From A to B to A: Palindromic Zero-Shot Voice Conversion with Non-Parallel Data
Pith reviewed 2026-06-30 10:54 UTC · model grok-4.3
The pith
KNN retrieval over WavLM representations aligns non-parallel speech to create synthetic training pairs for zero-shot voice conversion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that KNN retrieval over WavLM representations produces sufficiently accurate alignments between non-parallel source and target segments to serve as synthetic training pairs; a model trained on these pairs plus a speaker-verification loss then performs zero-shot voice conversion that maintains high naturalness and target-speaker similarity across languages even when all training data is English.
What carries the argument
KNN retrieval over WavLM representations to form synthetic-to-real training pairs from non-parallel utterances.
If this is right
- The same English-only model can be applied directly to target speakers in other languages without retraining or parallel data.
- No explicit time-alignment or phonetic transcription is required to build the training set.
- The speaker loss derived from a pretrained verification model is sufficient to enforce target identity on the converted output.
- The synthetic-to-real training paradigm removes the need for any parallel corpus while still supporting supervised learning.
Where Pith is reading between the lines
- If the KNN alignments prove robust, the same retrieval step could be reused to bootstrap training data for other audio-to-audio tasks that currently lack parallel corpora.
- The method implicitly assumes that WavLM space preserves enough phonetic and prosodic detail for segment matching; relaxing this assumption would require testing alternative self-supervised encoders.
- Because the approach separates the alignment stage from the conversion network, either component could be swapped for newer representations or architectures without redesigning the overall pipeline.
Load-bearing premise
KNN retrieval over WavLM representations produces alignments accurate enough to yield useful synthetic training pairs.
What would settle it
A controlled listening test in which the proposed system is compared head-to-head with a parallel-data baseline on the same target speakers and the proposed system scores reliably lower on both naturalness and speaker similarity would falsify the central claim.
Figures

read the original abstract
We present a voice conversion (VC) framework that utilizes K-Nearest Neighbors (KNN) retrieval over WavLM representations to align non-parallel source and target speech, constructing synthetic training pairs for supervised learning. The retrieved segments serve as synthetic inputs, while real target audio provides ground-truth outputs, forming a synthetic-to-real training paradigm that naturally supports multilingual data without requiring parallel corpora or explicit alignment. To ensure consistent target-speaker identity, we incorporate a speaker loss derived from a pretrained speaker verification model. Experiments across multiple languages demonstrate that the proposed approach achieves high naturalness and strong speaker similarity, outperforming competitive VC baselines, despite being trained exclusively on English data. Samples can be accessed at: https://palindromic-vc.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a zero-shot voice conversion framework that employs KNN retrieval over WavLM features to align non-parallel source and target utterances, thereby synthesizing training pairs for a supervised model. Real target audio serves as the ground-truth output while the retrieved segments act as inputs; a speaker-verification loss is added to preserve target identity. The model is trained exclusively on English data yet is reported to generalize to multiple languages, achieving higher naturalness and speaker similarity than competitive baselines.
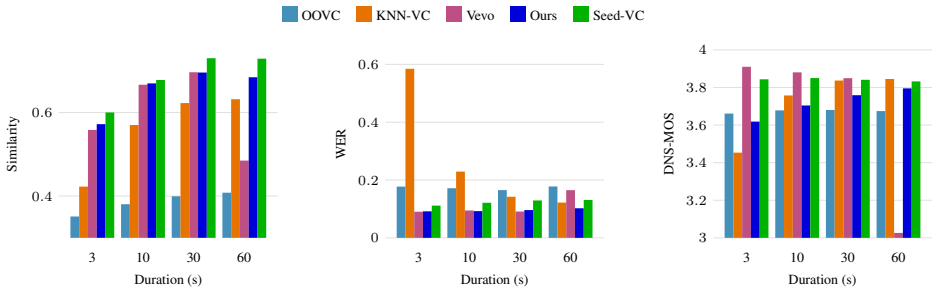
Significance. If the KNN-derived pairs are verifiably content-aligned, the synthetic-to-real paradigm would offer a practical route to non-parallel, cross-lingual VC without language-specific resources or parallel corpora. The explicit use of off-the-shelf pretrained models (WavLM, speaker verifier) and the public release of listening samples constitute reproducible strengths that facilitate external validation.
major comments (2)
- [Method] Method section (KNN retrieval paragraph): no quantitative metric (e.g., forced-alignment phone error rate, cosine similarity of content embeddings, or human content-match rating) is reported for the retrieved segments when source and target languages differ. Because the entire supervised objective rests on these pairs being phonetically matched, absence of such validation directly undermines the cross-lingual generalization claim.
- [Experiments] Experiments section: while the abstract asserts outperformance over baselines, the manuscript provides neither per-language objective scores (e.g., WER, speaker similarity cosine), error bars, nor an ablation that replaces KNN retrieval with random or language-mismatched pairs. Without these controls it is impossible to determine whether performance gains derive from the proposed alignment or from other factors.
minor comments (2)
- [Introduction] The title uses “Palindromic” without an explicit definition or diagram showing the A→B→A cycle; a short clarifying sentence or figure would aid readers.
- [Method] The speaker-loss formulation is described only at a high level; the precise weighting hyper-parameter and its interaction with the reconstruction loss should be stated explicitly.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Method] Method section (KNN retrieval paragraph): no quantitative metric (e.g., forced-alignment phone error rate, cosine similarity of content embeddings, or human content-match rating) is reported for the retrieved segments when source and target languages differ. Because the entire supervised objective rests on these pairs being phonetically matched, absence of such validation directly undermines the cross-lingual generalization claim.
Authors: We agree that the manuscript does not report quantitative metrics validating phonetic alignment of KNN-retrieved segments in cross-lingual cases. While the approach builds on WavLM's established content modeling capabilities, direct evidence would strengthen the claims. In revision we will add cosine similarity between content embeddings of source and retrieved segments, computed separately for intra- and cross-lingual pairs, and include these results in the method section. revision: yes
-
Referee: [Experiments] Experiments section: while the abstract asserts outperformance over baselines, the manuscript provides neither per-language objective scores (e.g., WER, speaker similarity cosine), error bars, nor an ablation that replaces KNN retrieval with random or language-mismatched pairs. Without these controls it is impossible to determine whether performance gains derive from the proposed alignment or from other factors.
Authors: We acknowledge that the current experiments section lacks per-language breakdowns, error bars, and the requested ablation. In the revised manuscript we will report per-language WER and speaker-similarity cosine scores with error bars from repeated runs. We will also add an ablation replacing KNN retrieval with random and language-mismatched pairing to isolate the contribution of the alignment step. revision: yes
Circularity Check
No circularity: method relies on external pretrained models and experimental validation
full rationale
The paper's core pipeline constructs synthetic training pairs via KNN retrieval on WavLM features from non-parallel data, then applies supervised training with an external speaker verification loss; performance claims rest on multilingual experiments rather than any internal derivation, fitted parameter renamed as prediction, or self-citation chain. No self-definitional steps, ansatzes smuggled via prior work, or uniqueness theorems imported from the authors appear in the description. The approach is self-contained against external benchmarks (WavLM, speaker verifier) with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
From A to B to A: Palindromic Zero-Shot Voice Conversion with Non-Parallel Data
Introduction V oice conversion (VC) aims to modify the speech of a source speaker to match the characteristics of a target speaker while preserving the linguistic content. These characteristics may in- clude speaker identity, prosody, or emotional style. In this work, we address zero-shot, any-to-any speaker identity conversion with unseen source and targ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Method An overview of our method is shown in Figure 1. We intro- duce an end-to-end training framework for any-to-any zero-shot voice conversion under a non-parallel data setting. The core motivation of this design is to enable supervised learning of speaker conversion without requiring parallel or aligned speech, by introducing a synthetic intermediate r...
-
[3]
In Stage 2, we train a 77M-parameter six-layer Transformer with 16 attention heads and a hidden di- mension of 1024 for 800K steps using Adam [25] with a learn- ing rate of3×10 −4
Experiments In Stage 1, following KNN-VC [18], we extract features from the 6th layer of WavLM [20] and train a 16M-parameter vocoder for 100K steps. In Stage 2, we train a 77M-parameter six-layer Transformer with 16 attention heads and a hidden di- mension of 1024 for 800K steps using Adam [25] with a learn- ing rate of3×10 −4. In Stage 3, a new instance...
-
[4]
Conclusions & Future Work We present a non-parallel, zero-shot, any-to-any voice con- version framework that enables supervised speaker conversion without aligned speech. By introducing a palindromic training strategy based on controlled KNN-generated synthetic features, our method leverages non-parallel data to learn speaker identity mapping in a scalabl...
-
[5]
It was not used to generate substantial technical content, research ideas, experimental design, or results
Generative AI Use Disclosure A generative AI tool was used to assist with language editing and refinement of specific sections of this manuscript. It was not used to generate substantial technical content, research ideas, experimental design, or results
-
[6]
V oice conver- sion using deep neural networks with layer-wise generative train- ing,
L.-H. Chen, Z.-H. Ling, L.-J. Liu, and L.-R. Dai, “V oice conver- sion using deep neural networks with layer-wise generative train- ing,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 22, no. 12, pp. 1859–1872, 2014
2014
-
[7]
V oice conversion using deep bidirectional long short-term memory based recurrent neural networks,
L. Sun, S. Kang, K. Li, and H. Meng, “V oice conversion using deep bidirectional long short-term memory based recurrent neural networks,” inInternational conference on acoustics, speech and signal processing (ICASSP). IEEE, 2015
2015
-
[8]
Phonetic poste- riorgrams for many-to-one voice conversion without parallel data training,
L. Sun, K. Li, H. Wang, S. Kang, and H. Meng, “Phonetic poste- riorgrams for many-to-one voice conversion without parallel data training,” inInternational Conference on Multimedia and Expo (ICME). IEEE, 2016
2016
-
[9]
Any- to-many voice conversion with location-relative sequence-to- sequence modeling,
S. Liu, Y . Cao, D. Wang, X. Wu, X. Liu, and H. Meng, “Any- to-many voice conversion with location-relative sequence-to- sequence modeling,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 1717–1728, 2021
2021
-
[10]
Transfer learning from speech synthesis to voice conversion with non-parallel training data,
M. Zhang, Y . Zhou, L. Zhao, and H. Li, “Transfer learning from speech synthesis to voice conversion with non-parallel training data,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 1290–1302, 2021
2021
-
[11]
Cotatron: Transcription- guided speech encoder for any-to-many voice conversion without parallel data,
S.-w. Park, D.-y. Kim, and M.-c. Joe, “Cotatron: Transcription- guided speech encoder for any-to-many voice conversion without parallel data,”Proc. Interspeech, 2020
2020
-
[12]
Autovc: Zero-shot voice style transfer with only au- toencoder loss,
K. Qian, Y . Zhang, S. Chang, X. Yang, and M. Hasegawa- Johnson, “Autovc: Zero-shot voice style transfer with only au- toencoder loss,” inInternational Conference on Machine Learn- ing. PMLR, 2019
2019
-
[13]
One-shot voice conversion by separating speaker and content representations with instance normalization,
J.-c. Chou, C.-c. Yeh, and H.-y. Lee, “One-shot voice conversion by separating speaker and content representations with instance normalization,”Proc. Interspeech, 2019
2019
-
[14]
Speech Resynthesis from Discrete Disentangled Self-Supervised Representations,
A. Polyak, Y . Adi, J. Copet, E. Kharitonov, K. Lakhotia, W.-N. Hsu, A. Mohamed, and E. Dupoux, “Speech Resynthesis from Discrete Disentangled Self-Supervised Representations,” inProc. Interspeech, 2021
2021
-
[15]
Frag- mentvc: Any-to-any voice conversion by end-to-end extracting and fusing fine-grained voice fragments with attention,
Y . Y . Lin, C.-M. Chien, J.-H. Lin, H.-y. Lee, and L.-s. Lee, “Frag- mentvc: Any-to-any voice conversion by end-to-end extracting and fusing fine-grained voice fragments with attention,” inInter- national Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021
2021
-
[16]
S3prl-vc: Open-source voice conversion frame- work with self-supervised speech representations,
W.-C. Huang, S.-W. Yang, T. Hayashi, H.-Y . Lee, S. Watanabe, and T. Toda, “S3prl-vc: Open-source voice conversion frame- work with self-supervised speech representations,” inInterna- tional Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022
2022
-
[17]
Freevc: Towards high-quality text- free one-shot voice conversion,
J. Li, W. Tu, and L. Xiao, “Freevc: Towards high-quality text- free one-shot voice conversion,” inInternational Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023
2023
-
[18]
Vqvc+: One-shot voice conversion by vector quantization and u-net architecture,
D.-Y . Wu, Y .-H. Chen, and H.-Y . Lee, “Vqvc+: One-shot voice conversion by vector quantization and u-net architecture,”Proc. Interspeech, 2020
2020
-
[19]
Again-vc: A one-shot voice conversion using activation guidance and adaptive instance normalization,
Y .-H. Chen, D.-Y . Wu, T.-H. Wu, and H.-y. Lee, “Again-vc: A one-shot voice conversion using activation guidance and adaptive instance normalization,” inInternational Conference on Acous- tics, Speech and Signal Processing (ICASSP). IEEE, 2021
2021
-
[20]
O o-vc: Synthetic data-driven one-to-one alignment for any-to- any voice conversion,
H. T. Tu, H. Vu, N. T. Cuong, N. D. Hy, and N. T. T. Trang, “O o-vc: Synthetic data-driven one-to-one alignment for any-to- any voice conversion,” inFindings of the Association for Compu- tational Linguistics: EMNLP 2025, 2025, pp. 16 197–16 208
2025
-
[21]
arXiv preprint arXiv:2411.09943 , year=
S. Liu, “Zero-shot voice conversion with diffusion transformers,” arXiv preprint arXiv:2411.09943, 2024
-
[22]
Synthvc: Leveraging syn- thetic data for end-to-end low latency streaming voice conver- sion,
Z. Guo, Z. Ning, G. Ma, and L. Xie, “Synthvc: Leveraging syn- thetic data for end-to-end low latency streaming voice conver- sion,”arXiv preprint arXiv:2510.09245, 2025
-
[23]
V oice conversion with just nearest neighbors,
M. Baas, B. van Niekerk, and H. Kamper, “V oice conversion with just nearest neighbors,” inProc. Interspeech, 2023
2023
-
[24]
Phoneme hallucina- tor: One-shot voice conversion via set expansion,
S. Shan, Y . Li, A. Banerjee, and J. B. Oliva, “Phoneme hallucina- tor: One-shot voice conversion via set expansion,” inProceedings of the AAAI Conference on Artificial Intelligence, 2024
2024
-
[25]
Wavlm: Large-scale self- supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiaoet al., “Wavlm: Large-scale self- supervised pre-training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[26]
Hifi-gan: Generative adversarial net- works for efficient and high fidelity speech synthesis,
J. Kong, J. Kim, and J. Bae, “Hifi-gan: Generative adversarial net- works for efficient and high fidelity speech synthesis,”Advances in neural information processing systems, vol. 33, pp. 17 022– 17 033, 2020
2020
-
[27]
Ecapa-tdnn: Emphasized channel attention, propagation and aggregation in tdnn based speaker verification,
B. Desplanques, J. Thienpondt, and K. Demuynck, “Ecapa-tdnn: Emphasized channel attention, propagation and aggregation in tdnn based speaker verification,”Proc. Interspeech, 2020
2020
-
[28]
Vevo: Controllable zero-shot voice imitation with self- supervised disentanglement,
X. Zhang, X. Zhang, K. Peng, Z. Tang, V . Manohar, Y . Liu, J. Hwang, D. Li, Y . Wang, J. Chan, Y . Huang, Z. Wu, and M. Ma, “Vevo: Controllable zero-shot voice imitation with self- supervised disentanglement,” inICLR, 2025
2025
-
[29]
Parallel wavegan: A fast waveform generation model based on generative adversarial net- works with multi-resolution spectrogram,
R. Yamamoto, E. Song, and J.-M. Kim, “Parallel wavegan: A fast waveform generation model based on generative adversarial net- works with multi-resolution spectrogram,” inInternational Con- ference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020
2020
-
[30]
Adam: A method for stochastic opti- mization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic opti- mization,” inInternational Conference on Learning Representa- tions (ICLR), 2015
2015
-
[31]
Lib- rispeech: an asr corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Lib- rispeech: an asr corpus based on public domain audio books,” inInternational conference on acoustics, speech and signal pro- cessing (ICASSP). IEEE, 2015
2015
-
[32]
Mls: A large-scale multilingual dataset for speech research,
V . Pratap, Q. Xu, A. Sriram, G. Synnaeve, and R. Collobert, “Mls: A large-scale multilingual dataset for speech research,”Proc. In- terspeech, 2020
2020
-
[33]
Dnsmos p.835: A non- intrusive perceptual objective speech quality metric to evalu- ate noise suppressors,
C. K. Reddy, V . Gopal, and R. Cutler, “Dnsmos p.835: A non- intrusive perceptual objective speech quality metric to evalu- ate noise suppressors,” inInternational conference on acoustics, speech and signal processing (ICASSP). IEEE, 2022
2022
-
[34]
Reshape Dimensions Network for Speaker Recognition,
I. Yakovlev, R. Makarov, A. Balykin, P. Malov, A. Okhotnikov, and N. Torgashov, “Reshape Dimensions Network for Speaker Recognition,” inProc. Interspeech, 2024
2024
-
[35]
Robust Speech Recognition via Large-Scale Weak Supervision
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large- scale weak supervision,” 2022. [Online]. Available: https: //arxiv.org/abs/2212.04356
work page internal anchor Pith review Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.