TRL-Bench: Standardizing Cross-Paradigm Representation-Level Evaluation of Tabular Encoders
Pith reviewed 2026-06-27 16:46 UTC · model grok-4.3
The pith
Standardizing downstream conditions reveals that tabular encoder quality is capability-specific rather than ranked by any single leaderboard.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
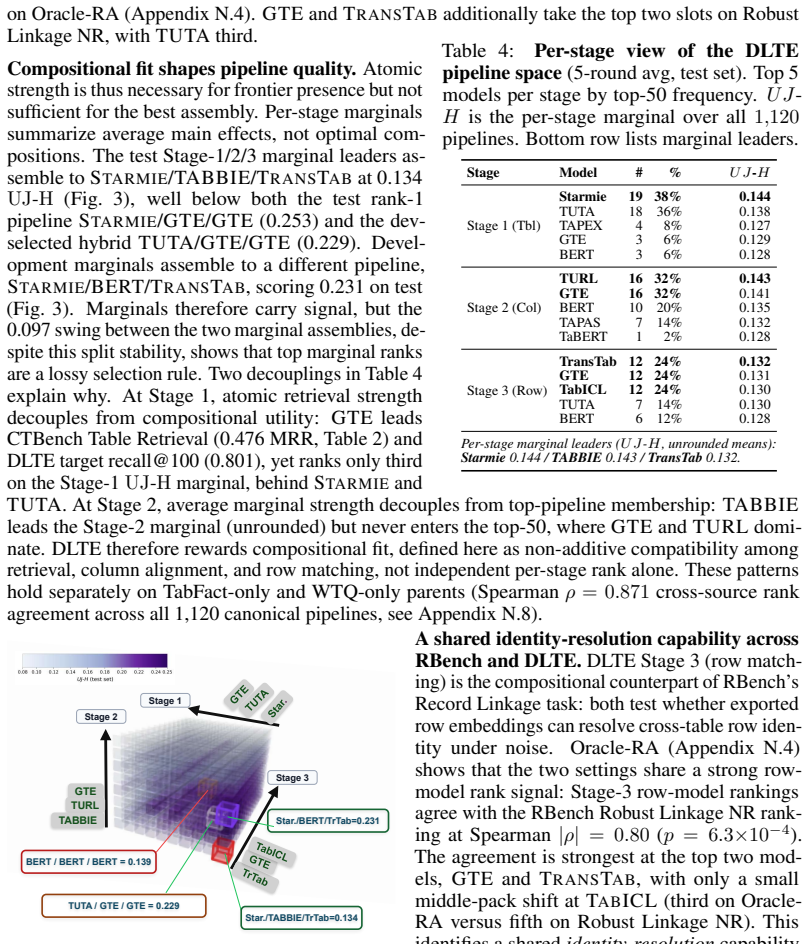
Once downstream conditions are standardized, encoder quality is capability-specific rather than captured by a single leaderboard. In column and table tasks generic text encoders often lead where surface-text signal is strong while tabular specialists win where their pretraining aligns with the task. Within-table prediction and cross-table linkage favor different regimes, and atomic linkage performance correlates with the row-matching stage of enrichment pipelines. Strongest pipelines combine capability-matched specialists rather than reuse one encoder, and end-to-end quality depends on non-additive compositional fit.
What carries the argument
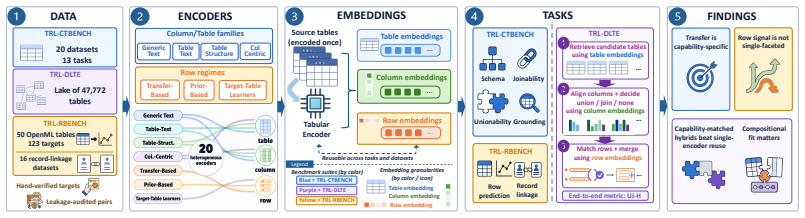
TRL-Bench, a multi-granular benchmark that standardizes export of row-, column-, or table embeddings and probes them with shared lightweight heads across TRL-CTbench, TRL-Rbench, and TRL-DLTE suites.
If this is right
- Generic text encoders lead on tasks with strong surface-text signal while tabular specialists win on aligned objectives.
- Within-table prediction and cross-table linkage favor different training regimes.
- Atomic linkage performance correlates strongly with the row-matching stage of DLTE pipelines.
- Top end-to-end quality depends on non-additive compositional fit rather than per-stage marginal rank.
Where Pith is reading between the lines
- Practitioners could select encoders by matching capability to task type instead of overall rank.
- Extending the benchmark with additional head architectures would test whether the capability-specific pattern persists.
- Similar standardization might reveal capability splits in other modalities such as graph or time-series encoders.
Load-bearing premise
The chosen lightweight heads, task reformulations, and wrapper interfaces do not systematically favor or disfavor particular training paradigms.
What would settle it
A single encoder ranking first across all three suites under the fixed protocol would falsify the claim that quality is capability-specific.
Figures
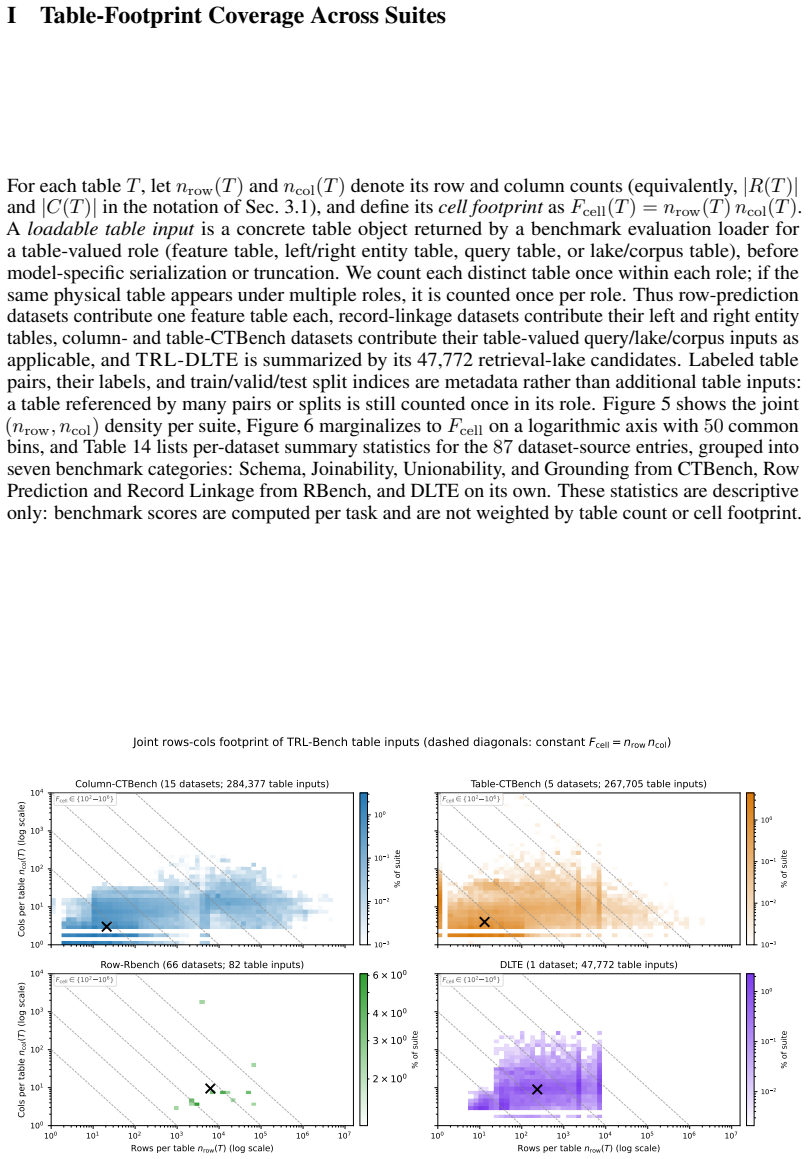
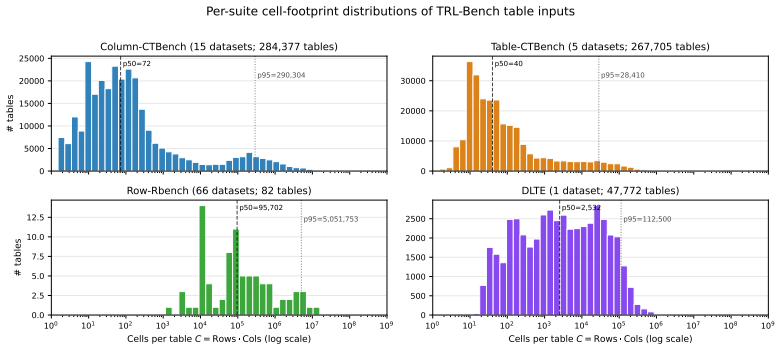
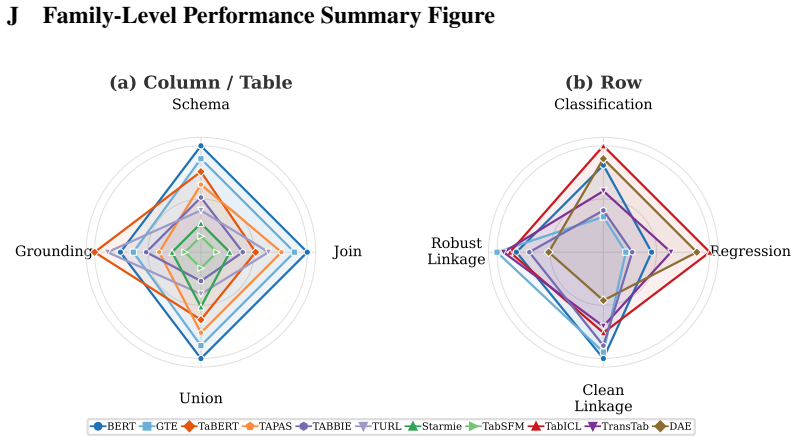
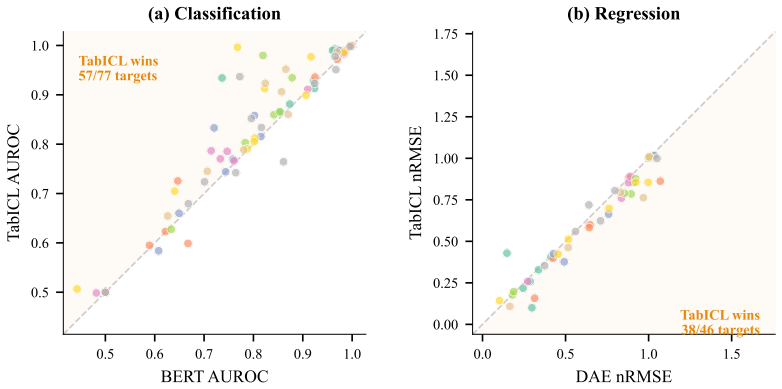



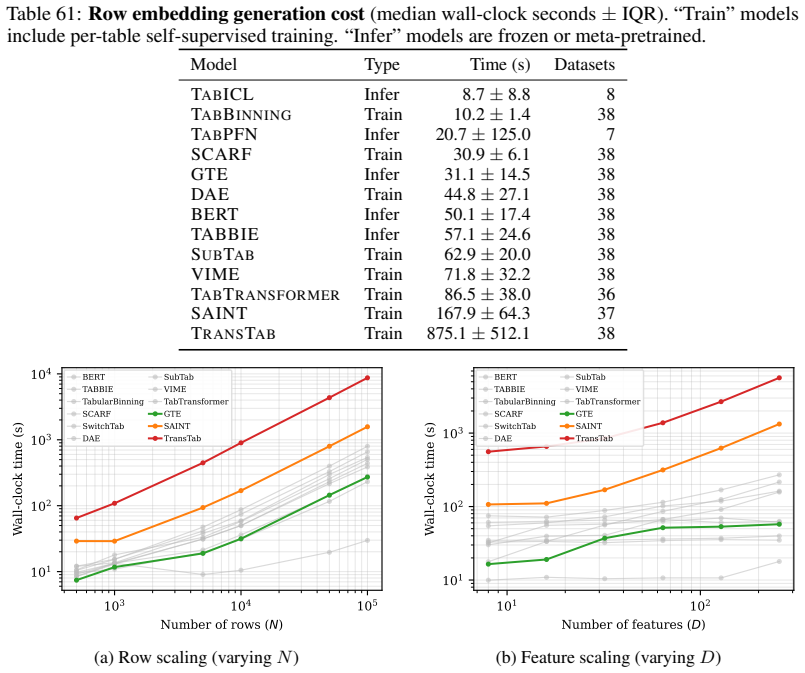
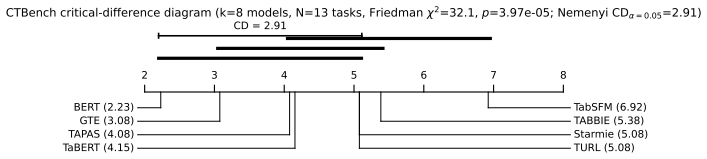
read the original abstract
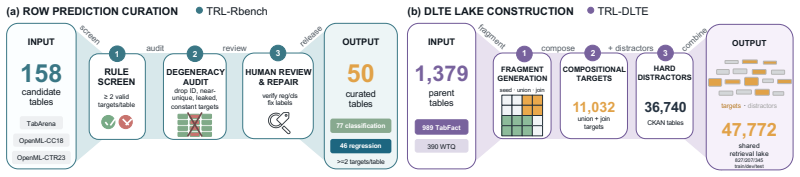
Tabular encoders are usually evaluated inside task-specific end-to-end pipelines, so models from different training paradigms are difficult to compare directly even when they operate on similar tabular signals. We introduce TRL-Bench, a multi-granular tabular representation learning (TRL) benchmark that standardizes cross-paradigm representation-level evaluation: each encoder exports row-, column-, or table embeddings through its supported wrapper, and shared lightweight heads probe them across three suites: TRL-CTbench (column/table), TRL-Rbench (row), and TRL-DLTE (compositional Data-Lake Table Enrichment spanning all three granularities). To support this standardized setting, we release curated benchmark assets and task reformulations, including 50 OpenML tables with 123 verified targets, 16 row-pair linkage rewrites, and a 47,772-table DLTE lake derived from 1,379 parent tables. Across 20 models and 16 tasks, TRL-Bench shows that once downstream conditions are standardized, encoder quality is capability-specific rather than captured by a single leaderboard. In TRL-CTbench, generic text encoders often lead on tasks with strong surface-text signal, while tabular specialists win where their pretraining objective aligns with the task. In TRL-Rbench, within-table prediction and cross-table linkage favor different training regimes, with atomic linkage performance correlating strongly with the row-matching stage of DLTE pipelines. In TRL-DLTE, the strongest pipelines combine capability-matched specialists rather than reuse a single encoder, and top end-to-end quality depends on non-additive compositional fit rather than per-stage marginal rank alone. TRL-Bench provides a common protocol for measuring reusable signal in exported tabular representations under shared downstream conditions. Code and data: https://github.com/LOGO-CUHKSZ/TRL-Bench
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TRL-Bench, a multi-granular benchmark for standardizing cross-paradigm representation-level evaluation of tabular encoders. Encoders export row/column/table embeddings via supported wrappers; shared lightweight heads then probe them on three suites (TRL-CTbench for column/table tasks, TRL-Rbench for row tasks, TRL-DLTE for compositional Data-Lake Table Enrichment). The benchmark releases 50 OpenML tables with 123 verified targets, 16 row-pair linkage rewrites, and a 47,772-table DLTE lake. Experiments across 20 models and 16 tasks support the claim that, once downstream conditions are standardized, encoder quality is capability-specific rather than captured by any single leaderboard (text encoders lead on surface-text signals, specialists win on aligned objectives, and DLTE pipelines require non-additive compositional fit).
Significance. If the central claim holds, the work is significant for supplying a reusable protocol and assets that enable direct comparison of tabular encoders from different paradigms at the representation level. It supplies concrete evidence against single-leaderboard rankings and illustrates that top end-to-end quality arises from capability-matched combinations rather than marginal per-stage ranks. The public release of curated tables, reformulations, and code is a clear strength supporting reproducibility and follow-on work.
major comments (1)
- [Abstract and evaluation protocol description] The central claim (abstract) that encoder quality is capability-specific once downstream conditions are standardized rests on the assumption that the shared evaluation protocol itself is neutral across paradigms. The described setup uses encoder-specific wrappers, 123 verified targets, 16 row-pair linkage rewrites, and lightweight heads for the three suites, yet no ablation is reported that swaps head architectures (e.g., MLP vs. linear), alters reformulation templates, or further standardizes wrapper interfaces. Without such checks it remains possible that the observed patterns (text encoders on surface-text tasks, non-additive DLTE pipelines) are partly artifacts of the particular protocol choices rather than intrinsic capability differences.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation protocol. We address the major comment below and describe the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and evaluation protocol description] The central claim (abstract) that encoder quality is capability-specific once downstream conditions are standardized rests on the assumption that the shared evaluation protocol itself is neutral across paradigms. The described setup uses encoder-specific wrappers, 123 verified targets, 16 row-pair linkage rewrites, and lightweight heads for the three suites, yet no ablation is reported that swaps head architectures (e.g., MLP vs. linear), alters reformulation templates, or further standardizes wrapper interfaces. Without such checks it remains possible that the observed patterns (text encoders on surface-text tasks, non-additive DLTE pipelines) are partly artifacts of the particular protocol choices rather than intrinsic capability differences.
Authors: We agree that additional ablations would provide stronger evidence for the neutrality of the protocol. The wrappers must be encoder-specific to handle the heterogeneous output formats and embedding spaces of models from different paradigms, but the probing heads are deliberately shared and lightweight (primarily linear or small MLP) to minimize downstream bias. The 123 targets and 16 rewrites were manually verified for consistency. In the revised manuscript we will add (i) a head-architecture ablation (linear vs. two-layer MLP) on a representative subset of tasks from each suite and (ii) a sensitivity analysis to the reformulation templates used in TRL-Rbench and TRL-DLTE. We will also expand the methods section to document the exact interface standardization steps already taken. These additions will directly address the concern that the reported patterns could be protocol artifacts. revision: yes
Circularity Check
No circularity: empirical benchmark comparisons on released assets
full rationale
The paper introduces TRL-Bench and reports direct empirical results across 20 models and 16 tasks using standardized wrappers, heads, and reformulations on curated assets (50 OpenML tables, 123 targets, 16 rewrites, 47k-table lake). The central claim—that encoder quality is capability-specific once conditions are standardized—is an observation from these runs, not a quantity derived from equations, fitted parameters renamed as predictions, or self-citation chains. No load-bearing step reduces to its own inputs by construction; the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Lightweight heads applied to exported embeddings provide a fair probe of encoder quality across paradigms.
Reference graph
Works this paper leans on
-
[1]
α-ReQ: Assessing representation quality in self-supervised learning by measuring eigenspectrum decay
Kumar Krishna Agrawal, Arnab Kumar Mondal, Arna Ghosh, and Blake Richards. α-ReQ: Assessing representation quality in self-supervised learning by measuring eigenspectrum decay. InNeurIPS, 2022
2022
-
[2]
Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classifier probes.arXiv preprint arXiv:1610.01644, 2016
Pith/arXiv arXiv 2016
-
[3]
TabularS3L: A PyTorch Lightning-based library for self- and semi-supervised learning on tabular data.https://github.com/Alcoholrithm/TabularS3L, 2024
Alcoholrithm. TabularS3L: A PyTorch Lightning-based library for self- and semi-supervised learning on tabular data.https://github.com/Alcoholrithm/TabularS3L, 2024
2024
-
[4]
Macke, and Davide Zoccolan
Alessio Ansuini, Alessandro Laio, Jakob H. Macke, and Davide Zoccolan. Intrinsic dimension of data representations in deep neural networks. InNeurIPS, 2019
2019
-
[5]
Transformers for tabular data representa- tion: A survey of models and applications.Transactions of the Association for Computational Linguistics, 11:227–249, 2023
Gilbert Badaro, Mohammed Saeed, and Paolo Papotti. Transformers for tabular data representa- tion: A survey of models and applications.Transactions of the Association for Computational Linguistics, 11:227–249, 2023
2023
-
[6]
SCARF: Self-supervised contrastive learning using random feature corruption
Dara Bahri, Heinrich Jiang, Yi Tay, and Donald Metzler. SCARF: Self-supervised contrastive learning using random feature corruption. InICLR, 2022
2022
-
[7]
Representation learning: A review and new perspectives.IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(8): 1798–1828, 2013
Yoshua Bengio, Aaron Courville, and Pascal Vincent. Representation learning: A review and new perspectives.IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(8): 1798–1828, 2013
2013
-
[8]
van Rijn, and Joaquin Vanschoren
Bernd Bischl, Giuseppe Casalicchio, Matthias Feurer, Pieter Gijsbers, Frank Hutter, Michel Lang, Rafael Gomes Mantovani, Jan N. van Rijn, and Joaquin Vanschoren. OpenML bench- marking suites. InNeurIPS Datasets and Benchmarks Track, 2021
2021
-
[9]
Alex Bogatu, Alvaro A. A. Fernandes, Norman W. Paton, and Nikolaos Konstantinou. Dataset discovery in data lakes. InICDE, pages 709–720, 2020
2020
-
[10]
Language models are realistic tabular data generators
Vadim Borisov, Kathrin Seßler, Tobias Leemann, Martin Pawelczyk, and Gjergji Kasneci. Language models are realistic tabular data generators. InICLR, 2023
2023
-
[11]
Deep neural networks and tabular data: A survey.IEEE Transactions on Neural Networks and Learning Systems, 35(6):7499–7519, 2024
Vadim Borisov, Tobias Leemann, Kathrin Seßler, Johannes Haug, Martin Pawelczyk, and Gjergji Kasneci. Deep neural networks and tabular data: A survey.IEEE Transactions on Neural Networks and Learning Systems, 35(6):7499–7519, 2024
2024
-
[12]
ExcelFormer: A neural network surpassing GBDTs on tabular data.arXiv preprint arXiv:2301.02819, 2023
Jintai Chen, Jiahuan Yan, Qiyuan Chen, Danny Ziyi Chen, Jian Wu, and Jimeng Sun. ExcelFormer: A neural network surpassing GBDTs on tabular data.arXiv preprint arXiv:2301.02819, 2023
arXiv 2023
-
[13]
TabFact: A large-scale dataset for table-based fact verification
Wenhu Chen, Hongmin Wang, Jianshu Chen, Yunkai Zhang, Hong Wang, Shiyang Li, Xiyou Zhou, and William Yang Wang. TabFact: A large-scale dataset for table-based fact verification. InICLR, 2020
2020
-
[14]
Double/debiased machine learning for treatment and structural parameters.The Econometrics Journal, 2018
Victor Chernozhukov, Denis Chetverikov, Mert Demirer, Esther Duflo, Christian Hansen, Whitney Newey, and James Robins. Double/debiased machine learning for treatment and structural parameters.The Econometrics Journal, 2018
2018
-
[15]
Tianji Cong, Madelon Hulsebos, Zhenjie Sun, Paul Groth, and H. V . Jagadish. Observatory: Characterizing embeddings of relational tables.Proceedings of the VLDB Endowment, 17(4): 849–862, 2023. 10
2023
-
[16]
Statistical comparisons of classifiers over multiple data sets.Journal of Machine Learning Research, 7:1–30, 2006
Janez Demšar. Statistical comparisons of classifiers over multiple data sets.Journal of Machine Learning Research, 7:1–30, 2006
2006
-
[17]
TURL: Table understanding through representation learning.Proceedings of the VLDB Endowment, 14(3):307–319, 2020
Xiang Deng, Huan Sun, Alyssa Lees, You Wu, and Cong Yu. TURL: Table understanding through representation learning.Proceedings of the VLDB Endowment, 14(3):307–319, 2020
2020
-
[18]
Yuhao Deng, Chengliang Chai, Lei Cao, Qin Yuan, Siyuan Chen, Yanrui Yu, Zhaoze Sun, Junyi Wang, Jiajun Li, Ziqi Cao, Kaisen Jin, Chi Zhang, Yuqing Jiang, Yuanfang Zhang, Yuping Wang, Ye Yuan, Guoren Wang, and Nan Tang. LakeBench: A benchmark for discovering joinable and unionable tables in data lakes.Proceedings of the VLDB Endowment, 17(8):1925–1938, 202...
-
[19]
BERT: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. InNAACL, 2019
2019
-
[20]
Nick Erickson, Jonas Mueller, Alexander Shirkov, Hang Zhang, Pedro Larroy, Mu Li, and Alexander Smola. AutoGluon-Tabular: Robust and accurate AutoML for structured data.arXiv preprint arXiv:2003.06505, 2020
Pith/arXiv arXiv 2003
-
[21]
TabArena: A living benchmark for machine learning on tabular data
Nick Erickson, Lennart Purucker, Andrej Tschalzev, David Holzmüller, Prateek Mutalik Desai, David Salinas, and Frank Hutter. TabArena: A living benchmark for machine learning on tabular data. InNeurIPS Datasets and Benchmarks Track, 2025
2025
-
[22]
Estimating the intrinsic dimension of datasets by a minimal neighborhood information.Scientific Reports, 7(1):12140, 2017
Elena Facco, Maria d’Errico, Alex Rodriguez, and Alessandro Laio. Estimating the intrinsic dimension of datasets by a minimal neighborhood information.Scientific Reports, 7(1):12140, 2017
2017
-
[23]
Grace Fan, Jin Wang, Yuliang Li, and Renée J. Miller. Table discovery in data lakes: State-of- the-art and future directions. InSIGMOD Companion, 2023
2023
-
[24]
Grace Fan, Jin Wang, Yuliang Li, Dan Zhang, and Renée J. Miller. Semantics-aware dataset dis- covery from data lakes with contextualized column-based representation learning.Proceedings of the VLDB Endowment, 16(7):1726–1739, 2023
2023
-
[25]
OpenML-CTR23: A curated tabular regression benchmarking suite
Sebastian Fischer, Liana Harutyunyan, Matthias Feurer, and Bernd Bischl. OpenML-CTR23: A curated tabular regression benchmarking suite. InAutoML Conference, 2023
2023
-
[26]
RankMe: Assessing the downstream performance of pretrained self-supervised representations by their rank
Quentin Garrido, Randall Balestriero, Laurent Najman, and Yann LeCun. RankMe: Assessing the downstream performance of pretrained self-supervised representations by their rank. In ICML, 2023
2023
-
[27]
Revisiting deep learning models for tabular data
Yury Gorishniy, Ivan Rubachev, Valentin Khrulkov, and Artem Babenko. Revisiting deep learning models for tabular data. InNeurIPS, 2021
2021
-
[28]
TabR: Tabular deep learning meets nearest neighbors
Yury Gorishniy, Ivan Rubachev, Nikolay Kartashev, Daniil Shlenskii, Akim Kotelnikov, and Artem Babenko. TabR: Tabular deep learning meets nearest neighbors. InICLR, 2024
2024
-
[29]
TaPas: Weakly supervised table parsing via pre-training
Jonathan Herzig, Pawel Krzysztof Nowak, Thomas Müller, Francesco Piccinno, and Julian Mar- tin Eisenschlos. TaPas: Weakly supervised table parsing via pre-training. InACL, 2020
2020
-
[30]
Open domain question answering over tables via dense retrieval
Jonathan Herzig, Thomas Müller, Syrine Krichene, and Julian Eisenschlos. Open domain question answering over tables via dense retrieval. InNAACL, 2021
2021
-
[31]
TabPFN: A transformer That solves small tabular classification problems in a second
Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. TabPFN: A transformer That solves small tabular classification problems in a second. InICLR, 2023
2023
-
[32]
Accurate predictions on small data with a tabular foundation model.Nature, 2025
Noah Hollmann, Samuel Müller, Lennart Purucker, Arjun Krishnakumar, Max Körfer, Shi Bin Hoo, Robin Tibor Schirrmeister, and Frank Hutter. Accurate predictions on small data with a tabular foundation model.Nature, 2025
2025
-
[33]
Xin Huang, Ashish Khetan, Milan Cvitkovic, and Zohar Karnin. TabTransformer: Tabular data modeling using contextual embeddings.arXiv preprint arXiv:2012.06678, 2020
Pith/arXiv arXiv 2012
-
[34]
TABBIE: Pretrained representa- tions of tabular data
Hiroshi Iida, Dung Thai, Varun Manjunatha, and Mohit Iyyer. TABBIE: Pretrained representa- tions of tabular data. InNAACL, 2021. 11
2021
-
[35]
OmniTab: Pretraining with natural and synthetic data for few-shot table-based question answering
Zhengbao Jiang, Yi Mao, Pengcheng He, Graham Neubig, and Weizhu Chen. OmniTab: Pretraining with natural and synthetic data for few-shot table-based question answering. In NAACL, 2022
2022
-
[36]
SemTab 2019: Resources to benchmark tabular data to knowledge graph matching systems
Ernesto Jiménez-Ruiz, Oktie Hassanzadeh, Vasilis Efthymiou, Jiaoyan Chen, and Kavitha Srinivas. SemTab 2019: Resources to benchmark tabular data to knowledge graph matching systems. InESWC, pages 514–530, 2020. doi: 10.1007/978-3-030-49461-2_30
-
[37]
Billion-scale similarity search with GPUs
Jeff Johnson, Matthijs Douze, and Hervé Jégou. Billion-scale similarity search with GPUs. IEEE Transactions on Big Data, 7(3):535–547, 2021
2021
-
[38]
PATE-GAN: Generating synthetic data with differential privacy guarantees
James Jordon, Jinsung Yoon, and Mihaela van der Schaar. PATE-GAN: Generating synthetic data with differential privacy guarantees. InICLR, 2019
2019
-
[39]
Miller, and Mirek Riedewald
Aamod Khatiwada, Grace Fan, Roee Shraga, Zixuan Chen, Wolfgang Gatterbauer, Renée J. Miller, and Mirek Riedewald. SANTOS: Relationship-based semantic table union search. In SIGMOD, 2023
2023
-
[40]
TabSketchFM: Sketch-based tabular representation learning for data discovery over data lakes
Aamod Khatiwada, Harsha Kokel, Ibrahim Abdelaziz, Subhajit Chaudhury, Julian Dolby, Oktie Hassanzadeh, Zhenhan Huang, Tejaswini Pedapati, Horst Samulowitz, and Kavitha Srinivas. TabSketchFM: Sketch-based tabular representation learning for data discovery over data lakes. InICDE, 2025
2025
-
[41]
CARTE: Pretraining and transfer for tabular learning
Myung Jun Kim, Léo Grinsztajn, and Gaël Varoquaux. CARTE: Pretraining and transfer for tabular learning. InICML, 2024
2024
-
[42]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InICLR, 2015
2015
-
[43]
SOTAB: The WDC Schema.org table annotation benchmark
Keti Korini, Ralph Peeters, and Christian Bizer. SOTAB: The WDC Schema.org table annotation benchmark. InSemTab @ ISWC, 2022
2022
-
[44]
TabDDPM: Mod- elling tabular data with diffusion models
Akim Kotelnikov, Dmitry Baranchuk, Ivan Rubachev, and Artem Babenko. TabDDPM: Mod- elling tabular data with diffusion models. InICML, 2023
2023
-
[45]
Valentine: Evaluating matching techniques for dataset discovery
Christos Koutras, George Siachamis, Andra Ionescu, Kyriakos Psarakis, Jerry Brons, Marios Fragkoulis, Christoph Lofi, Angela Bonifati, and Asterios Katsifodimos. Valentine: Evaluating matching techniques for dataset discovery. InICDE, 2021
2021
-
[46]
Harold W. Kuhn. The Hungarian method for the assignment problem.Naval Research Logistics Quarterly, 2(1–2):83–97, 1955
1955
-
[47]
Word translation without parallel data
Guillaume Lample, Alexis Conneau, Marc’Aurelio Ranzato, Ludovic Denoyer, and Hervé Jégou. Word translation without parallel data. InICLR, 2018
2018
-
[48]
Binning as a pretext task: Improving self-supervised learning in tabular domains
Kyungeun Lee, Ye Seul Sim, Hye-Seung Cho, Moonjung Eo, Suhee Yoon, Sanghyu Yoon, and Woohyung Lim. Binning as a pretext task: Improving self-supervised learning in tabular domains. InICML, 2024
2024
-
[49]
Deep entity matching with pre-trained language models.Proceedings of the VLDB Endowment, 14(1): 50–60, 2020
Yuliang Li, Jinfeng Li, Yoshihiko Suhara, AnHai Doan, and Wang-Chiew Tan. Deep entity matching with pre-trained language models.Proceedings of the VLDB Endowment, 14(1): 50–60, 2020
2020
-
[50]
Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, and Meishan Zhang. Towards general text embeddings with multi-stage contrastive learning.arXiv preprint arXiv:2308.03281, 2023
Pith/arXiv arXiv 2023
-
[51]
Isolation forest
Fei Tony Liu, Kai Ming Ting, and Zhi-Hua Zhou. Isolation forest. InICDM, 2008
2008
-
[52]
TAPEX: Table pre-training via learning a neural SQL executor
Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, and Jian-Guang Lou. TAPEX: Table pre-training via learning a neural SQL executor. InICLR, 2022
2022
-
[53]
Deep learning for entity matching: A design space exploration
Sidharth Mudgal, Han Li, Theodoros Rekatsinas, AnHai Doan, Youngchoon Park, Ganesh Krishnan, Rohit Deep, Esteban Arcaute, and Vijay Raghavendra. Deep learning for entity matching: A design space exploration. InSIGMOD, 2018. 12
2018
-
[54]
Pu, and Renée J
Fatemeh Nargesian, Erkang Zhu, Ken Q. Pu, and Renée J. Miller. Table union search on open data.Proceedings of the VLDB Endowment, 11(7):813–825, 2018
2018
-
[55]
Text and code embeddings by contrastive pre-training
Arvind Neelakantan, Tao Xu, Raul Puri, Alec Radford, Jesse Michael Han, Jerry Tworek, Qiming Yuan, Nikolas Tezak, Jong Wook Kim, Chris Hallacy, Johannes Heidecke, Pranav Shyam, Boris Power, Tyna Eloundou Nekoul, Girish Sastry, Gretchen Krueger, David Schnurr, Felipe Petroski Such, Kenny Hsu, Madeleine Thompson, Tabarak Khan, Toki Sherbakov, Joanne Jang, P...
Pith/arXiv arXiv 2022
-
[56]
Hall, Daniel Cer, and Yinfei Yang
Jianmo Ni, Gustavo Hernández Ábrego, Noah Constant, Ji Ma, Keith B. Hall, Daniel Cer, and Yinfei Yang. Sentence-T5: Scalable sentence encoders from pre-trained text-to-text models. In Findings of ACL, 2022
2022
-
[57]
New embedding models and API updates
OpenAI. New embedding models and API updates. https://openai.com/index/ new-embedding-models-and-api-updates/, 2024. Released January 25, 2024
2024
-
[58]
Koyena Pal, Aamod Khatiwada, Roee Shraga, and Renée J. Miller. Generative benchmark creation for table union search.arXiv preprint arXiv:2308.03883, 2023
arXiv 2023
-
[59]
ClavaDDPM: Multi-relational data synthesis with cluster-guided diffusion models
Wei Pang, Masoumeh Shafieinejad, Lucy Liu, Stephanie Hazlewood, and Xi He. ClavaDDPM: Multi-relational data synthesis with cluster-guided diffusion models. InNeurIPS, 2024
2024
-
[60]
Compositional semantic parsing on semi-structured tables
Panupong Pasupat and Percy Liang. Compositional semantic parsing on semi-structured tables. InACL, 2015
2015
-
[61]
The synthetic data vault
Neha Patki, Roy Wedge, and Kalyan Veeramachaneni. The synthetic data vault. InDSAA, 2016
2016
-
[62]
Using schema.org annotations for training and maintaining product matchers
Ralph Peeters, Anna Primpeli, Benedikt Wichtlhuber, and Christian Bizer. Using schema.org annotations for training and maintaining product matchers. InWIMS, 2020
2020
-
[63]
The WDC training dataset and gold standard for large-scale product matching
Anna Primpeli, Ralph Peeters, and Christian Bizer. The WDC training dataset and gold standard for large-scale product matching. InCompanion of The 2019 World Wide Web Conference (WWW ’19 Companion), ECNLP Workshop, 2019
2019
-
[64]
TabICL: A tabular foundation model for in-context learning on large data
Jingang Qu, David Holzmüller, Gaël Varoquaux, and Marine Le Morvan. TabICL: A tabular foundation model for in-context learning on large data. InICML, 2025
2025
-
[65]
Tabular data: Deep learning is not all you need
Ravid Shwartz-Ziv and Amitai Armon. Tabular data: Deep learning is not all you need. Information Fusion, 81:84–90, 2022
2022
-
[66]
Bayan Bruss, and Tom Goldstein
Gowthami Somepalli, Micah Goldblum, Avi Schwarzschild, C. Bayan Bruss, and Tom Goldstein. SAINT: Improved neural networks for tabular data via row attention and contrastive pre-training. arXiv preprint arXiv:2106.01342, 2021
arXiv 2021
-
[67]
MPNet: Masked and permuted pre-training for language understanding
Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, and Tie-Yan Liu. MPNet: Masked and permuted pre-training for language understanding. InNeurIPS, 2020
2020
-
[68]
LakeBench: Benchmarks for data discovery over data lakes.arXiv preprint arXiv:2307.04217, 2023
Kavitha Srinivas, Julian Dolby, Ibrahim Abdelaziz, Oktie Hassanzadeh, Harsha Kokel, Aamod Khatiwada, Tejaswini Pedapati, Subhajit Chaudhury, and Horst Samulowitz. LakeBench: Benchmarks for data discovery over data lakes.arXiv preprint arXiv:2307.04217, 2023
arXiv 2023
-
[69]
Aofeng Su, Aowen Wang, Chao Ye, et al. TableGPT2: A large multimodal model with tabular data integration.arXiv preprint arXiv:2411.02059, 2024
arXiv 2024
-
[70]
Annotating columns with pre-trained language models
Yoshihiko Suhara, Jinfeng Li, Yuliang Li, Dan Zhang, Ça ˘gatay Demiralp, Chen Chen, and Wang-Chiew Tan. Annotating columns with pre-trained language models. InSIGMOD, 2022
2022
-
[71]
Unsupervised embedding quality evaluation.arXiv preprint arXiv:2305.16562, 2023
Anton Tsitsulin, Marina Munkhoeva, and Bryan Perozzi. Unsupervised embedding quality evaluation.arXiv preprint arXiv:2305.16562, 2023
arXiv 2023
-
[72]
SubTab: Subsetting features of tabular data for self-supervised representation learning
Talip Ucar, Ehsan Hajiramezanali, and Lindsay Edwards. SubTab: Subsetting features of tabular data for self-supervised representation learning. InNeurIPS, 2021. 13
2021
-
[73]
van Rijn, Bernd Bischl, and Luis Torgo
Joaquin Vanschoren, Jan N. van Rijn, Bernd Bischl, and Luis Torgo. OpenML: Networked science in machine learning.ACM SIGKDD Explorations Newsletter, 15(2):49–60, 2014
2014
-
[74]
Extracting and composing robust features with denoising autoencoders
Pascal Vincent, Hugo Larochelle, Yoshua Bengio, and Pierre-Antoine Manzagol. Extracting and composing robust features with denoising autoencoders. InICML, 2008
2008
-
[75]
TUTA: Tree-based transformers for generally structured table pre-training
Zhiruo Wang, Haoyu Dong, Ran Jia, Jia Li, Zhiyi Fu, Shi Han, and Dongmei Zhang. TUTA: Tree-based transformers for generally structured table pre-training. InKDD, 2021
2021
-
[76]
TransTab: Learning transferable tabular transformers across tables
Zifeng Wang and Jimeng Sun. TransTab: Learning transferable tabular transformers across tables. InNeurIPS, 2022
2022
-
[77]
Modeling tabular data using conditional GAN
Lei Xu, Maria Skoularidou, Alfredo Cuesta-Infante, and Kalyan Veeramachaneni. Modeling tabular data using conditional GAN. InNeurIPS, 2019
2019
-
[78]
TaBERT: Pretraining for joint understanding of textual and tabular data
Pengcheng Yin, Graham Neubig, Wen tau Yih, and Sebastian Riedel. TaBERT: Pretraining for joint understanding of textual and tabular data. InACL, 2020
2020
-
[79]
GAIN: Missing data imputation using generative adversarial nets
Jinsung Yoon, James Jordon, and Mihaela van der Schaar. GAIN: Missing data imputation using generative adversarial nets. InICML, 2018
2018
-
[80]
VIME: Extending the success of self- and semi-supervised learning to tabular domain
Jinsung Yoon, Yao Zhang, James Jordon, and Mihaela van der Schaar. VIME: Extending the success of self- and semi-supervised learning to tabular domain. InNeurIPS, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.