Seeing is Believing: Aligning Prompt Rewriting with Visual Anchors for Text-to-Image Generation
Pith reviewed 2026-06-27 19:03 UTC · model grok-4.3
The pith
An image generated from the original prompt serves as a visual anchor that lets an LLM rewrite prompts to better match user intent for text-to-image models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
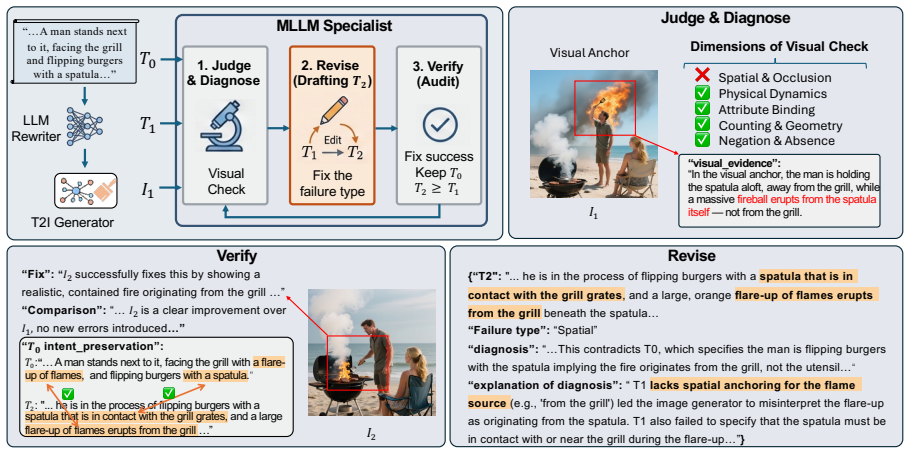
FaithRewriter generates an intermediate image from the user prompt with an MLLM to serve as a visual cue. This cue is combined with the prompt and passed to an LLM, which produces augmentations that reflect the intended visual content without excessive over-inference. The augmentations are distilled into a small-scale LLM, enabling efficient generation of prompts that are more faithful to the original intent and more visually plausible.
What carries the argument
The visual cue generated by the MLLM from the original prompt, which is combined with the text prompt to guide the LLM in creating grounded augmentations.
If this is right
- Rewritten prompts stay closer to the original user intent without adding unsupported details.
- The generated images become more visually plausible because the augmentations are tied to an actual visual reference.
- Distillation allows the method to run efficiently on smaller models while retaining the benefits of the larger LLM step.
- The intent-generation gap narrows because prompt enhancement now incorporates explicit visual grounding.
Where Pith is reading between the lines
- The same visual-cue step could be tested on prompts involving abstract or emotional content where image generation may be less reliable.
- If the initial MLLM image generation carries systematic biases, those biases could propagate into the rewritten prompts.
- Combining this approach with other grounding signals, such as user-provided reference images, might further reduce over-inference.
Load-bearing premise
The image created from the original prompt accurately represents the user's intended content and does not introduce misleading details that would steer the rewriting process off course.
What would settle it
A controlled test in which the intermediate image is deliberately altered to mismatch the prompt, followed by rewriting and image generation, would show whether the rewritten prompts still improve fidelity or instead follow the altered cue.
Figures



read the original abstract
Despite the impressive capabilities of text-to-image (T2I) models, an intent-generation gap often persists due to the brevity and ambiguity of user prompts. Existing approaches primarily polish the prompt for fluency and readability. However, the enhancement process still lacks visual grounding. As a result, the rewriter may over-infer missing details, causing an intent-generation gap. To address this limitation, we propose FaithRewriter, a novel prompt-enhancement framework for T2I generation. Specifically, FaithRewriter first leverages a multimodal MLLM to generate an image from the original prompt as an intermediate visual cue. This cue is then combined with the prompt and fed into a large-scale LLM to produce visually grounded augmentations that better reflect how the intended content should appear in images. Finally, these augmentations are distilled into a small-scale LLM for efficient deployment, enhancing its ability to generate effective T2I prompts. Experiments show that FaithRewriter yields prompts that are more faithful to the user intent and more visually plausible than strong baselines, helping narrow the intent-generation gap.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FaithRewriter, a prompt-enhancement framework for text-to-image (T2I) generation. It first uses an MLLM to generate an image from the original (often brief/ambiguous) user prompt as an intermediate visual cue. This cue is combined with the prompt and passed to a large-scale LLM to produce visually grounded augmentations. The augmentations are then distilled into a small-scale LLM for efficient deployment. The central claim is that the resulting prompts are more faithful to user intent and more visually plausible than those from strong baselines, thereby narrowing the intent-generation gap.
Significance. If the empirical claims hold under rigorous evaluation, the framework offers a concrete mechanism for injecting visual grounding into prompt rewriting, which could reduce over-inference in T2I systems. The distillation step addresses deployment practicality. The approach is novel in its explicit use of an MLLM-generated image as an anchor rather than relying solely on text polishing.
major comments (2)
- [Abstract] Abstract: The assertion that 'Experiments show that FaithRewriter yields prompts that are more faithful to the user intent and more visually plausible than strong baselines' is presented without any metrics, dataset names, baseline implementations, ablation results, or quantitative comparisons. This leaves the central empirical claim without visible supporting evidence.
- [Method description] Method description (visual cue step): The pipeline generates an image via MLLM from the identical short/ambiguous prompt and treats it as ground-truth visual anchor for the subsequent LLM rewriting step. No argument or experiment is supplied showing that this image avoids the over-inference or hallucination problems the paper attributes to text-only rewriting; the assumption that the MLLM cue is faithful therefore remains untested and load-bearing for the 'visual grounding' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that 'Experiments show that FaithRewriter yields prompts that are more faithful to the user intent and more visually plausible than strong baselines' is presented without any metrics, dataset names, baseline implementations, ablation results, or quantitative comparisons. This leaves the central empirical claim without visible supporting evidence.
Authors: The abstract is a concise summary, while the Experiments section provides the requested details on metrics, datasets, baselines, ablations, and quantitative comparisons. We agree the abstract claim would be stronger with supporting specifics and will revise it to include key quantitative highlights. revision: yes
-
Referee: [Method description] Method description (visual cue step): The pipeline generates an image via MLLM from the identical short/ambiguous prompt and treats it as ground-truth visual anchor for the subsequent LLM rewriting step. No argument or experiment is supplied showing that this image avoids the over-inference or hallucination problems the paper attributes to text-only rewriting; the assumption that the MLLM cue is faithful therefore remains untested and load-bearing for the 'visual grounding' claim.
Authors: The MLLM image provides a concrete visual reference to ground the LLM rewriting and reduce over-inference relative to text-only methods, with end-to-end results supporting the framework. We acknowledge the absence of an isolated experiment or argument specifically validating the cue's faithfulness. We will add discussion and analysis of the visual cue's role and limitations in the revision. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper presents an empirical prompt-rewriting framework (MLLM image cue + LLM augmentation + distillation) validated by experiments on faithfulness and plausibility. No equations, fitted parameters, predictions, or self-citations are described that reduce any claimed result to its own inputs by construction. The method is externally benchmarked rather than self-referential.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A multimodal MLLM can generate an image from text that serves as a faithful visual representation of user intent
invented entities (1)
-
FaithRewriter framework
no independent evidence
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.