardinelli, A. W. Goodall, et al., Probabilistic shielding for safe reinforcement learning, in: Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, 2025, pp. 16091–16099
2025
-
[37]
M. Ma, J. Gao, L. Feng, J. A. Stankovic, STLnet: Signal temporal logic enforced multivariate recurrent neural networks, in: H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, H. Lin (Eds.), Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, 2020....
2020
-
[38]
C. D. Francescomarino, C. Ghidini, F. M. Maggi, G. Petrucci, A. Yeshchenko, An eye into the future: Leveraging a-priori knowledge in predictive business process monitoring, in: J. Carmona, G. Engels, A. Kumar (Eds.), Business Process Management - 15th International Conference, BPM 2017, Barcelona, Spain, September 10-15, 2017, Proceedings, volume 10445 of...
-
[39]
Equivariant relative submajorization
V. Collura, K. Tit, L. Bussi, E. Giunchiglia, M. Cordy, TRIDENT: temporally restricted inference via dfa-enhanced neural traversal, CoRR abs/2506.09701 (2025). URL: https://doi.org/10.48550/arXiv. 2506.09701. doi:10.48550/ARXIV.2506.09701.arXiv:2506.09701
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[40]
X. Lu, P. West, R. Zellers, R. Le Bras, C. Bhagavatula, Y. Choi, NeuroLogic decoding: (un)supervised neural text generation with predicate logic constraints, in: K. Toutanova, A. Rumshisky, L. Zettle- moyer, D. Hakkani-Tur, I. Beltagy, S. Bethard, R. Cotterell, T. Chakraborty, Y. Zhou (Eds.), Proceedings of the 2021 Conference of the North American Chapte...
-
[41]
X. Lu, S. Welleck, P. West, L. Jiang, J. Kasai, D. Khashabi, R. Le Bras, L. Qin, Y. Yu, R. Zellers, N. A. Smith, Y. Choi, NeuroLogic A*esque decoding: Constrained text generation with lookahead heuristics, in: M. Carpuat, M.-C. de Marneffe, I. V. Meza Ruiz (Eds.), Proceedings of the 2022 Conference of the North American Chapter of the Association for Comp...
-
[42]
N. Miao, H. Zhou, L. Mou, R. Yan, L. Li, CGMH: constrained sentence generation by metropolis- hastings sampling, in: Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence and Thirty-First Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Symposium on Educational Advances in Artificial Intelligence, AAAI’19/I...
-
[43]
Loula, B
J. Loula, B. LeBrun, L. Du, B. Lipkin, C. Pasti, G. Grand, T. Liu, Y. Emara, M. Freedman, J. Eisner, R. Cotterell, V. Mansinghka, A. K. Lew, T. Vieira, T. J. O’Donnell, Syntactic and semantic control of large language models via sequential monte carlo, in: The Thirteenth International Conference on Learning Representations, 2025. URL: https://openreview.n...
2025
-
[44]
Ahmed, K.-W
K. Ahmed, K.-W. Chang, G. V. den Broeck, A pseudo-semantic loss for autoregressive models with logical constraints, in: Thirty-seventh Conference on Neural Information Processing Systems,
-
[45]
URL: https://openreview.net/forum?id=hVAla2O73O
-
[46]
G e D i: G enerative D iscriminator G uided S equence G eneration
B. Krause, A. D. Gotmare, B. McCann, N. S. Keskar, S. Joty, R. Socher, N. F. Rajani, GeDi: Generative discriminator guided sequence generation, in: M.-F. Moens, X. Huang, L. Specia, S. W.-t. Yih (Eds.), Findings of the Association for Computational Linguistics: EMNLP 2021, Association for Computational Linguistics, Punta Cana, Dominican Republic, 2021, pp...
-
[47]
Zhang, P
H. Zhang, P. Kung, M. Yoshida, G. V. den Broeck, N. Peng, Adaptable logical control for large language models, in: A. Globersons, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. M. Tomczak, C. Zhang (Eds.), Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Cana...
2024
-
[48]
E. Umili, R. Capobianco, Deepdfa: Automata learning through neural probabilistic relaxations, in: ECAI 2024 - 27th European Conference on Artificial Intelligence, 19-24 October 2024, Santiago de Compostela, Spain - Including 13th Conference on Prestigious Applications of Intelligent Systems (PAIS 2024), 2024, pp. 1051–1058. URL: https://doi.org/10.3233/FA...
-
[49]
F. Fuggitti, LTLf2DFA, 2019. URL: https://doi.org/10.5281/zenodo.3888410. doi:10.5281/zenodo. 3888410
-
[50]
E. Umili, R. Capobianco, G. De Giacomo, Grounding ltlf specifications in image sequences, in: Proceedings of the 20th International Conference on Principles of Knowledge Representation and Reasoning, KR 2023, Rhodes, Greece, September 2-8, 2023, 2023, pp. 668–678. URL: https: //doi.org/10.24963/kr.2023/65. doi:10.24963/KR.2023/65
-
[51]
I. Donadello, P. Felli, C. Innes, F. M. Maggi, M. Montali, LTL-based conformance checking of fuzzy event logs, Process Science 2 (2025). doi:10.1007/S44311-025-00020-W
-
[52]
N. Manginas, G. Paliouras, L. D. Raedt, Nesya: Neurosymbolic automata, in: Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, IJCAI 2025, Montreal, Canada, August 16-22, 2025, ijcai.org, 2025, pp. 5950–5958. doi:10.24963/IJCAI.2025/662
-
[53]
M. Pesic, W. M. P. van der Aalst, A declarative approach for flexible business processes management, in: J. Eder, S. Dustdar (Eds.), Business Process Management Workshops, BPM 2006 International Workshops, BPD, BPI, ENEI, GPWW, DPM, semantics4ws, Vienna, Austria, September 4-7, 2006, Proceedings, volume 4103 ofLecture Notes in Computer Science, Springer, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.