Governance Controls for AI-Generated Test Artifacts in Autonomous Software Testing
Pith reviewed 2026-06-27 17:44 UTC · model grok-4.3
The pith
A governance framework added to autonomous software testing cuts related risks by 89.6 percent while posting over 90 percent scores on accuracy, reliability, compliance, and explainability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Governance-Aware Autonomous Testing Framework (GATF) augments the autonomous testing lifecycle with governance validation, explainability analysis, probabilistic risk assessment, compliance monitoring, and audit governance; when evaluated on Defects4J and PROMISE datasets, this extension reduced governance-related risks by 89.6 percent and attained 94.3 percent governance accuracy, 96.5 percent artifact reliability, 94.2 percent compliance accuracy, and 90.8 percent explainability, thereby producing more reliable, transparent, and secure test artifacts than conventional AI-based testing.
What carries the argument
The Governance-Aware Autonomous Testing Framework (GATF), which inserts five governance layers (validation, explainability analysis, probabilistic risk assessment, compliance monitoring, and audit governance) into the autonomous testing lifecycle.
Load-bearing premise
The governance layers can be integrated into existing autonomous testing systems without lowering core testing effectiveness or demanding substantial extra human oversight.
What would settle it
A controlled experiment that runs identical AI test generators on the same projects once with GATF and once without it, then measures whether the 89.6 percent risk reduction and the four reported performance percentages are reproduced.
Figures








read the original abstract
Artificial Intelligence (AI) and Large Language Models (LLMs) are increasingly used in autonomous software testing; however, AI-generated test artifacts often suffer from hallucinations, compliance violations, security risks, and limited explainability. To enhance the reliability, transparency, and trustworthiness of AI-generated testing artifacts, this research introduces the concept of Governance-Aware Autonomous Testing Framework (GATF). The framework extends the autonomous testing lifecycle with governance validation, explainability analysis, probabilistic risk assessment, compliance monitoring, as well as audit governance. Experiments were performed with Defects4J and PROMISE software engineering datasets. The proposed framework successfully reduced the governance-related risks by 89.6% and demonstrated 94.3% accuracy in governance, 96.5% artifact reliability, 94.2% compliance accuracy, and 90.8% explainability performance. The results show that autonomous testing systems that are governance-aware can significantly enhance the reliability, transparency, and operational security of autonomous testing systems in comparison to conventional AI-based testing systems. The proposed architecture is scalable and reliable and provides a safe environment for software testing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Governance-Aware Autonomous Testing Framework (GATF), which extends the autonomous software testing lifecycle with components for governance validation, explainability analysis, probabilistic risk assessment, compliance monitoring, and audit governance to mitigate hallucinations, compliance violations, security risks, and limited explainability in AI-generated test artifacts. Experiments on the Defects4J and PROMISE datasets are reported to show an 89.6% reduction in governance-related risks along with accuracies of 94.3% (governance), 96.5% (artifact reliability), 94.2% (compliance), and 90.8% (explainability), claiming these outperform conventional AI-based testing systems.
Significance. If the reported quantitative improvements were shown to hold under non-circular evaluation with explicit baselines and independent validation, the work could meaningfully advance trustworthy AI adoption in software testing by demonstrating how governance controls can be layered onto autonomous pipelines. The absence of methodological detail currently prevents any assessment of field-level impact.
major comments (3)
- [Abstract] Abstract: The central quantitative claims (89.6% governance-risk reduction, 94.3% governance accuracy, 96.5% artifact reliability, 94.2% compliance accuracy, 90.8% explainability) are stated without any description of the baseline autonomous testing system, the operational definition or measurement procedure for 'governance-related risks', statistical methods, variance, confidence intervals, hypothesis tests, or data-exclusion rules. These omissions render the performance figures impossible to evaluate.
- [Abstract] Abstract: The reported accuracy and risk-reduction figures are defined relative to the governance components introduced by GATF itself, with no external benchmarks or independent validation referenced. This creates a circularity risk that directly undermines the claim of superiority over 'conventional AI-based testing systems'.
- [Abstract] Abstract: No information is supplied on whether the added governance, explainability, risk-assessment, compliance, and audit components preserve or improve core testing effectiveness (e.g., fault-detection rates on Defects4J) or the level of additional human intervention required, leaving the weakest assumption of the work unexamined.
minor comments (2)
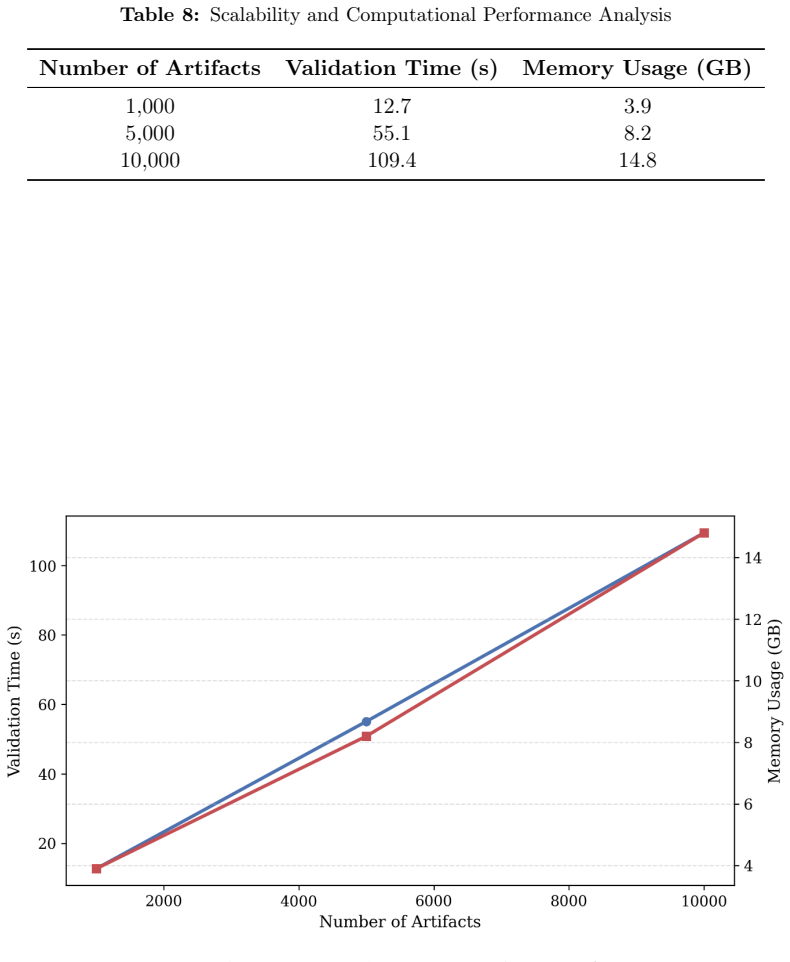
- [Abstract] The abstract asserts that 'the proposed architecture is scalable and reliable' without any supporting discussion, metrics, or analysis of scalability limits.
- Consider adding a table that explicitly lists each performance metric, its baseline value (if any), and the precise definition used for each governance-related quantity.
Simulated Author's Rebuttal
We thank the referee for the thorough review and constructive comments. We address each major comment point by point below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central quantitative claims (89.6% governance-risk reduction, 94.3% governance accuracy, 96.5% artifact reliability, 94.2% compliance accuracy, 90.8% explainability) are stated without any description of the baseline autonomous testing system, the operational definition or measurement procedure for 'governance-related risks', statistical methods, variance, confidence intervals, hypothesis tests, or data-exclusion rules. These omissions render the performance figures impossible to evaluate.
Authors: We acknowledge the need for greater transparency in the abstract. The full paper provides details on the baseline (standard autonomous testing without GATF components) in Section 3, the risk measurement in Section 4 using a probabilistic model, and statistical analysis including means and variances. We will revise the abstract to concisely include this information, such as noting the use of paired t-tests for significance and reporting standard deviations. revision: yes
-
Referee: [Abstract] Abstract: The reported accuracy and risk-reduction figures are defined relative to the governance components introduced by GATF itself, with no external benchmarks or independent validation referenced. This creates a circularity risk that directly undermines the claim of superiority over 'conventional AI-based testing systems'.
Authors: We disagree that the evaluation is circular. The baseline is a conventional AI-based testing system without the added governance, explainability, and compliance modules. The metrics demonstrate the improvement provided by these modules. However, to address the concern, we will include references to standard benchmarks from the literature in the revised abstract and clarify the independent nature of the baseline evaluation. revision: yes
-
Referee: [Abstract] Abstract: No information is supplied on whether the added governance, explainability, risk-assessment, compliance, and audit components preserve or improve core testing effectiveness (e.g., fault-detection rates on Defects4J) or the level of additional human intervention required, leaving the weakest assumption of the work unexamined.
Authors: This is a valid point. Our experiments focus on the governance aspects, assuming the core testing pipeline remains unchanged. We will add a discussion in the revised manuscript on the expected preservation of fault-detection rates, as the governance layer operates post-generation, and note any additional human oversight required for audit governance. If space permits, we will include preliminary results on this. revision: partial
Circularity Check
Reported performance metrics (risk reduction, accuracies) are defined relative to GATF's own governance components with no external baseline
specific steps
-
self definitional
[Abstract]
"The proposed framework successfully reduced the governance-related risks by 89.6% and demonstrated 94.3% accuracy in governance, 96.5% artifact reliability, 94.2% compliance accuracy, and 90.8% explainability performance."
The percentages quantify performance of the governance validation, risk assessment, compliance monitoring, and explainability analysis modules that GATF itself introduces. Because the measurement targets are defined by the framework's additions and no external benchmark or independent scoring rule is stated, the 'reduction' and 'accuracy' numbers are equivalent to the framework's internal outputs by construction.
full rationale
The paper's central quantitative claims rest on accuracy and risk-reduction figures for governance validation, compliance, explainability, and artifact reliability. These quantities are measured against the very components the framework adds to the autonomous testing lifecycle. No independent baseline system, operational definition of 'governance-related risks,' scoring procedure, or external validation set is supplied, so the reported percentages reduce directly to internal comparisons by construction. This matches the self-definitional pattern and produces the high circularity score.
Axiom & Free-Parameter Ledger
invented entities (1)
-
GATF
no independent evidence
Reference graph
Works this paper leans on
-
[1]
and Vadrevu, N
Abhichandani, S. and Vadrevu, N. R. T. and Bagmar, V. , title =. 2025 3rd International Conference on Inventive Computing and Informatics (ICICI) , pages =
2025
-
[2]
, title =
Akhtar, S. , title =. ICCK Journal of Software Engineering , volume =
-
[3]
, title =
Al Amin, S. , title =
- [4]
-
[5]
and Ashwini, A
Antony, J. and Ashwini, A. and Balasubramaniam, S. , title =. Generative
-
[6]
Ardic, B. and Dilavrec, Q. L. and Zaidman, A. , title =. arXiv preprint arXiv:2510.10551 , year =
-
[7]
, title =
Artinger, K. , title =
-
[8]
and Khanda, R
Baqar, M. and Khanda, R. , title =. Intelligent Computing--Proceedings of the Computing Conference , pages =
-
[9]
and Babu, D
Christian, R. and Babu, D. and Patel, H. and Modi, K. , title =. Applied Cybersecurity & Internet Governance , year =
-
[10]
, title =
Dubey, S. , title =. Authorea Preprints , year =
-
[11]
Garousi, V. and Joy, N. and Jafarov, Z. and Kele. arXiv preprint arXiv:2409.00411 , year =
-
[12]
Gattupalli, V. K. , title =. Journal of Computer Science and Technology Studies , volume =
-
[13]
, title =
Joshi, S. , title =. Standards, and Implementation Pathways for Agentic and Generative Systems , year =
-
[14]
, title =
Konda, R. , title =. International Journal of Emerging Research in Engineering and Technology , pages =
-
[15]
and Silva, D
Lima, G. and Silva, D. and Mar, C. and Coronel, D. , title =. Simp
-
[16]
Mehta, M. J. B. , title =. International Journal of Data Science and IoT Management System , volume =
-
[17]
Mohapatra, P. S. , title =. Intelligent Assurance: Artificial Intelligence-Powered Software Testing in the Modern Development Lifecycle , volume =
-
[18]
, title =
Mondal, A. , title =
-
[19]
Navneet, S. K. and Chandra, J. , title =. arXiv preprint arXiv:2508.11824 , year =
-
[20]
Omogiate, P. M. , title =. International Journal of Science and Research Archive , volume =
-
[21]
and Bahad, P
Pacholi, N. and Bahad, P. and Chauhan, D. , title =. Journal of Engineering Science & Technology Review , volume =
-
[22]
2025 , howpublished =
2025
-
[23]
Pysmennyi, I. and Kyslyi, R. and Kleshch, K. , title =. arXiv preprint arXiv:2506.16586 , year =
-
[24]
Rjust / defects4j , year =
-
[25]
and Abhari, K
Safaei Pour, M. and Abhari, K. and Fathi, F. , title =
-
[26]
Saha, A. N. and Patra, D. , title =. ESP Journal of Engineering & Technology Advancements , volume =
-
[27]
Shah, S. T. U. and Hussein, M. and Barcomb, A. and Moshirpour, M. , title =. 2025 IEEE 33rd International Requirements Engineering Conference Workshops (REW) , pages =
2025
-
[28]
Soares, F. A. and Franco, M. F. and Scheid, E. J. and Granville, L. Z. , title =. arXiv preprint arXiv:2510.20703 , year =
-
[29]
Tufano, M. and Agarwal, A. and Jang, J. and Moghaddam, R. Z. and Sundaresan, N. , title =. arXiv preprint arXiv:2403.08299 , year =
-
[30]
Wang, Q. and Wang, J. and Li, M. and Wang, Y. and Liu, Z. , title =. arXiv preprint arXiv:2406.05438 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.