A unified multi-task framework enables interpretable chest radiograph analysis
Pith reviewed 2026-06-28 10:54 UTC · model grok-4.3
The pith
A unified transformer sequentially executes four chest X-ray tasks to create traceable diagnostic pathways from images to reports.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a single transformer architecture, after medical-domain instruction tuning, can carry out multi-label disease classification, lesion localization, anatomical segmentation, and radiology report generation in sequence, thereby producing evidence-integrated reports whose decision pathways can be followed from anatomical findings to final conclusions.
What carries the argument
The unified transformer that sequentially executes the four tasks after medical-domain instruction tuning, linking image features through intermediate outputs to the final report.
Load-bearing premise
That running the four tasks in sequence inside one model creates genuinely traceable pathways without hidden interference between tasks or leakage from training data.
What would settle it
A review in which radiologists examine the model's intermediate localization and segmentation maps and find they do not support the reasoning stated in the generated report.
Figures

read the original abstract
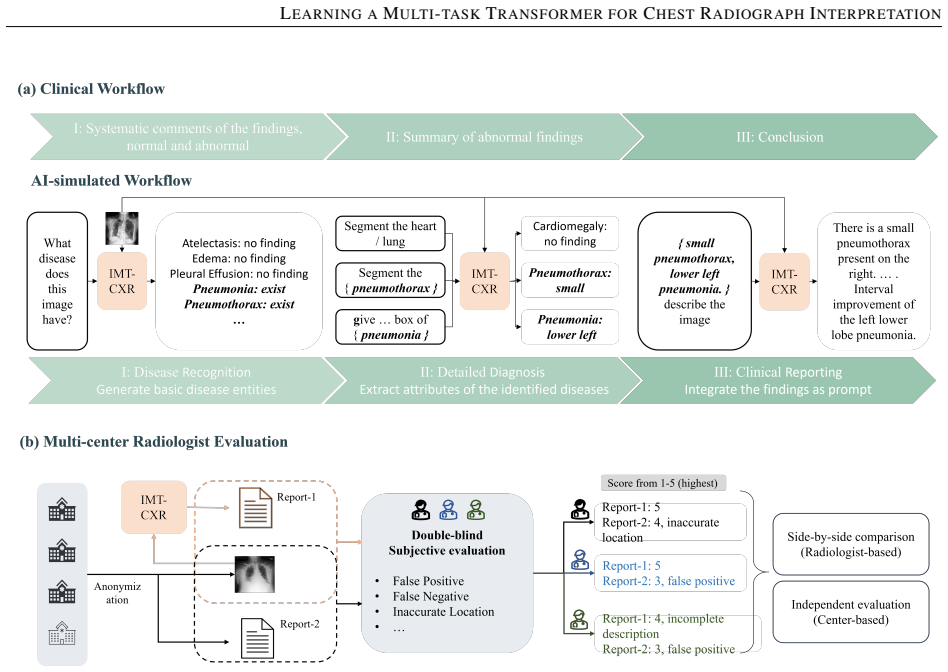
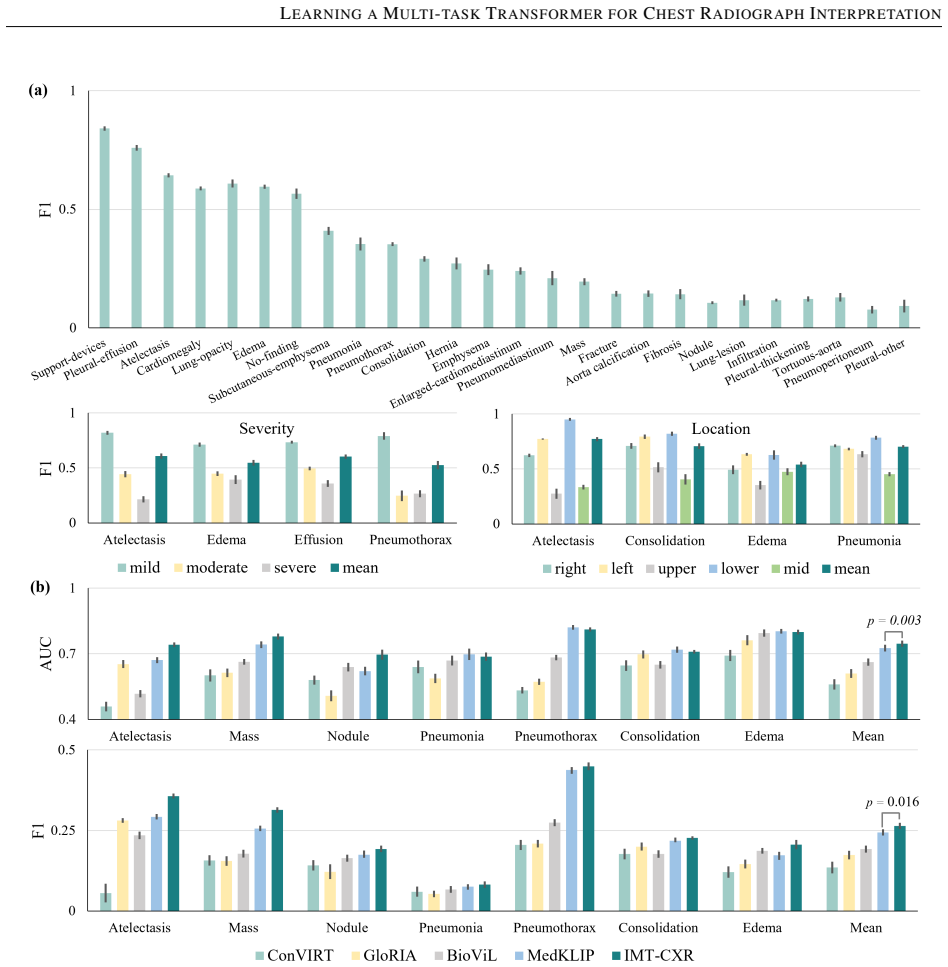
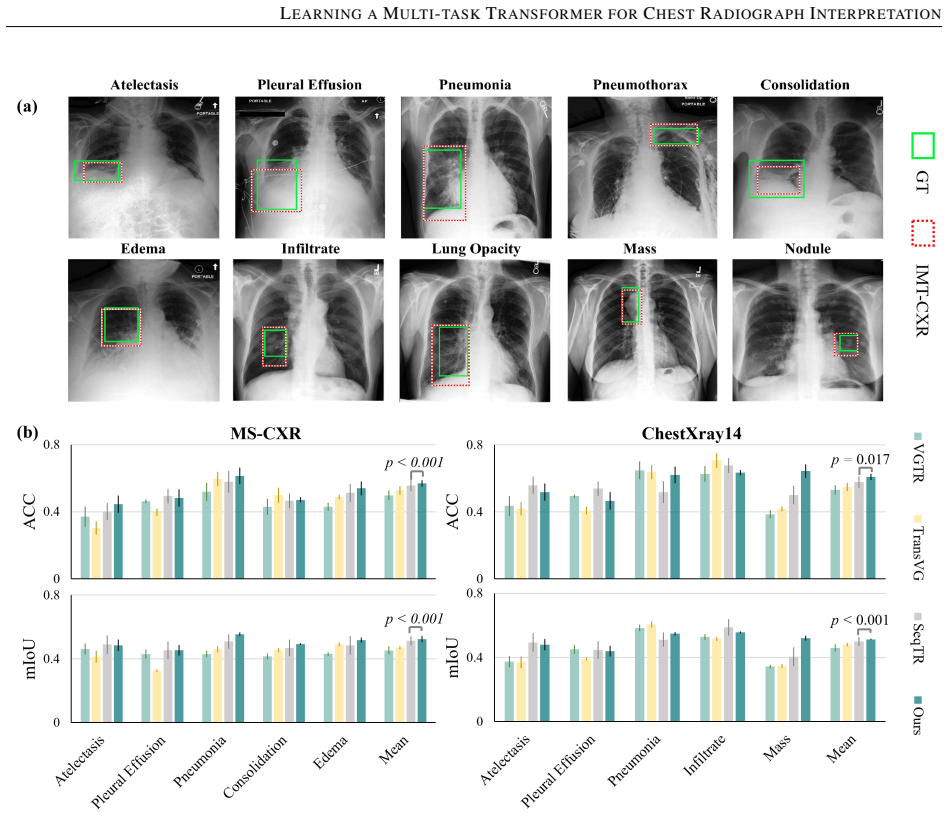
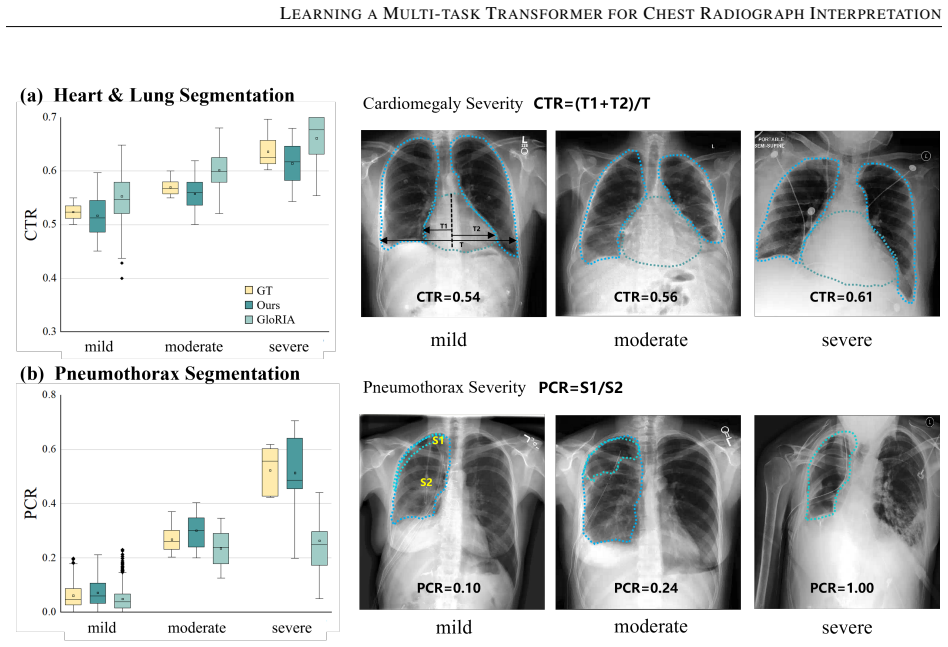
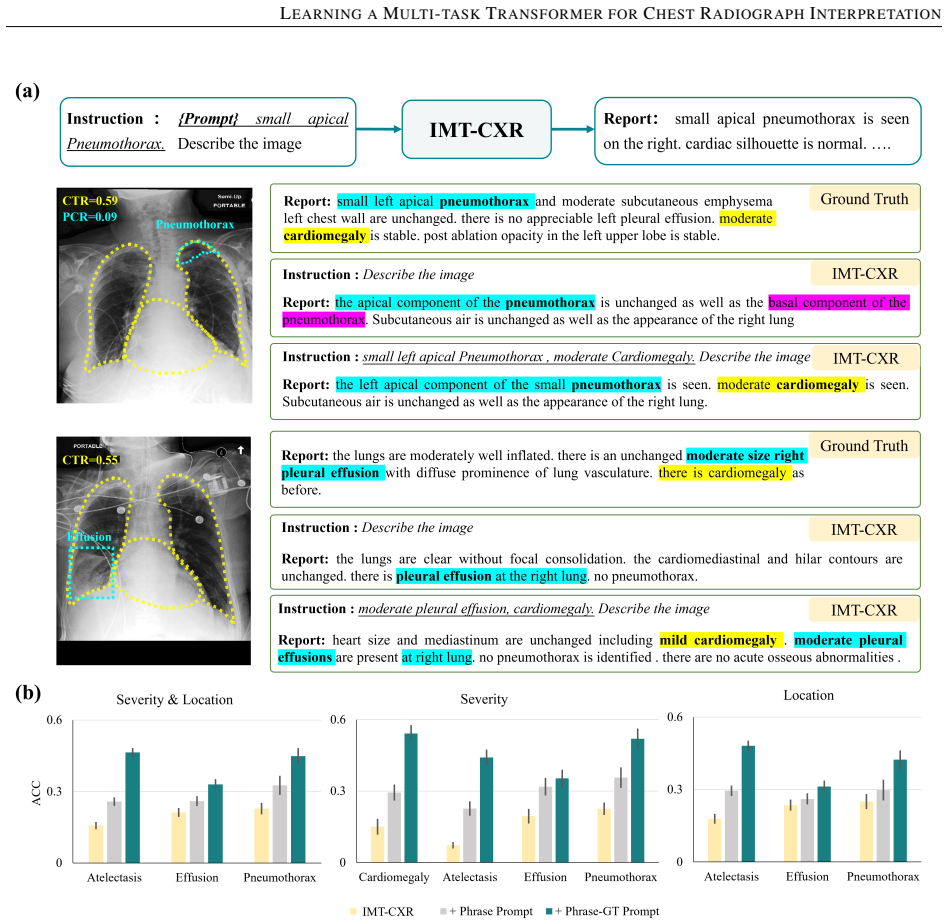
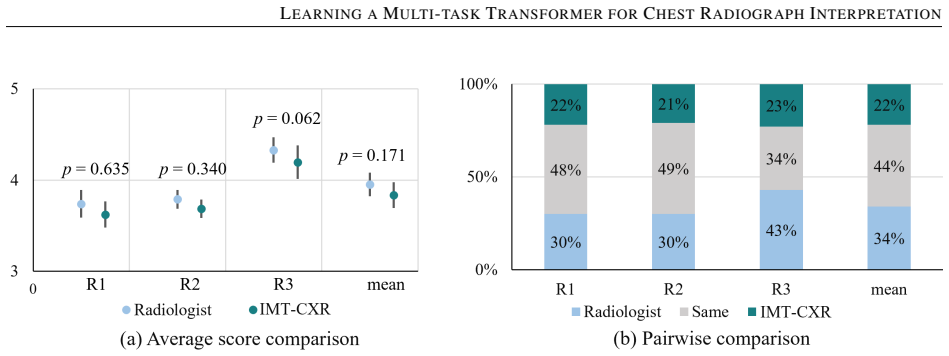
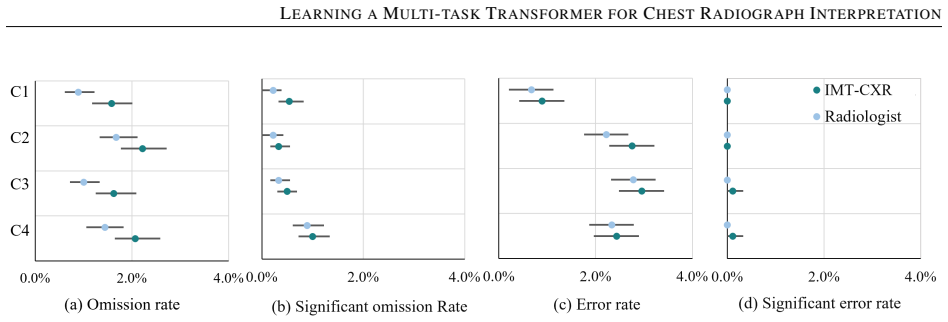
While multimodal deep learning has advanced medical imaging analysis, existing black-box systems \textcolor{black}{may remain confined to isolated tasks, often overlooking} the trust-sensitive nature of clinical diagnosis as a multi-task process. We propose IMT-CXR (Interpretable Multi-task Transformer for Chest X-ray Analysis), a framework that emulates radiologists' diagnostic workflow through three evidence-driven stages: 1) Disease recognition; 2) Attribute characterization (e.g., size, location, severity quantification); 3) Evidence-integrated report generation with traceable decision pathways. The framework employs a unified transformer architecture optimized via medical-domain instruction tuning, sequentially executing four clinical tasks: multi-label disease classification, lesion localization, anatomical segmentation, and radiology report generation. Experimental validation demonstrates competitive performance on ten CXR benchmarks under direct inference and fine-tuning settings. In a blinded evaluation of 160 historical reports from four medical centers, three radiologists rated 66\% of AI-generated reports as comparable to or surpassing original clinical reports in diagnostic clarity, highlighting the framework's translational potential. By establishing traceable diagnostic pathways from anatomical findings to conclusions, this work bridges the gap between AI technical metrics and clinical utility, advancing trustworthy AI systems in medical imaging.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes IMT-CXR, a unified transformer framework for chest X-ray analysis that emulates radiologists' workflow via sequential execution of four tasks (multi-label disease classification, lesion localization, anatomical segmentation, and radiology report generation) using medical-domain instruction tuning. It claims this yields traceable decision pathways from anatomical findings to conclusions, with competitive performance on ten CXR benchmarks under direct inference and fine-tuning, and a blinded study where three radiologists rated 66% of 160 AI-generated reports from four centers as comparable or superior to original clinical reports in diagnostic clarity.
Significance. If substantiated, the work could advance trustworthy AI in medical imaging by connecting multi-task technical performance to clinical interpretability and workflow emulation, addressing the trust gap in black-box systems.
major comments (2)
- [Abstract] Abstract: The statement that 'experimental validation demonstrates competitive performance on ten CXR benchmarks' supplies no quantitative metrics, baselines, error bars, or optimization details for the multi-task setup, preventing verification that the data support the central claims of competitiveness and translational potential.
- [Experimental validation] Experimental validation paragraph: No ablation (joint vs. sequential training) or proxy metric (e.g., attention alignment with lesion masks, path consistency across tasks) is reported to isolate whether the unified transformer produces interference-free traceable pathways, which is load-bearing for the claim that sequential execution emulates radiologist workflow without hidden biases or data leakage.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment point-by-point below, proposing revisions where they strengthen the manuscript without misrepresenting our results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The statement that 'experimental validation demonstrates competitive performance on ten CXR benchmarks' supplies no quantitative metrics, baselines, error bars, or optimization details for the multi-task setup, preventing verification that the data support the central claims of competitiveness and translational potential.
Authors: We agree that the abstract would benefit from explicit quantitative support. In the revised manuscript we will expand the abstract to report key metrics (e.g., AUC ranges, mAP, Dice scores, and report-generation BLEU/METEOR scores) together with the primary baselines used, while preserving the existing word limit and overall claims. revision: yes
-
Referee: [Experimental validation] Experimental validation paragraph: No ablation (joint vs. sequential training) or proxy metric (e.g., attention alignment with lesion masks, path consistency across tasks) is reported to isolate whether the unified transformer produces interference-free traceable pathways, which is load-bearing for the claim that sequential execution emulates radiologist workflow without hidden biases or data leakage.
Authors: The referee is correct that the current manuscript does not contain an explicit joint-versus-sequential ablation or quantitative proxy metrics for pathway consistency. While the multi-task benchmark results and the blinded radiologist study provide indirect support for the absence of catastrophic interference, we acknowledge that direct evidence would strengthen the interpretability claim. We will therefore add (i) a controlled ablation comparing joint multi-task training against sequential task-specific fine-tuning and (ii) a proxy analysis of attention-map overlap with lesion localization masks in the revised experimental section. revision: yes
Circularity Check
No circularity: empirical framework with no derivation chain
full rationale
The manuscript describes a multi-task transformer framework (IMT-CXR) that sequentially performs disease classification, lesion localization, segmentation, and report generation via medical instruction tuning. All central claims rest on reported benchmark scores across ten CXR datasets and a blinded radiologist preference study (66% of generated reports rated comparable or better). No equations, fitted parameters renamed as predictions, self-citation load-bearing uniqueness theorems, or ansatzes appear in the abstract or described experiments. The architecture is presented as an engineering choice whose value is assessed externally by performance metrics, rendering the work self-contained with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Learnable Token Sparsification for Efficient Gigapixel Whole Slide Image Reasoning
Learnable sparsification framework compresses WSI visual tokens to 32 (0.78% of original) via SparseLearn, achieving 73.32% accuracy on SlideBench (TCGA) and outperforming baselines.
Reference graph
Works this paper leans on
-
[1]
A foundation model for generalizable disease diagnosis in chest x-ray images
Lijian Xu, Ziyu Ni, Hao Sun, Hongsheng Li, and Shaoting Zhang. A foundation model for generalizable disease diagnosis in chest x-ray images. arXiv preprint arXiv:2410.08861, 2024
arXiv 2024
-
[2]
Lijian Xu, Hao Sun, Ziyu Ni, Hongsheng Li, and Shaoting Zhang. Medvilam: A multimodal large language model with advanced generalizability and explainability for medical data understanding and generation. arXiv preprint arXiv:2409.19684, 2024
arXiv 2024
-
[3]
Efficient chest x-ray representation learning via semantic- partitioned contrastive learning
Wangyu Feng, Shawn Y oung, and Lijian Xu. Efficient chest x-ray representation learning via semantic- partitioned contrastive learning. arXiv preprint arXiv:2603.07113, 2026. 18 LEARNING A MULTI -TASK TRANSFORMER FOR CHEST RADIOGRAPH INTERPRETATION
arXiv 2026
-
[4]
Xrayclaw: Cooperative-competitive multi-agent alignment for trustworthy chest x-ray diagnosis
Shawn Y oung and Lijian Xu. Xrayclaw: Cooperative-competitive multi-agent alignment for trustworthy chest x-ray diagnosis. arXiv preprint arXiv:2604.02695, 2026
Pith/arXiv arXiv 2026
-
[5]
An image is worth 16x16 words: Transformers for image recognition at scale, 2021
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale, 2021
2021
-
[6]
Swin trans- former: Hierarchical vision transformer using shifted windows
Ze Liu, Y utong Lin, Y ue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin trans- former: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision , pages 10012–10022, 2021
2021
-
[7]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018
Pith/arXiv arXiv 2018
-
[8]
Llama: Open and efficient foundation language models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Bap- tiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023
Pith/arXiv arXiv 2023
-
[9]
Palm: Scaling language modeling with pathways
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. Journal of Machine Learning Research , 24(240):1–113, 2023
2023
-
[10]
Glam: Efficient scaling of language models with mixture-of-experts
Nan Du, Y anping Huang, Andrew M Dai, Simon Tong, Dmitry Lepikhin, Y uanzhong Xu, Maxim Krikun, Y anqi Zhou, Adams Wei Y u, Orhan Firat, et al. Glam: Efficient scaling of language models with mixture-of-experts. In International Conference on Machine Learning , pages 5547–5569. PMLR, 2022
2022
-
[11]
Glm-130b: An open bilingual pre-trained model
Aohan Zeng, Xiao Liu, Zhengxiao Du, Zihan Wang, Hanyu Lai, Ming Ding, Zhuoyi Y ang, Yifan Xu, Wendi Zheng, Xiao Xia, et al. Glm-130b: An open bilingual pre-trained model. arXiv preprint arXiv:2210.02414 , 2022
Pith/arXiv arXiv 2022
-
[12]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sand- hini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems , 35:27730–27744, 2022
2022
-
[13]
Towards expert-level medical question answering with large language models
Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Le Hou, Kevin Clark, Stephen Pfohl, Heather Cole-Lewis, Darlene Neal, et al. Towards expert-level medical question answering with large language models. arXiv preprint arXiv:2305.09617, 2023
Pith/arXiv arXiv 2023
-
[14]
One leaf reveals the season: Occlusion-based contrastive learning with semantic-aware views for efficient visual representation
Xiaoyu Y ang, Lijian Xu, Hongsheng Li, and Shaoting Zhang. One leaf reveals the season: Occlusion-based contrastive learning with semantic-aware views for efficient visual representation. In International Conference on Machine Learning, pages 71425–71440, 2025
2025
-
[15]
Shawn Y oung, Xingyu Zeng, and Lijian Xu. Fewer tokens, greater scaling: Self-adaptive visual bases for efficient and expansive representation learning. arXiv preprint arXiv:2511.19515, 2026
arXiv 2026
-
[16]
The model knows which tokens matter:automatic token selection via noise gating
Landi He, Xiaoyu Y ang, and Lijian Xu. The model knows which tokens matter:automatic token selection via noise gating. arXiv preprint arXiv:2603.07135, 2026
arXiv 2026
-
[17]
Segmentation and vascular vectorization for coronary artery by geometry-based cascaded neural network
Xiaoyu Y ang, Lijian Xu, Simon Y u, Qing Xia, Hongsheng Li, and Shaoting Zhang. Segmentation and vascular vectorization for coronary artery by geometry-based cascaded neural network. IEEE Transactions on Medical Imaging, 44(1):259–269, 2024
2024
-
[18]
Zhao, Kelvin Guu, Adams Wei Y u, Brian Lester, Nan Du, Andrew M
Jason Wei, Maarten Bosma, Vincent Y . Zhao, Kelvin Guu, Adams Wei Y u, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V . Le. Finetuned language models are zero-shot learners, 2022
2022
-
[19]
Scaling instruction-finetuned language models
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Y unxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. Scaling instruction-finetuned language models. Journal of Machine Learning Research, 25(70):1–53, 2024
2024
-
[20]
Zerosense: How vision matters in long context compression
Y onghan Gao, Zehong Chen, Lijian Xu, Jingzhi Chen, Jingwei Guan, and Xingyu Zeng. Zerosense: How vision matters in long context compression. arXiv preprint arXiv:2603.11846, 2026
arXiv 2026
-
[21]
Instructblip: Towards general-purpose vision-language models with instruction tuning, 2023
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning, 2023
2023
-
[22]
Scalar: Spatial- concept alignment for robust vision in harsh open world
Xiaoyu Y ang, Lijian Xu, Xingyu Zeng, Xiaosong Wang, Hongsheng Li, and Shaoting Zhang. Scalar: Spatial- concept alignment for robust vision in harsh open world. Pattern Recognition, page 113203, 2026
2026
-
[23]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Y ong Jae Lee. Visual instruction tuning. Advances in neural information processing systems, 36, 2024. 19 LEARNING A MULTI -TASK TRANSFORMER FOR CHEST RADIOGRAPH INTERPRETATION
2024
-
[24]
Med-bert: pretrained contextualized embeddings on large-scale structured electronic health records for disease prediction
Laila Rasmy, Y ang Xiang, Ziqian Xie, Cui Tao, and Degui Zhi. Med-bert: pretrained contextualized embeddings on large-scale structured electronic health records for disease prediction. NPJ digital medicine, 4(1):86, 2021
2021
-
[25]
Large language models encode clinical knowledge
Karan Singhal, Shekoofeh Azizi, Tao Tu, S Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, et al. Large language models encode clinical knowledge. Nature, 620(7972):172–180, 2023
2023
-
[26]
Foundation models for generalist medical artificial intelligence
Michael Moor, Oishi Banerjee, Zahra Shakeri Hossein Abad, Harlan M Krumholz, Jure Leskovec, Eric J Topol, and Pranav Rajpurkar. Foundation models for generalist medical artificial intelligence. Nature, 616(7956):259– 265, 2023
2023
-
[27]
A generalist vision–language foundation model for diverse biomedical tasks
Kai Zhang, Rong Zhou, Eashan Adhikarla, Zhiling Y an, Yixin Liu, Jun Y u, Zhengliang Liu, Xun Chen, Brian D Davison, Hui Ren, et al. A generalist vision–language foundation model for diverse biomedical tasks. Nature Medicine, pages 1–13, 2024
2024
-
[28]
Llava-med: Training a large language-and-vision assistant for biomedicine in one day
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Y ang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. Llava-med: Training a large language-and-vision assistant for biomedicine in one day. Advances in Neural Information Processing Systems , 36, 2024
2024
-
[29]
Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports
Alistair EW Johnson, Tom J Pollard, Seth J Berkowitz, Nathaniel R Greenbaum, Matthew P Lungren, Chih- ying Deng, Roger G Mark, and Steven Horng. Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports. Scientific data, 6(1):317, 2019
2019
-
[30]
Vindr-cxr: An open dataset of chest x-rays with radiologist’s annotations
Ha Q Nguyen, Khanh Lam, Linh T Le, Hieu H Pham, Dat Q Tran, Dung B Nguyen, Dung D Le, Chi M Pham, Hang TT Tong, Diep H Dinh, et al. Vindr-cxr: An open dataset of chest x-rays with radiologist’s annotations. Scientific Data, 9(1):429, 2022
2022
-
[31]
A structure-aware relation network for thoracic diseases detection and segmentation
Jie Lian, Jingyu Liu, Shu Zhang, Kai Gao, Xiaoqing Liu, Dingwen Zhang, and Yizhou Y u. A structure-aware relation network for thoracic diseases detection and segmentation. IEEE Transactions on Medical Imaging , 40(8):2042–2052, 2021
2042
-
[32]
Chexmask: a large-scale dataset of anatomical segmentation masks for multi-center chest x-ray images
Nicolas Gaggion, Candelaria Mosquera, Lucas Mansilla, Julia Mariel Saidman, Martina Aineseder, Diego H Milone, and Enzo Ferrante. Chexmask: a large-scale dataset of anatomical segmentation masks for multi-center chest x-ray images. Scientific Data, 11(1):511, 2024
2024
-
[33]
Siim-acr pneumothorax segmentation
Anna Zawacki, Carol Wu, George Shih, Julia Elliott, Mikhail Fomitchev, Mohannad Hussain, ParasLakhani, Phil Culliton, and Shunxing Bao. Siim-acr pneumothorax segmentation. Kaggle, 2019
2019
-
[34]
Chestx- ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases
Xiaosong Wang, Yifan Peng, Le Lu, Zhiyong Lu, Mohammadhadi Bagheri, and Ronald M Summers. Chestx- ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In Proceedings of the IEEE conference on computer vision and pattern recognition , pages 2097–2106, 2017
2097
-
[35]
Chexpert: A large chest radiograph dataset with uncer- tainty labels and expert comparison
Jeremy Irvin, Pranav Rajpurkar, Michael Ko, Yifan Y u, Silviana Ciurea-Ilcus, Chris Chute, Henrik Marklund, Behzad Haghgoo, Robyn Ball, Katie Shpanskaya, et al. Chexpert: A large chest radiograph dataset with uncer- tainty labels and expert comparison. In Proceedings of the AAAI conference on artificial intelligence , volume 33, pages 590–597, 2019
2019
-
[36]
Augmenting the national institutes of health chest radiograph dataset with expert annotations of possible pneumonia
George Shih, Carol C Wu, Safwan S Halabi, Marc D Kohli, Luciano M Prevedello, Tessa S Cook, Arjun Sharma, Judith K Amorosa, V eronica Arteaga, Maya Galperin-Aizenberg, et al. Augmenting the national institutes of health chest radiograph dataset with expert annotations of possible pneumonia. Radiology: Artificial Intelligence, 1(1):e180041, 2019
2019
-
[37]
Junji Shiraishi, Shigehiko Katsuragawa, Junpei Ikezoe, Tsuneo Matsumoto, Takeshi Kobayashi, Ken-ichi Ko- matsu, Mitate Matsui, Hiroshi Fujita, Y oshie Kodera, and Kunio Doi. Development of a digital image database for chest radiographs with and without a lung nodule: receiver operating characteristic analysis of radiologists’ detection of pulmonary nodule...
2000
-
[38]
Making the most of text semantics to improve biomedical vision–language processing
Benedikt Boecking, Naoto Usuyama, Shruthi Bannur, Daniel C Castro, Anton Schwaighofer, Stephanie Hyland, Maria Wetscherek, Tristan Naumann, Aditya Nori, Javier Alvarez-V alle, et al. Making the most of text semantics to improve biomedical vision–language processing. In European conference on computer vision , pages 1–21. Springer, 2022
2022
-
[39]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In ICML, pages 1597–1607. PMLR, 2020
2020
-
[40]
Contrastive learning of medical visual representations from paired images and text
Y uhao Zhang, Hang Jiang, Y asuhide Miura, Christopher D Manning, and Curtis P Langlotz. Contrastive learning of medical visual representations from paired images and text. In Machine Learning for Healthcare Conference , pages 2–25. PMLR, 2022. 20 LEARNING A MULTI -TASK TRANSFORMER FOR CHEST RADIOGRAPH INTERPRETATION
2022
-
[41]
Lungren, and Serena Y eung
Shih-Cheng Huang, Liyue Shen, Matthew P . Lungren, and Serena Y eung. Gloria: A multimodal global-local representation learning framework for label-efficient medical image recognition. 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 3922–3931, 2021
2021
-
[42]
Generalized radiograph representation learning via cross-supervision between images and free-text radiology reports
Hong-Y u Zhou, Xiaoyu Chen, Yinghao Zhang, Ruibang Luo, Liansheng Wang, and Yizhou Y u. Generalized radiograph representation learning via cross-supervision between images and free-text radiology reports. Nature Machine Intelligence, 4(1):32–40, 2022
2022
-
[43]
Multimodal masked autoencoders learn transferable representations, 2022
Xinyang Geng, Hao Liu, Lisa Lee, Dale Schuurmans, Sergey Levine, and Pieter Abbeel. Multimodal masked autoencoders learn transferable representations, 2022
2022
-
[44]
Multi-granularity cross-modal alignment for generalized medical visual representation learning
Fuying Wang, Y uyin Zhou, Shujun Wang, V arut V ardhanabhuti, and Lequan Y u. Multi-granularity cross-modal alignment for generalized medical visual representation learning. Advances in Neural Information Processing Systems, 35:33536–33549, 2022
2022
-
[45]
Medklip: Medical knowledge enhanced language-image pre-training for x-ray diagnosis
Chaoyi Wu, Xiaoman Zhang, Y a Zhang, Y anfeng Wang, and Weidi Xie. Medklip: Medical knowledge enhanced language-image pre-training for x-ray diagnosis. In ICCV, pages 21372–21383, 2023
2023
-
[46]
Delving into masked autoencoders for multi-label thorax disease classification
Junfei Xiao, Y utong Bai, Alan Y uille, and Zongwei Zhou. Delving into masked autoencoders for multi-label thorax disease classification. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 3588–3600, 2023
2023
-
[47]
Advancing radiograph representation learning with masked record modeling
Hong-Y u Zhou, Chenyu Lian, Liansheng Wang, and Yizhou Y u. Advancing radiograph representation learning with masked record modeling. In The Eleventh International Conference on Learning Representations , 2023
2023
-
[48]
Visual grounding with transformers.2022 IEEE International Conference on Multimedia and Expo , pages 1–6, 2022
Y e Du, Zehua Fu, Qingjie Liu, and Y unhong Wang. Visual grounding with transformers.2022 IEEE International Conference on Multimedia and Expo , pages 1–6, 2022
2022
-
[49]
Seqtr: A simple yet universal network for visual grounding
Chaoyang Zhu, Yiyi Zhou, Y unhang Shen, Gen Luo, Xingjia Pan, Mingbao Lin, Chao Chen, Liujuan Cao, Xiaoshuai Sun, and Rongrong Ji. Seqtr: A simple yet universal network for visual grounding. In European Conference on Computer Vision, pages 598–615. Springer, 2022
2022
-
[50]
Transvg: End-to-end visual grounding with transformers
Jiajun Deng, Zhengyuan Y ang, Tianlang Chen, Wengang Zhou, and Houqiang Li. Transvg: End-to-end visual grounding with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 1769–1779, October 2021
2021
-
[51]
Medical phrase grounding with region-phrase context contrastive alignment
Zhihao Chen, Y ang Zhou, Anh Tran, Junting Zhao, Liang Wan, Gideon Su Kai Ooi, Lionel Tim-Ee Cheng, Choon Hua Thng, Xinxing Xu, Y ong Liu, et al. Medical phrase grounding with region-phrase context contrastive alignment. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 371–381. Springer, 2023
2023
-
[52]
Chex: Interactive localization and region description in chest x-rays
Philip Muller, Georgios Kaissis, and Daniel Rueckert. Chex: Interactive localization and region description in chest x-rays. In European Conference on Computer Vision, pages 92–111. Springer, 2025
2025
-
[53]
Knowledge-enhanced visual-language pre-training on chest radiology images
Xiaoman Zhang, Chaoyi Wu, Y a Zhang, Weidi Xie, and Y anfeng Wang. Knowledge-enhanced visual-language pre-training on chest radiology images. Nature Communications, 14(1):4542, 2023
2023
-
[54]
Referring transformer: A one-step approach to multi-task visual grounding
Muchen Li and Leonid Sigal. Referring transformer: A one-step approach to multi-task visual grounding. Ad- vances in neural information processing systems , 34:19652–19664, 2021
2021
-
[55]
Bottom-up and top-down attention for image captioning and visual question answering
Peter Anderson, Xiaodong He, Chris Buehler, Damien Teney, Mark Johnson, Stephen Gould, and Lei Zhang. Bottom-up and top-down attention for image captioning and visual question answering. In CVPR, pages 6077– 6086, 2018
2018
-
[56]
Self-critical sequence training for image captioning
Steven J Rennie, Etienne Marcheret, Y oussef Mroueh, Jerret Ross, and V aibhava Goel. Self-critical sequence training for image captioning. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7008–7024, 2017
2017
-
[57]
Cross-modal memory networks for radiology report generation
Zhihong Chen, Y aling Shen, Y an Song, and Xiang Wan. Cross-modal memory networks for radiology report generation. In ACL-IJCNLP V olume 1: Long Papers, pages 5904–5914, 2021
2021
-
[58]
Con- trastive attention for automatic chest x-ray report generation, 2023
Fenglin Liu, Changchang Yin, Xian Wu, Shen Ge, Y uexian Zou, Ping Zhang, Y uexian Zou, and Xu Sun. Con- trastive attention for automatic chest x-ray report generation, 2023
2023
-
[59]
Interactive and explainable region-guided radiology report generation
Tim Tanida, Philip Muller, Georgios Kaissis, and Daniel Rueckert. Interactive and explainable region-guided radiology report generation. In CVPR, pages 7433–7442, 2023
2023
-
[60]
Multimodal image-text matching improves retrieval-based chest x-ray report generation
Jaehwan Jeong, Katherine Tian, Andrew Li, Sina Hartung, Subathra Adithan, Fardad Behzadi, Juan Calle, David Osayande, Michael Pohlen, and Pranav Rajpurkar. Multimodal image-text matching improves retrieval-based chest x-ray report generation. In Medical Imaging with Deep Learning , pages 978–990. PMLR, 2024. 21 LEARNING A MULTI -TASK TRANSFORMER FOR CHEST...
2024
-
[61]
A deep-learning-based framework for identifying and localizing multiple abnormalities and assessing cardiomegaly in chest x-ray
Weijie Fan, Yi Y ang, Jing Qi, Qichuan Zhang, Cuiwei Liao, Li Wen, Shuang Wang, Guangxian Wang, Y u Xia, Qihua Wu, et al. A deep-learning-based framework for identifying and localizing multiple abnormalities and assessing cardiomegaly in chest x-ray. Nature Communications, 15(1):1347, 2024
2024
-
[62]
Maira-2: Grounded radiology report generation
Shruthi Bannur, Kenza Bouzid, Daniel C Castro, Anton Schwaighofer, Sam Bond-Taylor, Maximilian Ilse, Fer- nando Perez-Garcia, V alentina Salvatelli, Harshita Sharma, Felix Meissen, et al. Maira-2: Grounded radiology report generation. arXiv preprint arXiv:2406.04449, 2024
arXiv 2024
-
[63]
Llava-rad mimic-cxr annotations
Juan Manuel Zambrano Chaves, Shih-Cheng Huang, Y anbo Xu, Hanwen Xu, Naoto Usuyama, Sheng Zhang, Fei Wang, Y ujia Xie, Mahmoud Khademi, Ziyi Y ang, Hany Awadalla, Julia Gong, Houdong Hu, Jianwei Y ang, Chunyuan Li, Jianfeng Gao, Y u Gu, Cliff Wong, Mu-Hsin Wei, Tristan Naumann, Muhao Chen, Matthew Lun- gren, Akshay Chaudhari, Serena Y eung, Curtis Langlot...
2025
-
[64]
Cxr-llava: a multimodal large language model for interpreting chest x-ray images
Seowoo Lee, Jiwon Y oun, Hyungjin Kim, Mansu Kim, and Soon Ho Y oon. Cxr-llava: a multimodal large language model for interpreting chest x-ray images. European Radiology, pages 1–13, 2025
2025
-
[65]
Chexagent: Towards a foundation model for chest x-ray interpretation
Zhihong Chen, Maya V arma, Jean-Benoit Delbrouck, Magdalini Paschali, Louis Blankemeier, Dave V an V een, Jeya Maria Jose V alanarasu, Alaa Y oussef, Joseph Paul Cohen, Eduardo Pontes Reis, et al. Chexagent: Towards a foundation model for chest x-ray interpretation. In AAAI 2024 Spring Symposium on Clinical F oundation Models, 2024
2024
-
[66]
A deepseek-powered ai system for automated chest radiograph interpretation in clinical practice
Y aowei Bai, Ruiheng Zhang, Y u Lei, Xuhua Duan, Jingfeng Y ao, Shuguang Ju, Chaoyang Wang, Wei Y ao, Yiwan Guo, Guilin Zhang, et al. A deepseek-powered ai system for automated chest radiograph interpretation in clinical practice. arXiv preprint arXiv:2512.20344, 2025
arXiv 2025
-
[67]
A generalist learner for multifaceted medical image interpretation
Hong-Y u Zhou, Subathra Adithan, Julian Nicolas Acosta, Eric J Topol, and Pranav Rajpurkar. A generalist learner for multifaceted medical image interpretation. arXiv preprint arXiv:2405.07988, 2024
arXiv 2024
-
[68]
Tc-ssa: Token compression via semantic slot aggregation for gigapixel pathology reasoning
Zhuo Chen, Shawn Y oung, and Lijian Xu. Tc-ssa: Token compression via semantic slot aggregation for gigapixel pathology reasoning. arXiv preprint arXiv:2603.01143, 2026
arXiv 2026
-
[69]
Ofa: Unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework, 2022
Peng Wang, An Y ang, Rui Men, Junyang Lin, Shuai Bai, Zhikang Li, Jianxin Ma, Chang Zhou, Jingren Zhou, and Hongxia Y ang. Ofa: Unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework, 2022
2022
-
[70]
Pix2seq: A language modeling framework for object detection
Ting Chen, Saurabh Saxena, Lala Li, David J Fleet, and Geoffrey Hinton. Pix2seq: A language modeling framework for object detection. In International Conference on Learning Representations , 2021
2021
-
[71]
Unified-io: A unified model for vision, language, and multi-modal tasks
Jiasen Lu, Christopher Clark, Rowan Zellers, Roozbeh Mottaghi, and Aniruddha Kembhavi. Unified-io: A unified model for vision, language, and multi-modal tasks. In The Eleventh International Conference on Learning Representations, 2022
2022
-
[72]
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, V es Stoy- anov, and Luke Zettlemoyer. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461, 2019
Pith/arXiv arXiv 1910
-
[73]
Improving language understanding by generative pre-training
Alec Radford and Karthik Narasimhan. Improving language understanding by generative pre-training. 2018
2018
-
[74]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages 311–318, 2002
2002
-
[75]
Rouge: A package for automatic evaluation of summaries
Chin-Y ew Lin. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out, pages 74–81, 2004
2004
-
[76]
Evaluating progress in automatic chest x-ray radiology report generation
Feiyang Y u, Mark Endo, Rayan Krishnan, Ian Pan, Andy Tsai, Eduardo Pontes Reis, Eduardo Kaiser Uru- rahy Nunes Fonseca, Henrique Min Ho Lee, Zahra Shakeri Hossein Abad, Andrew Y Ng, et al. Evaluating progress in automatic chest x-ray radiology report generation. Patterns, 4(9), 2023
2023
-
[77]
Shawn Xu, Lin Y ang, Christopher Kelly, Marcin Sieniek, Timo Kohlberger, Martin Ma, Wei-Hung Weng, At- tila Kiraly, Sahar Kazemzadeh, Zakkai Melamed, et al. Elixr: Towards a general purpose x-ray artificial in- telligence system through alignment of large language models and radiology vision encoders. arXiv preprint arXiv:2308.01317, 2023
arXiv 2023
-
[78]
A foundation model for generalizable disease detection from retinal images
Y ukun Zhou, Mark A Chia, Siegfried K Wagner, Murat S Ayhan, Dominic J Williamson, Robbert R Struyven, Timing Liu, Moucheng Xu, Mateo G Lozano, Peter Woodward-Court, et al. A foundation model for generalizable disease detection from retinal images. Nature, 622(7981):156–163, 2023. 22 LEARNING A MULTI -TASK TRANSFORMER FOR CHEST RADIOGRAPH INTERPRETATION A...
2023
-
[79]
What disease does this image have?
Disease Classification Dataset includes entity information across 193 categories and 0.24M images. For the entity classification task, the instruction is "What disease does this image have?". The answer includes all possible diseases present in the data, such as "pneumonia" and "atelectasis.", "Is Pneumonia in this image?". The response can be either "yes" ...
-
[80]
Give the accurate bounding box of {}
Lesion Localization Dataset incorporates VinDR-CXR, ChestX-Det, and In-house datasets, consisting of 0.09M images and corresponding BBox for 12 diseases. The instruction given for the lesion localization task is "Give the accurate bounding box of {}.". Here, the placeholder {} represents the category of the specific disease, such as "pneumonia, in the lowe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.