Unified Energy for Invariant and Independent Decoding in Diffusion Language Models
Pith reviewed 2026-06-27 16:49 UTC · model grok-4.3
The pith
A unified energy function corrects distribution shifts from dependency and invariance in diffusion language models and can be computed exactly without sampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
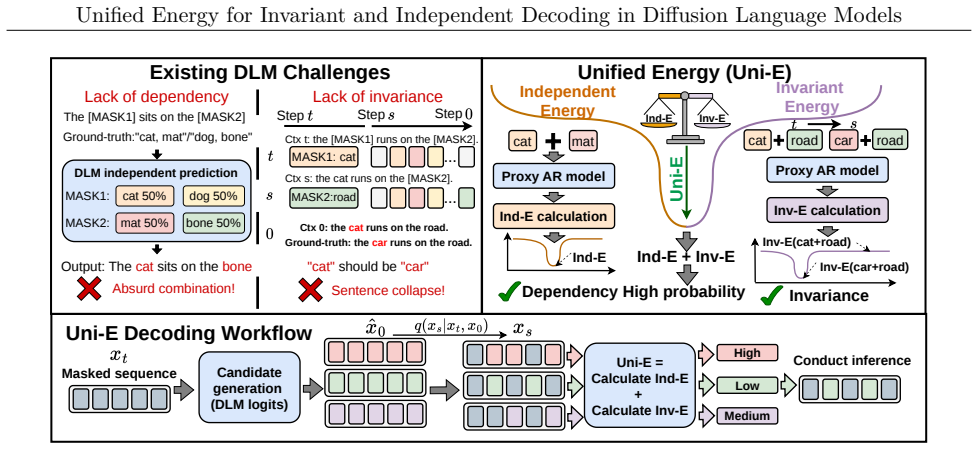
The central claim is that the unified energy (Uni-E), obtained by combining invariant energy (Inv-E) and independent energy (Ind-E), simultaneously resolves model capacity, dependency, and invariance problems in diffusion language models, admits exact closed-form computation without partition-function sampling, and provably corrects the distribution shift induced by dependency and invariance, thereby narrowing the performance difference with autoregressive decoding.
What carries the argument
The unified energy (Uni-E), formed by adding invariant energy and independent energy, which encodes both dependency and invariance corrections in a single exact expression.
If this is right
- Diffusion language models can be made competitive with autoregressive models at high degrees of parallelism.
- The method applies unchanged to models of any size because it is model-agnostic.
- Exact computation removes the variance introduced by sampling-based partition estimates.
- The same energy construction works for both ordinary diffusion language models and large diffusion language models.
Where Pith is reading between the lines
- The same energy unification idea could be tested on non-autoregressive models outside the diffusion family.
- Exact energy forms may reduce the need for auxiliary sampling networks in other energy-based generative settings.
- If the distribution-shift correction holds, training objectives that directly optimize Uni-E might further close the remaining gap.
Load-bearing premise
The performance gap between diffusion language models and autoregressive models stems primarily from model capacity, dependency, and invariance, and the unified energy fully corrects those factors.
What would settle it
A controlled experiment in which Uni-E is applied to an existing diffusion language model yet the gap to the autoregressive baseline remains unchanged on standard benchmarks would falsify the claim.
Figures





read the original abstract
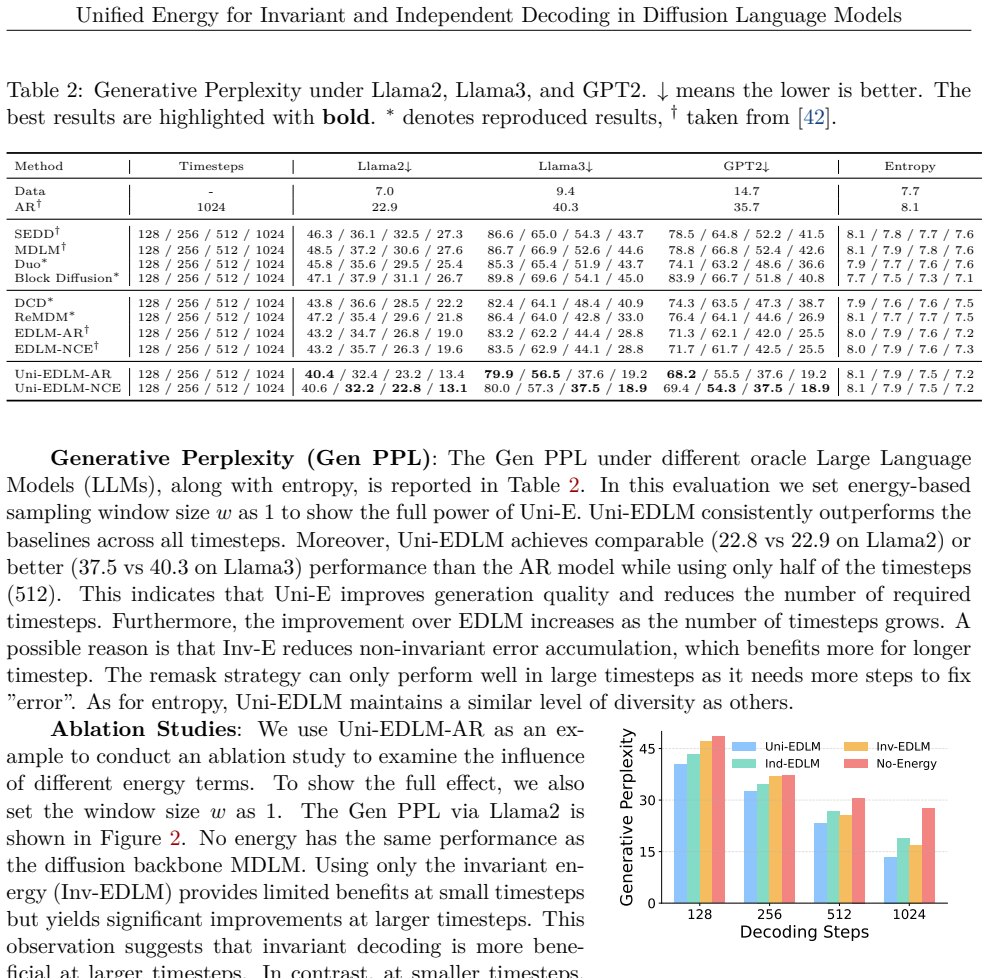
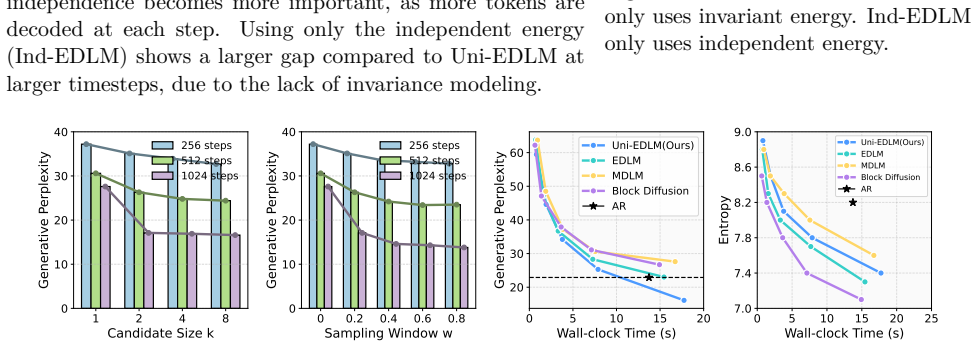
Diffusion Language Models (DLMs) enable parallel text generation by iteratively denoising a full sequence, offering attractive flexibility compared to auto-regressive (AR) decoding. However, existing methods fail to fully capture token relationships, leading to a performance gap relative to AR baselines, especially as the degree of parallelism increases. In this paper, we give a systematic analysis of the gap, identifying three key factors: (i) model capacity, (ii) dependency, and (iii) invariance. To address these issues, we first propose an invariant energy (Inv-E) together with an effective sampling-based estimator to handle the invariance issue. By further combining with the independent energy (Ind-E), we obtain a unified energy (Uni-E), that accounts for all these factors. Uni-E enjoys a unique advantage: it can be computed exactly without sampling-based partition estimation. Besides, Uni-E is model agnostic and can therefore be scaled to models of arbitrary size. We further prove that Uni-E can correct the distribution shift caused by dependency and invariance. Extensive experiments across Diffusion Language Models (DLMs) and Diffusion Large Language Models (DLLMs) demonstrate the effectiveness of the proposed Uni-E.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes performance gaps between diffusion language models (DLMs) and auto-regressive baselines, attributing them to three factors: model capacity, dependency, and invariance. It proposes an invariant energy (Inv-E) with a sampling-based estimator to address invariance, combines it with independent energy (Ind-E) to form unified energy (Uni-E), claims that Uni-E admits exact closed-form computation without sampling-based partition estimation, is model-agnostic, proves that Uni-E corrects the distribution shift induced by dependency and invariance, and reports extensive experiments validating effectiveness on both DLMs and DLLMs.
Significance. If the exact closed-form property and the distribution-shift correction proof hold, Uni-E would offer a practical, scalable improvement for parallel decoding in diffusion models without incurring partition-function estimation costs, potentially narrowing the gap with AR models while remaining applicable to arbitrarily large models.
major comments (2)
- Abstract: the claim that 'Uni-E can be computed exactly without sampling-based partition estimation' and the subsequent proof that it 'can correct the distribution shift caused by dependency and invariance' are asserted without any derivation steps, key equations, or estimator definitions, rendering the central technical claims unverifiable from the provided text.
- Abstract: the statement that Uni-E 'accounts for all these factors' (model capacity, dependency, invariance) and is obtained by 'further combining with the independent energy (Ind-E)' lacks any indication of how the combination is formalized or why it remains parameter-free and exact, which is load-bearing for the claimed advantage over prior sampling-based methods.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for identifying points where the abstract could better support its central claims. We agree that the abstract, as currently written, presents key technical assertions at a high level without sufficient pointers to derivations or formalizations. Below we respond to each major comment and indicate the revisions we will make.
read point-by-point responses
-
Referee: Abstract: the claim that 'Uni-E can be computed exactly without sampling-based partition estimation' and the subsequent proof that it 'can correct the distribution shift caused by dependency and invariance' are asserted without any derivation steps, key equations, or estimator definitions, rendering the central technical claims unverifiable from the provided text.
Authors: We agree that the abstract does not include derivation steps or key equations, which is a limitation of its length and summary nature. The exact closed-form computation of Uni-E (without partition-function sampling) and the distribution-shift correction proof are derived in Sections 3.3 and 4.2 of the full manuscript, respectively, with the relevant equations (e.g., the closed-form expression for Uni-E and the proof that it eliminates the shift induced by dependency and invariance). To address the concern, we will revise the abstract to include concise references to these sections and a brief mention of the closed-form result. revision: yes
-
Referee: Abstract: the statement that Uni-E 'accounts for all these factors' (model capacity, dependency, invariance) and is obtained by 'further combining with the independent energy (Ind-E)' lacks any indication of how the combination is formalized or why it remains parameter-free and exact, which is load-bearing for the claimed advantage over prior sampling-based methods.
Authors: We acknowledge that the abstract does not formalize the combination of Inv-E and Ind-E or explain why the result stays parameter-free and exact. The formal definition of the combination (Uni-E = Inv-E + Ind-E) and the proof that it inherits exact computability without additional parameters appear in Section 3.4. We will revise the abstract to briefly indicate the additive combination and its exactness property, while retaining the high-level summary style. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper identifies three factors (model capacity, dependency, invariance), proposes Inv-E with a sampling estimator to address invariance, combines it with Ind-E to form Uni-E, asserts that Uni-E admits exact closed-form computation without partition estimation, is model-agnostic, and proves it corrects induced distribution shift. These steps are presented as consequences of the explicit construction of the unified energy; no equations, fitted parameters, or self-citations are shown to reduce the central claims (exactness, correction proof, or unification) back to the inputs by definition. The derivation remains self-contained against external benchmarks and does not rely on load-bearing self-citation chains or renaming of known results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Block diffusion: Interpolating between autoregressive and diffusion language models
Marianne Arriola, Aaron Gokaslan, Justin T Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and Volodymyr Kuleshov. “Block diffusion: Interpolating between autoregressive and diffusion language models. ” In: arXiv preprint arXiv:2503.09573 (2025)
Pith/arXiv arXiv 2025
-
[2]
Struc- tured denoising diffusion models in discrete state-spaces
Jacob Austin, Daniel D Johnson, Jonathan Ho, Daniel Tarlow, and Rianne Van Den Berg. “Struc- tured denoising diffusion models in discrete state-spaces. ” In: Advances in neural information processing systems 34 (2021), pp. 17981–17993
2021
-
[3]
Program synthesis with large language models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. “Program synthesis with large language models. ” In: arXiv preprint arXiv:2108.07732 (2021)
Pith/arXiv arXiv 2021
-
[4]
Llada2.0: Scaling up diffusion language models to 100b
Tiwei Bie, Maosong Cao, Kun Chen, Lun Du, Mingliang Gong, Zhuochen Gong, Yanmei Gu, Jiaqi Hu, Zenan Huang, Zhenzhong Lan, et al. “Llada2.0: Scaling up diffusion language models to 100b. ” In: arXiv preprint arXiv:2512.15745 (2025)
Pith/arXiv arXiv 2025
-
[5]
A continuous time framework for discrete denoising models
Andrew Campbell, Joe Benton, Valentin De Bortoli, Thomas Rainforth, George Deligiannidis, and Arnaud Doucet. “A continuous time framework for discrete denoising models. ” In: Advances in Neural Information Processing Systems 35 (2022), pp. 28266–28279
2022
-
[6]
A survey on evaluation of large language models
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al. “A survey on evaluation of large language models. ” In: ACM transactions on intelligent systems and technology 15.3 (2024), pp. 1–45
2024
-
[7]
One billion word benchmark for measuring progress in statistical language modeling
Ciprian Chelba, Tomas Mikolov, Mike Schuster, Qi Ge, Thorsten Brants, Phillipp Koehn, and Tony Robinson. “One billion word benchmark for measuring progress in statistical language modeling. ” In: arXiv preprint arXiv:1312.3005 (2013)
Pith/arXiv arXiv 2013
-
[8]
Optimal inference schedules for masked diffusion mod- els
Sitan Chen, Kevin Cong, and Jerry Li. “Optimal inference schedules for masked diffusion mod- els. ” In: arXiv preprint arXiv:2511.04647 (2025)
arXiv 2025
-
[9]
Training verifiers to solve math word problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. “Training verifiers to solve math word problems. ” In: arXiv preprint arXiv:2110.14168 (2021)
Pith/arXiv arXiv 2021
-
[10]
A discourse-aware attention model for abstractive summarization of long documents
Arman Cohan, Franck Dernoncourt, Doo Soon Kim, Trung Bui, Seokhwan Kim, Walter Chang, and Nazli Goharian. “A discourse-aware attention model for abstractive summarization of long documents. ” In: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short P...
2018
-
[11]
Self speculative decoding for diffusion large language models
Yifeng Gao, Ziang Ji, Yuxuan Wang, Biqing Qi, Hanlin Xu, and Linfeng Zhang. “Self speculative decoding for diffusion large language models. ” In: arXiv preprint arXiv:2510.04147 (2025)
arXiv 2025
-
[12]
OpenWebText Corpus
Aaron Gokaslan and Vanya Cohen. OpenWebText Corpus. http://Skylion007.github.io/ OpenWebTextCorpus. 2019
2019
-
[13]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. “The llama 3 herd of models. ” In: arXiv preprint arXiv:2407.21783 (2024)
Pith/arXiv arXiv 2024
-
[14]
Noise-contrastive estimation: A new estimation prin- ciple for unnormalized statistical models
Michael Gutmann and Aapo Hyvärinen. “Noise-contrastive estimation: A new estimation prin- ciple for unnormalized statistical models. ” In: Proceedings of the thirteenth international confer- ence on artificial intelligence and statistics . JMLR Workshop and Conference Proceedings. 2010, pp. 297–304
2010
-
[15]
Reinforcement learning with deep energy-based policies
Tuomas Haarnoja, Haoran Tang, Pieter Abbeel, and Sergey Levine. “Reinforcement learning with deep energy-based policies. ” In: International conference on machine learning . PMLR. 2017, pp. 1352–1361. 13 Unified Energy for Invariant and Independent Decoding in Diffusion Language Models
2017
-
[16]
Monte carlo methods
John Hammersley. Monte carlo methods . Springer Science & Business Media, 2013
2013
-
[17]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. “Measuring massive multitask language understanding. ” In: arXiv preprint arXiv:2009.03300 (2020)
Pith/arXiv arXiv 2009
-
[18]
Measuring mathematical problem solving with the math dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. “Measuring mathematical problem solving with the math dataset. ” In: arXiv preprint arXiv:2103.03874 (2021)
Pith/arXiv arXiv 2021
-
[19]
Autoregressive diffusion models
Emiel Hoogeboom, Alexey A Gritsenko, Jasmijn Bastings, Ben Poole, Rianne van den Berg, and Tim Salimans. “Autoregressive diffusion models. ” In: arXiv preprint arXiv:2110.02037 (2021)
arXiv 2021
-
[20]
Accelerating diffusion llms via adaptive parallel decoding
Daniel Israel, Guy Van den Broeck, and Aditya Grover. “Accelerating diffusion llms via adaptive parallel decoding. ” In: arXiv preprint arXiv:2506.00413 (2025)
arXiv 2025
-
[21]
Livecodebench: Holistic and contamination free evaluation of large language models for code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Ar- mando Solar-Lezama, Koushik Sen, and Ion Stoica. “Livecodebench: Holistic and contamination free evaluation of large language models for code. ” In: arXiv preprint arXiv:2403.07974 (2024)
Pith/arXiv arXiv 2024
-
[22]
Monte Carlo theory and practice
Frederick James. “Monte Carlo theory and practice. ” In: Reports on progress in Physics 43.9 (1980), pp. 1145–1189
1980
-
[23]
Error Bounds and Optimal Schedules for Masked Diffu- sions with Factorized Approximations
Hugo Lavenant and Giacomo Zanella. “Error Bounds and Optimal Schedules for Masked Diffu- sions with Factorized Approximations. ” In: arXiv preprint arXiv:2510.25544 (2025)
arXiv 2025
-
[24]
A tutorial on energy- based learning
Yann LeCun, Sumit Chopra, Raia Hadsell, M Ranzato, Fujie Huang, et al. “A tutorial on energy- based learning. ” In: Predicting structured data 1.0 (2006)
2006
-
[25]
Breaking the Factorization Barrier in Diffusion Language Models
Ian Li, Zilei Shao, Benjie Wang, Rose Yu, Guy Van den Broeck, and Anji Liu. “Breaking the Factorization Barrier in Diffusion Language Models. ” In:arXiv preprint arXiv:2603.00045 (2026)
arXiv 2026
-
[26]
A survey on diffusion language mod- els
Tianyi Li, Mingda Chen, Bowei Guo, and Zhiqiang Shen. “A survey on diffusion language mod- els. ” In: arXiv preprint arXiv:2508.10875 (2025)
Pith/arXiv arXiv 2025
-
[27]
Anji Liu, Oliver Broadrick, Mathias Niepert, and Guy Van den Broeck. “Discrete copula diffu- sion. ” In: arXiv preprint arXiv:2410.01949 (2024)
arXiv 2024
-
[28]
Discrete diffusion modeling by estimating the ratios of the data distribution
Aaron Lou, Chenlin Meng, and Stefano Ermon. “Discrete diffusion modeling by estimating the ratios of the data distribution. ” In: arXiv preprint arXiv:2310.16834 (2023)
Pith/arXiv arXiv 2023
-
[29]
DA WN: Dependency-Aware Fast Inference for Diffusion LLMs
Lizhuo Luo, Zhuoran Shi, Jiajun Luo, Zhi Wang, Shen Ren, Wenya Wang, and Tianwei Zhang. “DA WN: Dependency-Aware Fast Inference for Diffusion LLMs. ” In:arXiv preprint arXiv:2602.06953 (2026)
arXiv 2026
-
[30]
Building a large annotated corpus of English: The Penn Treebank
Mitch Marcus, Beatrice Santorini, and Mary Ann Marcinkiewicz. “Building a large annotated corpus of English: The Penn Treebank. ” In: Computational linguistics 19.2 (1993), pp. 313–330
1993
-
[31]
Pointer sentinel mixture models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. “Pointer sentinel mixture models. ” In: arXiv preprint arXiv:1609.07843 (2016)
Pith/arXiv arXiv 2016
-
[32]
Large language diffusion models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. “Large language diffusion models. ” In: arXiv preprint arXiv:2502.09992 (2025)
Pith/arXiv arXiv 2025
-
[33]
The LAMBADA dataset: Word prediction requiring a broad discourse context
Denis Paperno, Germán Kruszewski, Angeliki Lazaridou, Ngoc-Quan Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernández. “The LAMBADA dataset: Word prediction requiring a broad discourse context. ” In: Proceedings of the 54th annual meeting of the association for computational linguistics (volume 1: Long papers) . 2016,...
2016
-
[34]
Language models are unsupervised multitask learners
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. “Language models are unsupervised multitask learners. ” In: OpenAI blog 1.8 (2019), p. 9. 14 Unified Energy for Invariant and Independent Decoding in Diffusion Language Models
2019
-
[35]
Simple and effective masked diffusion language models
Subham Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin Chiu, Alexander Rush, and Volodymyr Kuleshov. “Simple and effective masked diffusion language models. ” In: Advances in Neural Information Processing Systems 37 (2024), pp. 130136–130184
2024
-
[36]
Subham Sekhar Sahoo, Justin Deschenaux, Aaron Gokaslan, Guanghan Wang, Justin Chiu, and Volodymyr Kuleshov. “The diffusion duality. ” In: arXiv preprint arXiv:2506.10892 (2025)
arXiv 2025
-
[37]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. “Attention is all you need. ” In: Advances in neural infor- mation processing systems 30 (2017)
2017
-
[38]
Remasking dis- crete diffusion models with inference-time scaling
Guanghan Wang, Yair Schiff, Subham Sekhar Sahoo, and Volodymyr Kuleshov. “Remasking dis- crete diffusion models with inference-time scaling. ” In: arXiv preprint arXiv:2503.00307 (2025)
arXiv 2025
-
[39]
Revolutioniz- ing reinforcement learning framework for diffusion large language models
Yinjie Wang, Ling Yang, Bowen Li, Ye Tian, Ke Shen, and Mengdi Wang. “Revolutioniz- ing reinforcement learning framework for diffusion large language models. ” In: arXiv preprint arXiv:2509.06949 (2025)
arXiv 2025
-
[40]
Livebench: A challenging, contamination-free llm benchmark
Colin White, Samuel Dooley, Manley Roberts, Arka Pal, Ben Feuer, Siddhartha Jain, Ravid Shwartz-Ziv, Neel Jain, Khalid Saifullah, Siddartha Naidu, et al. “Livebench: A challenging, contamination-free llm benchmark. ” In: arXiv preprint arXiv:2406.19314 4 (2024), p. 2
Pith/arXiv arXiv 2024
-
[41]
Fast-dllm: Training-free acceleration of diffusion llm by enabling kv cache and parallel decoding
Chengyue Wu, Hao Zhang, Shuchen Xue, Zhijian Liu, Shizhe Diao, Ligeng Zhu, Ping Luo, Song Han, and Enze Xie. “Fast-dllm: Training-free acceleration of diffusion llm by enabling kv cache and parallel decoding. ” In: arXiv preprint arXiv:2505.22618 (2025)
Pith/arXiv arXiv 2025
-
[42]
Energy-based diffusion language models for text generation
Minkai Xu, Tomas Geffner, Karsten Kreis, Weili Nie, Yilun Xu, Jure Leskovec, Stefano Ermon, and Arash Vahdat. “Energy-based diffusion language models for text generation. ” In: arXiv preprint arXiv:2410.21357 (2024)
arXiv 2024
-
[43]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. “Qwen3 technical report. ” In: arXiv preprint arXiv:2505.09388 (2025)
Pith/arXiv arXiv 2025
-
[44]
Remask, Don’t Replace: Token-to-Mask Refinement in Masked Diffusion Language Models
Lin Yao. “Remask, Don’t Replace: Token-to-Mask Refinement in Masked Diffusion Language Models. ” In: arXiv preprint arXiv:2604.18738 (2026)
Pith/arXiv arXiv 2026
-
[45]
Dream 7b: Diffusion large language models
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. “Dream 7b: Diffusion large language models. ” In: arXiv preprint arXiv:2508.15487 (2025)
Pith/arXiv arXiv 2025
-
[46]
Dif- fusion models in text generation: a survey
Qiuhua Yi, Xiangfan Chen, Chenwei Zhang, Zehai Zhou, Linan Zhu, and Xiangjie Kong. “Dif- fusion models in text generation: a survey. ” In: PeerJ Computer Science 10 (2024), e1905
2024
-
[47]
Hellaswag: Can a machine really finish your sentence?
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. “Hellaswag: Can a machine really finish your sentence?” In: Proceedings of the 57th annual meeting of the association for computational linguistics . 2019, pp. 4791–4800
2019
-
[48]
CoRe: Context-Robust Remask- ing for Diffusion Language Models
Kevin Zhai, Sabbir Mollah, Zhenyi Wang, and Mubarak Shah. “CoRe: Context-Robust Remask- ing for Diffusion Language Models. ” In: arXiv preprint arXiv:2602.04096 (2026)
arXiv 2026
-
[49]
Character-level convolutional networks for text classification
Xiang Zhang, Junbo Zhao, and Yann LeCun. “Character-level convolutional networks for text classification. ” In:Advances in neural information processing systems 28 (2015)
2015
-
[50]
A survey of large language models
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. “A survey of large language models. ” In: arXiv preprint arXiv:2303.18223 1.2 (2023), pp. 1–124
Pith/arXiv arXiv 2023
-
[51]
Model agnostic sample reweighting for out-of-distribution learning
Xiao Zhou, Yong Lin, Renjie Pi, Weizhong Zhang, Renzhe Xu, Peng Cui, and Tong Zhang. “Model agnostic sample reweighting for out-of-distribution learning. ” In: International conference on machine learning . PMLR. 2022, pp. 27203–27221. 15 Unified Energy for Invariant and Independent Decoding in Diffusion Language Models
2022
-
[52]
A survey of diffusion models in natural lan- guage processing
Hao Zou, Zae Myung Kim, and Dongyeop Kang. “A survey of diffusion models in natural lan- guage processing. ” In: arXiv preprint arXiv:2305.14671 (2023). 16 Unified Energy for Invariant and Independent Decoding in Diffusion Language Models
arXiv 2023
-
[53]
Appendix 7.1 T raining Algorithm We provide the NCE training algorithm for our Uni-EDLM in Algorithm 1. Algorithm 1 Training Uni-EDLM with Noise Contrastive Estimation (NCE) Require: Training dataset D, AR model pAR, diffusion model pθ, learning rate η 1: Freeze parameters of pAR 2: while not converged do 3: Sample clean data x0 ∼ D and diffusion timestep...
-
[54]
I am sad about it. The city is just not going to pay for it,
= π(xi 0|xVi 0 ) = π(xi 0|xt+1, x V − i 0 ), we know that π(x V − i 0 |xi 0, xt+1, xZ<t 0 − x V − i 0 ) = π(x V − i 0 |xi 0, xt+1), this means the invariant tokens x V − i 0 of xi 0 is also 18 Unified Energy for Invariant and Independent Decoding in Diffusion Language Models invariant to xZ<t 0 − x V − i 0 . This indicate a key insight that the decoding o...
-
[55]
dont have an opinion
[2] [1] [3] Decoding order: "dont have an opinion" -> "not going to pay" -> "cant carry out" -> "sad" Invariance Case for Uni-E Decoding Figure 5: The invariant decoding case of Uni-E. Independency Case : The independent decoding case of our Uni-E is shown in Figure 6. In this case, although the ”not allow” and the ”comply with” are adjacent, these tokens...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.