Vision Language Model Helps Private Information De-Identification in Vision Data
Pith reviewed 2026-06-27 16:27 UTC · model grok-4.3
The pith
VisShield trains vision-language models to localize and mask private text in images using a specialized dataset.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
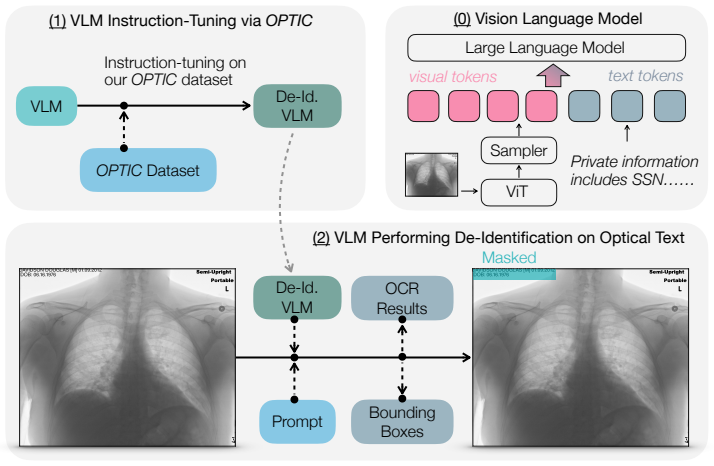
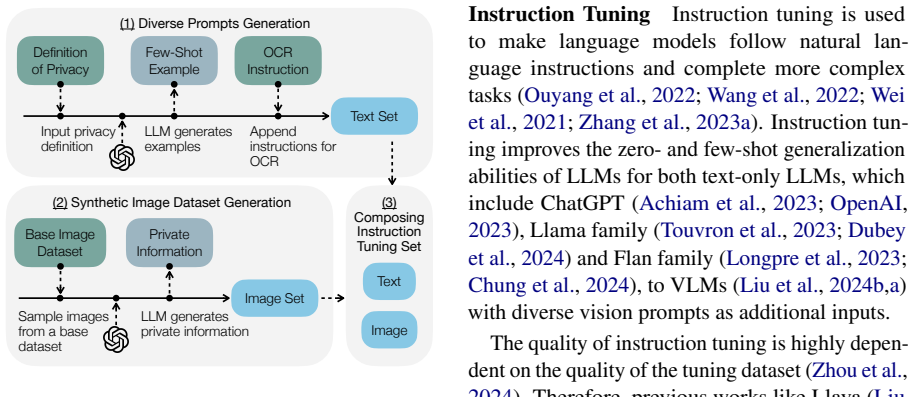
The central claim is that the VisShield framework, built from the OPTIC instruction-tuning dataset and a tailored training methodology, lets vision-language models recognize privacy-sensitive text, perform precise localization, and output bounding boxes that enable effective masking, thereby outperforming existing approaches in privacy protection for vision data.
What carries the argument
The VisShield framework consisting of the OPTIC dataset that supplies privacy-oriented prompts for targeted OCR and the training strategy that adapts VLMs to output bounding boxes for sensitive entities.
Load-bearing premise
The assumption that instruction tuning on the OPTIC dataset and the tailored training methodology will enable VLMs to accurately localize sensitive text and produce usable bounding boxes for effective masking.
What would settle it
An experiment in which the adapted VLM produces bounding boxes that fail to align with ground-truth sensitive text locations or shows no improvement over baselines on privacy metrics would falsify the central claim.
Figures







read the original abstract
Visual Language Models (VLMs) have gained significant popularity due to their remarkable ability. While various methods exist to enhance privacy in text-based applications, privacy risks associated with visual inputs remain largely overlooked such as Protected Health Information (PHI) in medical images. To tackle this problem, two key tasks: accurately localizing sensitive text and processing it to ensure privacy protection should be performed. To address this issue, we introduce VisShield (Vision Privacy Shield), an end-to-end framework designed to enhance the privacy awareness of VLMs. Our framework consists of two key components: a specialized instruction-tuning dataset OPTIC (Optical Privacy Text Instruction Collection) and a tailored training methodology. The dataset provides diverse privacy-oriented prompts that guide VLMs to perform targeted Optical Character Recognition (OCR) for precise localization of sensitive text, while the training strategy ensures effective adaptation of VLMs to privacy-preserving tasks. Specifically, our approach ensures that VLMs recognize privacy-sensitive text and output precise bounding boxes for detected entities, allowing for effective masking of sensitive information. Extensive experiments demonstrate that our framework significantly outperforms existing approaches in handling private information, paving the way for privacy-preserving applications in vision-language models. Our dataset and code can be found here.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces VisShield, an end-to-end framework that instruction-tunes vision-language models on the OPTIC dataset to perform targeted OCR, output bounding boxes around sensitive text (e.g., PHI), and enable subsequent masking. It claims this yields significant outperformance over existing approaches for privacy preservation in vision data.
Significance. If the localization step is shown to be reliable, the framework could meaningfully advance privacy-preserving VLM applications in domains such as medical imaging. Releasing the OPTIC dataset and code is a positive contribution to reproducibility.
major comments (2)
- [Section 4] Section 4: Experiments report only downstream privacy metrics (de-identification success rates) and qualitative examples. No tables or text supply standard localization metrics such as mean IoU, precision@IoU=0.5, or recall for the bounding-box outputs on held-out images. This is load-bearing because the central claim requires that the boxes be precise enough for effective masking; without these numbers it is impossible to distinguish reliable localization from prompt-engineering effects.
- [Section 3] Section 3: The training objective is described as eliciting OCR plus box output, yet no ablation or validation is provided on how well the fine-tuned model generalizes to unseen image distributions or prompt variations that would affect box quality.
minor comments (2)
- [Abstract] Abstract and Section 1 should explicitly list the baselines, metrics, and error analysis used in the experiments rather than stating only that outperformance was observed.
- [Section 3] Notation for bounding-box coordinates and the masking procedure should be defined once with consistent symbols across Sections 3 and 4.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive suggestions. We address the major comments below and plan to incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: Section 4: Experiments report only downstream privacy metrics (de-identification success rates) and qualitative examples. No tables or text supply standard localization metrics such as mean IoU, precision@IoU=0.5, or recall for the bounding-box outputs on held-out images. This is load-bearing because the central claim requires that the boxes be precise enough for effective masking; without these numbers it is impossible to distinguish reliable localization from prompt-engineering effects.
Authors: We agree that providing standard localization metrics would offer a more comprehensive evaluation of the bounding box outputs. Although the de-identification success rates indirectly validate the localization quality (as inaccurate boxes would lead to failed masking), we will revise Section 4 to include a table with mean IoU, precision at IoU=0.5, and recall computed on held-out images. This will help demonstrate that the localization is reliable rather than due to prompt engineering. revision: yes
-
Referee: Section 3: The training objective is described as eliciting OCR plus box output, yet no ablation or validation is provided on how well the fine-tuned model generalizes to unseen image distributions or prompt variations that would affect box quality.
Authors: The comment is valid; additional validation on generalization would be beneficial. We will add experiments evaluating the model on unseen image distributions (e.g., non-medical images or different scanners) and different prompt variations, reporting the corresponding localization metrics to assess robustness. revision: yes
Circularity Check
No derivation chain or self-referential elements present
full rationale
The paper presents an applied framework (VisShield) built around a new instruction-tuning dataset (OPTIC) and a training procedure for VLMs to output bounding boxes for sensitive text, followed by masking. No equations, parameters fitted to subsets then re-predicted, or mathematical derivations appear in the abstract or described sections. Claims rest on downstream empirical results rather than any reduction to prior self-citations or definitional loops. The absence of any load-bearing derivation chain means the work is self-contained against external benchmarks with no circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[2]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[3]
Advances in neural information processing systems , volume=
Flamingo: a visual language model for few-shot learning , author=. Advances in neural information processing systems , volume=
-
[4]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution , author=. arXiv preprint arXiv:2409.12191 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
arXiv preprint arXiv:2405.02246 , year=
What matters when building vision-language models? , author=. arXiv preprint arXiv:2405.02246 , year=
-
[6]
European Conference on Computer Vision , pages=
Vary: Scaling up the vision vocabulary for large vision-language model , author=. European Conference on Computer Vision , pages=. 2025 , organization=
2025
-
[7]
PaliGemma: A versatile 3B VLM for transfer
Paligemma: A versatile 3b vlm for transfer , author=. arXiv preprint arXiv:2407.07726 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
arXiv preprint arXiv:2405.20797 , year=
Ovis: Structural Embedding Alignment for Multimodal Large Language Model , author=. arXiv preprint arXiv:2405.20797 , year=
-
[9]
CogVLM: Visual Expert for Pretrained Language Models
Cogvlm: Visual expert for pretrained language models , author=. arXiv preprint arXiv:2311.03079 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Minigpt-4: Enhancing vision-language understanding with advanced large language models , author=. arXiv preprint arXiv:2304.10592 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Deepseek-vl: towards real-world vision-language understanding , author=. arXiv preprint arXiv:2403.05525 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
arXiv preprint arXiv:2408.08872 , year=
xgen-mm (blip-3): A family of open large multimodal models , author=. arXiv preprint arXiv:2408.08872 , year=
-
[13]
arXiv preprint arXiv:2309.11499 , year=
Dreamllm: Synergistic multimodal comprehension and creation , author=. arXiv preprint arXiv:2309.11499 , year=
-
[14]
arXiv preprint arXiv:2307.09474 , year=
Chatspot: Bootstrapping multimodal llms via precise referring instruction tuning , author=. arXiv preprint arXiv:2307.09474 , year=
-
[15]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Latr: Layout-aware transformer for scene-text vqa , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[16]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
From images to textual prompts: Zero-shot visual question answering with frozen large language models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[17]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Enhancing Visual Question Answering through Question-Driven Image Captions as Prompts , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[18]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Bliva: A simple multimodal llm for better handling of text-rich visual questions , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[19]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Fusecap: Leveraging large language models for enriched fused image captions , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[20]
Advances in Neural Information Processing Systems , volume=
Exploring diverse in-context configurations for image captioning , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
International Conference on Machine Learning , pages=
Pix2struct: Screenshot parsing as pretraining for visual language understanding , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[22]
Kosmos-2: Grounding Multimodal Large Language Models to the World
Kosmos-2: Grounding multimodal large language models to the world , author=. arXiv preprint arXiv:2306.14824 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
European Conference on Computer Vision , pages=
Merlin: Empowering multimodal llms with foresight minds , author=. European Conference on Computer Vision , pages=. 2025 , organization=
2025
-
[24]
arXiv preprint arXiv:2309.11419 , year=
Kosmos-2.5: A multimodal literate model , author=. arXiv preprint arXiv:2309.11419 , year=
-
[25]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[26]
arXiv preprint arXiv:2204.07705 , volume=
Benchmarking generalization via in-context instructions on 1,600+ language tasks , author=. arXiv preprint arXiv:2204.07705 , volume=
-
[27]
Finetuned Language Models Are Zero-Shot Learners
Finetuned language models are zero-shot learners , author=. arXiv preprint arXiv:2109.01652 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
arXiv preprint arXiv:2308.10792 , year=
Instruction tuning for large language models: A survey , author=. arXiv preprint arXiv:2308.10792 , year=
-
[29]
GPT-4 Technical Report , author=. arXiv preprint arXiv:2303.08774, 2023 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
2023 , url =
OpenAI , title =. 2023 , url =
2023
-
[31]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
International Conference on Machine Learning , pages=
The flan collection: Designing data and methods for effective instruction tuning , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[34]
Journal of Machine Learning Research , volume=
Scaling instruction-finetuned language models , author=. Journal of Machine Learning Research , volume=
-
[35]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Improved baselines with visual instruction tuning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[36]
Advances in Neural Information Processing Systems , volume=
Lima: Less is more for alignment , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
Computer Vision--ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13 , pages=
Microsoft coco: Common objects in context , author=. Computer Vision--ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13 , pages=. 2014 , organization=
2014
-
[38]
arXiv preprint arXiv:2306.17107 , year=
Llavar: Enhanced visual instruction tuning for text-rich image understanding , author=. arXiv preprint arXiv:2306.17107 , year=
-
[39]
arXiv 2023 , author=
Shikra: Unleashing Multimodal LLM’s Referential Dialogue Magic. arXiv 2023 , author=
2023
-
[40]
InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning , url =
Dai, Wenliang and Li, Junnan and LI, DONGXU and Tiong, Anthony and Zhao, Junqi and Wang, Weisheng and Li, Boyang and Fung, Pascale N and Hoi, Steven , booktitle =. InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning , url =
-
[41]
Proceedings of the IEEE international conference on computer vision , pages=
Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[42]
Scientific Data , volume=
A DICOM dataset for evaluation of medical image de-identification , author=. Scientific Data , volume=. 2021 , publisher=
2021
-
[43]
Signal Processing: Image Communication , volume=
De-identification for privacy protection in multimedia content: A survey , author=. Signal Processing: Image Communication , volume=. 2016 , publisher=
2016
-
[44]
Proceedings of the Workshop on NLP and Pseudonymisation , volume=
Pseudonymisation of Swedish electronic patient records using a rule-based approach , author=. Proceedings of the Workshop on NLP and Pseudonymisation , volume=
-
[45]
Journal of Personalized medicine , volume=
Verification of de-identification techniques for personal information using tree-based methods with Shapley values , author=. Journal of Personalized medicine , volume=. 2022 , publisher=
2022
-
[46]
Biomedical engineering systems and technologies, international joint conference, BIOSTEC
DeIDNER Model: A Neural Network Named Entity Recognition Model for Use in the De-identification of Clinical Notes , author=. Biomedical engineering systems and technologies, international joint conference, BIOSTEC... revised selected papers. BIOSTEC (Conference) , volume=. 2022 , organization=
2022
-
[47]
arXiv preprint arXiv:2303.11032 , year=
Deid-gpt: Zero-shot medical text de-identification by gpt-4 , author=. arXiv preprint arXiv:2303.11032 , year=
-
[48]
2006 Conference on computer vision and pattern recognition workshop (CVPRW'06) , pages=
Model-based face de-identification , author=. 2006 Conference on computer vision and pattern recognition workshop (CVPRW'06) , pages=. 2006 , organization=
2006
-
[49]
2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) , pages=
I know that person: Generative full body and face de-identification of people in images , author=. 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) , pages=. 2017 , organization=
2017
-
[50]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Personalized and invertible face de-identification by disentangled identity information manipulation , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[51]
Advances in Neural Information Processing Systems , volume=
Revisiting resnets: Improved training and scaling strategies , author=. Advances in Neural Information Processing Systems , volume=
-
[52]
IEEE intelligent systems , volume=
The unreasonable effectiveness of data , author=. IEEE intelligent systems , volume=. 2009 , publisher=
2009
-
[53]
2009 IEEE conference on computer vision and pattern recognition , pages=
Imagenet: A large-scale hierarchical image database , author=. 2009 IEEE conference on computer vision and pattern recognition , pages=. 2009 , organization=
2009
-
[54]
Scaling Laws for Neural Language Models
Scaling laws for neural language models , author=. arXiv preprint arXiv:2001.08361 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[55]
OPT: Open Pre-trained Transformer Language Models
Opt: Open pre-trained transformer language models , author=. arXiv preprint arXiv:2205.01068 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Qwen-vl: A frontier large vision-language model with versatile abilities , author=. arXiv preprint arXiv:2308.12966 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
arXiv preprint arXiv:2402.02103 , year=
D 'ej a Vu Memorization in Vision-Language Models , author=. arXiv preprint arXiv:2402.02103 , year=
-
[58]
International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=
Can llms’ tuning methods work in medical multimodal domain? , author=. International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=. 2024 , organization=
2024
-
[59]
2024 IEEE/ACM Conference on Connected Health: Applications, Systems and Engineering Technologies (CHASE) , pages=
On large visual language models for medical imaging analysis: An empirical study , author=. 2024 IEEE/ACM Conference on Connected Health: Applications, Systems and Engineering Technologies (CHASE) , pages=. 2024 , organization=
2024
-
[60]
arXiv preprint arXiv:2409.15256 , year=
Behavioral Bias of Vision-Language Models: A Behavioral Finance View , author=. arXiv preprint arXiv:2409.15256 , year=
-
[61]
Journal of the American Medical Informatics Association , volume=
BoB, a best-of-breed automated text de-identification system for VHA clinical documents , author=. Journal of the American Medical Informatics Association , volume=. 2013 , publisher=
2013
-
[62]
A Survey on In-context Learning
A survey on in-context learning , author=. arXiv preprint arXiv:2301.00234 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
Advances in Neural Information Processing Systems , volume=
What makes good examples for visual in-context learning? , author=. Advances in Neural Information Processing Systems , volume=
-
[64]
2024 , url =
Joke, Edén and contributors , title =. 2024 , url =
2024
-
[65]
2024 , url =
Pillow , author =. 2024 , url =
2024
-
[66]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
Connecting pixels to privacy and utility: Automatic redaction of private information in images , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[67]
LoRA: Low-Rank Adaptation of Large Language Models
Lora: Low-rank adaptation of large language models , author=. arXiv preprint arXiv:2106.09685 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[68]
arXiv preprint arXiv:2210.07903 , year=
Text detection forgot about document OCR , author=. arXiv preprint arXiv:2210.07903 , year=
-
[69]
IEEE transactions on pattern analysis and machine intelligence , volume=
Faster R-CNN: Towards real-time object detection with region proposal networks , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2016 , publisher=
2016
-
[70]
2023 , howpublished =
Presidio - Open Source Data Protection and Privacy Engineering Platform , author =. 2023 , howpublished =
2023
-
[71]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Scene parsing through ade20k dataset , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[72]
Medical Image Computing and Computer-Assisted Intervention--MICCAI 2013: 16th International Conference, Nagoya, Japan, September 22-26, 2013, Proceedings, Part II 16 , pages=
Automated separation of binary overlapping trees in low-contrast color retinal images , author=. Medical Image Computing and Computer-Assisted Intervention--MICCAI 2013: 16th International Conference, Nagoya, Japan, September 22-26, 2013, Proceedings, Part II 16 , pages=. 2013 , organization=
2013
-
[73]
arXiv preprint arXiv:2304.08109 , year=
A comparative study between full-parameter and lora-based fine-tuning on chinese instruction data for instruction following large language model , author=. arXiv preprint arXiv:2304.08109 , year=
-
[74]
Decoupled Weight Decay Regularization
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[75]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[76]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Phi-3 technical report: A highly capable language model locally on your phone , author=. arXiv preprint arXiv:2404.14219 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[77]
30th USENIX Security Symposium (USENIX Security 21) , pages=
Extracting training data from large language models , author=. 30th USENIX Security Symposium (USENIX Security 21) , pages=
-
[78]
arXiv preprint arXiv:2205.12506 , year=
Memorization in nlp fine-tuning methods , author=. arXiv preprint arXiv:2205.12506 , year=
-
[79]
arXiv preprint arXiv:2205.12628 , year=
Are Large Pre-Trained Language Models Leaking Your Personal Information? , author=. arXiv preprint arXiv:2205.12628 , year=
-
[80]
arXiv preprint arXiv:2410.22108 , year=
Protecting privacy in multimodal large language models with mllmu-bench , author=. arXiv preprint arXiv:2410.22108 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.