Momentum for Reasoning: Dense Intrinsic Signals in Policy Optimization
Pith reviewed 2026-06-27 18:24 UTC · model grok-4.3
The pith
Intrinsic signals from a policy's own probabilities can densify sparse outcome rewards and reduce two structural failure modes in LLM reasoning training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
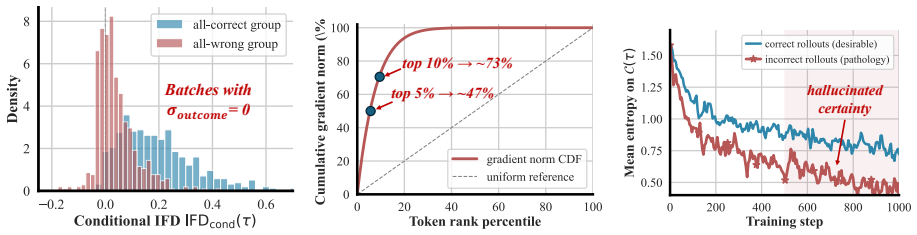
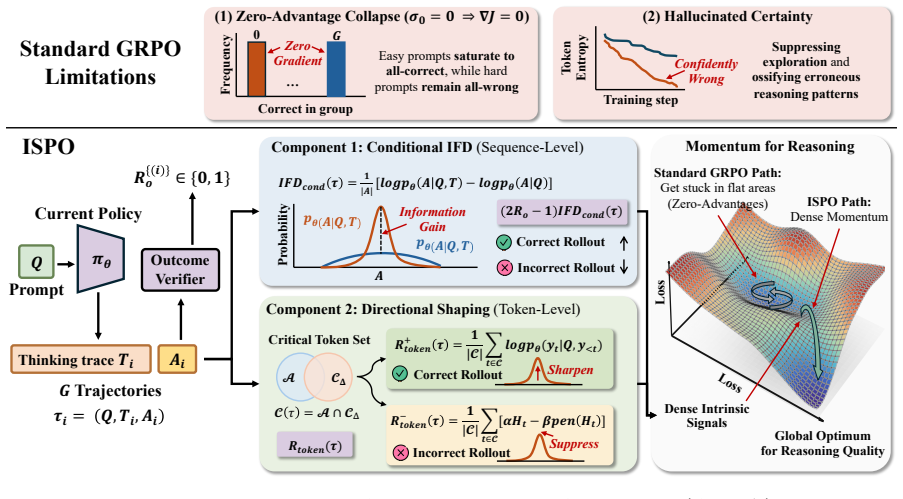
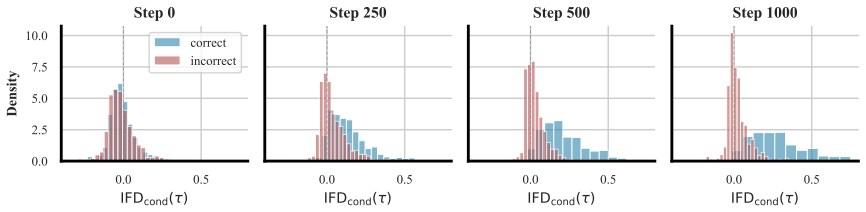
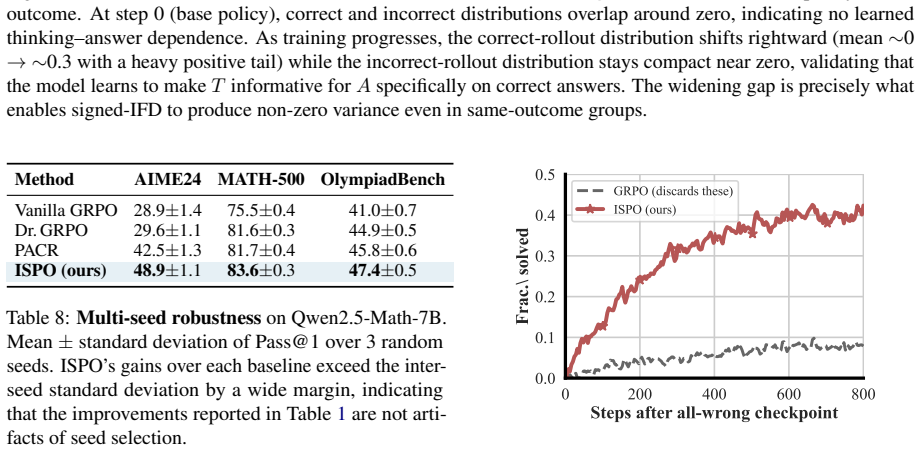
ISPO densifies the binary outcome reward by combining a sequence-level signal that measures how informative the thinking trajectory is for the final answer with a token-level directional reward whose hallucinated-certainty hinge penalizes confidently-wrong predictions at critical decision tokens; across three base models and five mathematical reasoning benchmarks this yields consistent outperformance over baselines, largest gains on the hardest benchmarks, and confirmed reductions in both zero-advantage collapse and hallucinated certainty.
What carries the argument
ISPO (Intrinsic Signal Policy Optimization), which adds sequence-level trajectory informativeness and token-level hallucinated-certainty hinge signals derived solely from the policy's conditional probabilities.
If this is right
- Performance gains are largest on the hardest benchmarks, exactly where zero-advantage collapse is most common.
- Training-dynamics measurements show both zero-advantage collapse and hallucinated certainty decrease under ISPO.
- The method delivers consistent improvements across three different base models and five benchmarks.
- Both failure modes are mitigated without requiring external verification or additional reward models.
Where Pith is reading between the lines
- The same internal-probability signals might extend to non-mathematical domains where outcome verification is costly.
- If the signals truly capture trajectory quality, they could reduce reliance on verifiable-reward setups altogether.
- Combining the token-level hinge with other forms of self-supervised shaping could further stabilize long-horizon training.
- The approach implies that policy entropy and conditional likelihoods already contain usable information about reasoning correctness.
Load-bearing premise
Signals computed only from the policy's own conditional probabilities give a reliable measure of trajectory informativeness and can penalize hallucinated certainty without introducing new biases.
What would settle it
A run on the same benchmarks where the frequency of zero-advantage groups stays the same or rises, or where average on incorrect tokens fails to drop, would show the intrinsic signals do not address the claimed failure modes.
Figures


read the original abstract
Reinforcement learning with verifiable rewards (RLVR) has emerged as a powerful paradigm for eliciting long-chain reasoning in large language models. However, existing methods based on Group Relative Policy Optimization (GRPO) rely on a binary outcome reward, which induces two structural failure modes: Zero-Advantage Collapse, in which all rollouts in a group share the same outcome and the gradient vanishes, and Hallucinated Certainty, in which the model becomes increasingly confident on incorrect rollouts late in training. We address both modes by densifying the reward with intrinsic signals computed entirely from the policy's own conditional probabilities, and propose ISPO (Intrinsic Signal Policy Optimization, which combines a sequence-level signal measuring how informative the thinking trajectory is for the final answer, with a token-level directional reward whose hallucinated-certainty hinge penalizes confidently-wrong predictions at critical decision tokens. Across three base models and five mathematical reasoning benchmarks, ISPO consistently outperforms competitive baselines, with the largest gains on the hardest benchmarks where zero-advantage collapse is most frequent, and training-dynamics diagnostics confirm that both failure modes are decreased.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ISPO (Intrinsic Signal Policy Optimization) to address two failure modes in Group Relative Policy Optimization (GRPO) for RLVR on mathematical reasoning tasks in LLMs: zero-advantage collapse (vanishing gradients when all group rollouts share the same outcome) and hallucinated certainty (increasing confidence on incorrect trajectories). It densifies the binary outcome reward using two intrinsic signals computed solely from the policy's conditional probabilities—a sequence-level informativeness signal for thinking trajectories and a token-level hallucinated-certainty hinge that penalizes confident errors at critical tokens—claiming consistent outperformance over baselines across three base models and five benchmarks (largest gains on hardest tasks), with diagnostics showing reduced incidence of both failure modes.
Significance. If the intrinsic signals prove reliable without external anchors, the approach could stabilize and improve RL-based reasoning elicitation in LLMs by mitigating common collapse issues in sparse-reward settings, offering a parameter-free densification method that scales to harder benchmarks. The emphasis on training-dynamics diagnostics is a positive step toward falsifiable validation of the claimed failure-mode reductions.
major comments (3)
- [Abstract, §3] Abstract and §3 (method): The central claim that the sequence-level informativeness signal and token-level hallucinated-certainty hinge (both derived exclusively from the policy's own conditional probabilities) reliably measure trajectory usefulness and penalize errors is load-bearing, yet the manuscript provides no external verification, ground-truth comparison, or ablation against oracle signals; this leaves open the risk that the signals reinforce existing policy errors when probability mass concentrates on incorrect reasoning paths.
- [§4] §4 (experiments): The reported outperformance and largest gains on hardest benchmarks are presented without error bars, statistical significance tests, or per-benchmark breakdown of zero-advantage frequency before/after ISPO; without these, it is unclear whether the gains are attributable to reduced collapse or to other factors.
- [§5] §5 (diagnostics): The training-dynamics diagnostics confirming decreased zero-advantage collapse and hallucinated certainty rely on the same intrinsic signals whose validity is under question; an independent metric (e.g., external verifier agreement or human judgment of reasoning steps) is needed to establish that the observed reductions are not artifacts of the signal definitions.
minor comments (2)
- [Abstract] The abstract would benefit from a one-sentence definition or equation sketch of the two intrinsic signals to allow readers to assess their non-circularity immediately.
- [§3] Notation for the hinge function and informativeness measure should be introduced with explicit dependence on the policy π_θ to clarify that no external model or reward is involved.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects of validation and statistical rigor. We address each major comment below, proposing revisions where the manuscript can be strengthened without altering its core claims.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (method): The central claim that the sequence-level informativeness signal and token-level hallucinated-certainty hinge (both derived exclusively from the policy's own conditional probabilities) reliably measure trajectory usefulness and penalize errors is load-bearing, yet the manuscript provides no external verification, ground-truth comparison, or ablation against oracle signals; this leaves open the risk that the signals reinforce existing policy errors when probability mass concentrates on incorrect reasoning paths.
Authors: We agree that direct external verification against oracle signals would provide stronger evidence. The design choice for fully intrinsic signals (computed only from policy conditional probabilities) is deliberate to ensure the method remains parameter-free and applicable without external verifiers or ground-truth reasoning annotations, which are often unavailable at scale. The empirical gains on harder benchmarks, where collapse is prevalent, offer indirect support, but we acknowledge the risk of reinforcing errors. In revision, we will add a targeted ablation on a subset of MATH problems with available step-level annotations, comparing intrinsic signals to an oracle informativeness measure, and include a limitations paragraph discussing potential error reinforcement. revision: partial
-
Referee: [§4] §4 (experiments): The reported outperformance and largest gains on hardest benchmarks are presented without error bars, statistical significance tests, or per-benchmark breakdown of zero-advantage frequency before/after ISPO; without these, it is unclear whether the gains are attributable to reduced collapse or to other factors.
Authors: This is a valid point on reporting standards. The current results aggregate across runs without variance measures. In the revised manuscript, we will rerun experiments with at least three random seeds per setting, report mean and standard deviation, apply paired t-tests for significance on key comparisons, and add a table breaking down zero-advantage frequency per benchmark before and after ISPO to directly link gains to collapse reduction. revision: yes
-
Referee: [§5] §5 (diagnostics): The training-dynamics diagnostics confirming decreased zero-advantage collapse and hallucinated certainty rely on the same intrinsic signals whose validity is under question; an independent metric (e.g., external verifier agreement or human judgment of reasoning steps) is needed to establish that the observed reductions are not artifacts of the signal definitions.
Authors: We recognize that the diagnostics are defined using the proposed signals, creating potential circularity. The performance improvements on held-out benchmarks provide an external check that overall reasoning quality improves, but this does not directly validate the per-trajectory signal reductions. In revision, we will expand §5 to explicitly state this limitation, add a qualitative example analysis of trajectories where signals diverge from final outcome, and discuss the value of future human or verifier-based validation while noting that such metrics were outside the scope of the current intrinsic-signal focus. revision: partial
Circularity Check
No circularity: signals defined from policy probabilities in standard RL manner
full rationale
The paper defines sequence-level informativeness and token-level hallucinated-certainty signals directly from the policy's own conditional probabilities to densify the binary outcome reward. This is a self-contained construction within the RL objective and does not reduce any claimed prediction or result to a fitted parameter or prior self-citation by construction. No equations or steps in the abstract or description exhibit self-definitional equivalence, uniqueness imported via self-citation, or renaming of known results. Empirical gains on benchmarks are presented as external validation rather than forced by the input definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
From quantity to quality: Boosting llm performance with self-guided data selection for instruction tuning , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[3]
From Parameters to Data: A Task-Parameter-Guided Fine-Tuning Pipeline for Efficient LLM Alignment
From Parameters to Data: A Task-Parameter-Guided Fine-Tuning Pipeline for Efficient LLM Alignment , author=. arXiv preprint arXiv:2605.21558 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Training-Trajectory-Aware Token Selection
Training-Trajectory-Aware Token Selection , author=. arXiv preprint arXiv:2601.10348 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
arXiv preprint arXiv:2602.05281 , year=
Back to Basics: Revisiting Exploration in Reinforcement Learning for LLM Reasoning via Generative Probabilities , author=. arXiv preprint arXiv:2602.05281 , year=
-
[6]
arXiv preprint arXiv:2510.19807 , year=
Scaf-grpo: Scaffolded group relative policy optimization for enhancing LLM reasoning , author=. arXiv preprint arXiv:2510.19807 , year=
-
[7]
arXiv preprint arXiv:2510.22255 , year=
PACR: Progressively Ascending Confidence Reward for LLM Reasoning , author=. arXiv preprint arXiv:2510.22255 , year=
-
[8]
Advances in Neural Information Processing Systems , volume=
Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
arXiv preprint arXiv:2508.04349 , year=
Gtpo and grpo-s: Token and sequence-level reward shaping with policy entropy , author=. arXiv preprint arXiv:2508.04349 , year=
-
[10]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Advances in Neural Information Processing Systems , volume=
Dapo: An open-source llm reinforcement learning system at scale , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
Understanding R1-Zero-Like Training: A Critical Perspective
Understanding r1-zero-like training: A critical perspective , author=. arXiv preprint arXiv:2503.20783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
InfoDensity: Rewarding Information-Dense Traces for Efficient Reasoning
InfoDensity: Rewarding Information-Dense Traces for Efficient Reasoning , author=. arXiv preprint arXiv:2603.17310 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
ETR: Entropy Trend Reward for Efficient Chain-of-Thought Reasoning
ETR: Entropy Trend Reward for Efficient Chain-of-Thought Reasoning , author=. arXiv preprint arXiv:2604.05355 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
ERPO: Token-Level Entropy-Regulated Policy Optimization for Large Reasoning Models
ERPO: Token-Level Entropy-Regulated Policy Optimization for Large Reasoning Models , author=. arXiv preprint arXiv:2603.28204 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Direct Reasoning Optimization: Constrained RL with Token-Level Dense Reward and Rubric-Gated Constraints for Open-ended Tasks , author=. arXiv preprint arXiv:2506.13351 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Bingo: Boosting efficient reasoning of llms via dynamic and significance-based reinforcement learning , author=. arXiv preprint arXiv:2506.08125 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
arXiv preprint arXiv:2511.00794 , year=
Efficient Reinforcement Learning for Large Language Models with Intrinsic Exploration , author=. arXiv preprint arXiv:2511.00794 , year=
-
[19]
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi k1. 5: Scaling reinforcement learning with llms , author=. arXiv preprint arXiv:2501.12599 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement , author=. arXiv preprint arXiv:2409.12122 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[23]
International Conference on Learning Representations , volume=
Let's verify step by step , author=. International Conference on Learning Representations , volume=
-
[24]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[25]
Advances in neural information processing systems , volume=
Deep reinforcement learning from human preferences , author=. Advances in neural information processing systems , volume=
-
[26]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[27]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[28]
Constitutional AI: Harmlessness from AI Feedback
Constitutional ai: Harmlessness from ai feedback , author=. arXiv preprint arXiv:2212.08073 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Advances in neural information processing systems , volume=
Large language models are zero-shot reasoners , author=. Advances in neural information processing systems , volume=
-
[30]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Scaling llm test-time compute optimally can be more effective than scaling model parameters , author=. arXiv preprint arXiv:2408.03314 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
s1: Simple test-time scaling , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[32]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Large language monkeys: Scaling inference compute with repeated sampling , author=. arXiv preprint arXiv:2407.21787 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
A possibility for implementing curiosity and boredom in model-building neural controllers , author=. Proc. of the international conference on simulation of adaptive behavior: From animals to animats , pages=
-
[34]
Icml , volume=
Policy invariance under reward transformations: Theory and application to reward shaping , author=. Icml , volume=. 1999 , organization=
1999
-
[35]
Advances in neural information processing systems , volume=
Unifying count-based exploration and intrinsic motivation , author=. Advances in neural information processing systems , volume=
-
[36]
International conference on machine learning , pages=
Curiosity-driven exploration by self-supervised prediction , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[37]
Exploration by Random Network Distillation
Exploration by random network distillation , author=. arXiv preprint arXiv:1810.12894 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Ussr computational mathematics and mathematical physics , volume=
Some methods of speeding up the convergence of iteration methods , author=. Ussr computational mathematics and mathematical physics , volume=. 1964 , publisher=
1964
-
[39]
Dokl akad nauk Sssr , volume=
A method for solving the convex programming problem with convergence rate O (1/k2) , author=. Dokl akad nauk Sssr , volume=
-
[40]
International conference on machine learning , pages=
On the importance of initialization and momentum in deep learning , author=. International conference on machine learning , pages=. 2013 , organization=
2013
-
[41]
Adam: A Method for Stochastic Optimization
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
arXiv preprint arXiv:2506.23235 , year=
Generalist reward models: Found inside large language models , author=. arXiv preprint arXiv:2506.23235 , year=
-
[43]
Hugging Face repository , url =
Math-AI , title =. Hugging Face repository , url =. 2024 , publisher =
2024
-
[44]
Hugging Face repository , howpublished =
Math-AI , title =. Hugging Face repository , howpublished =. 2025 , publisher =
2025
-
[45]
Hugging Face repository , howpublished =
Math-AI , title =. Hugging Face repository , howpublished =. 2023 , publisher =
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.