CoVEBench: Can Video Editing Models Handle Complex Instructions?
Pith reviewed 2026-06-27 19:01 UTC · model grok-4.3
The pith
Current video editing models frequently fail at instructions that require several edits at once while preserving unrelated content.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
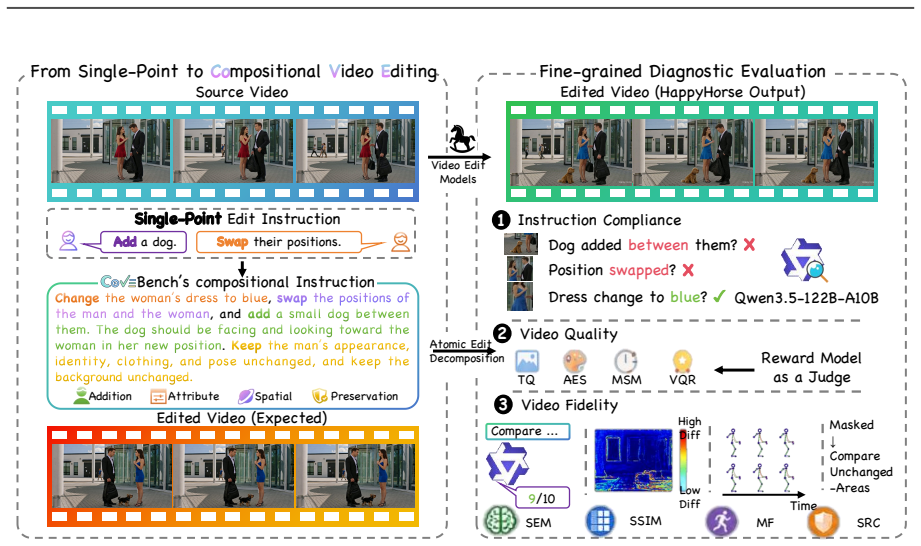
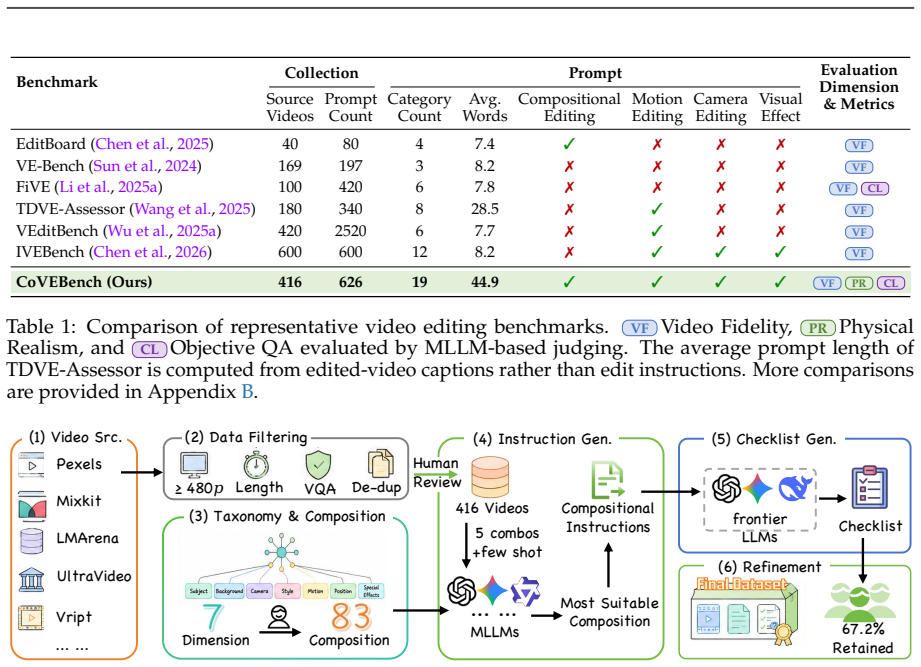
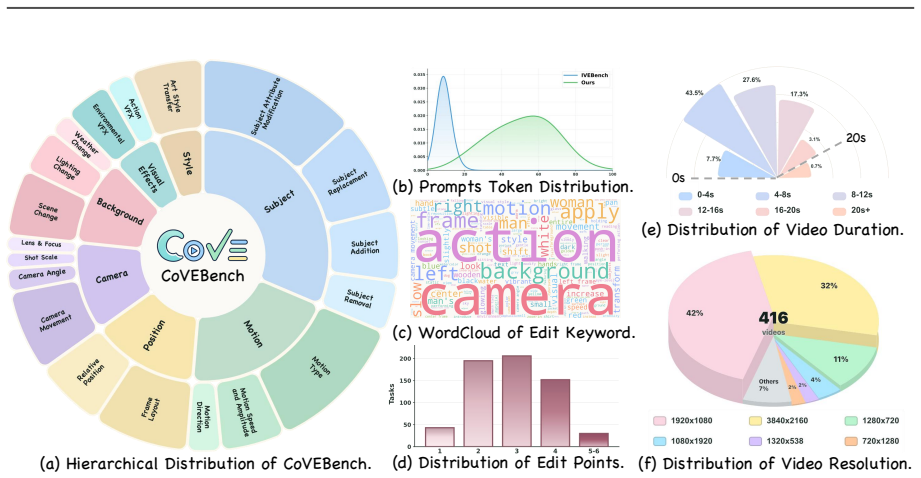
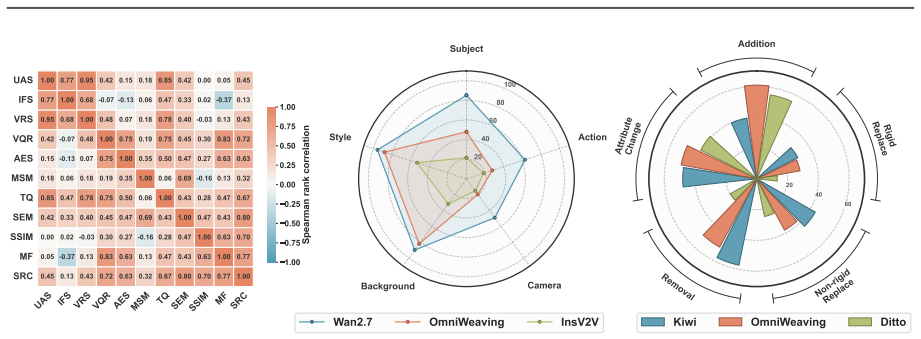
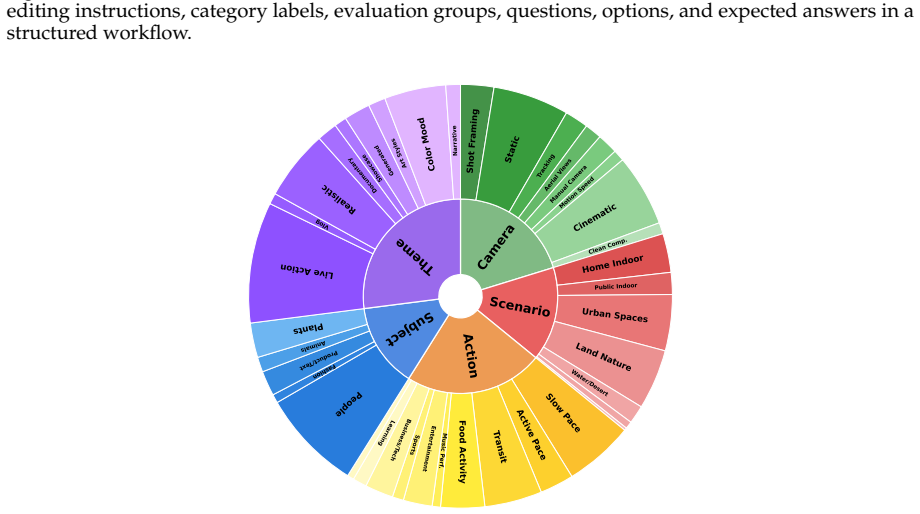
Compositional editing remains a profound challenge: current models frequently omit edits, violate preservation constraints, or introduce artifacts when handling multiple operations simultaneously. CoVEBench supplies a diagnostic testbed of 416 curated videos, 626 multi-point instructions, and 9,990 checklist items that measures performance through MLLM-based compliance and fidelity scores together with automated video-quality metrics.
What carries the argument
CoVEBench, the benchmark consisting of source videos, multi-point editing instructions, and fine-grained checklists scored by MLLM judgments of compliance and fidelity.
If this is right
- Video editing models require new mechanisms to track and execute multiple simultaneous edits without omissions.
- Future benchmarks must move beyond isolated single-edit tests to compositional multi-operation workflows.
- Evaluation protocols should combine MLLM checklist scoring with automated fidelity metrics to diagnose specific failure modes.
- Progress on CoVEBench would indicate models are closer to handling the coupled edits common in real user requests.
Where Pith is reading between the lines
- If models improve on the benchmark, downstream applications such as AI video assistants could handle more realistic user workflows without manual correction.
- The checklist approach could be adapted to other generative tasks that involve preserving large portions of an input while applying targeted changes.
- Extending the benchmark to longer videos or overlapping temporal edits would test whether current failure modes scale with sequence length.
Load-bearing premise
That MLLM-based judgments of instruction compliance and video fidelity serve as reliable and unbiased proxies for human assessment of editing success.
What would settle it
A side-by-side comparison in which human raters score the same set of edited videos that the MLLM judged, with large systematic disagreement indicating the benchmark evaluations are unreliable.
Figures



read the original abstract
While recent text-guided video editing models excel at elementary tasks (e.g., style transfer, object insertion), real-world user requests are highly compositional. A single prompt often demands multiple coupled edits, such as modifying subjects, actions, and camera views, while strictly preserving unrelated spatiotemporal content. Existing benchmarks, heavily constrained by isolated edits and coarse global metrics, fail to diagnose how models handle such complex workflows. To address this gap, we introduce CoVEBench, a compositional video editing benchmark comprising 416 curated source videos, 626 multi-point editing instructions, and 9,990 fine-grained checklist items. Covering diverse editing dimensions, CoVEBench evaluates models via MLLM-judged instruction compliance and video fidelity, alongside automated metrics for video quality. Extensive experiments reveal that compositional editing remains a profound challenge: current models frequently omit edits, violate preservation constraints, or introduce artifacts when handling multiple operations simultaneously. CoVEBench provides a challenging, diagnostic testbed to advance video editing toward realistic user workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CoVEBench, a compositional video editing benchmark with 416 curated source videos, 626 multi-point editing instructions, and 9,990 fine-grained checklist items. It evaluates text-guided video editing models on complex, multi-operation prompts using MLLM-judged instruction compliance and video fidelity (plus automated quality metrics), claiming that current models frequently omit edits, violate preservation constraints, or introduce artifacts when handling simultaneous operations.
Significance. If the MLLM-based evaluation protocol proves reliable, the benchmark would usefully diagnose limitations in handling realistic compositional workflows that existing isolated-edit benchmarks overlook. The curation of source videos, instructions, and checklist items constitutes a concrete resource contribution.
major comments (2)
- [Abstract and evaluation protocol] Abstract and §4 (evaluation protocol): the central claim that models 'frequently omit edits, violate preservation constraints, or introduce artifacts' is supported solely by MLLM judgments on the 9,990 checklist items; no inter-annotator agreement, human-MLLM correlation, calibration on held-out edits, or bias controls are reported.
- [§4 (experiments)] §4 (experiments): no statistical significance tests or confidence intervals are provided for the reported failure rates across models or editing dimensions, making it impossible to assess whether observed differences are reliable.
minor comments (1)
- [§4] The description of automated video quality metrics is brief; a short table or paragraph clarifying which metrics (e.g., FVD, CLIP similarity) are used and how they complement MLLM judgments would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation protocol and statistical reporting. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract and evaluation protocol] Abstract and §4 (evaluation protocol): the central claim that models 'frequently omit edits, violate preservation constraints, or introduce artifacts' is supported solely by MLLM judgments on the 9,990 checklist items; no inter-annotator agreement, human-MLLM correlation, calibration on held-out edits, or bias controls are reported.
Authors: We acknowledge that the manuscript does not report inter-annotator agreement, human-MLLM correlation, calibration studies, or explicit bias controls for the MLLM judgments. To strengthen the claims, we will add a human evaluation on a representative subset of checklist items (reporting agreement metrics and correlation) and discuss bias mitigation steps in the revised version. revision: yes
-
Referee: [§4 (experiments)] §4 (experiments): no statistical significance tests or confidence intervals are provided for the reported failure rates across models or editing dimensions, making it impossible to assess whether observed differences are reliable.
Authors: We agree that the lack of statistical tests and confidence intervals limits interpretability of the differences. We will incorporate bootstrap confidence intervals and appropriate significance tests (e.g., McNemar or Wilcoxon) for the failure rates and model comparisons in the revised experiments section. revision: yes
Circularity Check
No derivation chain or self-referential reduction present
full rationale
This is a benchmark release paper whose central claims are empirical observations from running existing video editing models on a newly curated dataset of 416 videos and 626 instructions, scored via MLLM judgments and automated metrics. The abstract and provided text contain no equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations that reduce the reported failure rates to the benchmark construction itself. The evaluation protocol is external (MLLM-based) rather than self-definitional, and no uniqueness theorems or ansatzes are invoked. This matches the default case of a self-contained empirical benchmark with no circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL https://lf3-static.bytednsdoc.com/obj/eden-cn/lapzild-tss/ljhwZthlaukjlkulzlp/r esearch/Seed-1.8-Modelcard.pdf. Zhe Cao, Tao Wang, Jiaming Wang, Yanghai Wang, Yuanxing Zhang, Jialu Chen, Miao Deng, Jiahao Wang, Yubin Guo, Chenxi Liao, Yize Zhang, Zhaoxiang Zhang, and Jiaheng Liu. T2av-compass: Towards unified evaluation for text-to-audio-video generat...
Pith/arXiv arXiv 2026
-
[2]
TokenFlow: Consistent Diffusion Features for Consistent Video Editing
SigLIP-based aesthetic score predictor. Accessed: 2026-05-15. Rinon Gal, Or Patashnik, Haggai Maron, Amit H. Bermano, Gal Chechik, and Daniel Cohen-Or. Stylegan- nada.ACM Transactions on Graphics (TOG), 41:1 – 13, 2021. URL https://api.semanticscholar.org/ CorpusID:236772156. Michal Geyer, Omer Bar-Tal, Shai Bagon, and Tali Dekel. Tokenflow: Consistent di...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/iccv51701.2025.005 2026
-
[3]
Image quality as- sessment: from error visibility to structural similarity
URLhttps://api.semanticscholar.org/CorpusID:278905042. Xiang Wang, Hangjie Yuan, Shiwei Zhang, Dayou Chen, Jiuniu Wang, Yingya Zhang, Yujun Shen, Deli Zhao, and Jingren Zhou. Videocomposer: Compositional video synthesis with motion controllability. ArXiv, abs/2306.02018, 2023. URLhttps://api.semanticscholar.org/CorpusID:259075720. 11 Zhou Wang, A.C. Bovik...
work page doi:10.1109/tip 2023
-
[4]
In Video B, are there exactly three glass cups present on the espresso machine’s tray? Correct Answer:Yes
-
[5]
In Video B, are these three cups arranged in a row? Correct Answer:Yes
-
[6]
In Video B, are all of the cups double-layered (double-walled) glasses? Correct Answer:Yes
-
[7]
In Video B, are any of the cups suspended in mid-air or severely blurred? Correct Answer:No Espresso Liquid and Crema
-
[8]
In Video B, are the two side cups filled with dark espresso? Correct Answer:Yes
-
[9]
In Video B, is there a visible layer of crema on the surface of the coffee in both side cups? Correct Answer:Yes
-
[10]
In Video B, does the coffee liquid in the two side cups remain stable when no coffee is being poured into them? Correct Answer:Yes
-
[11]
In Video B, as the espresso machine continues pouring liquid into the middle cup, is there a phenomenon where the cup is completely full but the coffee liquid does not overflow? Correct Answer:No
-
[12]
In Video B, does the coffee liquid flowing into the middle cup appear distorted or fall unnaturally? Correct Answer:No Background Color
-
[13]
White background; B
In Video B, what is the color of the background? Options:A. White background; B. Black background. Correct Answer:A Preservation of Original Elements
-
[14]
Comparing Video A and Video B, how accurately are the two streams of espresso pouring into the center cup preserved? Correct Answer:10
-
[15]
Comparing Video A and Video B, how well is the static camera framing and medium close-up shot preserved? Correct Answer:10
-
[16]
Addition and Placement of Side Cups
Comparing Video A and Video B, how well is the silver espresso machine’s appearance and metallic texture preserved? Correct Answer:10 Figure 7: Representative dataset sample. The images display frames sampled from the original video, and the text box below presents a complete example of the corresponding evaluation checklist. 15 Figure 8: Annotation inter...
2024
-
[17]
Return a single valid JSON object
JSON OUTPUT ONLY. Return a single valid JSON object. No extra text, no markdown formatting outside the JSON block
-
[18]
original_description
SCENE DESCRIPTION. The "original_description" must clearly describe the source video: main subjects (people / objects / animals), their specific actions and facial expressions, the environment and lighting, relative spatial layout, and camera framing
-
[19]
replace the cat with a dog
COMBINATION SELECTION (Mandatory). You will be provided with 5 candidate combinations below, each specifying 2-4 fine- grained editing operations. Select the ONE combination that best suits the source video scene, and instantiate the corresponding atomic edits into a single cohesive instruction. On average the final instruction should specify around 4 ato...
-
[20]
Editing Instruction
Analyze the "Editing Instruction" carefully
-
[21]
Change background to a bamboo forest with sunlight beams
If the instruction is "Change background to a bamboo forest with sunlight beams": - "Bamboo forest" -> Background & Environment - "Sunlight beams" -> Background & Environment (Lighting) - Result: ["Background & Environment"] (Do NOT include Camera)
-
[22]
Zoom in on the bamboo forest
If the instruction is "Zoom in on the bamboo forest": - "Zoom in" -> Camera - Result: ["Camera"]. ## Output Format Return ONLY the JSON object. No markdown, no explanations. { "categories": ["Category1", "Category2"] } I.3 Fine-Grained Checklist Generation For each (source-video description, editing instruction) pair, we synthesize a fine-grained checklis...
-
[23]
Instantiates the Instruction Compliance top-level dimension of the paper's evaluation matrix
Execution Accuracy -- evaluates if the specific editing instruction was successfully applied. Instantiates the Instruction Compliance top-level dimension of the paper's evaluation matrix
-
[24]
Comparing Video A and Video B, does the skin on the wrist in Video B match the lighting , skin tone, and texture of the rest of the hand shown in Video A?
Physical Logic -- evaluates the internal physical consistency of Video B ONLY. Checks if Video B obeys the laws of physics on its own (accurate internal lighting, gravity, fluid dynamics, proper shadows matching the light source within Video B). Instantiates the Physical Realism metric within Video Quality. - CRITICAL RULE: Physical Logic questions MUST O...
-
[25]
Instantiates the Semantic Consistency metric within Video Fidelity
Semantic Preservation -- evaluates if the unmodified elements, background, camera motion, and original temporal dynamics are preserved. Instantiates the Semantic Consistency metric within Video Fidelity. - CRITICAL RULE: Questions under Semantic Preservation MUST EXCLUSIVELY use the Score-MCQ (1-10 scoring) format. NEVER use Dual-TF, Single-TF, or AB-MCQ ...
-
[26]
Video A Description: textual description of the scene, subjects, and actions before editing (produced by the source captioning prompt)
-
[27]
Edit Points
Editing Instruction: the specific compositional command given to the AI editor. # Task From the inputs, identify "Edit Points" (each atomic operation in the instruction) and "Preservation Points" (elements that should remain unchanged). Create a separate question group for each point. Within each group, generate a HIGH VOLUME of exhaustive and highly spec...
-
[28]
- Format: exactly two options (A and B)
A/B Multiple Choice (AB-MCQ) [Execution Accuracy] - Visibility: evaluator ONLY sees Video B. - Format: exactly two options (A and B). - Rule (Anti-Lazy): NEVER use placeholder terms for Option A. Explicitly describe the exact visual state based on Video A's description
-
[29]
Single-Video True/False (Single-TF) [Execution Accuracy / Physical Logic] - Visibility: evaluator ONLY sees Video B. - Rule (Absence Check): right after an AB-MCQ for a replaced or removed object, you MUST add a Single-TF question asking if the specific Video-A target is still visible anywhere in Video B (Expected Answer: "No")
-
[30]
Yes/No" questions beginning with
Dual-Video True/False (Dual-TF) [Execution Accuracy / Physical Logic ONLY] - Visibility: evaluator sees BOTH Video A and Video B. - Format: "Yes/No" questions beginning with "Comparing Video A and Video B...". - Example: "Comparing Video A and Video B, does the newly inserted object in Video B cast a shadow in the exact same direction as the natural light...
-
[31]
Comparing Video A and Video B
1-10 Scoring Multiple Choice (Score-MCQ) [STRICTLY for Semantic Preservation] - Visibility: evaluator sees BOTH Video A and Video B. - Format: a 1-10 scale that mirrors the runtime judge rubric: 1-2 = complete loss of identity / disappearance; 3-6 = unintended attribute inconsistency; 7-8 = structural distortion; 9-10 = perfect consistency. - Question ste...
-
[32]
Do not include markdown blocks (no```json fences)
Your output must be ONLY a valid, parsable JSON object. Do not include markdown blocks (no```json fences)
-
[33]
evaluation_groups
Group everything by target_element (one group per edit point or preservation point). 27 # JSON Output Structure Example { "evaluation_groups": [ { "target_element": "The object falling into the liquid", "description": "Evaluation of the primary object replacement and its physical interaction.", "questions": [ { "id": "Q1", "type": "AB-MCQ", "dimension": "...
-
[35]
Do not make assumptions or hallucinate
Strict Objectivity: You must remain 100% objective. Do not make assumptions or hallucinate. If you observe an action, object, or state happening in the video, you must acknowledge it truthfully
-
[36]
Tolerance for Blurry/Unclear Visuals (CRUCIAL): You must judge the presence of objects even in low-quality or unclear situations. If an option mentions an object (e.g., Object A) and you observe even a blurry outline, a phantom, a silhouette, a partial glimpse, or a shadow of that object in the video, you MUST consider it as positively visible and present...
-
[37]
A" and "B
Option Evaluation: Each question provides two main options: "A" and "B". You must evaluate both independently against the video evidence
-
[38]
A" (if only option A is factually correct/visible based on the video) -
Valid Answer Scope: Your final answer MUST be exactly one of the following three exact strings: - "A" (if only option A is factually correct/visible based on the video) - "B" (if only option B is factually correct/visible based on the video) - "A and B" (if BOTH option A and option B are simultaneously correct/visible in the video)
-
[39]
the video is unclear
Mandatory Selection (No Abstentions Allowed): You MUST provide a definitive answer for every single question. Refusing to answer, claiming "the video is unclear", stating "cannot be determined", or leaving the answer blank is STRICTLY PROHIBITED. You must make your best evidence-based judgment using the rule of blurry visuals (Rule 3) and select from the ...
-
[40]
id": "Q1
Visual Evidence ONLY (No Audio): You must completely ignore any audio, speech, or sound track present in the video. Your reasoning and final answers must be derived 100% from the visual data (pixels, frames, movement, and text on screen). # Input Format The questions will be provided to you like the following JSON array structure: [ { "id": "Q1", "questio...
-
[41]
Video Identity: The input video you are analyzing corresponds exactly to "Video B" mentioned in the questions
-
[42]
Simply observe the video and answer the question truthfully based strictly on what is visibly present
Objective Answering: You must remain objective. Simply observe the video and answer the question truthfully based strictly on what is visibly present. Do not make assumptions
-
[44]
Yes" or
Mandatory Selection: You MUST provide a definitive "Yes" or "No" for every single question. You are not allowed to skip, refuse to answer, or output "Unclear"
-
[45]
Do not be overly strict or pedantic about minor deviations from ideal physical behavior in the video
Physics Law Tolerance: When a question involves physical laws or physics-related phenomena (e.g., gravity, momentum, fluid dynamics, light behavior, etc.), you should apply a reasonable tolerance in your judgment. Do not be overly strict or pedantic about minor deviations from ideal physical behavior in the video. However, this tolerance only applies to p...
-
[46]
Do not miss or overlook any visual details
Careful & Independent Observation: You must observe the video carefully and thoroughly. Do not miss or overlook any visual details. Critically, you must evaluate the video content and the question independently -- do not let the phrasing or implication of the question bias or mislead your observation. Always look at the video first, form your own objectiv...
-
[47]
original
Original Video Context: The video you are analyzing (Video B) is the edited video. You do not have access to the original, pre-edited video. Whenever a question mentions the "original" video, you must rely solely on the textual description provided within the question itself. # Input Format The questions will be provided to you like the following JSON arr...
-
[48]
Video A", and the second video is exactly
Video Identity: You will be provided with two videos. The first video you receive is exactly "Video A", and the second video is exactly "Video B" as mentioned in the questions
-
[49]
Simply observe the visual elements, physics, and movements in both videos
Objective Comparison: You must remain objective. Simply observe the visual elements, physics, and movements in both videos. Answer the question truthfully based strictly on what is visibly present. Do not make assumptions. No audio analysis is required or allowed
-
[50]
Yes" - "No
Strict Binary Answer: Your final answer MUST be exactly one of the following two strings: - "Yes" - "No" No other words, variations, or explanations are allowed in the final answer field
-
[51]
Yes" or
Mandatory Selection: You MUST provide a definitive "Yes" or "No" for every single question. You are not allowed to skip, refuse to answer, or output "Unclear". # Input Format The questions will be provided to you like the following JSON array structure. You should focus on answering the "question" field: [ {"id": "Q11", "question": "Comparing Video A and ...
-
[52]
Your job is to judge whether it was improperly affected by the edit
Focus on Unedited Targets: The question specifically asks about a region or object that the editing instruction did NOT request to change. Your job is to judge whether it was improperly affected by the edit
-
[53]
Focus exclusively on the element mentioned in the question
Evaluate Only the Specified Target: Do not let the quality or consistency of other parts of the video influence your score. Focus exclusively on the element mentioned in the question
-
[54]
Do not speculate beyond visible evidence
Visual Evidence Only: Base your judgment solely on what is visually observable. Do not speculate beyond visible evidence. Ignore audio
-
[55]
Do not include any text outside the JSON output
Strict Output Format: Your score must be an integer from 1 to 10. Do not include any text outside the JSON output
-
[56]
id": "Q12
No Skipping: Every question must receive a score. # Input Format The questions will be provided as a JSON array: [ { "id": "Q12", "editing_instruction": "Change the weather to a snowy winter day.", "question": "Comparing Video A and Video B, how consistently is the red car parked in the background preserved?" } 31 ] # Output Format Output a strictly valid...
-
[57]
If a behavior is explicitly required or implied by the editing prompt (e.g., stylized effects, exaggerated motion, fantasy elements, magic), DO NOT count it as a physics violation
The editing prompt used to generate or modify the video You MUST use the editing prompt as context. If a behavior is explicitly required or implied by the editing prompt (e.g., stylized effects, exaggerated motion, fantasy elements, magic), DO NOT count it as a physics violation. --- **Critical Rules:**
-
[59]
You are required to observe the video with extreme attention to detail
You MUST ONLY evaluate physics-related issues. You are required to observe the video with extreme attention to detail. Strictly look for real-world physics violations, such as: - **Collisions & Clipping:** Solid objects passing through each other (clipping), lacking realistic impact/recoil, or ignoring structural boundaries. - **Gravity & Mass:** Objects ...
-
[60]
DO NOT include AI artifacts (flickering, warping, anatomical errors, sudden mutations, etc.)
-
[61]
type": "physics_evaluation
DO NOT confuse: - Physics violations = gravity errors, clipping/intersections, wrong shadows, broken inertia, material physics failures. - AI artifacts = generation/rendering errors, ghosting, anatomical instability (NOT allowed here). --- **Scoring Rules:** - Start from 10. - Deduct 1 to 2 points per distinct physics violation: - **-2 points** for SEVERE...
-
[62]
If a visual effect is explicitly required (e.g., stylized distortion, intentional morphing, surreal transformation), DO NOT count it as an artifact
The editing prompt You MUST use the editing prompt as context. If a visual effect is explicitly required (e.g., stylized distortion, intentional morphing, surreal transformation), DO NOT count it as an artifact. --- **Critical Rules:**
-
[63]
The listed dimensions are only references, not limitations
-
[64]
You are required to observe the video with extreme attention to detail
You MUST ONLY evaluate AI-generated artifacts. You are required to observe the video with extreme attention to detail. Strictly look for common AI hallucinations, such as: - **Sudden Mutations:** Objects or entities abruptly changing shape, structure, or identity (unless prompted). - **Appearance/Disappearance:** Objects, limbs, or details popping into ex...
-
[65]
DO NOT include physics violations (gravity, collision, lighting realism, etc.)
-
[66]
type": "ai_artifact_evaluation
DO NOT confuse: - AI artifacts = instability, ghosting, vanishing/appearing objects, sudden mutations, warping, anatomical issues. - Physics violations = real-world inconsistencies (NOT allowed here). --- **Scoring Rules:** - Start from 10. - Deduct 1 to 2 points per distinct AI hallucination/artifact: - **-2 points** for SEVERE artifacts (e.g., obvious a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.