Reinforcement Learning for Flow-Matching Policies with Density Transport
Pith reviewed 2026-06-27 18:53 UTC · model grok-4.3
The pith
RLDT fine-tunes flow-matching policies by transporting action densities toward high-reward regions with an SVGD-derived field and expected-target approximation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RLDT constructs a transport field from a maximum-entropy RL objective using Stein Variational Gradient Descent and finetunes a pretrained flow-matching policy to align with this field. Training uses an expected-target estimation of policy actions from intermediate denoising steps to propagate the transport-field update into network parameters without unstable backpropagation through time.
What carries the argument
Stein Variational Gradient Descent transport field derived from the maximum-entropy RL objective, aligned to the flow-matching policy via expected-target estimation of intermediate denoising steps.
If this is right
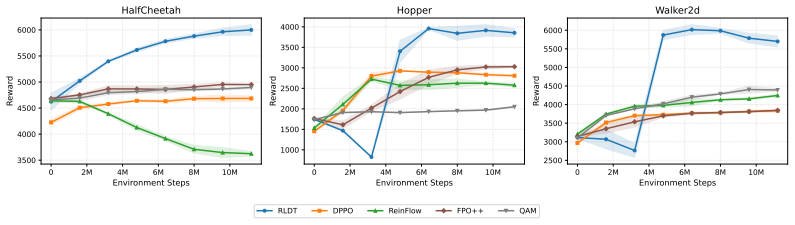
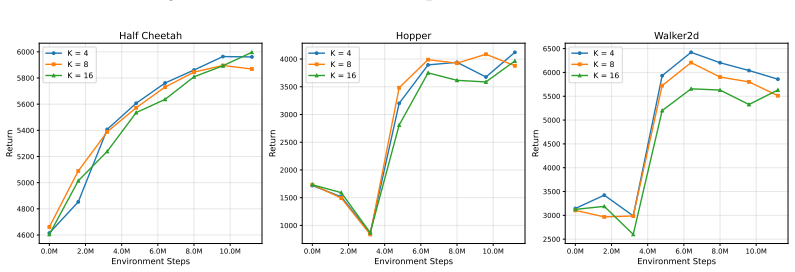
- RLDT produces higher reward quality and faster convergence than competitive baselines across continuous-control tasks.
- The method succeeds with both dense and sparse reward signals.
- Performance extends to state-based and vision-based long-horizon robot manipulation.
Where Pith is reading between the lines
- The density-transport formulation may extend to fine-tuning other multi-step generative policies such as diffusion models without requiring distillation.
- If the expected-target approximation remains stable across model sizes, it could reduce reliance on full trajectory unrolling in generative RL.
- The same transport-field construction might combine with other maximum-entropy objectives to handle multimodal action distributions in new control domains.
Load-bearing premise
The expected-target estimation approximation of policy actions from intermediate denoising steps allows the transport-field update to propagate into the network parameters without unstable backpropagation through time.
What would settle it
If RLDT shows no improvement in final reward or convergence speed over distillation baselines on a held-out long-horizon vision-based manipulation task with sparse rewards, the claimed benefit of the density-transport alignment would not hold.
Figures






read the original abstract
We present an online reinforcement learning (RL) algorithm for fine-tuning flow-matching policies in continuous-control problems. Our key insight is to view RL-based policy improvement as a transport of action densities towards regions of high reward, which naturally aligns with the transport formulation of flow matching models. Prior methods either approximate the current or optimal policy distribution or resort to distillation, which introduces biased gradients or sacrifices multimodal modeling capacity. In contrast, our approach for RL with Density Transport, which we name \emph{RLDT}, constructs a transport field from a maximum-entropy RL objective using Stein Variational Gradient Descent (SVGD). Then, it finetunes a pretrained flow matching policy to align with this field. Training with this alignment objective is nontrivial because flow-matching policies generate actions via a multi-step process, making direct gradient-based optimization challenging. To overcome this challenge and stabilize training, we approximate policy actions from intermediate denoising steps via expected-target estimation. This allows the transport-field update to propagate into the network parameters without unstable backpropagation through time. Experimental results demonstrate that RLDT outperforms competitive baselines in reward quality and convergence speed. This performance holds across diverse continuous-control tasks, encompassing both dense and sparse rewards, as well as state- and vision-based long-horizon robot manipulation. The project webpage is \href{https://rpfey.github.io/rldt/}{https://rpfey.github.io/rldt/}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RLDT, an online RL algorithm for fine-tuning pretrained flow-matching policies in continuous control tasks. It frames policy improvement as transporting action densities toward high-reward regions using a transport field derived from a maximum-entropy RL objective via SVGD. To handle the multi-step denoising process in flow-matching policies, it employs an expected-target estimation approximation for actions at intermediate steps, allowing the transport update to propagate into network parameters without direct backpropagation through time. The method is claimed to outperform baselines in reward quality and convergence speed across dense/sparse reward tasks and state/vision-based robot manipulation.
Significance. If the expected-target approximation is shown to be sufficiently accurate and the experimental gains are reproducible, the work could meaningfully advance integration of RL with flow-matching generative policies, preserving multimodal capacity while enabling online fine-tuning without distillation biases. The alignment of density transport with flow-matching is a conceptually clean contribution.
major comments (2)
- [Abstract / Method description] The expected-target estimation approximation for intermediate denoising steps (described in the abstract as the mechanism to propagate the transport-field update) is load-bearing for all performance claims, yet the manuscript provides no derivation of unbiasedness, no error bound, and no ablation isolating its contribution versus the base flow-matching pretraining or SVGD alone. This directly affects whether observed gains can be attributed to RLDT.
- [Experiments] § on experimental results: the claim that RLDT outperforms competitive baselines in reward quality and convergence speed across diverse tasks lacks reported details on the approximation's stability (e.g., variance of the expected-target estimator) or comparisons that control for the approximation itself, making it impossible to verify that the transport alignment, rather than other factors, drives the results.
minor comments (2)
- [Method] Notation for the transport field and its relation to the SVGD kernel should be introduced with explicit equations early in the method section for clarity.
- [Abstract] The project webpage link is provided but no mention of whether code or hyperparameters for the expected-target estimator will be released.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract / Method description] The expected-target estimation approximation for intermediate denoising steps (described in the abstract as the mechanism to propagate the transport-field update) is load-bearing for all performance claims, yet the manuscript provides no derivation of unbiasedness, no error bound, and no ablation isolating its contribution versus the base flow-matching pretraining or SVGD alone. This directly affects whether observed gains can be attributed to RLDT.
Authors: We agree that the manuscript currently lacks a formal derivation of the approximation's unbiasedness properties, error bounds, and a dedicated ablation. The expected-target estimation is introduced as a practical mechanism to avoid unstable backpropagation through the multi-step denoising process while still allowing the SVGD-derived transport field to influence parameters. In the revision we will add (i) a short derivation showing that the estimator is unbiased with respect to the expected target under the flow-matching marginal, (ii) a simple error bound expressed in terms of the variance of the intermediate denoising targets, and (iii) an ablation that isolates the contribution of this estimator versus plain SVGD updates on the pretrained flow-matching model. These additions will make the attribution of performance gains clearer. revision: yes
-
Referee: [Experiments] § on experimental results: the claim that RLDT outperforms competitive baselines in reward quality and convergence speed across diverse tasks lacks reported details on the approximation's stability (e.g., variance of the expected-target estimator) or comparisons that control for the approximation itself, making it impossible to verify that the transport alignment, rather than other factors, drives the results.
Authors: We acknowledge that the current experimental section does not report variance statistics for the expected-target estimator nor include controls that disable the approximation. In the revised manuscript we will add (i) plots and tables showing the empirical variance of the estimator across tasks and training iterations, and (ii) controlled comparisons that replace the expected-target step with direct sampling or with a no-transport baseline while keeping all other components fixed. These results will help isolate the contribution of the density-transport alignment. revision: yes
Circularity Check
No circularity in derivation chain; method uses standard components with a training approximation.
full rationale
The paper constructs a transport field from the standard maximum-entropy RL objective via SVGD (an established technique) and aligns a pretrained flow-matching policy to it. The expected-target estimation is presented as a practical approximation to enable stable gradient propagation through the multi-step denoising process, without any indication that the central result or performance claims reduce by construction to a fitted quantity defined by the method itself. No self-citations are invoked as load-bearing uniqueness theorems, no ansatz is smuggled, and no renaming of known results occurs. The derivation remains self-contained against external benchmarks such as SVGD and flow matching.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Flow-matching policies can be aligned to an external transport field derived from an RL objective
Reference graph
Works this paper leans on
-
[1]
Marvin Alles, Nutan Chen, Patrick van der Smagt, and Botond Cseke. Flowq: Energy-guided flow policies for offline reinforcement learning.arXiv preprint arXiv:2505.14139, 2025
arXiv 2025
-
[2]
From imitation to refinement – residual rl for precise assembly, 2024
Lars Ankile, Anthony Simeonov, Idan Shenfeld, Marcel Torne, and Pulkit Agrawal. From imitation to refinement – residual rl for precise assembly, 2024
2024
-
[3]
A careful examination of large behavior models for multitask dexterous manipulation.Science Robotics, 11(113):eaea6201, 2026
Jose Barreiros, Andrew Beaulieu, Aditya Bhat, Rick Cory, Eric Cousineau, Hongkai Dai, Ching-Hsin Fang, Kunimatsu Hashimoto, Muhammad Zubair Irshad, Masha Itkina, et al. A careful examination of large behavior models for multitask dexterous manipulation.Science Robotics, 11(113):eaea6201, 2026
2026
-
[4]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky.π0: A visio...
Pith/arXiv arXiv 2024
-
[5]
Training diffusion models with reinforcement learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforcement learning. InThe International Conference on Learning Representations, 2024
2024
-
[6]
One-step flow policy mirror descent.arXiv preprint arXiv:2507.23675, 2025
Tianyi Chen, Haitong Ma, Na Li, Kai Wang, and Bo Dai. One-step flow policy mirror descent.arXiv preprint arXiv:2507.23675, 2025
arXiv 2025
-
[7]
Consistency models as a rich and efficient policy class for reinforcement learning
Zihan Ding and Chi Jin. Consistency models as a rich and efficient policy class for reinforcement learning. arXiv preprint arXiv:2309.16984, 2023
arXiv 2023
-
[8]
Expo: Stable reinforcement learning with expressive policies.arXiv preprint arXiv:2507.07986, 2025
Perry Dong, Qiyang Li, Dorsa Sadigh, and Chelsea Finn. Expo: Stable reinforcement learning with expressive policies.arXiv preprint arXiv:2507.07986, 2025
Pith/arXiv arXiv 2025
-
[9]
Dynaguide: Steering diffusion policies with active dynamic guidance
Maximilian Du and Shuran Song. Dynaguide: Steering diffusion policies with active dynamic guidance. InProceedings of the 39th Conference on Neural Information Processing Systems (NeurIPS), 2025
2025
-
[10]
Scaling offline rl via efficient and expressive shortcut models.Neural Information Processing Symposium (NeurIPS), 2025
Nicolas Espinosa-Dice, Yiyi Zhang, Yiding Chen, Bradley Guo, Owen Oertell, Gokul Swamy, Kiante Brantley, and Wen Sun. Scaling offline rl via efficient and expressive shortcut models.Neural Information Processing Symposium (NeurIPS), 2025
2025
-
[11]
Linjiajie Fang, Ruoxue Liu, Jing Zhang, Wenjia Wang, and Bing-Yi Jing. Diffusion actor-critic: Formu- lating constrained policy iteration as diffusion noise regression for offline reinforcement learning.arXiv preprint arXiv:2405.20555, 2024
arXiv 2024
-
[12]
Flow matching policy with entropy regularization.arXiv preprint arXiv:2603.17685, 2026
Ting Gao, Stavros Orfanoudakis, Nan Lin, Elvin Isufi, Winnie Daamen, and Serge Hoogendoorn. Flow matching policy with entropy regularization.arXiv preprint arXiv:2603.17685, 2026
Pith/arXiv arXiv 2026
-
[13]
Reinforcement learning with deep energy-based policies
Tuomas Haarnoja, Haoran Tang, Pieter Abbeel, and Sergey Levine. Reinforcement learning with deep energy-based policies. InInternational conference on machine learning, pages 1352–1361. PMLR, 2017
2017
-
[14]
Philippe Hansen-Estruch, Ilya Kostrikov, Michael Janner, Jakub Grudzien Kuba, and Sergey Levine. Idql: Implicit q-learning as an actor-critic method with diffusion policies.arXiv preprint arXiv:2304.10573, 2023
Pith/arXiv arXiv 2023
-
[15]
Minho Heo, Youngwoon Lee, Doohyun Lee, and Joseph J. Lim. Furniturebench: Reproducible real-world benchmark for long-horizon complex manipulation. InRobotics: Science and Systems, 2023
2023
-
[16]
Physical Intelligence, Bo Ai, Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Greg Balke, Kevin Black, George Bokinsky, Shihao Cao, Thomas Charbonnier, et al. Pi07: a steerable generalist robotic foundation model with emergent capabilities.arXiv preprint arXiv:2604.15483, 2026
Pith/arXiv arXiv 2026
-
[17]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. Pi0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[18]
Fairoz Nower Khan, Nabuat Zaman Nahim, Ruiquan Huang, Haibo Yang, and Peizhong Ju. Flow matching for offline reinforcement learning with discrete actions.arXiv preprint arXiv:2602.06138, 2026
Pith/arXiv arXiv 2026
-
[19]
Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Paul Foster, Pannag R. Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Openvla: An open-source vision- language-action model. In Pulkit Agrawal, Oliver Kroemer, ...
2024
-
[20]
Understanding diffusion objectives as the ELBO with simple data augmentation
Diederik P Kingma and Ruiqi Gao. Understanding diffusion objectives as the ELBO with simple data augmentation. InThirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[21]
Prajwal Koirala and Cody Fleming. Flow-based single-step completion for efficient and expressive policy learning.arXiv preprint arXiv:2506.21427, 2025
arXiv 2025
-
[22]
Composite flow matching for reinforcement learning with shifted-dynamics data
Lingkai Kong, Haichuan Wang, Tonghan Wang, GUOJUN XIONG, and Milind Tambe. Composite flow matching for reinforcement learning with shifted-dynamics data. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[23]
Q-learning with adjoint matching.CoRR, abs/2601.14234, 2026
Qiyang Li and Sergey Levine. Q-learning with adjoint matching.CoRR, abs/2601.14234, 2026
Pith/arXiv arXiv 2026
-
[24]
Back to basics: Let denoising generative models denoise.CoRR, abs/2511.13720, 2025
Tianhong Li and Kaiming He. Back to basics: Let denoising generative models denoise.CoRR, abs/2511.13720, 2025
Pith/arXiv arXiv 2025
-
[25]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.ArXiv, abs/2210.02747, 2022
Pith/arXiv arXiv 2022
-
[26]
Yaron Lipman, Marton Havasi, Peter Holderrieth, Neta Shaul, Matt Le, Brian Karrer, Ricky T. Q. Chen, David Lopez-Paz, Heli Ben-Hamu, and Itai Gat. Flow matching guide and code.CoRR, abs/2412.06264, 2024
Pith/arXiv arXiv 2024
-
[27]
Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.05470, 2025
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.05470, 2025
Pith/arXiv arXiv 2025
-
[28]
A kernelized stein discrepancy for goodness-of-fit tests
Qiang Liu, Jason Lee, and Michael Jordan. A kernelized stein discrepancy for goodness-of-fit tests. In International conference on machine learning, pages 276–284. PMLR, 2016
2016
-
[29]
Stein variational gradient descent: A general purpose bayesian inference algorithm.Advances in neural information processing systems, 29, 2016
Qiang Liu and Dilin Wang. Stein variational gradient descent: A general purpose bayesian inference algorithm.Advances in neural information processing systems, 29, 2016
2016
-
[30]
Contrastive energy prediction for exact energy-guided diffusion sampling in offline reinforcement learning
Cheng Lu, Huayu Chen, Jianfei Chen, Hang Su, Chongxuan Li, and Jun Zhu. Contrastive energy prediction for exact energy-guided diffusion sampling in offline reinforcement learning. InInternational Conference on Machine Learning, pages 22825–22855. PMLR, 2023
2023
-
[31]
Efficient online reinforcement learning for diffusion policy.arXiv preprint arXiv:2502.00361, 2025
Haitong Ma, Tianyi Chen, Kai Wang, Na Li, and Bo Dai. Efficient online reinforcement learning for diffusion policy.arXiv preprint arXiv:2502.00361, 2025
arXiv 2025
-
[32]
Efficient online reinforcement learning for diffusion policy
Haitong Ma, Tianyi Chen, Kai Wang, Na Li, and Bo Dai. Efficient online reinforcement learning for diffusion policy. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,F orty-second International Conference on Machine Learning, ICML 2025, V ancouver , BC, Canada, July 13-19...
2025
-
[33]
What matters in learning from offline human demonstrations for robot manipulation
Ajay Mandlekar, Danfei Xu, Josiah Wong, Soroush Nasiriany, Chen Wang, Rohun Kulkarni, Li Fei-Fei, Silvio Savarese, Yuke Zhu, and Roberto Martín-Martín. What matters in learning from offline human demonstrations for robot manipulation. InarXiv preprint arXiv:2108.03298, 2021
Pith/arXiv arXiv 2021
-
[34]
Flow matching policy gradients
David McAllister, Songwei Ge, Brent Yi, Chung Min Kim, Ethan Weber, Hongsuk Choi, Haiwen Feng, and Angjoo Kanazawa. Flow matching policy gradients. InThe F ourteenth International Conference on Learning Representations, 2026
2026
-
[35]
Flow matching with semidiscrete couplings.arXiv preprint arXiv:2509.25519, 2025
Alireza Mousavi-Hosseini, Stephen Y Zhang, Michal Klein, and Marco Cuturi. Flow matching with semidiscrete couplings.arXiv preprint arXiv:2509.25519, 2025
arXiv 2025
-
[36]
Flow q-learning
Seohong Park, Qiyang Li, and Sergey Levine. Flow q-learning. InF orty-second International Conference on Machine Learning, 2025
2025
-
[37]
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
Pith/arXiv arXiv 2025
-
[38]
Reinforcement learning for flow-matching policies.arXiv preprint arXiv:2507.15073, 2025
Samuel Pfrommer, Yixiao Huang, and Somayeh Sojoudi. Reinforcement learning for flow-matching policies.arXiv preprint arXiv:2507.15073, 2025
arXiv 2025
-
[39]
Learning a diffusion model policy from rewards via q-score matching
Michael Psenka, Alejandro Escontrela, Pieter Abbeel, and Yi Ma. Learning a diffusion model policy from rewards via q-score matching. InInternational Conference on Machine Learning, pages 41163–41182. PMLR, 2024. 11
2024
-
[40]
Diffusion policy policy optimization
Allen Z Ren, Justin Lidard, Lars Lien Ankile, Anthony Simeonov, Pulkit Agrawal, Anirudha Majumdar, Benjamin Burchfiel, Hongkai Dai, and Max Simchowitz. Diffusion policy policy optimization. InThe International Conference on Learning Representations, 2025
2025
-
[41]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[42]
Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Martino Russi, Andres Marafioti, et al. Smolvla: A vision-language- action model for affordable and efficient robotics.arXiv preprint arXiv:2506.01844, 2025
Pith/arXiv arXiv 2025
-
[43]
Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021
2021
-
[44]
Rfs: Reinforcement learning with residual flow steering for dexterous manipulation
Entong Su, Tyler Westenbroek, Anusha Nagabandi, and Abhishek Gupta. Rfs: Reinforcement learning with residual flow steering for dexterous manipulation. InThe F ourteenth International Conference on Learning Representations, 2026
2026
-
[45]
Score-based diffusion policy compatible with reinforcement learning via optimal transport
Mingyang Sun, Pengxiang Ding, Weinan Zhang, and Donglin Wang. Score-based diffusion policy compatible with reinforcement learning via optimal transport. InF orty-second International Conference on Machine Learning, 2025
2025
-
[46]
Xiaohui Sun, Ruitong Xiao, Jianye Mo, Bowen Wu, Qun Yu, and Baoxun Wang. F5r-tts: Improving flow- matching based text-to-speech with group relative policy optimization.arXiv preprint arXiv:2504.02407, 2025
arXiv 2025
-
[47]
Pilarski, Marlos C
Harm van Seijen, Ashique Rupam Mahmood, Patrick M. Pilarski, Marlos C. Machado, and Richard S. Sutton. True online temporal-difference learning.J. Mach. Learn. Res., 17:145:1–145:40, 2016
2016
-
[48]
Dilin Wang and Qiang Liu. Learning to draw samples: With application to amortized mle for generative adversarial learning.arXiv preprint arXiv:1611.01722, 2016
Pith/arXiv arXiv 2016
-
[49]
Pengcheng Wang, Chenran Li, Catherine Weaver, Kenta Kawamoto, Masayoshi Tomizuka, Chen Tang, and Wei Zhan. Residual-mppi: Online policy customization for continuous control.arXiv preprint arXiv:2407.00898, 2024
arXiv 2024
-
[50]
Yunshen Wang, Shaohang Zhu, Peiyuan Zhi, Yuhan Li, Jiaxin Li, Yong-Lu Li, Yuchen Xiao, Xingxing Wang, Baoxiong Jia, and Siyuan Huang. Omnixtreme: Breaking the generality barrier in high-dynamic humanoid control.arXiv preprint arXiv:2602.23843, 2026
arXiv 2026
-
[51]
A pragmatic vla foundation model.arXiv preprint arXiv:2601.18692, 2026
Wei Wu, Fan Lu, Yunnan Wang, Shuai Yang, Shi Liu, Fangjing Wang, Qian Zhu, He Sun, Yong Wang, Shuailei Ma, et al. A pragmatic vla foundation model.arXiv preprint arXiv:2601.18692, 2026
Pith/arXiv arXiv 2026
-
[52]
Simple policy optimization
Zhengpeng Xie, Qiang Zhang, Fan Yang, Marco Hutter, and Renjing Xu. Simple policy optimization. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,F orty-second International Conference on Machine Learning, ICML 2025, V ancouver , BC, Canada, July 13-19, 2025, Proceedings ...
2025
-
[53]
Steering diffusion policies with value-guided denoising
Hanming Ye. Steering diffusion policies with value-guided denoising. InNeurIPS 2025 Workshop: Second Workshop on Aligning Reinforcement Learning Experimentalists and Theorists, 2025
2025
-
[54]
Truong, Carmelo Sferrazza, Yi Ma, Yan Duan, Pieter Abbeel, Guanya Shi, Karen Liu, and Angjoo Kanazawa
Brent Yi, Hongsuk Choi, Himanshu Gaurav Singh, Xiaoyu Huang, Takara E. Truong, Carmelo Sferrazza, Yi Ma, Yan Duan, Pieter Abbeel, Guanya Shi, Karen Liu, and Angjoo Kanazawa. Flow policy gradients for legged robots, 2026
2026
-
[55]
Entropy-regularized diffusion policy with q-ensembles for offline reinforcement learning.Advances in neural information processing systems, 37:98871–98897, 2024
Ruoqi Zhang, Ziwei Luo, Jens Sjölund, Thomas B Schön, and Per Mattsson. Entropy-regularized diffusion policy with q-ensembles for offline reinforcement learning.Advances in neural information processing systems, 37:98871–98897, 2024
2024
-
[56]
Reinflow: Fine-tuning flow matching policy with online reinforcement learning, 2025
Tonghe Zhang, Chao Yu, Sichang Su, and Yu Wang. Reinflow: Fine-tuning flow matching policy with online reinforcement learning, 2025
2025
-
[57]
SAC flow: Sample-efficient reinforcement learning of flow-based policies via velocity-reparameterized sequential modeling
Yixian Zhang, Shu’ang Yu, Tonghe Zhang, Mo Guang, Haojia Hui, Kaiwen Long, Yu Wang, Chao Yu, and Wenbo Ding. SAC flow: Sample-efficient reinforcement learning of flow-based policies via velocity-reparameterized sequential modeling. InThe F ourteenth International Conference on Learning Representations, 2026
2026
-
[58]
Ziebart.Modeling Purposeful Adaptive Behavior with the Principle of Maximum Causal Entropy
Brian D. Ziebart.Modeling Purposeful Adaptive Behavior with the Principle of Maximum Causal Entropy. PhD thesis, Carnegie Mellon University, USA, 2010. 12 A Algorithm Summary Our method is summarized in Algorithm 1. Algorithm 1:RLDT Flow matching policy parametersθ, Q-network parameters{ϕi},i= 1,2; Assign target parameters: ¯θ←θ,¯ϕi←ϕi; D←empty replay buf...
2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.