Beyond Averages: Evaluating LLMs on Human Survey Replication at the Distributional Level
Pith reviewed 2026-06-27 17:02 UTC · model grok-4.3
The pith
LLMs that match human survey means can still produce distributions farther from humans than a simple pooled baseline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
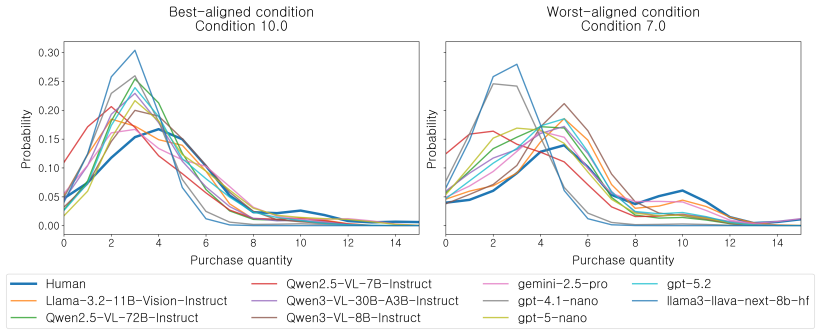
LLMs reproduce condition-level patterns reasonably well but fail to capture distributional structure: for purchase quantity, no model beats a condition-insensitive baseline that simply matches the pooled human distribution. Because models that match human means well can still produce distributions further from humans than this baseline, mean-based evaluation alone can be actively misleading. Replication also varies with input configuration, with structured personas and multimodal inputs improving alignment while explicit reasoning prompting degrades it monotonically.
What carries the argument
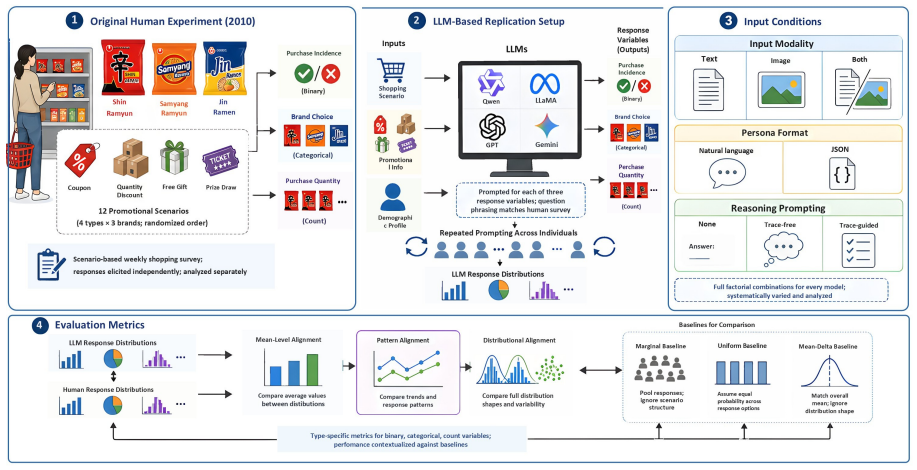
Comparison of mean-level, pattern, and distributional alignment metrics against human-data baselines, applied to binary purchase incidence, categorical brand choice, and count purchase quantity from the noodle experiment.
If this is right
- Mean-level agreement is insufficient and can be actively misleading for judging LLM survey replication quality.
- No tested model matches the full human distribution for purchase quantity counts better than the pooled baseline.
- Structured personas and multimodal inputs raise distributional alignment; explicit reasoning steps lower it monotonically.
- Alignment quality differs by response type: binary and categorical variables show better pattern capture than counts.
- Input format choices directly affect how closely LLM outputs track human response variability.
Where Pith is reading between the lines
- Evaluations of LLM human simulation should shift primary focus from means to full distributional metrics.
- Repeating the test on other non-public choice datasets would show whether the distribution gap is domain-specific.
- Different choices of pooled baseline could alter which models rank highest on distributional fidelity.
- Prompt configurations could be optimized specifically to increase output variance rather than reduce it.
Load-bearing premise
The 2010 non-public Korean noodle dataset is treated as a clean, representative test of general LLM capabilities with no training-data overlap and that the chosen condition-insensitive pooled baseline is the right reference for measuring true distributional replication.
What would settle it
An LLM run on the same noodle dataset that produces purchase-quantity distributions closer to the human data than the pooled baseline, while still matching means, would undermine the claim that mean matching is actively misleading.
Figures

read the original abstract
LLMs are increasingly used to simulate human survey responses, but prior work has mainly evaluated replication using mean-level or aggregate agreement, offering limited insight into whether LLMs reproduce the variability of human behavior. We evaluate LLM-based survey replication at the distributional level using a non-public 2010 consumer choice experiment on Korean instant noodle purchases, a setting unlikely to overlap with model training data. We evaluate three response variables of differing statistical type: binary purchase incidence, categorical brand choice, and count purchase quantity. For each, we compare human and LLM responses at mean-level, pattern, and distributional alignment, and against reference baselines from the human data alone. LLMs reproduce condition-level patterns reasonably well but fail to capture distributional structure: for purchase quantity, no model beats a condition-insensitive baseline that simply matches the pooled human distribution. Because models that match human means well can still produce distributions further from humans than this baseline, mean-based evaluation alone can be actively misleading. Replication also varies with input configuration, with structured personas and multimodal inputs improving alignment while explicit reasoning prompting degrades it monotonically.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates LLMs' ability to replicate human survey responses at the distributional level using a non-public 2010 Korean instant noodle purchase dataset. It compares LLM outputs to human data on three variables (binary purchase incidence, categorical brand choice, count purchase quantity) across mean-level, pattern, and distributional alignment, using explicit baselines derived from the human data. The central claim is that LLMs capture condition-level patterns reasonably well but fail to reproduce distributional structure—for purchase quantity, no model outperforms a condition-insensitive pooled baseline—implying that mean-based evaluation alone can be actively misleading. The work also reports that structured personas and multimodal inputs improve alignment while explicit reasoning prompting degrades it.
Significance. If the results hold, the paper makes a useful contribution by demonstrating that mean-matching does not guarantee distributional fidelity in LLM-based human simulation, with the pooled baseline providing a clear reference point that exposes this gap. The choice of a pre-2010 non-public dataset reduces contamination concerns and strengthens the empirical case. Explicit inclusion of human-derived baselines and multi-level comparisons (mean/pattern/distribution) is a strength, as is the examination of input configuration effects. This could encourage more rigorous distributional metrics in the field.
major comments (1)
- [Results (purchase quantity)] Results section on purchase quantity: the claim that 'no model beats' the condition-insensitive pooled baseline is load-bearing for the 'actively misleading' conclusion, but the manuscript does not specify the exact divergence metric, how 'beats' is operationalized (e.g., statistical significance threshold), or the sample sizes used for the comparison. This detail is needed to assess whether the result reflects true failure to exploit condition information or a property of the chosen metric.
minor comments (2)
- [Methods] Clarify in the methods how the three response variables were encoded for LLM prompting and how condition information was provided across the different input configurations.
- [Abstract and Results] The abstract states that replication 'varies with input configuration' but does not quantify the effect sizes or provide a table summarizing the configuration results; adding this would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation of minor revision. The single major comment requests clarification on the purchase-quantity results; we address it directly below and will incorporate the requested details.
read point-by-point responses
-
Referee: [Results (purchase quantity)] Results section on purchase quantity: the claim that 'no model beats' the condition-insensitive pooled baseline is load-bearing for the 'actively misleading' conclusion, but the manuscript does not specify the exact divergence metric, how 'beats' is operationalized (e.g., statistical significance threshold), or the sample sizes used for the comparison. This detail is needed to assess whether the result reflects true failure to exploit condition information or a property of the chosen metric.
Authors: We agree that the manuscript should make these operational details explicit. The divergence metric is the Wasserstein-1 distance between the empirical distributions of purchase quantities; 'beats' is defined as a strictly lower Wasserstein distance relative to the pooled human baseline (no significance threshold is applied because the comparison is deterministic given the fixed human data and the finite LLM samples). Human sample sizes are the full 2010 survey (N=2,847 respondents); LLM sample sizes are 500 independent generations per condition. In the revision we will add a dedicated paragraph in the Results section (and a corresponding methods subsection) stating the metric, the exact definition of 'beats,' the sample sizes, and the rationale for not using a statistical test on the divergence values themselves. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical evaluation comparing LLM outputs to human survey data on three response variables, using mean-level, pattern, and distributional metrics plus simple baselines (e.g., condition-insensitive pooled human distribution) computed directly from the same human data. No equations, derivations, or first-principles claims appear; the central finding that mean-matching models can underperform a pooled baseline is a direct empirical observation, not a reduction to a fitted parameter or self-citation. The 2010 dataset choice and baseline construction are transparent and do not presuppose the target result. This is a standard self-contained empirical study with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard statistical comparisons of means, patterns, and distributions are appropriate and sufficient to assess replication quality.
Reference graph
Works this paper leans on
-
[1]
Using Large Language Models to Simulate Multiple Humans and Replicate Human Subject Studies , booktitle =
Aher, Gati V and Arriaga, Rosa I and Kalai, Adam Tauman , year = 2023, pages =. Using Large Language Models to Simulate Multiple Humans and Replicate Human Subject Studies , booktitle =
2023
-
[2]
American Economic Review , volume =
What Can We Learn from Experiments?. American Economic Review , volume =
-
[3]
Journal of econometrics , volume =
Marketing Models of Consumer Heterogeneity , author =. Journal of econometrics , volume =
-
[4]
Out of One, Many:
Argyle, Lisa P and Busby, Ethan C and Fulda, Nancy and Gubler, Joshua R and Rytting, Christopher and Wingate, David , year = 2023, journal =. Out of One, Many:
2023
-
[5]
Synthetic Replacements for Human Survey Data?
Bisbee, James and Clinton, Joshua D and Dorff, Cassy and Kenkel, Brenton and Larson, Jennifer M , year = 2024, journal =. Synthetic Replacements for Human Survey Data?
2024
-
[6]
Survey Research:
Coughlan, Michael and Cronin, Patricia and Ryan, Frances , year = 2009, journal =. Survey Research:
2009
-
[7]
Journal of medical Internet research , volume =
Or Web-Based Questionnaire Invitations as a Method for Data Collection: Cross-Sectional Comparative Study of Differences in Response Rate, Completeness of Data, and Financial Cost , author =. Journal of medical Internet research , volume =
-
[8]
Elangovan, Aparna and Xu, Lei and Ko, Jongwoo and Elyasi, Mahsa and Liu, Ling and Bodapati, Sravan and Roth, Dan , year = 2024, journal =. Beyond Correlation:. 2410.03775 , archiveprefix =
arXiv 2024
-
[9]
Surveys on Surveys:
Goyder, John , year = 1986, journal =. Surveys on Surveys:
1986
-
[10]
Predicting Results of Social Science Experiments Using Large Language Models , author =
-
[11]
Large Language Models as Simulated Economic Agents:
Horton, John J , year = 2023, institution =. Large Language Models as Simulated Economic Agents:
2023
-
[12]
Aligning Language Models to User Opinions , booktitle =
Hwang, EunJeong and Majumder, Bodhisattwa and Tandon, Niket , year = 2023, pages =. Aligning Language Models to User Opinions , booktitle =
2023
-
[13]
Annual review of psychology , volume =
Survey Research , author =. Annual review of psychology , volume =
-
[14]
arXiv preprint arXiv:2408.06929 , eprint =
Evaluating Cultural Adaptability of a Large Language Model via Simulation of Synthetic Personas , author =. arXiv preprint arXiv:2408.06929 , eprint =
-
[15]
Proceedings of the 18th
Liusie, Adian and Manakul, Potsawee and Gales, Mark , year = 2024, pages =. Proceedings of the 18th
2024
-
[16]
What If Consumer Experiments Impact Variances as Well as Means?
Louviere, Jordan J , year = 2001, journal =. What If Consumer Experiments Impact Variances as Well as Means?
2001
-
[17]
Lu, Yuxuan and Huang, Jing and Han, Yan and Bei, Bennet and Xie, Yaochen and Wang, Dakuo and Wang, Jessie and He, Qi , year = 2025, journal =. Beyond Believability:. 2503.20749 , archiveprefix =
Pith/arXiv arXiv 2025
-
[18]
Factual Consistency Evaluation of Summarization in the
Luo, Zheheng and Xie, Qianqian and Ananiadou, Sophia , year = 2024, journal =. Factual Consistency Evaluation of Summarization in the
2024
-
[19]
Qin, Xiaoyou and Li, Zhihong and Cheng, Xiaoxiao , year = 2026, journal =. Restoring. 2604.06663 , archiveprefix =
Pith/arXiv arXiv 2026
-
[20]
Humanities and Social Sciences Communications , volume =
Performance and Biases of Large Language Models in Public Opinion Simulation , author =. Humanities and Social Sciences Communications , volume =
-
[21]
Do Large Language Models Show Decision Heuristics Similar to Humans?
Suri, Gaurav and Slater, Lily R and Ziaee, Ali and Nguyen, Morgan , year = 2024, journal =. Do Large Language Models Show Decision Heuristics Similar to Humans?
2024
-
[22]
Transactions of the Association for Computational Linguistics , volume =
Do Llms Exhibit Human-like Response Biases? A Case Study in Survey Design , author =. Transactions of the Association for Computational Linguistics , volume =
-
[23]
Aligning Large Language Models with Human:
Wang, Yufei and Zhong, Wanjun and Li, Liangyou and Mi, Fei and Zeng, Xingshan and Huang, Wenyong and Shang, Lifeng and Jiang, Xin and Liu, Qun , year = 2023, journal =. Aligning Large Language Models with Human:. 2307.12966 , archiveprefix =
arXiv 2023
-
[24]
Wang, Qian and Wu, Jiaying and Jiang, Zichen and Tang, Zhenheng and Luo, Bingqiao and Chen, Nuo and Chen, Wei and He, Bingsheng , year = 2025, journal =. 2501.08579 , archiveprefix =
arXiv 2025
-
[25]
Worldvaluesbench:
Zhao, Wenlong and Mondal, Debanjan and Tandon, Niket and Dillion, Danica and Gray, Kurt and Gu, Yuling , year = 2024, pages =. Worldvaluesbench:. Proceedings of the 2024
2024
-
[26]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[27]
Publications Manual , year = "1983", publisher =
1983
-
[28]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[29]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[30]
Dan Gusfield , title =. 1997
1997
-
[31]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[32]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.