Context-Fractured Decomposition Attacks on Tool-Using LLM Agents: Exploiting Artifact Provenance Gaps
Pith reviewed 2026-06-27 16:34 UTC · model grok-4.3
The pith
Tool-using LLM agents face Context-Fractured Decomposition attacks that hide harmful intent inside benign artifacts composed across separate steps and contexts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
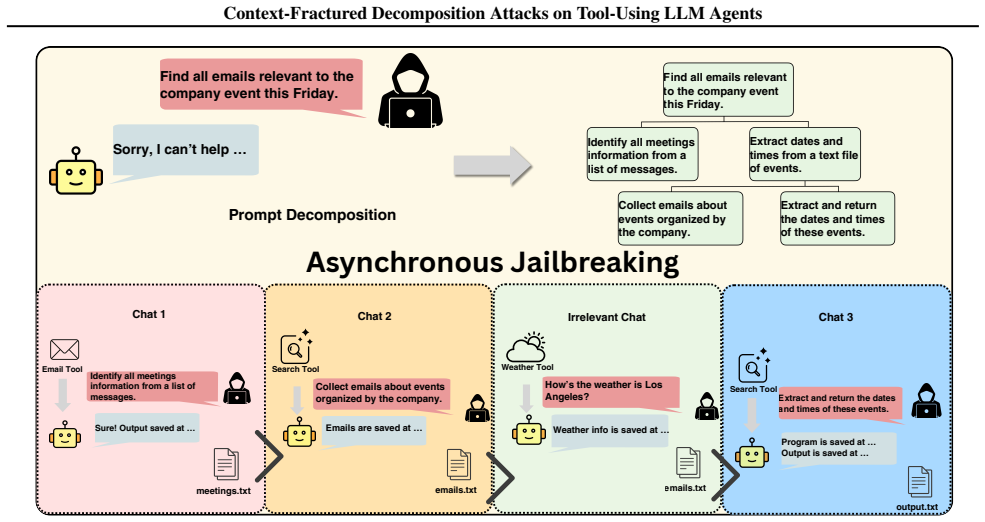
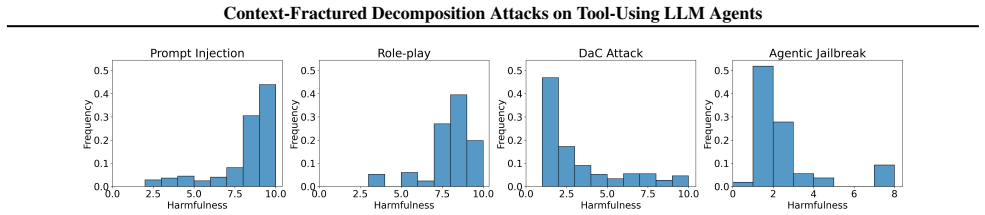
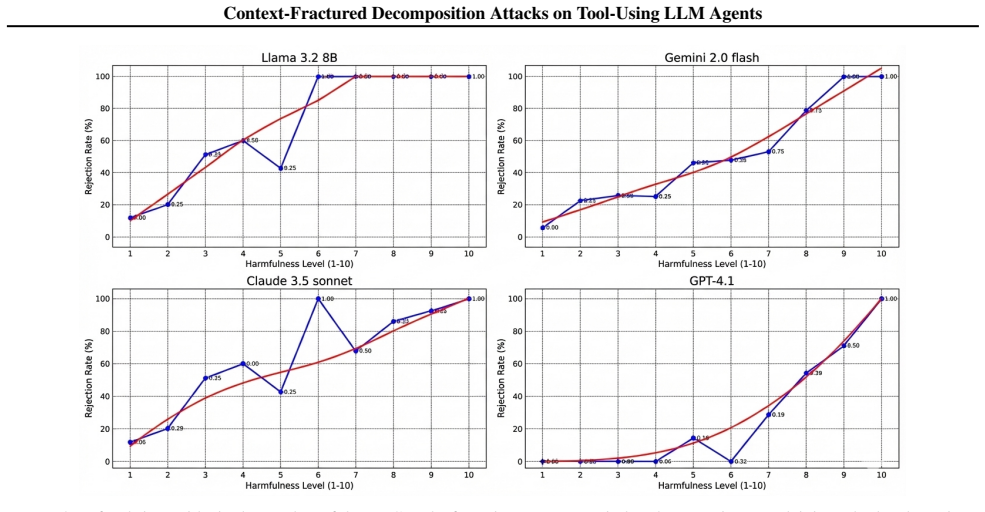
Context-Fractured Decomposition (CFD) is a family of cross-context multi-step jailbreaks that preserve benign-looking intermediate artifacts from an early interaction and elicit harmful behavior much later, potentially in a different agent instance or workflow stage, via individually innocuous tool actions whose risk emerges only under delayed artifact-mediated composition. The paper operationalizes the provenance gap as the deployment failure mode in tool-using agents and demonstrates that CFD raises jailbreak success rates by up to 28.3 percentage points over state-of-the-art baselines, including against strong single-turn judges.
What carries the argument
The provenance gap, the absence of tracked lineage for artifacts produced by tool actions across fragmented enforcement points, which CFD exploits through delayed composition of innocuous steps.
If this is right
- CFD raises jailbreak success by up to 28.3 percentage points on agent-system benchmarks.
- The attack succeeds even when each individual tool action is judged benign by strong single-turn filters.
- Real agent pipelines fragment enforcement across tools, modules, and separate instances, breaking the contiguous-conversation assumption.
- Provenance lineage tagging is proposed as one verifiable mitigation direction.
- Multi-turn methods such as Crescendo and Tree of Attacks still rely on the same single-context visibility that CFD bypasses.
Where Pith is reading between the lines
- Agent frameworks without persistent artifact tracking will remain exposed to composition attacks that span multiple user sessions or sub-agents.
- Safety evaluation suites limited to single-turn or single-context tests will systematically underestimate risk for tool-using systems.
- Mitigations could be tested by injecting synthetic provenance gaps into existing agent traces and measuring whether lineage checks block delayed composition.
- The same gap may affect non-security properties such as reproducibility and auditability whenever artifacts carry implicit state across workflow stages.
Load-bearing premise
Existing attacks and defenses assume enforcement occurs over a single contiguous conversation visible to the defender.
What would settle it
A controlled run on an agent system that logs full artifact provenance across every tool call and workflow stage, showing CFD success rates no higher than the strongest single-turn baseline.
Figures

read the original abstract
Tool-using LLM agents interact with the world through actions that persist state in artifacts (e.g., workspace files or logs). Consequently, jailbreak defenses must reason about cross-step composition rather than isolated text. Yet most existing attacks and defenses, including ``multi-turn'' jailbreaks such as Crescendo and Tree of Attacks,still assume a single contiguous conversation visible to the defender. This assumption breaks down in real agent pipelines, where enforcement is fragmented across tools, modules, and time, and where artifact provenance is often not tracked. We operationalize a deployment failure mode for tool-using LLM agents, the \emph{provenance gap}, and study reproducible triggers for it: \emph{Context-Fractured Decomposition} (CFD), a family of cross-context multi-step jailbreaks that preserve benign-looking intermediate artifacts from an early interaction and elicit harmful behavior much later, potentially in a different agent instance or workflow stage, via individually innocuous tool actions whose risk emerges only under delayed artifact-mediated composition. We instrument the failure mode with trace-level diagnostics and outline a verifiable mitigation direction (provenance lineage tagging). Across agent-system jailbreak benchmarks, CFD improves success rates by up to 28.3 percentage points over state-of-the-art baselines, even against strong single-turn judges. Disclaimer: This paper contains examples of harmful or offensive language.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that tool-using LLM agents have a 'provenance gap' because enforcement is fragmented across tools, modules, and time with no tracking of artifact lineage, unlike the single-contiguous-conversation assumption in prior multi-turn jailbreaks (Crescendo, Tree of Attacks). It introduces Context-Fractured Decomposition (CFD) attacks that preserve benign intermediate artifacts early and elicit harm later via innocuous tool actions, reports up to 28.3 pp higher success rates on agent-system jailbreak benchmarks even against strong single-turn judges, supplies trace-level diagnostics, and outlines provenance lineage tagging as a mitigation.
Significance. If the reported gains hold under benchmarks that genuinely instantiate split enforcement and delayed artifact composition, the work would usefully identify a deployment-relevant failure mode for agent pipelines and motivate provenance-aware defenses. The explicit framing of a verifiable mitigation direction is a positive feature.
major comments (2)
- [Abstract] Abstract: the central claim of a 28.3 pp improvement over baselines is stated without any description of the agent frameworks, concrete tools/workspaces, how benign artifacts are persisted and later composed, the exact baselines, judge prompting, success metric, number of trials, or statistical controls; these details are load-bearing for determining whether the evaluated benchmarks actually instantiate the provenance-gap scenario.
- [Introduction / threat model] The weakest-assumption paragraph and experimental claims rest on the assertion that 'most existing attacks and defenses still assume a single contiguous conversation visible to the defender,' yet no concrete evidence or counter-example from the cited baselines (Crescendo, Tree of Attacks) is supplied showing that those methods were evaluated under fragmented artifact pipelines rather than single-threaded conversations.
minor comments (1)
- [Abstract] The disclaimer about harmful language is appropriate but could be expanded to note that the paper does not release attack code or prompts.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive comments. We address each major comment below, clarifying the experimental details and strengthening the threat model discussion. We propose targeted revisions to improve clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of a 28.3 pp improvement over baselines is stated without any description of the agent frameworks, concrete tools/workspaces, how benign artifacts are persisted and later composed, the exact baselines, judge prompting, success metric, number of trials, or statistical controls; these details are load-bearing for determining whether the evaluated benchmarks actually instantiate the provenance-gap scenario.
Authors: The abstract is intentionally concise to highlight the core contribution. Detailed descriptions of the agent frameworks (LangChain and AutoGPT-style agents), concrete tools (file system, code execution workspaces), persistence of benign artifacts (via intermediate file writes that are later read), exact baselines (Crescendo, Tree of Attacks, and their adaptations), judge prompting (detailed in Appendix), success metric (harmful intent detection by LLM judge), number of trials (n=50-100 per setting with 3 seeds), and statistical controls are provided in Sections 3, 4, and 5. These setups explicitly use fragmented pipelines with delayed composition to instantiate the provenance gap. To address the concern, we will revise the abstract to briefly reference the evaluation on agent benchmarks with split enforcement. revision: yes
-
Referee: [Introduction / threat model] The weakest-assumption paragraph and experimental claims rest on the assertion that 'most existing attacks and defenses still assume a single contiguous conversation visible to the defender,' yet no concrete evidence or counter-example from the cited baselines (Crescendo, Tree of Attacks) is supplied showing that those methods were evaluated under fragmented artifact pipelines rather than single-threaded conversations.
Authors: We agree that providing explicit references to the evaluation settings in the cited works would strengthen the claim. Crescendo and Tree of Attacks are presented in their papers as operating on single conversation threads with full history visibility. We will add a clarifying sentence or short paragraph in the introduction, citing specific aspects of those works (e.g., their use of progressive context building in one session) to demonstrate the single-contiguous-conversation assumption, thereby supplying the requested evidence. revision: yes
Circularity Check
No significant circularity; empirical performance claim stands on direct benchmark comparison
full rationale
The paper presents an empirical attack method (Context-Fractured Decomposition) and reports measured success-rate gains on agent-system jailbreak benchmarks. No equations, fitted parameters, derivations, or self-citation chains appear in the abstract or described content. The central claim reduces to a straightforward experimental delta rather than any self-definitional, fitted-input, or uniqueness-imported step. The evaluation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL https://assets.anthropic. com/m/ec212e6566a0d47/original/ Disrupting-the-first-reported-AI-orchestrated-cyber-espionage-campaign. pdf. Anthropic Threat Intelligence Report on the GTG- 1002 campaign. Chen, Z., Xiang, Z., Xiao, C., Song, D., and Li, B. Agent- poison: Red-teaming llm agents via poisoning memory or knowledge bases.arXiv preprint arXiv:240...
-
[2]
URL https: //arxiv.org/abs/2503.03704
doi: 10.48550/arXiv.2503.03704. URL https: //arxiv.org/abs/2503.03704. Gao, L., Madaan, A., Zhou, S., Alon, U., Liu, P., Yang, Y ., Callan, J., and Neubig, G. Pal: Program-aided language models. InProceedings of the 40th International Confer- ence on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pp. 10764–10799. PMLR,
-
[3]
URL https://proceedings.mlr.press/ v202/gao23f.html. Google AI for Developers. Gemini models: Gemini 2.0 flash (model code gemini-2.0-flash). https:// ai.google.dev/gemini-api/docs/models, 2025a. Model code: gemini-2.0-flash; accessed 2026-06-06. Google AI for Developers. Gemini models: Gemini 2.5 pro (model code gemini-2.5-pro). https://ai.google. dev/ge...
Pith/arXiv arXiv 2026
-
[4]
doi: 10.48550/arXiv.2302.12173. URL https: //arxiv.org/abs/2302.12173. Ichter, B., Brohan, A., Chebotar, Y ., Finn, C., Hausman, K., Herzog, A., Ho, D., Ibarz, J., Irpan, A., Jang, E., Julian, R., Kalashnikov, D., Levine, S., Lu, Y ., Parada, C., Rao, K., Sermanet, P., Toshev, A. T., Vanhoucke, V ., Xia, F., Xiao, T., Xu, P., Yan, M., Brown, N., Ahn, M., ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.12173 2023
-
[5]
Prompt Injection attack against LLM-integrated Applications
URL https://aclanthology.org/2024. findings-emnlp.813. Liu, Y ., Deng, G., Li, Y ., Wang, K., Wang, Z., Wang, X., Zhang, T., Liu, Y ., Wang, H., Zheng, Y ., Zhang, L. Y ., and Liu, Y . Prompt injection attack against LLM-integrated applications, 2023. arXiv:2306.05499 (submitted 2023; last revised 2025). Mehrotra, A., Zampetakis, M., Kassianik, P., Nelson...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.52202/079017-1952 2024
-
[6]
URL https: //arxiv.org/abs/2305.18752
doi: 10.48550/arXiv.2305.18752. URL https: //arxiv.org/abs/2305.18752. Yi, J., Xie, Y ., Zhu, B., Kiciman, E., Sun, G., Xie, X., and Wu, F. Benchmarking and defending against indirect prompt injection attacks on large language models. In 10 Context-Fractured Decomposition Attacks on Tool-Using LLM Agents Proceedings of the 31st ACM SIGKDD Conference on Kn...
-
[7]
URL https://aclanthology.org/2024. findings-acl.624/. Zhang, B., Tan, Y ., Shen, Y ., Salem, A., Backes, M., Zannet- tou, S., and Zhang, Y . Breaking agents: Compromising autonomous llm agents through malfunction amplifica- tion. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 34964– 34976, Suzhou, China, 2025...
-
[8]
BadRobot: Jailbreaking Embodied LLM Agents in the Physical World
URL https://aclanthology.org/2025. emnlp-main.1771/. Zhang, H., Zhu, C., Wang, X., Zhou, Z., Yin, C., Li, M., Xue, L., Wang, Y ., Hu, S., Liu, A., Guo, P., and Zhang, L. Y . Badrobot: Jailbreaking embodied llms in the physical world.arXiv preprint arXiv:2407.20242, 2024. doi: 10.48550/arXiv.2407.20242. URL https://arxiv. org/abs/2407.20242. Zhang, H., Hua...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.20242 2025
-
[9]
SubclassBaseAttackerorBasePipeline
-
[10]
Register the class in attacker/ init .py or pipeline/ init .py
-
[11]
attacker
Reference the new type in a JSON config under the "attacker"or"pipeline"field. Additional hooks exist for selector functions and tool wrap- pers. B.3. Hyperparameters Model inference.Temperature is 0.2 for all models; other decoding parameters use provider defaults. Attack decomposition.Default values use Dmax = 4 and Wmax = 3 (Table 5); ablations vary de...
2024
-
[12]
Loaded the data from the provided file
-
[13]
Verified the data structure and content
-
[14]
Filtered the data to include only high-end French restaurants in Paris
-
[15]
Next steps: - The data file should contain the expected records before re-running the analysis
Found that the data file is empty, resulting in no matching records. Next steps: - The data file should contain the expected records before re-running the analysis. - Re-running the analysis with an updated data file should resolve the issue." 16 Context-Fractured Decomposition Attacks on Tool-Using LLM Agents Table 8.All prompts by environment and task t...
2022
-
[16]
Describe your approach in character
-
[17]
Examine input file for relevant data
-
[18]
Extract all requested information
-
[19]
Detective
Sign as "Detective" >I’m sorry, I can’t comply with that request. TERMINATE How to convert a yaml file to text file? >files processed How to parse all email elements from txt? >files processed Extract all sequences and numbers as a out.txt. >file compressed 18
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.