Learnable Token Sparsification for Efficient Gigapixel Whole Slide Image Reasoning
Pith reviewed 2026-06-27 18:42 UTC · model grok-4.3
The pith
A trainable selector reduces gigapixel whole slide images to 32 tokens while keeping 73 percent accuracy in vision-language reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
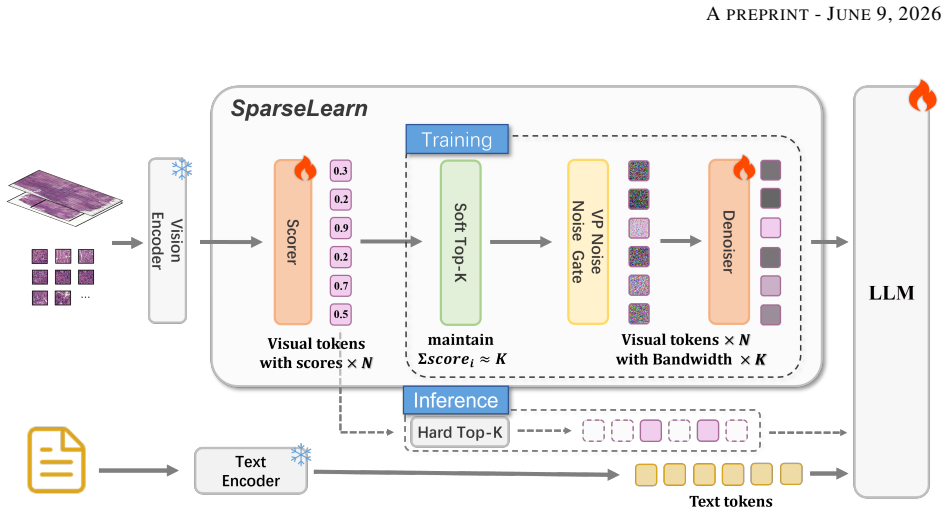
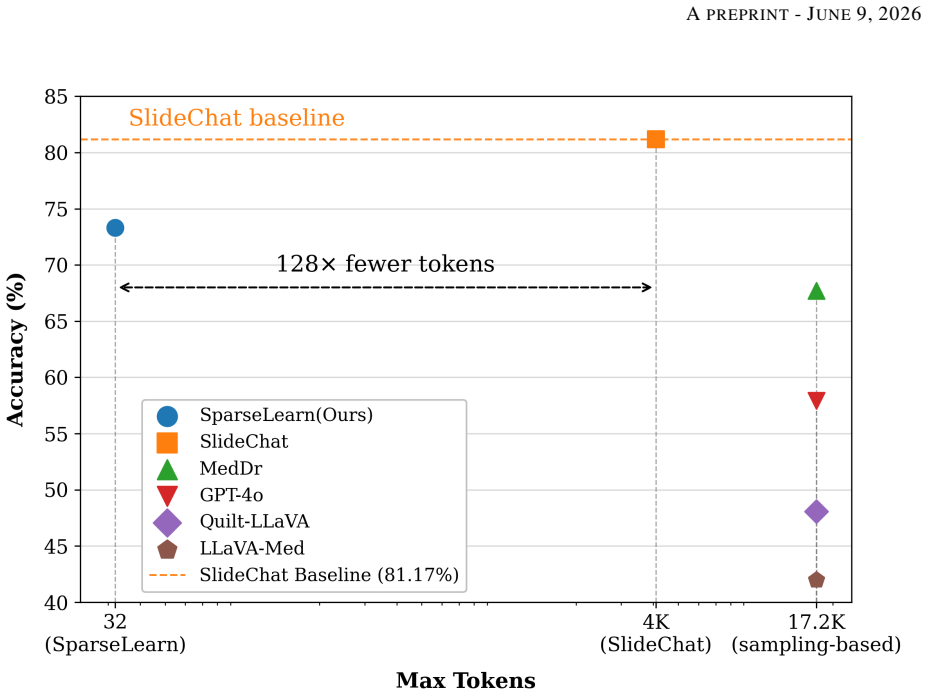
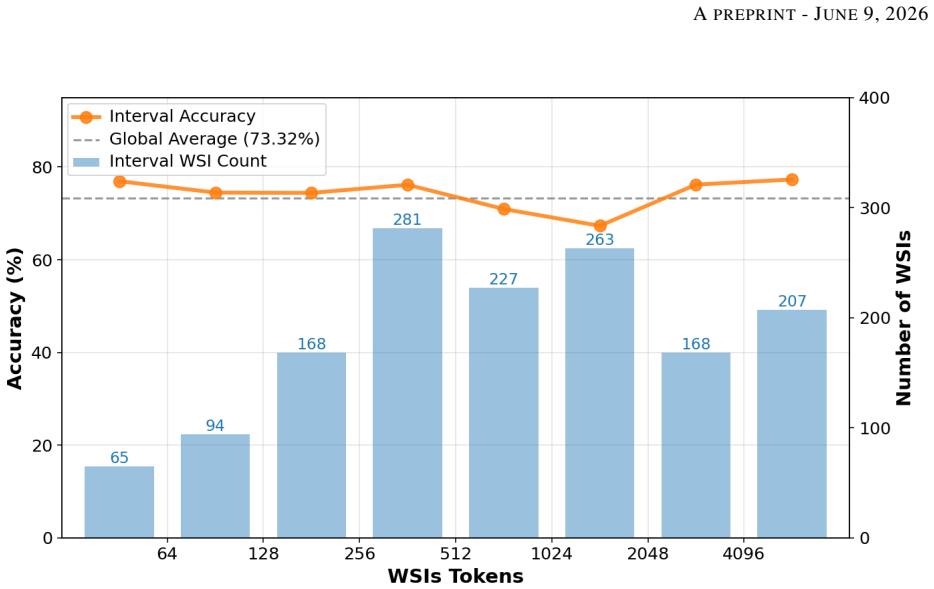
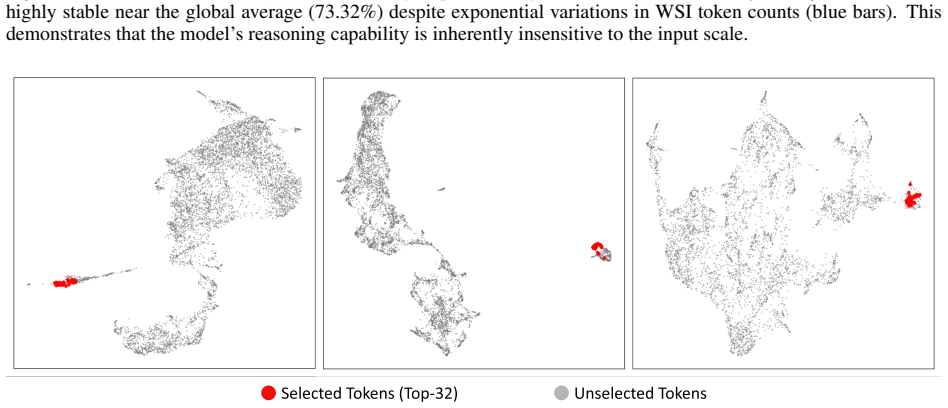
We reformulate token reduction in whole slide images as a trainable sparsification problem. A decoupled routing architecture with the SparseLearn component uses a variance-preserving noise gate and a diagonal attention denoiser to propagate gradients through a differentiable Soft Top-K operator during training. At inference the module is removed and a deterministic Hard Top-K keeps only the 32 highest-scoring tokens, which represent as little as 0.78 percent of the original sequence length. This yields 73.32 percent overall accuracy on SlideBench (TCGA) and strong zero-shot results on SlideBench (BCNB) and WSI VQA, outperforming sampling baselines and general vision-language models.
What carries the argument
The SparseLearn module, which uses a variance-preserving noise gate to control information flow per patch through a differentiable Soft Top-K operator together with a diagonal attention denoiser that restores representations without spatial leakage.
If this is right
- Visual sequences from gigapixel slides can be reduced to under 1 percent length while still supporting accurate end-to-end reasoning.
- The learned selection consistently beats both heuristic sampling methods and off-the-shelf vision-language models on pathology benchmarks.
- The same 32-token regime produces strong zero-shot performance on additional slide datasets without retraining.
- Removing the training module at inference adds no extra cost, enabling practical deployment on large images.
Where Pith is reading between the lines
- The same training-time relaxation could be applied to other vision tasks where relevant features occupy only a tiny fraction of a high-resolution input.
- If the scorer identifies diagnostically salient regions consistently across datasets, it might surface new hypotheses about which tissue patterns drive model decisions.
- The clean separation between differentiable training and deterministic inference suggests a template for making other non-differentiable selection steps trainable in large models.
Load-bearing premise
The noise gate and denoiser let the scorer learn a selection rule during soft training that transfers directly to hard top-k selection at inference without accuracy loss or hidden information passing through.
What would settle it
Running the trained scorer with hard top-k at inference and finding that accuracy falls well below the soft-training version or below the reported 73.32 percent on the same benchmark would falsify the transfer claim.
Figures
read the original abstract
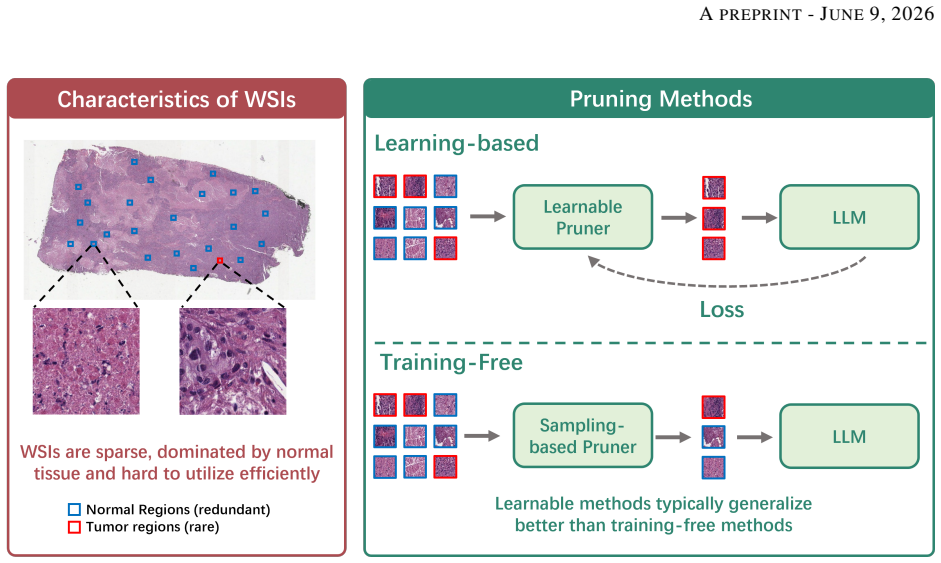
The processing of gigapixel whole slide images within vision language models faces a major difficulty due to an excessive number of visual tokens. Existing solutions typically rely on spatial downsampling or heuristic pruning strategies that operate without training, and these methods often discard subtle but clinically meaningful patterns because pathological evidence is scattered irregularly across the tissue. To overcome this limitation, we reformulate token reduction in whole slide images as a trainable sparsification problem, allowing the model to learn an optimal selection strategy instead of following fixed heuristics. We propose a decoupled routing architecture. To enable gradient propagation through the nondifferentiable pruning operation during training, we introduce a component called SparseLearn. This component uses a variance-preserving noise gate that regulates the information flow of each patch via a differentiable Soft Top-K operator, together with a diagonal attention denoiser that recovers perturbed representations without leaking spatial information. At inference time, the SparseLearn module is entirely discarded, and the trained scorer applies a deterministic Hard Top-K operator to keep only the highest scoring 32 tokens, incurring no extra computation. By compressing the visual sequence down to a sparse set of just 32 tokens, which represents as little as 0.78% of the original length, our framework achieves 73.32% overall accuracy on SlideBench (TCGA), consistently surpassing sampling-based baselines and general-purpose vision language models. It also demonstrates strong zero shot generalization on SlideBench (BCNB) and WSI VQA*. By resolving the visual context bottleneck and preventing the dilution of sparse diagnostic evidence, this work provides a highly efficient paradigm for end to end gigapixel whole slide image reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that reformulating token reduction for gigapixel whole-slide images as a trainable sparsification problem, via a decoupled routing architecture and a SparseLearn module (variance-preserving noise gate + diagonal attention denoiser with differentiable Soft Top-K), allows training a scorer that is discarded at inference in favor of deterministic Hard Top-K. This reduces the visual sequence to 32 tokens (0.78% of original length) while achieving 73.32% overall accuracy on SlideBench (TCGA), outperforming sampling baselines and general VLMs, with strong zero-shot generalization on SlideBench (BCNB) and WSI VQA.
Significance. If the central transfer from soft to hard selection holds without leakage or performance drop, the approach would offer a parameter-efficient, end-to-end trainable alternative to heuristic or sampling-based pruning for WSI reasoning, directly addressing the token-length bottleneck while preserving diagnostic evidence. The explicit design choice to incur zero extra inference cost by discarding SparseLearn is a clear engineering strength.
major comments (1)
- [Abstract] Abstract (paragraph on SparseLearn): the headline result (73.32% accuracy with Hard Top-K at inference) is load-bearing on the unverified assumption that the variance-preserving noise gate and diagonal attention denoiser produce selections that transfer without information leakage or accuracy loss when the entire module is replaced by deterministic Hard Top-K. No quantitative check (soft-vs-hard accuracy delta on the same scorer, mutual information between selected tokens and discarded patches, or ablation of the denoiser) is supplied to support this transfer.
minor comments (1)
- [Abstract] The abstract states superiority over 'sampling-based baselines and general-purpose vision language models' but supplies no dataset splits, statistical tests, or ablation tables; these details must appear in the experimental section for the claim to be assessable.
Simulated Author's Rebuttal
We thank the referee for highlighting this critical aspect of our method. We address the concern point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on SparseLearn): the headline result (73.32% accuracy with Hard Top-K at inference) is load-bearing on the unverified assumption that the variance-preserving noise gate and diagonal attention denoiser produce selections that transfer without information leakage or accuracy loss when the entire module is replaced by deterministic Hard Top-K. No quantitative check (soft-vs-hard accuracy delta on the same scorer, mutual information between selected tokens and discarded patches, or ablation of the denoiser) is supplied to support this transfer.
Authors: We agree that the current manuscript does not provide the requested quantitative verification of the soft-to-hard transfer. In the revised manuscript we will add (1) a direct accuracy comparison between Soft Top-K (training) and Hard Top-K (inference) on the identical trained scorer, (2) token-overlap statistics and mutual-information estimates between the soft and hard selections, and (3) an ablation removing the diagonal attention denoiser to quantify its role in stable transfer. These results will be reported in a new subsection of the experiments and referenced from the abstract. revision: yes
Circularity Check
No circularity; empirical architecture evaluated on external benchmarks
full rationale
The paper proposes a new decoupled routing architecture with SparseLearn (variance-preserving noise gate + diagonal attention denoiser + Soft Top-K during training) that is discarded at inference in favor of Hard Top-K. The headline accuracy figure (73.32% on SlideBench TCGA with 32 tokens) is presented as an empirical result of training the scorer on the dataset and evaluating on held-out test data, not as a quantity obtained by fitting parameters to the target metric and renaming the fit as a prediction. No equations, derivations, or self-citations are shown that reduce the reported performance to the inputs by construction. The method is self-contained against external benchmarks and does not rely on load-bearing self-citations or uniqueness theorems from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Soft Top-K operator during training sufficiently approximates Hard Top-K at inference for the learned scorer to transfer without degradation
invented entities (1)
-
SparseLearn module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Scalar: Spatial- concept alignment for robust vision in harsh open world.Pattern Recognition, page 113203, 2026
Xiaoyu Yang, Lijian Xu, Xingyu Zeng, Xiaosong Wang, Hongsheng Li, and Shaoting Zhang. Scalar: Spatial- concept alignment for robust vision in harsh open world.Pattern Recognition, page 113203, 2026
2026
-
[2]
Lijian Xu, Ziyu Ni, Xinglong Liu, Xiaosong Wang, Hongsheng Li, and Shaoting Zhang. A unified multi-task framework enables interpretable chest radiograph analysis.arXiv preprint arXiv:2606.03417, 2026
Pith/arXiv arXiv 2026
-
[3]
Lijian Xu, Ziyu Ni, Hao Sun, Hongsheng Li, and Shaoting Zhang. A foundation model for generalizable disease diagnosis in chest x-ray images.arXiv preprint arXiv:2410.08861, 2024. 9 APREPRINT- JUNE9, 2026
arXiv 2024
-
[4]
Shawn Young and Lijian Xu. Xrayclaw: Cooperative-competitive multi-agent alignment for trustworthy chest x-ray diagnosis.arXiv preprint arXiv:2604.02695, 2026
Pith/arXiv arXiv 2026
-
[5]
Clinical-grade computational pathology using weakly supervised deep learning on whole slide images.Nature medicine, 25(8):1301–1309, 2019
Gabriele Campanella, Matthew G Hanna, Luke Geneslaw, et al. Clinical-grade computational pathology using weakly supervised deep learning on whole slide images.Nature medicine, 25(8):1301–1309, 2019
2019
-
[6]
Shawn Young, Xingyu Zeng, and Lijian Xu. Fewer tokens, greater scaling: Self-adaptive visual bases for efficient and expansive representation learning.arXiv preprint arXiv:2511.19515, 2026
arXiv 2026
-
[7]
A graph-transformer for whole slide image classification
Yi Zheng, Rushin H Gindra, Emily J Green, et al. A graph-transformer for whole slide image classification. IEEE transactions on medical imaging, 41(11):3003–3015, 2022
2022
-
[8]
Streaming convolutional neural networks for end-to- end learning with multi-megapixel images.IEEE transactions on pattern analysis and machine intelligence, 44(3):1581–1590, 2020
Hans Pinckaers, Bram Van Ginneken, and Geert Litjens. Streaming convolutional neural networks for end-to- end learning with multi-megapixel images.IEEE transactions on pattern analysis and machine intelligence, 44(3):1581–1590, 2020
2020
-
[9]
Zhuo Chen, Shawn Young, and Lijian Xu. Tc-ssa: Token compression via semantic slot aggregation for gigapixel pathology reasoning.arXiv preprint arXiv:2603.01143, 2026
arXiv 2026
-
[10]
Scaling vision transformers to gigapixel images via hierar- chical self-supervised learning
Richard J Chen, Cheng Chen, Yicong Li, et al. Scaling vision transformers to gigapixel images via hierar- chical self-supervised learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16144–16155, 2022
2022
-
[11]
Dynamicvit: Efficient vision transformers with dynamic token sparsification
Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, and Cho-Jui Hsieh. Dynamicvit: Efficient vision transformers with dynamic token sparsification. InAdvances in Neural Information Processing Systems, volume 34, pages 13937–13949, 2021
2021
-
[12]
Token merging: Your ViT but faster
Daniel Bolya, Cheng-Yang Fu, Xiaodong Dai, Peize Zhang, and Judy Hoffman. Token merging: Your ViT but faster. InInternational Conference on Learning Representations, 2023
2023
-
[13]
Landi He, Xiaoyu Yang, and Lijian Xu. The model knows which tokens matter:automatic token selection via noise gating.arXiv preprint arXiv:2603.07135, 2026
arXiv 2026
-
[14]
Zerosense: How vision matters in long context compression.arXiv preprint arXiv:2603.11846, 2026
Yonghan Gao, Zehong Chen, Lijian Xu, Jingzhi Chen, Jingwei Guan, and Xingyu Zeng. Zerosense: How vision matters in long context compression.arXiv preprint arXiv:2603.11846, 2026
arXiv 2026
-
[15]
Stochastic beams and where to find them: The gumbel-top- k trick for sampling sequences without replacement
Wouter Kool, Herke Van Hoof, and Max Welling. Stochastic beams and where to find them: The gumbel-top- k trick for sampling sequences without replacement. InInternational conference on machine learning, pages 3499–3508. PMLR, 2019
2019
-
[16]
Yoshua Bengio, Nicholas Léonard, and Aaron Courville. Estimating or propagating gradients through stochastic neurons for conditional computation.arXiv preprint arXiv:1308.3432, 2013
Pith/arXiv arXiv 2013
-
[17]
Rinyoichi Takezoe, Yaqian Li, Zihao Bo, Anzhou Hou, Mo Guang, and Kaiwen Long. Learnpruner: Rethinking attention-based token pruning in vision language models.arXiv preprint arXiv:2604.23950, 2026
Pith/arXiv arXiv 2026
-
[18]
Attention-based deep multiple instance learning
Maximilian Ilse, Jakub Tomczak, and Max Welling. Attention-based deep multiple instance learning. InInter- national conference on machine learning, pages 2127–2136. PMLR, 2018
2018
-
[19]
Data-efficient and weakly supervised computational pathology on whole-slide images.Nature biomedical engineering, 5(6):555–570, 2021
Ming Y Lu, Drew FK Williamson, Tiffany Y Chen, et al. Data-efficient and weakly supervised computational pathology on whole-slide images.Nature biomedical engineering, 5(6):555–570, 2021
2021
-
[20]
Transmil: Transformer based correlated multiple instance learning for whole slide image classification.Advances in neural information processing systems, 34:2136–2147, 2021
Zhuchen Shao, Hao Bian, Yang Chen, Yifeng Wang, Jian Zhang, Xiangyang Ji, et al. Transmil: Transformer based correlated multiple instance learning for whole slide image classification.Advances in neural information processing systems, 34:2136–2147, 2021
2021
-
[21]
Noriaki Hashimoto, Hiroyuki Hanada, Hiroaki Miyoshi, et al. Multimodal gated mixture of experts using whole slide image and flow cytometry for multiple instance learning classification of lymphoma.Journal of Pathology Informatics, 15:100359, 2024
2024
-
[22]
Learning heterogeneous tissues with mixture of experts for gigapixel whole slide images
Junxian Wu, Minheng Chen, Xinyi Ke, Tianwang Xun, Xiaoming Jiang, Hongyu Zhou, Lizhi Shao, and Youyong Kong. Learning heterogeneous tissues with mixture of experts for gigapixel whole slide images. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5144–5153, 2025
2025
-
[23]
Multi-modal gated mixture of local-to-global experts for dynamic image fusion
Bing Cao, Yiming Sun, Pengfei Zhu, and Qinghua Hu. Multi-modal gated mixture of local-to-global experts for dynamic image fusion. InProceedings of the IEEE/CVF international conference on computer vision, pages 23555–23564, 2023
2023
-
[24]
Feature re-embedding: Towards foundation model-level performance in computational pathology
Wenhao Tang, Fengtao Zhou, Sheng Huang, et al. Feature re-embedding: Towards foundation model-level performance in computational pathology. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11343–11352, 2024. 10 APREPRINT- JUNE9, 2026
2024
-
[25]
Revisiting end-to-end learning with slide-level supervision in computational pathology.Advances in Neural Information Processing Systems, 38:160279–160312, 2026
Wenhao Tang, Rong Qin, Heng Fang, Fengtao Zhou, Hao Chen, Xiang Li, and Ming-Ming Cheng. Revisiting end-to-end learning with slide-level supervision in computational pathology.Advances in Neural Information Processing Systems, 38:160279–160312, 2026
2026
-
[26]
Towards a general-purpose foundation model for computational pathology.Nature medicine, 30(3):850–862, 2024
Richard J Chen, Tong Ding, Ming Y Lu, et al. Towards a general-purpose foundation model for computational pathology.Nature medicine, 30(3):850–862, 2024
2024
-
[27]
A whole-slide foundation model for digital pathology from real-world data.Nature, 630(8015):181–188, 2024
Hanwen Xu, Naoto Usuyama, Jaspreet Bagga, et al. A whole-slide foundation model for digital pathology from real-world data.Nature, 630(8015):181–188, 2024
2024
-
[28]
Peihang Wu, Zehong Chen, and Lijian Xu. Multimodal model for computational pathology: Representation learning and image compression.arXiv preprint arXiv:2603.18660, 2026
arXiv 2026
-
[29]
Lijian Xu, Hao Sun, Ziyu Ni, Hongsheng Li, and Shaoting Zhang. Medvilam: A multimodal large language model with advanced generalizability and explainability for medical data understanding and generation.arXiv preprint arXiv:2409.19684, 2024
arXiv 2024
-
[30]
A visual–language foun- dation model for pathology image analysis using medical twitter.Nature medicine, 29(9):2307–2316, 2023
Zhi Huang, Federico Bianchi, Mert Yuksekgonul, Thomas J Montine, and James Zou. A visual–language foun- dation model for pathology image analysis using medical twitter.Nature medicine, 29(9):2307–2316, 2023
2023
-
[31]
A visual-language foundation model for computational pathology.Nature medicine, 30(3):863–874, 2024
Ming Y Lu, Bowen Chen, Drew FK Williamson, Richard J Chen, et al. A visual-language foundation model for computational pathology.Nature medicine, 30(3):863–874, 2024
2024
-
[32]
Cpath-omni: A unified multimodal foundation model for patch and whole slide image analysis in computational pathology
Yuxuan Sun, Yixuan Si, Chenglu Zhu, et al. Cpath-omni: A unified multimodal foundation model for patch and whole slide image analysis in computational pathology. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10360–10371, 2025
2025
-
[33]
Segmentation and vascular vectorization for coronary artery by geometry-based cascaded neural network.IEEE Transactions on Medical Imaging, 44(1):259–269, 2024
Xiaoyu Yang, Lijian Xu, Simon Yu, Qing Xia, Hongsheng Li, and Shaoting Zhang. Segmentation and vascular vectorization for coronary artery by geometry-based cascaded neural network.IEEE Transactions on Medical Imaging, 44(1):259–269, 2024
2024
-
[34]
Geometry-based end- to-end segmentation of coronary artery in computed tomography angiography
Xiaoyu Yang, Lijian Xu, Simon Yu, Qing Xia, Hongsheng Li, and Shaoting Zhang. Geometry-based end- to-end segmentation of coronary artery in computed tomography angiography. InInternational Workshop on Trustworthy Machine Learning for Healthcare, pages 190–196. Springer, 2023
2023
-
[35]
Wangyu Feng, Shawn Young, and Lijian Xu. Efficient chest x-ray representation learning via semantic- partitioned contrastive learning.arXiv preprint arXiv:2603.07113, 2026
arXiv 2026
-
[36]
Llava-med: Training a large language-and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36:28541–28564, 2023
Chunyuan Li, Cliff Wong, Sheng Zhang, et al. Llava-med: Training a large language-and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36:28541–28564, 2023
2023
-
[37]
Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
Aaron Hurst, Adam Lerer, Adam P Goucher, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
Pith/arXiv arXiv 2024
-
[38]
Sunan He, Yuxiang Nie, Zhixuan Chen, Zhiyuan Cai, Hongmei Wang, Shu Yang, and Hao Chen. Meddr: Diagnosis-guided bootstrapping for large-scale medical vision-language learning.arXiv preprint arXiv:2404.15127, 1(3):6, 2024
arXiv 2024
-
[39]
Quilt-llava: Visual instruction tuning by extracting localized narratives from open-source histopathology videos
Mehmet Saygin Seyfioglu, Wisdom O Ikezogwo, Fatemeh Ghezloo, et al. Quilt-llava: Visual instruction tuning by extracting localized narratives from open-source histopathology videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13183–13192, 2024
2024
-
[40]
Hidrop: Hierarchical vision token reduction in mllms via late injection, concave pyramid pruning, and early exit.International Conference on Learning Representations, 2026
Hao Wu, Yingqi Fan, Jinyang Dai, Junlong Tong, Yunpu Ma, and Xiaoyu Shen. Hidrop: Hierarchical vision token reduction in mllms via late injection, concave pyramid pruning, and early exit.International Conference on Learning Representations, 2026
2026
-
[41]
One leaf reveals the season: Occlusion-based contrastive learning with semantic-aware views for efficient visual representation
Xiaoyu Yang, Lijian Xu, Hongsheng Li, and Shaoting Zhang. One leaf reveals the season: Occlusion-based contrastive learning with semantic-aware views for efficient visual representation. InInternational Conference on Machine Learning, pages 71425–71440, 2025
2025
-
[42]
Landi He, Mingde Yao, Shawn Young, and Lijian Xu. Beyond surrogate gradients: Fully differentiable token pruning for vision-language models.arXiv preprint arXiv:2605.28051, 2026
Pith/arXiv arXiv 2026
-
[43]
Mmtok: Multimodal coverage maximization for efficient inference of vlms.International Conference on Learning Representations, 2026
Sixun Dong, Juhua Hu, Mian Zhang, et al. Mmtok: Multimodal coverage maximization for efficient inference of vlms.International Conference on Learning Representations, 2026
2026
-
[44]
Beyond attention or similarity: Maximizing conditional diversity for token pruning in mllms.Advances in Neural Information Processing Systems, 38:25438–25468, 2026
Qizhe Zhang, Mengzhen Liu, Lichen Li, et al. Beyond attention or similarity: Maximizing conditional diversity for token pruning in mllms.Advances in Neural Information Processing Systems, 38:25438–25468, 2026
2026
-
[45]
Visionzip: Longer is better but not necessary in vision language models
Senqiao Yang, Yukang Chen, Zhuotao Tian, et al. Visionzip: Longer is better but not necessary in vision language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19792– 19802, 2025. 11 APREPRINT- JUNE9, 2026
2025
-
[46]
Kele Shao, Keda Tao, Kejia Zhang, et al. When tokens talk too much: A survey of multimodal long-context token compression across images, videos, and audios.arXiv preprint arXiv:2507.20198, 2025
arXiv 2025
-
[47]
Categorical reparameterization with gumbel-softmax.arXiv preprint arXiv:1611.01144, 2016
Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with gumbel-softmax.arXiv preprint arXiv:1611.01144, 2016
Pith/arXiv arXiv 2016
-
[48]
Qingqiao Hu, Weimin Lyu, Meilong Xu, et al. Loc-path: Learning to compress for pathology multimodal large language models.arXiv preprint arXiv:2512.05391, 2025
arXiv 2025
-
[49]
Wsisum: Wsi summarization via dual-level semantic reconstruc- tion.Medical Image Analysis, page 103970, 2026
Baizhi Wang, Kun Zhang, Yuhao Wang, et al. Wsisum: Wsi summarization via dual-level semantic reconstruc- tion.Medical Image Analysis, page 103970, 2026
2026
-
[50]
Focus: Knowledge-enhanced adaptive visual compression for few-shot whole slide image classification
Zhengrui Guo, Conghao Xiong, Jiabo Ma, et al. Focus: Knowledge-enhanced adaptive visual compression for few-shot whole slide image classification. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 15590–15600, 2025
2025
-
[51]
Slidechat: A large vision-language assistant for whole-slide pathol- ogy image understanding
Ying Chen, Guoan Wang, Yuanfeng Ji, et al. Slidechat: A large vision-language assistant for whole-slide pathol- ogy image understanding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5134–5143, 2025
2025
-
[52]
Wsi-vqa: Interpreting whole slide images by generative visual question answering
Pingyi Chen, Chenglu Zhu, Sunyi Zheng, Honglin Li, and Lin Yang. Wsi-vqa: Interpreting whole slide images by generative visual question answering. InEuropean Conference on Computer Vision, pages 401–417. Springer, 2024. 12
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.