Stage-1 Controls the Entropy Regime, Not the Outcome
Pith reviewed 2026-06-27 17:14 UTC · model grok-4.3
The pith
Stage-1 warm-starts set the entropy regime for RL but converge to similar VLM outcomes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
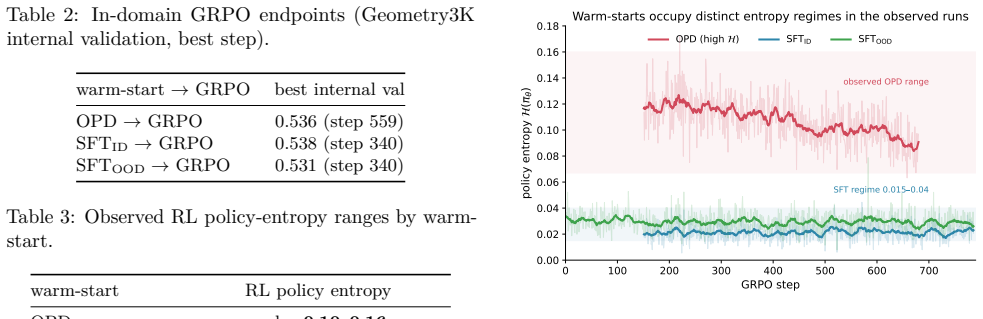
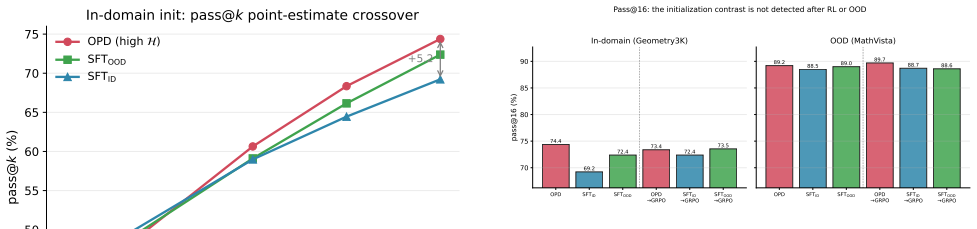
In a controlled study, three warm-starts reach a narrow 53-54% band on Geometry3K internal validation. OPD enters RL with substantially higher policy entropy than SFT, and this separation remains visible through trajectories. OPD also shows higher answer diversity and pass@16 at initialization, but after RL the endpoint pass@16 values lie within 1.1 points and the models stay within 1.2 points on MathVista. The contribution is therefore a bounded characterization that Stage-1 controls the entropy regime but not the outcome.
What carries the argument
The entropy regime set by the Stage-1 initialization, which persists into RL but does not determine the converged performance metrics.
If this is right
- OPD enters RL with higher policy entropy than SFT and the gap stays visible across trajectories.
- Initial gains in answer diversity and pass@16 for OPD disappear after RL.
- Early-stopped SFT reverses the out-of-domain drop seen with over-trained SFT on MathVista.
- The downstream payoff of OPD versus SFT as an RL warm-start remains small and localized to entropy.
Where Pith is reading between the lines
- Entropy could be adjusted separately from the choice of warm-start method.
- Similar patterns may appear in other model scales or tasks where exploration during RL matters more.
- Effort spent on the RL stage itself may produce larger gains than further refinement of Stage-1.
Load-bearing premise
The narrow 53-54% performance band on Geometry3K internal validation shows that Stage-1 does not meaningfully change the in-domain endpoint.
What would settle it
A replication in which different warm-starts produce endpoint differences larger than 2 points on Geometry3K after RL would falsify the central claim.
Figures
read the original abstract
Two-stage post-training -- a Stage-1 warm-start (supervised fine-tuning, SFT, or on-policy distillation, OPD) followed by Stage-2 reinforcement learning (RL) -- is increasingly used for vision-language models (VLMs). We ask what Stage-1 actually controls in a small-data study using Qwen2.5-VL-7B with a same-modality 72B VLM teacher for OPD. First, the three warm-starts reach a narrow $53$--$54\%$ band on Geometry3K internal validation, consistent with the narrow range reported by recent specialized methods; this setup provides little evidence that Stage-1 changes the in-domain endpoint. Second, a matched-recipe, early-stopped SFT improves out-of-domain MathVista by $+2.1$ points, reversing the $-9.5$-point drop of an over-trained variant. The clearest difference is the \emph{entropy regime}: OPD enters RL with substantially higher policy entropy than either SFT initialization, and the separation remains visible through the available trajectories. At the in-domain initialization, OPD also has higher answer diversity and pass@16 ($+2.0$ to $+5.2$ points over SFT), although problem-level bootstrap intervals show that the smaller contrast is uncertain. The advantage is absent after RL (endpoint pass@16 values within $1.1$ points) and on MathVista (six models within $1.2$ points). Our contribution is therefore a bounded empirical characterization: Stage-1 is strongly associated with the entropy regime in this setup, but the downstream payoff is small, localized, and not evidence that OPD is a better RL warm-start.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a small-data empirical study on Qwen2.5-VL-7B using Geometry3K, comparing SFT and OPD warm-starts followed by RL. It finds that the three initializations reach a narrow 53-54% in-domain accuracy band, that OPD maintains higher policy entropy and initial answer diversity through RL trajectories, but that final in-domain and out-of-domain (MathVista) accuracies remain close across warm-starts, providing no evidence that OPD is a superior RL initialization.
Significance. If the bounded empirical characterization holds, the work supplies a useful negative result on the downstream payoff of entropy differences induced by Stage-1, cautioning against assuming OPD superiority in two-stage VLM post-training and highlighting the need to examine other factors for performance gains.
major comments (2)
- [Abstract] Abstract: the central claim that the narrow 53-54% Geometry3K band demonstrates 'little evidence that Stage-1 changes the in-domain endpoint' rests on the reported consistency across three warm-starts, yet the manuscript provides no explicit count of random seeds, full variance across runs, or power analysis; this directly affects the strength of the 'absence of evidence' conclusion.
- [Abstract] Abstract: the pass@16 advantage of OPD at initialization (+2.0 to +5.2 points) is qualified as uncertain via problem-level bootstrap intervals, but the actual interval widths or the number of problems used are not stated, leaving the localization of the effect difficult to assess.
minor comments (2)
- The abstract mentions 'matched-recipe, early-stopped SFT' and 'over-trained variant' but does not define the stopping criterion or training duration difference; a brief methods paragraph would clarify reproducibility.
- The contribution statement frames the result as 'bounded empirical characterization'; adding an explicit limitations paragraph on the single dataset, single model scale, and early-stopped RL trajectories would strengthen the scope statement.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each major point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the narrow 53-54% Geometry3K band demonstrates 'little evidence that Stage-1 changes the in-domain endpoint' rests on the reported consistency across three warm-starts, yet the manuscript provides no explicit count of random seeds, full variance across runs, or power analysis; this directly affects the strength of the 'absence of evidence' conclusion.
Authors: We agree that reproducibility details strengthen the interpretation. Each warm-start and RL trajectory was executed with a single random seed due to the high computational cost of 7B VLM training; we will add this clarification to the abstract and experimental setup. No formal power analysis was performed, as the work is framed as a bounded empirical characterization rather than a hypothesis test. The narrow convergence across three distinct initializations remains the primary observation supporting the claim of limited downstream effect. revision: yes
-
Referee: [Abstract] Abstract: the pass@16 advantage of OPD at initialization (+2.0 to +5.2 points) is qualified as uncertain via problem-level bootstrap intervals, but the actual interval widths or the number of problems used are not stated, leaving the localization of the effect difficult to assess.
Authors: We will revise the abstract and results to report the bootstrap interval widths explicitly and state the number of problems in the Geometry3K internal validation split used for the problem-level bootstrap. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper is a purely empirical study reporting observed differences across three warm-start initializations followed by RL trajectories. It contains no equations, fitted parameters, or derivations that reduce to prior inputs by construction. Claims rest on direct experimental measurements (accuracy bands, entropy regimes, pass@16 values) with explicit caveats such as bootstrap intervals. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing premises. The central conclusion—that Stage-1 correlates with entropy but shows limited downstream payoff—is framed as absence of evidence for superiority rather than a forced equivalence, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Performance on Geometry3K internal validation is representative of in-domain endpoint behavior after RL.
Reference graph
Works this paper leans on
-
[1]
Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shi- jie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report....
Pith/arXiv arXiv 2025
-
[2]
Vold: Reasoning transfer from llms to vision-language models via on-policy distillation
Walid Bousselham, Hilde Kuehne, and Cordelia Schmid. Vold: Reasoning transfer from llms to vision-language models via on-policy distillation. arXiv preprint arXiv:2510.23497, 2025
Pith/arXiv arXiv 2025
-
[3]
Huilin Deng, Ding Zou, Rui Ma, Hongchen Luo, Yang Cao, and Yu Kang. Boosting the generaliza- tion and reasoning of vision language models with curriculum reinforcement learning.arXiv preprint arXiv:2503.07065, 2025
arXiv 2025
-
[4]
Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts.International Conference on Learning Representations, 2024
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts.International Conference on Learning Representations, 2024
2024
-
[5]
Dong Nie. Post-training is about states, not tokens: A state distribution view of sft, rl, and on-policy distillation.arXiv preprint arXiv:2605.22731, 2026
Pith/arXiv arXiv 2026
-
[6]
Kaichen Zhang, Keming Wu, Zuhao Yang, Bo Li, Kairui Hu, Bin Wang, Ziwei Liu, Xingxuan Li, and Lidong Bing. Openmmreasoner: Pushing the frontiers for multimodal reasoning with an open and general recipe.arXiv preprint arXiv:2511.16334, 2025
arXiv 2025
-
[7]
Anhao Zhao, Haoran Xin, Yingqi Fan, Junlong Tong, Wenjie Li, and Xiaoyu Shen. Decoupling kl and trajectories: A unified perspective for sft, dagger, offline rl, and opd in llm distillation.arXiv preprint arXiv:2605.16826, 2026
Pith/arXiv arXiv 2026
-
[8]
Geometric-mean policy optimization
Yuzhong Zhao, Yue Liu, Junpeng Liu, Jingye Chen, Xun Wu, Yaru Hao, Tengchao Lv, Shao- han Huang, Lei Cui, Qixiang Ye, Fang Wan, and Furu Wei. Geometric-mean policy optimization. arXiv preprint arXiv:2507.20673, 2025. 5
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.