N\"ushuVoice: Reviving the Voice of Endangered N\"ushu with Pitch-Aware Text-to-Speech
Pith reviewed 2026-06-27 16:38 UTC · model grok-4.3
The pith
Nüshu-PitchVITS conditions a VITS model on five-level pitch notation to synthesize speech from scarce archival recordings of the endangered script.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
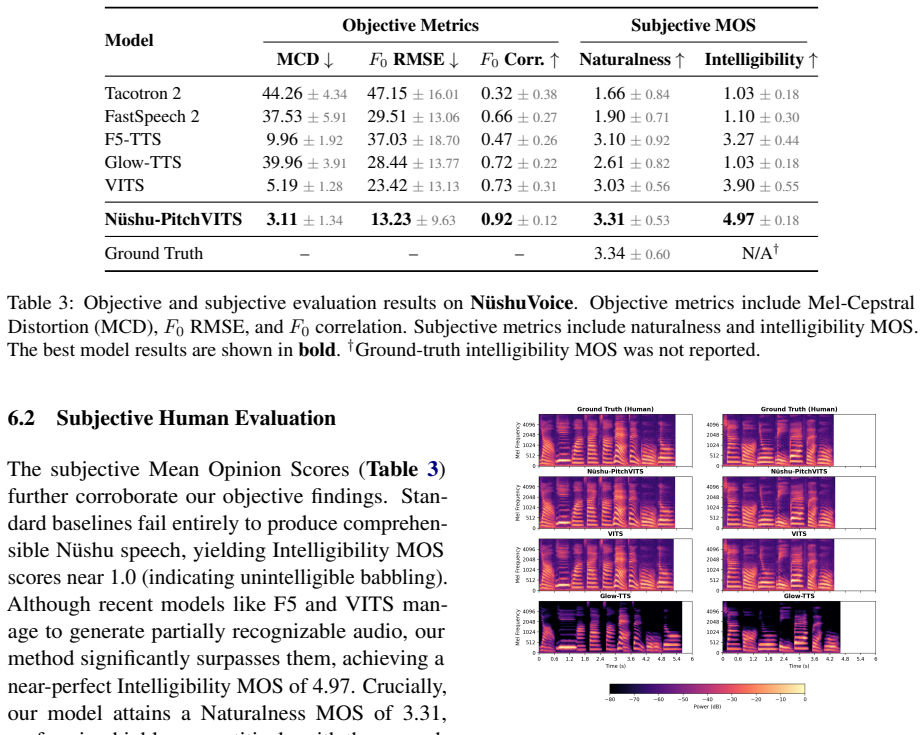
Nüshu-PitchVITS, an F0-conditioned VITS framework that leverages Nüshu's five-level pitch notation as an explicit prosodic inductive bias, outperforms strong TTS baselines in spectral fidelity, pitch reconstruction, and human-rated intelligibility.
What carries the argument
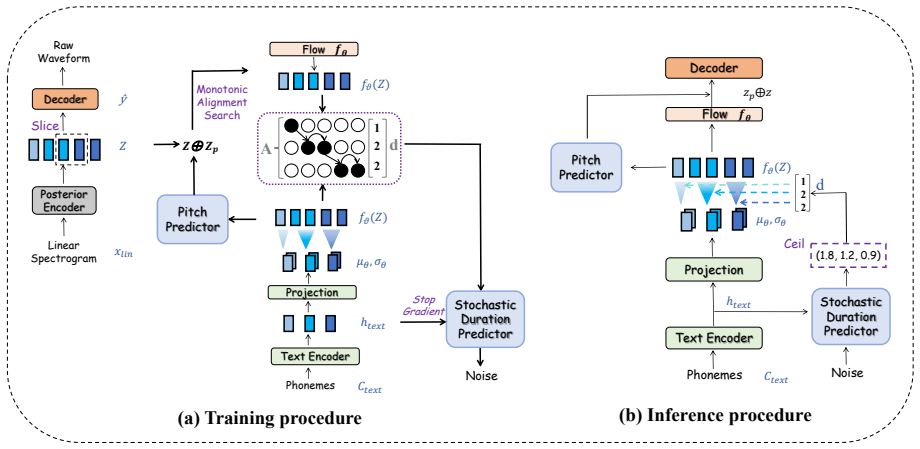
Nüshu-PitchVITS: an F0-conditioned VITS model that incorporates the five-level pitch notation extracted from Nüshu as an explicit prosodic bias to guide synthesis when sentence-level data is scarce.
If this is right
- The pitch-conditioned model produces higher-fidelity audio than unconditioned baselines under the same data constraints.
- The released sentence-level dataset of aligned Nüshu text and recordings supports further low-resource TTS experiments.
- Explicit use of the five-level pitch marks compensates for the absence of natural sentence-level utterances in the archives.
- Human-rated intelligibility improves, indicating the synthesized speech better preserves usable pronunciation.
Where Pith is reading between the lines
- The same explicit pitch-bias approach might transfer to other tonal scripts or languages where archival data consists mainly of isolated syllables.
- Future work could test whether the five-level notation generalizes to unseen Nüshu sentences without additional alignment effort.
- If more recordings become available, the model could be fine-tuned to produce longer, more varied prosody while retaining the pitch prior.
Load-bearing premise
The five-level pitch notation extracted from Nüshu can be aligned reliably with the limited archival recordings and functions as an effective explicit prosodic inductive bias inside the VITS architecture.
What would settle it
An ablation experiment or listening test in which removing the pitch conditioning produces no measurable drop in spectral or intelligibility metrics on the Nüshu test set would falsify the utility of the bias.
Figures

read the original abstract
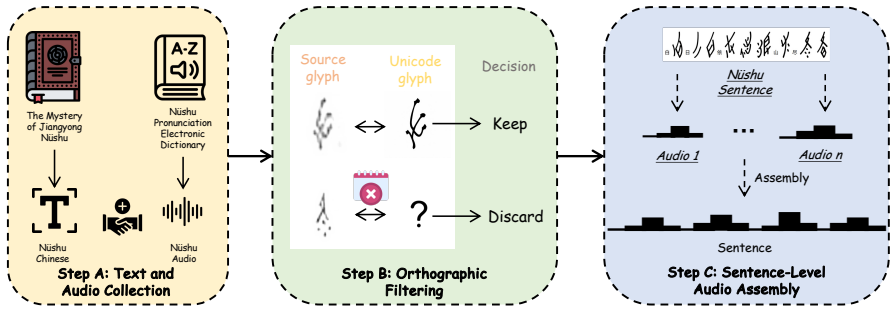
N\"ushu is an endangered phonetic script historically used by women in Jiangyong County, southern Hunan, China. While existing computational studies of N\"ushu mainly focus on textual digitization and visual recognition, the acoustic reconstruction of its authentic pronunciation remains largely unexplored. Building a N\"ushu text-to-speech (TTS) system is particularly challenging because available recordings are extremely limited and mostly consist of isolated syllable-level pronunciations rather than natural sentence-level utterances. In this work, we introduce N\"ushuVoice, the first TTS benchmark for N\"ushu. We construct a sentence-level N\"ushu text-to-audio dataset that aligns standardized Unicode N\"ushu text, phonetic transcriptions, standard Chinese translations, and archival recordings. To synthesize speech under this extreme low-resource setting, we propose N\"ushu-PitchVITS, an F0-conditioned VITS framework that leverages N\"ushu's five-level pitch notation as an explicit prosodic inductive bias. Experimental results show that N\"ushu-PitchVITS outperforms strong TTS baselines in spectral fidelity, pitch reconstruction, and human-rated intelligibility. We publicly release the dataset and code at: https://anonymous.4open.science/r/Nvshu-TTS-2EB6.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NüshuVoice as the first TTS benchmark for the endangered Nüshu script. It constructs a sentence-level dataset aligning standardized Unicode Nüshu text, phonetic transcriptions, Chinese translations, and limited archival recordings (mostly isolated syllables). It proposes Nüshu-PitchVITS, an F0-conditioned VITS model that incorporates Nüshu's five-level pitch notation as an explicit prosodic inductive bias, and claims this outperforms strong TTS baselines in spectral fidelity, pitch reconstruction, and human-rated intelligibility. The dataset and code are released publicly.
Significance. If the results hold, this would be a meaningful contribution to endangered language preservation by enabling acoustic reconstruction of Nüshu pronunciation, where prior work focused only on textual aspects. The explicit use of domain-specific pitch notation as inductive bias in extreme low-resource TTS is a potentially generalizable idea, and the public release of the dataset and code supports reproducibility and follow-on work.
major comments (2)
- [Abstract] Abstract and experimental results section: the central claim of outperformance in spectral fidelity, pitch reconstruction, and intelligibility is stated without any numerical metrics, baseline identities, data-split details, or statistical tests, so the strength of evidence cannot be assessed from the provided text.
- [Dataset construction] Dataset construction section: the five-level pitch notation alignment with limited archival recordings (mostly isolated syllable pronunciations) is load-bearing for the claim that the F0 conditioning delivers genuine prosodic gains; without explicit details on extraction, alignment procedure, validation against recordings, or error rates, it is unclear whether misalignment or noise in the pitch-to-F0 mapping undermines the inductive bias.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential contribution to endangered language preservation. We address each major comment below and will revise the manuscript to improve clarity and evidence presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental results section: the central claim of outperformance in spectral fidelity, pitch reconstruction, and intelligibility is stated without any numerical metrics, baseline identities, data-split details, or statistical tests, so the strength of evidence cannot be assessed from the provided text.
Authors: We agree that the abstract would be strengthened by including key quantitative results. In the revised version we will update the abstract to report specific metrics (e.g., MCD, F0 RMSE, and intelligibility MOS scores), name the baselines, briefly describe the train/test splits, and note any statistical tests performed. The experimental results section already contains these details; the revision will ensure they are summarized concisely in the abstract as well. revision: yes
-
Referee: [Dataset construction] Dataset construction section: the five-level pitch notation alignment with limited archival recordings (mostly isolated syllable pronunciations) is load-bearing for the claim that the F0 conditioning delivers genuine prosodic gains; without explicit details on extraction, alignment procedure, validation against recordings, or error rates, it is unclear whether misalignment or noise in the pitch-to-F0 mapping undermines the inductive bias.
Authors: We acknowledge that additional explicit details on the pitch alignment process would help readers evaluate the reliability of the inductive bias. The manuscript describes the use of the five-level notation and its alignment to the archival recordings, but we will expand the dataset construction section to specify the F0 extraction method, the precise alignment procedure between pitch levels and recorded contours, the validation steps taken against the available syllable recordings, and any observed error rates or quality controls. This will clarify that the mapping supports the reported prosodic gains. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper's central claim is an empirical result: Nüshu-PitchVITS outperforms baselines in spectral fidelity, pitch reconstruction, and intelligibility when using Nüshu's historical five-level pitch notation as an explicit conditioning signal inside VITS. This conditioning draws on external domain knowledge of the script rather than any quantity fitted or defined from the target evaluation metrics. No equations, predictions, or uniqueness claims reduce to self-defined inputs, fitted parameters renamed as outputs, or self-citation chains. The dataset construction and model architecture are presented as independent engineering steps whose effectiveness is tested against external baselines.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VITS architecture remains stable and effective when conditioned on discrete pitch levels under extreme data scarcity
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Proceedings of IEEE pacific rim conference on communications computers and signal processing , volume=
Mel-cepstral distance measure for objective speech quality assessment , author=. Proceedings of IEEE pacific rim conference on communications computers and signal processing , volume=. 1993 , organization=
1993
-
[9]
1996 , publisher=
Methods for subjective determination of transmission quality , author=. 1996 , publisher=
1996
-
[10]
International conference on machine learning , pages=
Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[11]
Introduction: Cultures of authenticity , author=
-
[12]
Sun, Yuqian and Tang, Yuying and Gao, Ze and Pan, Zhijun and Xu, Chuyan and Chen, Yurou and Qian, Kejiang and Wang, Zhigang and Braud, Tristan and Lee, Chang Hee and others , booktitle=. AI N
-
[13]
arXiv preprint arXiv:2412.00218 , year=
NushuRescue: Revitalization of the Endangered Nushu Language with AI , author=. arXiv preprint arXiv:2412.00218 , year=
-
[14]
Recontextualizing revitalization: A mixed media approach to reviving the n
Yang, Ivory and Guo, Xiaobo and Wang, Yuxin and Zhang, Hefan and Jia, Yaning and Dinauer, William and Vosoughi, Soroush , booktitle=. Recontextualizing revitalization: A mixed media approach to reviving the n
-
[15]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
F5-tts: A fairytaler that fakes fluent and faithful speech with flow matching , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[16]
arXiv preprint arXiv:2006.04558 , year=
Fastspeech 2: Fast and high-quality end-to-end text to speech , author=. arXiv preprint arXiv:2006.04558 , year=
arXiv 2006
-
[17]
Advances in Neural Information Processing Systems , volume=
Glow-tts: A generative flow for text-to-speech via monotonic alignment search , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
Parameter-Efficient Fine-Tuning for Low-Resource Text-to-Speech via Cross-Lingual Continual Learning , author=. Proc. Interspeech , volume=
-
[19]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
BnTTS: Few-shot speaker adaptation in low-resource setting , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
2025
-
[20]
Advancing Women in Leadership Journal , volume=
The Movement from Secret Acts of Defiance to Manifestation of Women's Empowerment , author=. Advancing Women in Leadership Journal , volume=
-
[21]
1995 , publisher=
Nushu (Chinese women's script) literacy and literature , author=. 1995 , publisher=
1995
-
[22]
Nyushu character unification——theory and rules , author=
-
[23]
arXiv preprint arXiv:2004.03136 , year=
g2pm: A neural grapheme-to-phoneme conversion package for mandarin chinese based on a new open benchmark dataset , author=. arXiv preprint arXiv:2004.03136 , year=
arXiv 2004
-
[24]
2018 IEEE international conference on acoustics, speech and signal processing (ICASSP) , pages=
Natural tts synthesis by conditioning wavenet on mel spectrogram predictions , author=. 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP) , pages=. 2018 , organization=
2018
-
[25]
arXiv preprint arXiv:2106.15561 , year=
A survey on neural speech synthesis , author=. arXiv preprint arXiv:2106.15561 , year=
-
[26]
, author=
A Systematic Review and Analysis of Multilingual Data Strategies in Text-to-Speech for Low-Resource Languages. , author=. Interspeech , pages=
-
[27]
Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages=
Lrspeech: Extremely low-resource speech synthesis and recognition , author=. Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages=
-
[28]
ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Unsupervised Pre-Training for Data-Efficient Text-to-Speech on Low Resource Languages , author=. ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2023 , organization=
2023
-
[29]
2023 , eprint=
Unsupervised Pre-Training For Data-Efficient Text-to-Speech On Low Resource Languages , author=. 2023 , eprint=
2023
-
[30]
The Oxford handbook of Chinese linguistics , pages=
Wu dialect , author=. The Oxford handbook of Chinese linguistics , pages=. 2015 , publisher=
2015
-
[31]
2024 , school=
Jiangyong Nvshu in China: the Gender, Signifier, Signified, and Sustainable Inheritance Path of the Local Culture , author=. 2024 , school=
2024
-
[32]
History, Characteristics, and Modern Vitality of N
Congrong, Li , journal=. History, Characteristics, and Modern Vitality of N. 2024 , publisher=
2024
-
[33]
arXiv preprint arXiv:2402.08093 , year=
Base tts: Lessons from building a billion-parameter text-to-speech model on 100k hours of data , author=. arXiv preprint arXiv:2402.08093 , year=
-
[34]
International Conference on Multi-modal Information Analytics , pages=
Intangible Cultural Heritage Protection Based on MAR Algorithm , author=. International Conference on Multi-modal Information Analytics , pages=. 2022 , organization=
2022
-
[35]
Proceedings of the Eight Workshop on the Use of Computational Methods in the Study of Endangered Languages , pages=
Evaluating Indigenous language speech synthesis for education: A participatory design workshop on Ojibwe text-to-speech , author=. Proceedings of the Eight Workshop on the Use of Computational Methods in the Study of Endangered Languages , pages=
-
[36]
The world’s first South S
Hiovain-Asikainen, Katri and Kj. The world’s first South S. Proceedings of the 10th International Workshop on Computational Linguistics for Uralic Languages , pages=
-
[37]
Falcini, Giulia , journal=. N
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.