CARE: A Conformal Safety Layer for Medical Summarization
Pith reviewed 2026-06-27 17:08 UTC · model grok-4.3
The pith
CARE overlays two conformal controllers on any LLM medical summary to bound the chance of an unflagged hallucination or missed important omission.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
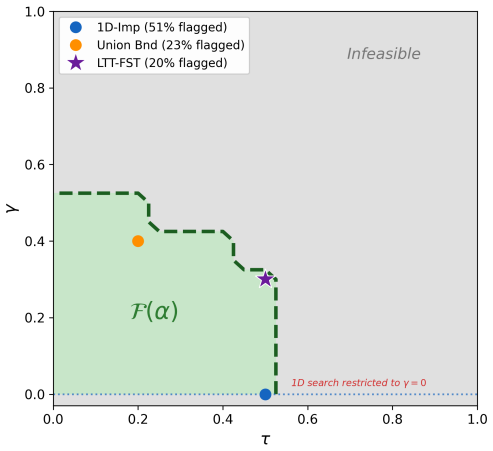
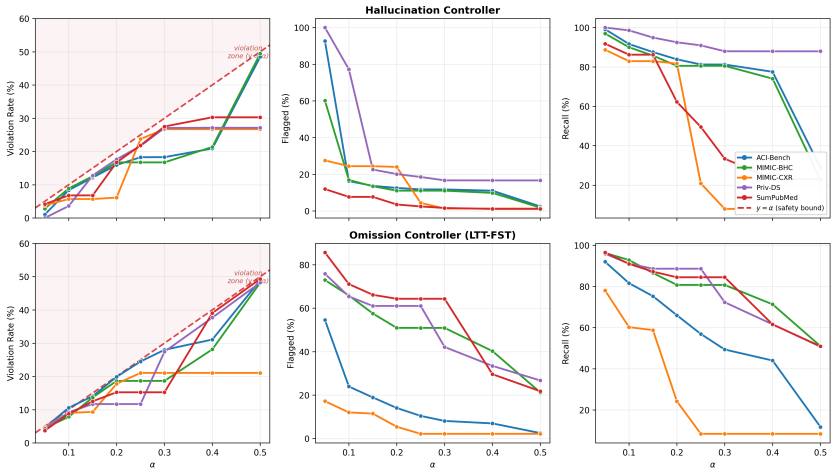
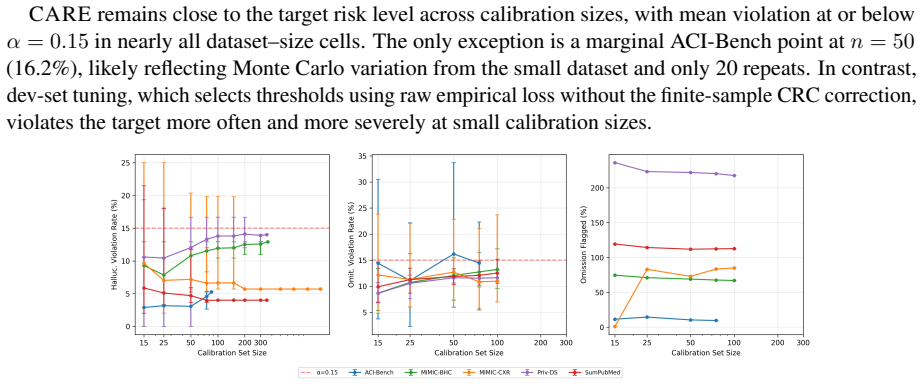
CARE supplies two controllers that together deliver distribution-free finite-sample bounds: the hallucination controller limits the probability that any document contains an unflagged hallucinated sentence, and the omission controller limits the expected fraction of important source sentences left out of the summary. These bounds are achieved by calibrating a pair of thresholds jointly over the full space rather than fixing one dimension first, which preserves validity while reducing the number of surfaced sentences by up to a factor of five compared with alternative calibrated methods. The method requires only exchangeable calibration and test data and operates on any black-box LLM output.
What carries the argument
Joint conformal risk control over the two-dimensional threshold space of hallucination score τ and omission coverage threshold γ, which produces calibrated flags while preserving the finite-sample risk bounds.
If this is right
- Clinicians can select an explicit risk level alpha and receive summaries whose worst-case error rates are provably controlled at that level using only a small calibration set.
- The same calibration data suffices for multiple downstream LLM summarizers without retraining.
- Sentence-level flags can be tuned to trade review effort against residual risk in a principled way.
- The joint calibration step avoids the over-conservatism that arises when hallucination and omission thresholds are set independently.
Where Pith is reading between the lines
- The same two-controller structure could be applied to other high-stakes text generation settings where both fabrication and omission carry clinical cost.
- If exchangeability is only approximate in practice, the observed violation rate on new data would quantify how much the formal bounds degrade.
- Extending the controllers to multi-sentence or paragraph-level units would require re-deriving the joint calibration to maintain the same coverage properties.
Load-bearing premise
Calibration and test data must be exchangeable so that the conformal risk-control procedure yields valid finite-sample coverage.
What would settle it
Collect a fresh exchangeable test set of medical summaries and count the fraction of documents that violate the hallucination bound or exceed the omission bound; if this fraction exceeds the target alpha level across repeated splits, the guarantees do not hold.
Figures


read the original abstract
Large language models (LLMs) are increasingly used for medical summarization, but their outputs can omit medically important information and introduce unsupported claims. Existing error-detection methods produce heuristic or uncalibrated scores, providing no formal control over missed errors and no principled way to trade off safety against clinician review burden. We introduce Conformal Assessment for Risk Evaluation (CARE), a post-hoc, model-agnostic safety layer that uses conformal risk control to overlay calibrated omission and hallucination flags onto summaries from any LLM without retraining. CARE provides finite-sample, distribution-free guarantees through two controllers: a hallucination controller that bounds the probability of a document containing any unflagged hallucinated sentence, and an omission controller that bounds the expected fraction of important omissions not surfaced for review. Unlike hallucination detection, omissions depend jointly on whether a source sentence is important and whether it is covered by the summary. We show that calibrating only one dimension can violate the target risk bound, while marginal decompositions remain valid but overly conservative. By jointly calibrating over the full $(\tau,\gamma)$ threshold space, CARE preserves formal guarantees while surfacing up to 5$\times$ fewer sentences than alternative calibrated baselines. Across five medical summarization tasks, CARE satisfies the target risk bound at $\alpha = 0.15$ with 95% confidence across 100 calibration/test resplits, using only ~100 labeled documents per domain. In a preliminary clinician study (75 document reviews), calibrated flags improved omission detection by 28.6 percentage points on average. These results show that sentence-level safety guarantees are feasible for LLM-assisted medical summarization and offer a tunable mechanism for balancing residual risk and review effort.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CARE, a post-hoc, model-agnostic safety layer for LLM medical summarization that overlays calibrated flags for hallucinations and omissions using conformal risk control. It claims finite-sample, distribution-free guarantees: a hallucination controller bounding the probability of any unflagged hallucinated sentence, and an omission controller bounding the expected fraction of important omissions. Joint calibration over the full (τ,γ) threshold space is used to achieve these bounds while surfacing fewer sentences than baselines; results are shown across five tasks with ~100 labeled documents, satisfying α=0.15 at 95% confidence over 100 resplits, plus a clinician study with 28.6 point improvement.
Significance. If the distribution-free guarantees hold, the work provides a practical mechanism for quantifiable risk control in high-stakes medical LLM use, requiring only small calibration sets and no model retraining. The joint handling of hallucination and omission risks via conformal methods, along with the empirical efficiency gains and clinician validation, strengthens its potential impact for safe deployment.
major comments (1)
- [Abstract and Methods] Abstract and methods description of joint calibration: The central claim that joint calibration over the full (τ,γ) threshold space preserves simultaneous finite-sample bounds for both the hallucination risk (P(any unflagged hallucinated sentence)) and omission risk (E[fraction of important omissions]) requires explicit construction details. The skeptic concern is valid here—the manuscript must specify the exact selection rule (e.g., conformal level-set, grid search with union bound, or other) to confirm it maintains exchangeability-based coverage for the joint event rather than allowing an unconstrained search on the calibration set that could invalidate the nominal α bound for the hallucination controller. This is load-bearing for the distribution-free guarantees.
minor comments (1)
- The abstract states 'up to 5× fewer sentences than alternative calibrated baselines' but does not name the baselines or tasks in the summary paragraph; adding this would improve clarity without altering the claim.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and precise feedback. The concern about the joint calibration procedure is well-taken and central to the validity of our distribution-free claims. We address it directly below and will revise the manuscript to include the requested construction details.
read point-by-point responses
-
Referee: [Abstract and Methods] Abstract and methods description of joint calibration: The central claim that joint calibration over the full (τ,γ) threshold space preserves simultaneous finite-sample bounds for both the hallucination risk (P(any unflagged hallucinated sentence)) and omission risk (E[fraction of important omissions]) requires explicit construction details. The skeptic concern is valid here—the manuscript must specify the exact selection rule (e.g., conformal level-set, grid search with union bound, or other) to confirm it maintains exchangeability-based coverage for the joint event rather than allowing an unconstrained search on the calibration set that could invalidate the nominal α bound for the hallucination controller. This is load-bearing for the distribution-free guarantees.
Authors: We agree that an explicit description of the selection rule is necessary. In the revised manuscript we will state that joint calibration proceeds via a deterministic grid search over a finite discrete set of candidate (τ, γ) pairs. For each pair we evaluate the empirical hallucination and omission risks on the calibration set; we then select the pair that minimizes the expected number of flagged sentences subject to both empirical risks lying below their respective α-adjusted thresholds, where the adjustment uses a union bound to control the probability that either controller fails at level α. Because the selection rule is a fixed function of the calibration data, exchangeability is preserved and the standard conformal risk-control coverage arguments apply simultaneously to the chosen thresholds. We will add pseudocode for the procedure and a short appendix proof sketch confirming joint control of the two risk events. revision: yes
Circularity Check
No significant circularity; relies on external conformal risk control theory
full rationale
The paper applies standard conformal risk control to obtain finite-sample, distribution-free guarantees for the hallucination and omission controllers. Validity is grounded in the external exchangeability assumption and established conformal theory rather than any internal fitting, self-definition, or self-citation chain. The abstract and description present joint calibration over (τ,γ) as preserving (not creating) those external guarantees, with no reduction of reported bounds or predictions to quantities defined by the paper's own fitted parameters. Empirical checks across resplits further confirm the claims rest on independent validation rather than construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Calibration and test data are exchangeable
Forward citations
Cited by 1 Pith paper
-
Deployment-Centered Evaluation: Predicting Query-Level Rejection Risk in a Clinical LLM System
A pre-response classifier predicts user rejection risk for clinical LLM outputs with AUROC 0.719 over 4.5 months of deployment data by incorporating deployment-specific context.
Reference graph
Works this paper leans on
-
[1]
Scope: Selective conformal optimized pairwise llm judging. Preprint, arXiv:2602.13110. Suhana Bedi, Yixing Jiang, Philip Chung, Sanmi Koyejo, and Nigam H. Shah. 2025a. Fidelity of medical reasoning in large language models.JAMA Network Open, 8(8):e2526021. Published online August 8,
-
[2]
QAFactEval: Improved QA-based factual consistency evaluation for summarization. InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2587–2601, Seattle, United States. Association for Computational Linguistics. David Fraile Navarro, Enrico Coiera, Thomas W. ...
2022
-
[3]
Gptscore: Evaluate as you desire.Preprint, arXiv:2302.04166. Zelalem Gero, Chandan Singh, Yiqing Xie, Sheng Zhang, Praveen Subramanian, Paul V ozila, Tristan Naumann, Jianfeng Gao, and Hoifung Poon
-
[4]
Attribute structuring improves llm-based evaluation of clinical text summaries.Preprint, arXiv:2403.01002. Isaac Gibbs, John J. Cherian, and Emmanuel J. Candès
-
[5]
Vivek Gupta, Prerna Bharti, Pegah Nokhiz, and Harish Karnick
Medfacteval and medagentbrief: A framework and workflow for generating and evaluating factual clinical summaries.Preprint, arXiv:2509.05878. Vivek Gupta, Prerna Bharti, Pegah Nokhiz, and Harish Karnick
-
[6]
From rubrics to reliable scores: Evidence-grounded text evaluation with llm judges.Preprint, arXiv:2601.08654. Alistair E. W. Johnson, Lucas Bulgarelli, Lu Shen, Alvin Gayles, Ayad Shammout, Steven Horng, Tom J. Pollard, Sicheng Hao, Benjamin Moody, Brian Gow, Li-wei H. Lehman, Leo A. Celi, and Roger G. Mark
-
[7]
Philippe Laban, Tobias Schnabel, Paul N
Document summarization with conformal importance guarantees.Preprint, arXiv:2509.20461. Philippe Laban, Tobias Schnabel, Paul N. Bennett, and Marti A. Hearst
-
[8]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu
SummaC: Re-visiting NLI-based models for inconsistency detection in summarization.Transactions of the Association for Computational Linguistics (TACL). Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023a. G-eval: NLG evaluation using gpt-4 with better human alignment. InProceedings of the 2023 Conference on Empirical Method...
2023
-
[9]
Victor Quach, Adam Fisch, Tal Schuster, Adam Yala, Jae Ho Sohn, Tommi Jaakkola, and Regina Barzilay
Unsupervised conformal inference: Bootstrapping and alignment to control llm uncertainty.Preprint, arXiv:2509.23002. Victor Quach, Adam Fisch, Tal Schuster, Adam Yala, Jae Ho Sohn, Tommi Jaakkola, and Regina Barzilay
-
[10]
A tutorial on conformal prediction.Preprint, arXiv:0706.3188. Nigam H. Shah, Nerissa Ambers, Abby Pandya, Timothy Keyes, Juan M. Banda, Srikar Nallan, Carlene Lugtu, Artem A. Trotsyuk, Suhana Bedi, Alyssa Unell, Miguel Fuentes, Francois Grolleau, Sneha S. Jain, Jonathan Chen, Devdutta Dash, Danton Char, Aditya Sharma, Duncan McElfresh, Patrick Scully, and...
-
[11]
Adoption and use of llms at an academic medical center.Preprint, arXiv:2602.00074. Manil Shrestha and Edward Kim
-
[12]
Conformal prediction for risk-controlled medical entity extraction across clinical domains.Preprint, arXiv:2603.00924. Dave Van Veen, Cara Van Uden, Maayane Attias, Anuj Pareek, Christian Bluethgen, Malgorzata Polacin, Wah Chiu, Jean-Benoit Delbrouck, Juan Manuel Zambrano Chaves, Curtis P. Langlotz, and Akshay S. Chaudhari
-
[13]
InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 6886–6898, Miami, Florida, USA
ConU: Conformal uncertainty in large language models with correctness coverage guarantees. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 6886–6898, Miami, Florida, USA. Association for Computational Linguistics. Christopher Y . K. Williams, Jaskaran Bains, Tianyu Tang, Kishan Patel, Alexa N. Lucas, Fiona Chen, Brenda Y . M...
2024
-
[14]
InFindings of the Association for Computational Linguistics: NAACL 2022, pages 528–535, Seattle, United States
Improving the faithfulness of abstractive summarization via entity coverage control. InFindings of the Association for Computational Linguistics: NAACL 2022, pages 528–535, Seattle, United States. Association for Computational Linguistics. Appendix A Oracle Label Validation CARE uses LLM-generated oracle labels from Phase 1 as reference labels for conform...
2022
-
[15]
B.1 Validity of the 2D Omission Calibration Standard CRC is stated for a scalar, totally ordered threshold
Because (τ, γ) has only a partial order, we use the Learn-Then-Test fixed-sequence procedure described below rather than applying the scalar infimum rule directly. B.1 Validity of the 2D Omission Calibration Standard CRC is stated for a scalar, totally ordered threshold. The omission controller instead depends on two thresholds, (τ, γ), for importance and...
2025
-
[16]
They motivate future work on conditional conformal methods that stratify risk by document type, clinical domain, or document complexity (Gibbs et al., 2025; Campos et al., 2024)
These results illustrate the gap between marginal risk control and per-document guarantees. They motivate future work on conditional conformal methods that stratify risk by document type, clinical domain, or document complexity (Gibbs et al., 2025; Campos et al., 2024). Table 7: Fractional vs. binary omission loss at α= 0.15 , averaged over 100 random cal...
2025
-
[17]
clinician
Biomedical research articles summa- rized into structured abstracts. This dataset tests CARE outside clinical notes in an extreme compression set- ting (12.9×). Appendix E Detailed Results Calibrated thresholds.Table 10 reports the calibrated thresholds selected at α= 0.15 for each dataset. The hallucination threshold λ∗ is applied to the support score, w...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.