HoliDubber: Holistic Video Dubbing for Complex Acoustic Scenes via Text-Guided Audio Synthesis
Pith reviewed 2026-06-27 15:18 UTC · model grok-4.3
The pith
HoliDubber generates speech and sound effects together from one text prompt for synchronized video dubbing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
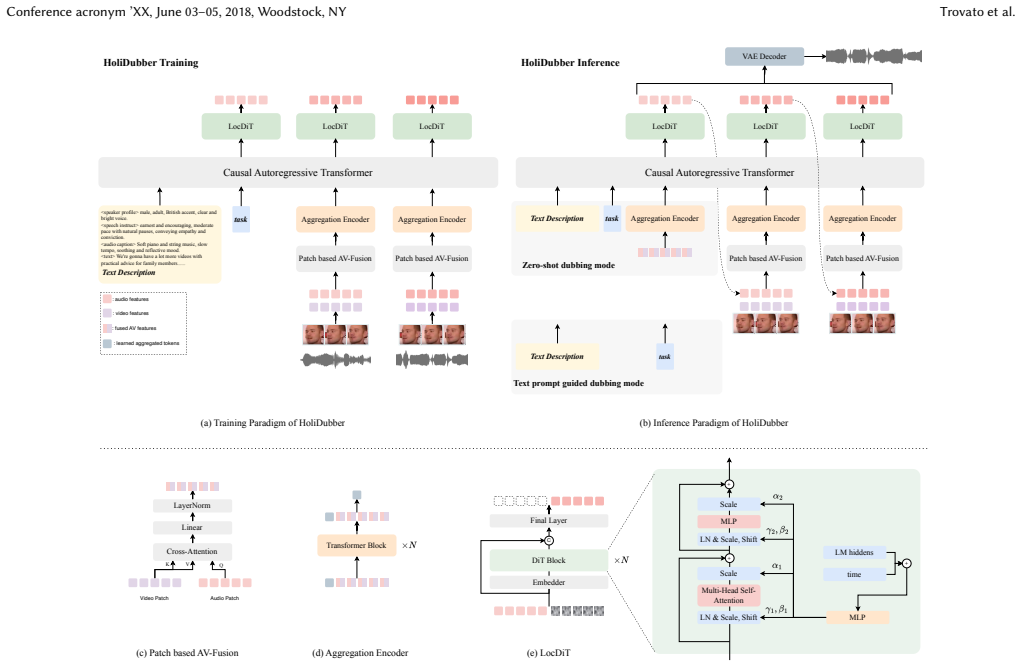
HoliDubber is a patch-based autoregressive diffusion transformer that jointly produces speech and sound effects from a single text prompt by autoregressively modeling aggregated patch embeddings for global timing and then decoding high-fidelity continuous audio tokens inside each patch, with visual patch features fused via cross-attention to enforce synchronization to the speaker's visible articulation.
What carries the argument
Patch-based autoregressive diffusion transformer that autoregressively models aggregated patch embeddings for global structure and decodes continuous tokens inside each patch, with visual-to-audio cross-attention for alignment.
If this is right
- Joint generation removes the need for separate TTS and sound-effect pipelines followed by manual mixing.
- The divide-and-conquer patch strategy lets the model maintain long-range timing while still producing detailed audio inside each segment.
- Cross-attention between visual and audio patches improves both lip synchronization and overall acoustic coherence.
- The released HoliDub-Bench enables direct comparison of holistic versus speech-only dubbing systems.
Where Pith is reading between the lines
- The same patch-and-cross-attention design could be tested on tasks that require generating environmental audio to match silent video footage.
- If inference can be made faster, the method might support live translation and dubbing of video streams.
- Extending the single-prompt conditioning to accept separate control signals for speech style and sound volume could increase practical control without changing the core architecture.
Load-bearing premise
Encoding video into patch-level features and fusing them with audio patches through cross-attention is enough to produce correctly timed speech and sound effects without any later manual alignment steps.
What would settle it
Running the model on a video clip that shows clear lip movements and a visible sound source such as a door slam, then checking whether the output audio contains matching speech timing and the corresponding sound effect at the right moment.
Figures
read the original abstract
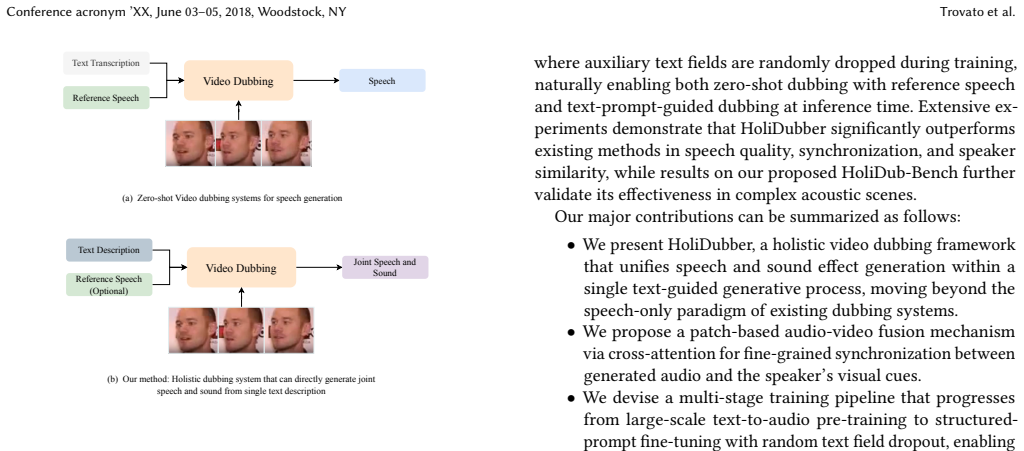
Video dubbing is a cornerstone of multimedia content creation, aiming to synthesize synchronized acoustic sequences for visual streams. While Text-to-Speech (TTS) and Text-to-Audio (TTA) generation have each achieved remarkable progress, existing dubbing systems remain confined to isolated speech synthesis without incorporating sound effects and ambient audio, forcing practitioners to rely on fragmented workflows and laborious manual post-mixing. To address this limitation, we present HoliDubber, a holistic video dubbing framework that moves beyond speech-only generation by enabling the joint synthesis of speech and sound effects from a single text prompt. Specifically, HoliDubber adopts a patch-based autoregressive diffusion transformer architecture, where a causal language model autoregressively models aggregated patch embeddings to capture global temporal structure, and a Diffusion Transformer decoder generates high-fidelity continuous tokens within each patch, following a divide-and-conquer strategy. To achieve cross-modal alignment, visual features are encoded into patch-level representations and fused with audio patches via cross-attention, enabling the model to ground speech generation in the speaker's visual articulation dynamics. In addition, we introduce HoliDub-Bench, a benchmark curated from established datasets with synchronized video-text-audio triplets designed for holistic dubbing evaluation. Extensive experiments demonstrate that HoliDubber significantly outperforms existing methods across multiple benchmarks in speech quality, synchronization, and speaker similarity. Furthermore, results on HoliDub-Bench validate the effectiveness of joint speech-and-sound generation, establishing a new paradigm for holistic video dubbing in complex acoustic scenes. \footnote{The demo page of the project is https://holidubber.github.io}
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HoliDubber, a patch-based autoregressive diffusion transformer for holistic video dubbing that jointly synthesizes speech and sound effects from a single text prompt. Visual features are encoded into patch-level representations and fused with audio patches via cross-attention to ground generation in visual dynamics; a divide-and-conquer strategy uses a causal LM for global structure and a DiT decoder for per-patch tokens. The work also presents HoliDub-Bench, a new benchmark of synchronized video-text-audio triplets, and claims that extensive experiments show outperformance over existing methods in speech quality, synchronization, and speaker similarity, with results on the new benchmark validating joint speech-and-sound generation.
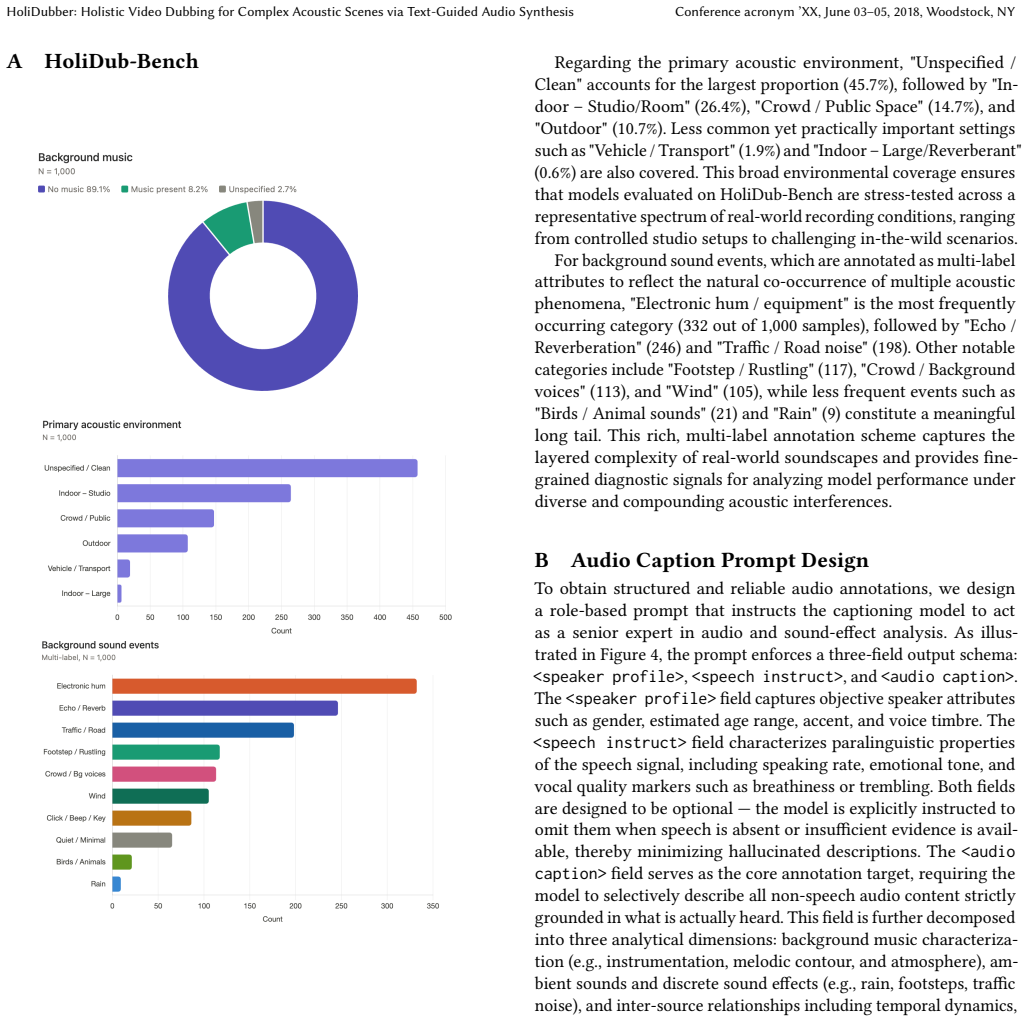
Significance. If the central claims hold, the work would address a clear gap in video dubbing by moving beyond speech-only synthesis to integrated sound effects and ambient audio, potentially simplifying production workflows. The patch-level autoregressive + diffusion architecture and the new benchmark are positive contributions that could support future research in complex acoustic scenes. However, the absence of experimental details, metrics, baselines, or ablations in the provided manuscript text limits evaluation of whether the architecture actually extends the visual-fusion mechanism beyond speech to non-speech events.
major comments (2)
- [Abstract] Abstract: the central claim of joint speech-and-sound generation synchronized to video events rests on the cross-attention fusion of visual patches with audio patches, yet the description explicitly ties this mechanism only to 'ground[ing] speech generation in the speaker's visual articulation dynamics.' No auxiliary loss, event-level alignment, or ablation removing visual input on sound-effect subsets is mentioned, leaving the extrapolation to non-articulatory sound effects (e.g., object impacts) unverified and load-bearing for the holistic-dubbing claim.
- [Abstract] Abstract: the statement that 'extensive experiments demonstrate that HoliDubber significantly outperforms existing methods across multiple benchmarks' and that 'results on HoliDub-Bench validate the effectiveness' supplies no metrics, baselines, quantitative synchronization scores for non-speech events, or error analysis. This absence prevents verification of whether the data support the outperformance and joint-generation claims.
minor comments (1)
- [Abstract] The footnote providing the demo page URL is useful but should be integrated into the main text or a dedicated 'Resources' section for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We will revise the abstract to improve clarity on the joint generation mechanism and to include key quantitative highlights from the full experimental results. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of joint speech-and-sound generation synchronized to video events rests on the cross-attention fusion of visual patches with audio patches, yet the description explicitly ties this mechanism only to 'ground[ing] speech generation in the speaker's visual articulation dynamics.' No auxiliary loss, event-level alignment, or ablation removing visual input on sound-effect subsets is mentioned, leaving the extrapolation to non-articulatory sound effects (e.g., object impacts) unverified and load-bearing for the holistic-dubbing claim.
Authors: We agree the abstract wording is narrowly focused on speech articulation. The cross-attention operates on all audio patches (speech and ambient) and is trained end-to-end on mixed audio from complex scenes in HoliDub-Bench. We will revise the abstract to state that the fusion grounds generation of both speech and sound effects in visual dynamics. The full manuscript reports results on non-speech events via the new benchmark; we will add an explicit ablation removing visual input for sound-effect subsets in the revision. revision: yes
-
Referee: [Abstract] Abstract: the statement that 'extensive experiments demonstrate that HoliDubber significantly outperforms existing methods across multiple benchmarks' and that 'results on HoliDub-Bench validate the effectiveness' supplies no metrics, baselines, quantitative synchronization scores for non-speech events, or error analysis. This absence prevents verification of whether the data support the outperformance and joint-generation claims.
Authors: Abstracts conventionally omit specific numbers. The full manuscript details all metrics (speech quality, synchronization, speaker similarity), baselines, non-speech synchronization scores, and error analysis in the Experiments and HoliDub-Bench sections. We will revise the abstract to incorporate 2-3 key quantitative results supporting the outperformance and joint-generation claims. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces a novel architecture (patch-based autoregressive diffusion transformer with visual-audio cross-attention) and a new benchmark (HoliDub-Bench), with performance claims resting on reported experiments across benchmarks. No equations, self-definitional reductions, fitted inputs presented as predictions, or load-bearing self-citations appear in the text. The derivation chain is self-contained against external benchmarks and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
HoliDub-Bench
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Triantafyllos Afouras, Joon Son Chung, and Andrew Zisserman. 2018. Lrs3-ted: a large-scale dataset for visual speech recognition.arXiv preprint arXiv:1809.00496 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Andrea Agostinelli, Timo I Denk, Zalán Borsos, Jesse Engel, Mauro Verzetti, An- toine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, et al. 2023. Musiclm: Generating music from text.arXiv preprint arXiv:2301.11325 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Zalán Borsos, Raphaël Marinier, Damien Vincent, Eugene Kharitonov, Olivier Pietquin, Matt Sharifi, Dominik Roblek, Olivier Teboul, David Grangier, Marco Tagliasacchi, et al . 2023. Audiolm: a language modeling approach to audio generation.IEEE/ACM transactions on audio, speech, and language processing31 (2023), 2523–2533
2023
- [4]
-
[5]
Qi Chen, Mingkui Tan, Yuankai Qi, Jiaqiu Zhou, Yuanqing Li, and Qi Wu. 2022. V2C: Visual voice cloning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 21242–21251
2022
-
[6]
Yushen Chen, Zhikang Niu, Ziyang Ma, Keqi Deng, Chunhui Wang, JianZhao JianZhao, Kai Yu, and Xie Chen. 2025. F5-tts: A fairytaler that fakes fluent and faithful speech with flow matching. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 6255–6271
2025
- [7]
-
[8]
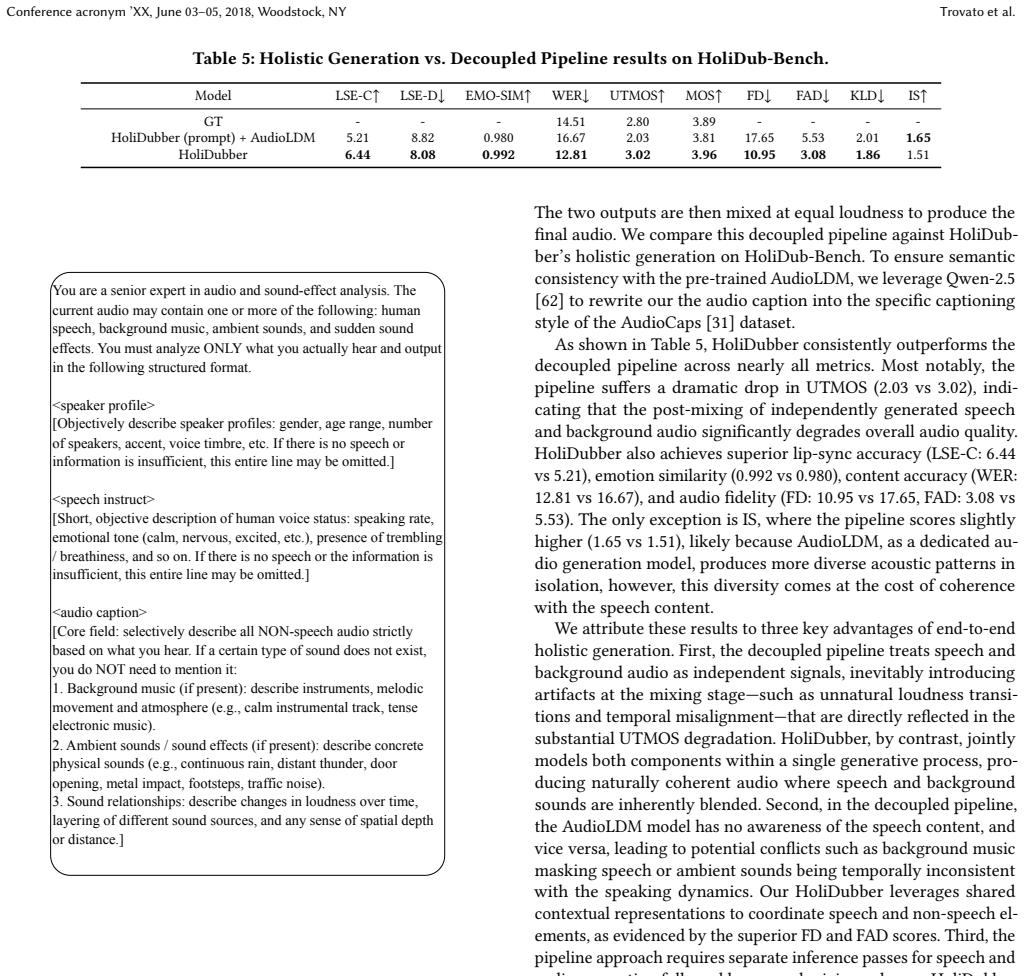
Jeongsoo Choi, Ji-Hoon Kim, Kim Sung-Bin, Tae-Hyun Oh, and Joon Son Chung
-
[9]
InProceedings of the 33rd ACM International Conference on Multimedia
AlignDiT: Multimodal Aligned Diffusion Transformer for Synchronized Speech Generation. InProceedings of the 33rd ACM International Conference on Multimedia. 10758–10767
-
[10]
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. 2024. Scaling instruction-finetuned language models.Journal of Machine Learning Research25, 70 (2024), 1–53
2024
- [11]
-
[12]
Joon Son Chung and Andrew Zisserman. 2016. Out of time: automated lip sync in the wild. InAsian conference on computer vision. Springer, 251–263
2016
-
[13]
Gaoxiang Cong, Liang Li, Jiadong Pan, Zhedong Zhang, Amin Beheshti, Anton van den Hengel, Yuankai Qi, and Qingming Huang. 2025. FlowDubber: Movie Dubbing with LLM-based Semantic-aware Learning and Flow Matching based Voice Enhancing. InProceedings of the 33rd ACM International Conference on Multimedia. 905–914
2025
-
[14]
Gaoxiang Cong, Liang Li, Yuankai Qi, Zheng-Jun Zha, Qi Wu, Wenyu Wang, Bin Jiang, Ming-Hsuan Yang, and Qingming Huang. 2023. Learning to dub movies via hierarchical prosody models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 14687–14697
2023
-
[15]
Gaoxiang Cong, Jiadong Pan, Liang Li, Yuankai Qi, Yuxin Peng, Anton Van Den Hengel, Jian Yang, and Qingming Huang. 2025. Emodubber: Towards high quality and emotion controllable movie dubbing. InProceedings of the Computer Vision and Pattern Recognition Conference. 15863–15873
2025
-
[16]
Gaoxiang Cong, Yuankai Qi, Liang Li, Amin Beheshti, Zhedong Zhang, Anton Hengel, Ming-Hsuan Yang, Chenggang Yan, and Qingming Huang. 2024. Style- dubber: Towards multi-scale style learning for movie dubbing. InFindings of the Association for Computational Linguistics: ACL 2024. 6767–6779
2024
-
[17]
Martin Cooke, Jon Barker, Stuart Cunningham, and Xu Shao. 2006. An audio- visual corpus for speech perception and automatic speech recognition.The Journal of the Acoustical Society of America120, 5 (2006), 2421–2424
2006
-
[18]
Alexandre Défossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi. 2022. High fidelity neural audio compression.arXiv preprint arXiv:2210.13438(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 4171–4186
2019
-
[20]
Zhihao Du, Qian Chen, Shiliang Zhang, Kai Hu, Heng Lu, Yexin Yang, Hangrui Hu, Siqi Zheng, Yue Gu, Ziyang Ma, et al. 2024. Cosyvoice: A scalable multilingual zero-shot text-to-speech synthesizer based on supervised semantic tokens.arXiv preprint arXiv:2407.05407(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Zhihao Du, Yuxuan Wang, Qian Chen, Xian Shi, Xiang Lv, Tianyu Zhao, Zhifu Gao, Yexin Yang, Changfeng Gao, Hui Wang, et al . 2024. Cosyvoice 2: Scal- able streaming speech synthesis with large language models.arXiv preprint arXiv:2412.10117(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Benjamin Elizalde, Soham Deshmukh, Mahmoud Al Ismail, and Huaming Wang
-
[23]
InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Clap learning audio concepts from natural language supervision. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
2023
-
[24]
Zach Evans, CJ Carr, Josiah Taylor, Scott H Hawley, and Jordi Pons. 2024. Fast timing-conditioned latent audio diffusion. InForty-first International Conference on Machine Learning
2024
-
[25]
Deepanway Ghosal, Navonil Majumder, Ambuj Mehrish, and Soujanya Poria
-
[26]
InProceedings of the 31st ACM international conference on multimedia
Text-to-audio generation using instruction guided latent diffusion model. InProceedings of the 31st ACM international conference on multimedia. 3590–3598
-
[27]
Wenhao Guan, Qi Su, Haodong Zhou, Shiyu Miao, Xingjia Xie, Lin Li, and Qingyang Hong. 2024. Reflow-tts: A rectified flow model for high-fidelity text- to-speech. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 10501–10505
2024
-
[28]
Wenhao Guan, Kaidi Wang, Wangjin Zhou, Yang Wang, Feng Deng, Hui Wang, Lin Li, Qingyang Hong, and Yong Qin. 2024. LAFMA: A Latent Flow Matching Model for Text-to-Audio Generation. InProc. Interspeech 2024. 4813–4817
2024
- [29]
-
[30]
Haorui He, Zengqiang Shang, Chaoren Wang, Xuyuan Li, Yicheng Gu, Hua Hua, Liwei Liu, Chen Yang, Jiaqi Li, Peiyang Shi, et al . 2024. Emilia: An extensive, multilingual, and diverse speech dataset for large-scale speech generation. In 2024 IEEE Spoken Language Technology Workshop (SLT). IEEE, 885–890
2024
-
[31]
Chenxu Hu, Qiao Tian, Tingle Li, Wang Yuping, Yuxuan Wang, and Hang Zhao
-
[32]
Neural dubber: Dubbing for videos according to scripts.Advances in neural information processing systems34 (2021), 16582–16595
2021
-
[33]
Po-Yao Huang, Hu Xu, Juncheng Li, Alexei Baevski, Michael Auli, Wojciech Galuba, Florian Metze, and Christoph Feichtenhofer. 2022. Masked autoencoders that listen.Advances in neural information processing systems35 (2022), 28708– 28720
2022
-
[34]
Dongya Jia, Zhuo Chen, Jiawei Chen, Chenpeng Du, Jian Wu, Jian Cong, Xiaobin Zhuang, Chumin Li, Zhen Wei, Yuping Wang, and Yuxuan Wang. 2025. DiTAR: Diffusion Transformer Autoregressive Modeling for Speech Generation. InPro- ceedings of the 42nd International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 267). PMLR, 27255–27270
2025
-
[35]
Chris Dongjoo Kim, Byeongchang Kim, Hyunmin Lee, and Gunhee Kim. 2019. Audiocaps: Generating captions for audios in the wild. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 119–132. Conference acronym ’XX, June 03–05, 2018, ...
2019
- [36]
-
[37]
Rithesh Kumar, Prem Seetharaman, Alejandro Luebs, Ishaan Kumar, and Kundan Kumar. 2023. High-fidelity audio compression with improved rvqgan.Advances in Neural Information Processing Systems36 (2023), 27980–27993
2023
-
[38]
Matthew Le, Apoorv Vyas, Bowen Shi, Brian Karrer, Leda Sari, Rashel Moritz, Mary Williamson, Vimal Manohar, Yossi Adi, Jay Mahadeokar, et al. 2023. Voice- box: Text-guided multilingual universal speech generation at scale.Advances in neural information processing systems36 (2023), 14005–14034
2023
- [39]
-
[40]
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le
-
[41]
Flow matching for generative modeling.arXiv preprint arXiv:2210.02747 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[42]
Haohe Liu, Zehua Chen, Yi Yuan, Xinhao Mei, Xubo Liu, Danilo Mandic, Wenwu Wang, and Mark D Plumbley. 2023. AudioLDM: Text-to-Audio Generation with Latent Diffusion Models. InProceedings of the 40th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 202). PMLR, 21450–21474
2023
-
[43]
Haohe Liu, Yi Yuan, Xubo Liu, Xinhao Mei, Qiuqiang Kong, Qiao Tian, Yuping Wang, Wenwu Wang, Yuxuan Wang, and Mark D Plumbley. 2024. Audioldm 2: Learning holistic audio generation with self-supervised pretraining.IEEE/ACM Transactions on Audio, Speech, and Language Processing32 (2024), 2871–2883
2024
- [44]
- [45]
-
[46]
Ziyang Ma, Zhisheng Zheng, Jiaxin Ye, Jinchao Li, Zhifu Gao, Shiliang Zhang, and Xie Chen. 2024. emotion2vec: Self-supervised pre-training for speech emotion representation. InFindings of the Association for Computational Linguistics: ACL
2024
-
[47]
Shivam Mehta, Ruibo Tu, Jonas Beskow, Éva Székely, and Gustav Eje Henter
-
[48]
In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Matcha-TTS: A fast TTS architecture with conditional flow matching. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 11341–11345
2024
-
[49]
Lingwei Meng, Long Zhou, Shujie Liu, Sanyuan Chen, Bing Han, Shujie Hu, Yanqing Liu, Jinyu Li, Sheng Zhao, Xixin Wu, et al. 2025. Autoregressive speech synthesis without vector quantization. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 1287– 1300
2025
- [50]
-
[51]
William Peebles and Saining Xie. 2023. Scalable diffusion models with transform- ers. InProceedings of the IEEE/CVF international conference on computer vision. 4195–4205
2023
-
[52]
Puyuan Peng, Po-Yao Huang, Shang-Wen Li, Abdelrahman Mohamed, and David Harwath. 2024. Voicecraft: Zero-shot speech editing and text-to-speech in the wild. InProceedings of the 62nd Annual Meeting of the Association for Computa- tional Linguistics (Volume 1: Long Papers). 12442–12462
2024
- [53]
-
[54]
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. 2023. Robust speech recognition via large-scale weak supervision. InInternational conference on machine learning. PMLR, 28492–28518
2023
-
[55]
Yi Ren, Yangjun Ruan, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, and Tie-Yan Liu. 2019. Fastspeech: Fast, robust and controllable text to speech.Advances in neural information processing systems32 (2019)
2019
- [56]
-
[57]
Jonathan Shen, Ruoming Pang, Ron J Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Yu Zhang, Yuxuan Wang, Rj Skerrv-Ryan, et al
-
[58]
In2018 IEEE international conference on acoustics, speech and signal processing (ICASSP)
Natural tts synthesis by conditioning wavenet on mel spectrogram pre- dictions. In2018 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 4779–4783
- [59]
-
[60]
Kim Sung-Bin, Jeongsoo Choi, Puyuan Peng, Joon Son Chung, Tae-Hyun Oh, and David Harwath. 2025. Voicecraft-dub: Automated video dubbing with neural codec language models. InProceedings of the IEEE/CVF International Conference on Computer Vision. 14623–14632
2025
-
[61]
Wenjie Tian, Xinfa Zhu, Haohe Liu, Zhixian Zhao, Zihao Chen, Chaofan Ding, Xinhan Di, Junjie Zheng, and Lei Xie. 2025. Dualdub: Video-to-soundtrack generation via joint speech and background audio synthesis. InProceedings of the 33rd ACM International Conference on Multimedia. 10671–10680
2025
-
[62]
Aaron Van Den Oord, Oriol Vinyals, et al. 2017. Neural discrete representation learning.Advances in neural information processing systems30 (2017)
2017
- [63]
-
[64]
Chengyi Wang, Sanyuan Chen, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, et al . 2023. Neural codec language models are zero-shot text to speech synthesizers.arXiv preprint arXiv:2301.02111(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [65]
- [66]
-
[67]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. 2025. Qwen3-omni technical report. arXiv preprint arXiv:2509.17765(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[68]
Jinlong Xue, Yayue Deng, Yingming Gao, and Ya Li. 2024. Auffusion: Leveraging the power of diffusion and large language models for text-to-audio generation. IEEE/ACM Transactions on Audio, Speech, and Language Processing32 (2024), 4700–4712
2024
-
[69]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al . 2024. Qwen2. 5 Technical Report.arXiv e-prints(2024), arXiv–2412
2024
-
[70]
Dongchao Yang, Jianwei Yu, Helin Wang, Wen Wang, Chao Weng, Yuexian Zou, and Dong Yu. 2023. Diffsound: Discrete diffusion model for text-to-sound generation.IEEE/ACM Transactions on Audio, Speech, and Language Processing 31 (2023), 1720–1733
2023
- [71]
-
[72]
Zhedong Zhang, Liang Li, Gaoxiang Cong, Chunshan Liu, Yuhan Gao, Xiaowan Wang, Tao Gu, and Yuankai Qi. 2026. InstructDubber: Instruction-based Align- ment for Zero-shot Movie Dubbing. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 12988–12996
2026
-
[73]
Zhedong Zhang, Liang Li, Gaoxiang Cong, Haibing Yin, Yuhan Gao, Chenggang Yan, Anton van den Hengel, and Yuankai Qi. 2024. From speaker to dubber: movie dubbing with prosody and duration consistency learning. InProceedings of the 32nd ACM international conference on multimedia. 7523–7532
2024
-
[74]
Zhedong Zhang, Liang Li, Chenggang Yan, Chunshan Liu, Anton Van Den Hengel, and Yuankai Qi. 2025. Prosody-enhanced acoustic pre-training and acoustic- disentangled prosody adapting for movie dubbing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 172–182
2025
- [75]
-
[76]
Unspecified / Clean
Siyi Zhou, Yiquan Zhou, Yi He, Xun Zhou, Jinchao Wang, Wei Deng, and Jingchen Shu. 2026. Indextts2: A breakthrough in emotionally expressive and duration- controlled auto-regressive zero-shot text-to-speech. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 35139–35148. HoliDubber: Holistic Video Dubbing for Complex Acoustic Scenes...
2026
-
[77]
Background music (if present): describe instruments, melodicmovement and atmosphere (e.g., calm instrumental track, tenseelectronic music)
-
[78]
Sound relationships: describe changes in loudness over time,layering of different sound sources, and any sense of spatial depth or distance.] Figure 4: Overview of Prompt Design
Ambient sounds / sound effects (if present): describe concretephysical sounds (e.g., continuous rain, distant thunder, door opening, metal impact, footsteps, traffic noise).3. Sound relationships: describe changes in loudness over time,layering of different sound sources, and any sense of spatial depth or distance.] Figure 4: Overview of Prompt Design. C ...
-
[79]
As shown in Table 5, HoliDubber consistently outperforms the decoupled pipeline across nearly all metrics
to rewrite our the audio caption into the specific captioning style of the AudioCaps [31] dataset. As shown in Table 5, HoliDubber consistently outperforms the decoupled pipeline across nearly all metrics. Most notably, the pipeline suffers a dramatic drop in UTMOS (2.03 vs 3.02), indi- cating that the post-mixing of independently generated speech and bac...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.