Is Text All You Need? Text as a Universal Information Bottleneck for Speech LLMs
Pith reviewed 2026-06-27 16:24 UTC · model grok-4.3
The pith
Representing speech frames as convex combinations of LLM token embeddings enables joint ASR and emotion recognition by preserving embedding trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
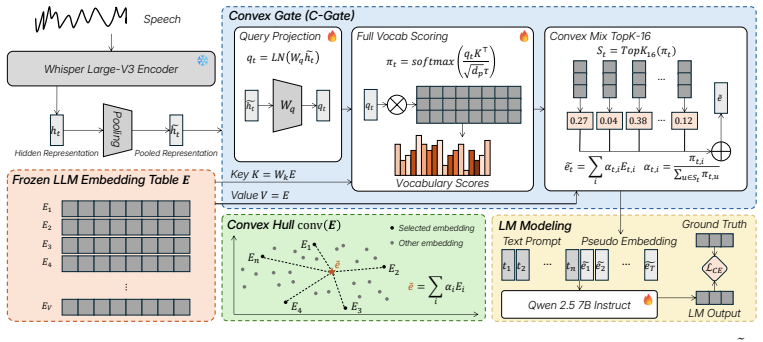
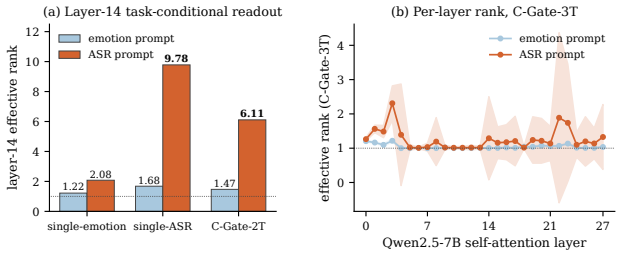
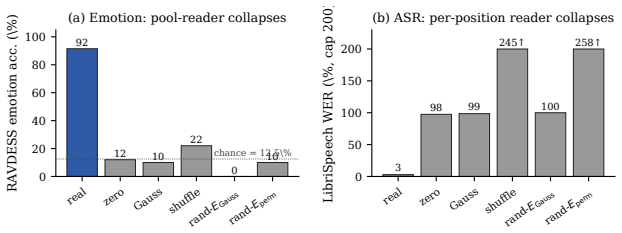
C-Gate represents each speech frame as a convex combination of the LLM's token embeddings, forcing all representations to lie within the input embedding manifold. This architectural constraint supports strong joint performance on automatic speech recognition and emotion recognition while preserving compatibility with the frozen autoregressive decoder. Causal interventions establish that both trajectory structure and manifold alignment are essential, showing that information resides in continuous trajectories within the embedding space rather than in discrete token selections.
What carries the argument
Convex Gate (C-Gate): an architectural convex-hull constraint expressing each speech frame as a convex combination of the LLM's token embeddings to enforce manifold compatibility.
If this is right
- Joint training on transcription and emotion tasks succeeds without performance trade-offs between them.
- Autoregressive decoding in the frozen LLM remains stable because inputs stay inside the pretrained embedding manifold.
- Disrupting embedding trajectories harms performance more than altering discrete token choices.
- Design of speech-to-LLM interfaces should prioritize geometry over forcing discrete token alignment.
Where Pith is reading between the lines
- The same convex-hull approach could be tested for integrating other continuous signals such as video frames into frozen LLMs.
- Full tokenization of speech may prove unnecessary if continuous trajectories inside the embedding space already suffice.
- Applying C-Gate to additional paralinguistic tasks would test how broadly the convex constraint preserves information.
- The method offers a controlled setting for isolating the role of embedding geometry in multimodal LLM integration.
Load-bearing premise
Forcing every speech frame into the convex hull of the LLM's token embeddings preserves all necessary paralinguistic information while guaranteeing compatibility with the frozen autoregressive decoder.
What would settle it
An experiment in which an unconstrained continuous speech encoder achieves higher joint ASR and emotion accuracy than C-Gate, or in which randomizing trajectories while preserving token identities leaves performance unchanged.
Figures
read the original abstract
Large language models (LLMs) provide a powerful reasoning backbone for speech understanding, but integrating continuous acoustic signals into a frozen LLM remains challenging. Existing speech-to-LLM interfaces typically operate at two extremes: either enforcing near-discrete token alignment, which benefits transcription but loses paralinguistic information, or learning unconstrained continuous representations, which can drift away from the LLM's input space and degrade autoregressive decoding. In this work, we propose Convex Gate (C-Gate), a speech-to-LLM bridge that constrains all speech representations to lie within the LLM's input embedding manifold with an architectural convex-hull constraint. Concretely, each frame is represented as a convex combination of token embeddings, ensuring compatibility with the pretrained LLM while preserving continuous expressivity. Across automatic speech recognition (ASR) and emotion recognition, C-Gate achieves strong joint performance, improving LibriSpeech WER by up to 48.7% relative while matching or exceeding single-task emotion accuracy. Beyond performance, our analysis reveals a key insight: information is not carried by discrete token identities, but by time-resolved trajectories in the embedding space. Causal interventions confirm that both the trajectory structure and alignment to the pretrained embedding manifold are critical for performance. These results suggest that geometry, rather than token discreteness, is the fundamental design factor in speech-to-LLM interfaces, and provide a controlled regime for studying multimodal integration in frozen LLMs. We release the checkpoint, per-sample outputs, mechanism dumps, and intervention suite for replication.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Convex Gate (C-Gate), an architectural bridge that represents each speech frame as a convex combination of the frozen LLM's token embeddings, thereby constraining all representations to the LLM input manifold. It reports that this yields up to 48.7% relative WER reduction on LibriSpeech ASR while matching or exceeding single-task emotion recognition accuracy, and uses causal interventions to argue that performance is driven by time-resolved trajectories within the embedding space rather than discrete token identities. The central claim is that geometric alignment to the pretrained manifold, not token discreteness, is the key design factor for speech-to-LLM interfaces.
Significance. If the empirical results and causal claims hold under full experimental scrutiny, the work would establish a controlled, parameter-light regime for studying multimodal integration into frozen LLMs and would supply reproducible artifacts (checkpoint, per-sample outputs, intervention suite) that directly support replication and extension. The geometry-versus-discreteness framing offers a falsifiable alternative to existing discrete-token or unconstrained-continuous approaches.
major comments (2)
- [Abstract] Abstract (C-Gate definition paragraph): the claim that the convex-hull projection 'preserves continuous expressivity' and thereby maintains paralinguistic information rests on the untested assumption that all emotion-relevant acoustic structure lies inside the convex hull of the LLM token embeddings; no ablation compares C-Gate against an unconstrained continuous baseline that is still forced to produce valid LLM inputs, leaving open whether the reported emotion parity reflects true preservation or residual leakage/task simplicity.
- [Causal interventions] Causal interventions section: the reported interventions on trajectory structure and manifold alignment do not include a control condition that deliberately places representations outside the convex hull while preserving trajectory statistics and autoregressive compatibility; without this isolation, the interventions cannot rule out that performance degradation arises from general manifold mismatch rather than the specific hull constraint that defines C-Gate.
minor comments (2)
- [Abstract] Abstract reports relative WER gains without absolute baseline values, error bars, or the number of runs; these details are required to assess whether the 48.7% figure is robust.
- [Abstract] The manuscript states that 'we release the checkpoint, per-sample outputs, mechanism dumps, and intervention suite,' which is a strength; the release should be accompanied by exact training hyperparameters and data splits to enable exact reproduction.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below with clarifications from the manuscript and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract (C-Gate definition paragraph): the claim that the convex-hull projection 'preserves continuous expressivity' and thereby maintains paralinguistic information rests on the untested assumption that all emotion-relevant acoustic structure lies inside the convex hull of the LLM token embeddings; no ablation compares C-Gate against an unconstrained continuous baseline that is still forced to produce valid LLM inputs, leaving open whether the reported emotion parity reflects true preservation or residual leakage/task simplicity.
Authors: The abstract describes C-Gate as using convex combinations to ensure compatibility while preserving continuous expressivity, and reports that this yields emotion recognition accuracy matching or exceeding single-task baselines. This is presented as an empirical outcome rather than a claim that every possible paralinguistic feature must lie inside the hull. We agree that an explicit ablation against an unconstrained continuous adapter (still mapped to the embedding space but without the convex-combination constraint) would further isolate the contribution of the hull. We will revise the abstract to emphasize the empirical preservation result and add a short discussion paragraph noting the absence of that specific baseline and its implications. This is a partial revision. revision: partial
-
Referee: [Causal interventions] Causal interventions section: the reported interventions on trajectory structure and manifold alignment do not include a control condition that deliberately places representations outside the convex hull while preserving trajectory statistics and autoregressive compatibility; without this isolation, the interventions cannot rule out that performance degradation arises from general manifold mismatch rather than the specific hull constraint that defines C-Gate.
Authors: The interventions separately ablate trajectory structure (while retaining manifold alignment) and manifold alignment (while retaining trajectory statistics), each producing measurable degradation. These results, together with comparisons to prior discrete-token and unconstrained-continuous interfaces that operate outside the hull, support the importance of both factors. A control that places points strictly outside the hull while exactly preserving trajectory statistics and autoregressive compatibility is difficult to construct without introducing uncontrolled changes to the representation; the convex-combination mechanism itself defines the hull constraint. We will add a paragraph in the causal interventions section explaining this design choice and the limits of further isolation. This is a partial revision. revision: partial
Circularity Check
No circularity: C-Gate defined by explicit architectural constraint, performance reported as external validation
full rationale
The paper defines C-Gate directly via the architectural requirement that each speech frame be a convex combination of the frozen LLM's token embeddings, then measures downstream ASR WER and emotion accuracy on LibriSpeech and other benchmarks. No equations reduce the reported relative WER gains (e.g., 48.7%) or emotion scores to quantities fitted from the same evaluation data; the convex-hull constraint is not derived from or fitted to those metrics. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing premises in the abstract or described method. Causal interventions test the defined architecture rather than presupposing its outcomes. The derivation chain is therefore self-contained as an architectural proposal with independent empirical checks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The pretrained LLM's input embedding table defines a manifold that is compatible with its autoregressive decoder when inputs lie inside its convex hull.
Reference graph
Works this paper leans on
-
[1]
Yunfei Chu, Jin Xu, Xiaohuan Zhou, Qian Yang, Shiliang Zhang, Zhijie Yan, Chang Zhou, and Jingren Zhou. Qwen-audio: Advancing universal audio understanding via unified large-scale audio-language models.CoRR, abs/2311.07919,
-
[2]
Qwen2-audio technical report.CoRR, abs/2407.10759,
9 Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen2-audio technical report.CoRR, abs/2407.10759,
-
[3]
Closing the gap between text and speech understanding in llms.CoRR, abs/2510.13632,
Santiago Cuervo, Skyler Seto, Maureen de Seyssel, Richard He Bai, Zijin Gu, Tatiana Likhomanenko, Navdeep Jaitly, and Zakaria Aldeneh. Closing the gap between text and speech understanding in llms.CoRR, abs/2510.13632,
-
[4]
Audio flamingo 3: Advancing audio intelligence with fully open large audio language models
Arushi Goel, Sreyan Ghosh, Jaehyeon Kim, Sonal Kumar, Zhifeng Kong, Sang-gil Lee, Chao- Han Huck Yang, Ramani Duraiswami, Dinesh Manocha, Rafael Valle, and Bryan Catanzaro. Audio flamingo 3: Advancing audio intelligence with fully open large audio language models. CoRR, abs/2507.08128,
-
[5]
URL https://arxiv.org/abs/2509.21060. Shujie Hu, Long Zhou, Shujie Liu, Sanyuan Chen, Lingwei Meng, Hongkun Hao, Jing Pan, Xunying Liu, Jinyu Li, Sunit Sivasankaran, Linquan Liu, and Furu Wei. Wavllm: Towards robust and adaptive speech large language model. InEMNLP (Findings), Findings of ACL, pages 4552–4572. Association for Computational Linguistics,
-
[6]
KimiTeam, Ding Ding, Zeqian Ju, Yichong Leng, Songxiang Liu, Tong Liu, Zeyu Shang, Kai Shen, Wei Song, Xu Tan, Heyi Tang, Zhengtao Wang, Chu Wei, Yifei Xin, Xinran Xu, Jianwei Yu, Yutao Zhang, Xinyu Zhou, Y . Charles, Jun Chen, Yanru Chen, Yulun Du, Weiran He, Zhenxing Hu, Guokun Lai, Qingcheng Li, Yangyang Liu, Weidong Sun, Jianzhou Wang, Yuzhi Wang, Yue...
-
[7]
Fastslm: Hierarchical frame q-former for effective speech modality adaptation.CoRR, abs/2601.06199,
Junseok Lee, Sangyong Lee, and Chang-Jae Chun. Fastslm: Hierarchical frame q-former for effective speech modality adaptation.CoRR, abs/2601.06199,
-
[8]
doi: 10.1371/journal.pone.0196391. Fernando López, Santosh Kesiraju, and Jordi Luque. Robustness assessment of large audio language models in multiple-choice evaluation,
-
[9]
Rao Ma, Tongzhou Chen, Kartik Audhkhasi, and Bhuvana Ramabhadran
URLhttps://arxiv.org/abs/2510.04584. Rao Ma, Tongzhou Chen, Kartik Audhkhasi, and Bhuvana Ramabhadran. Legoslm: Connecting LLM with speech encoder using CTC posteriors. InEMNLP (Findings), pages 18171–18186. Association for Computational Linguistics,
-
[10]
Olivier Roy and Martin Vetterli
URLhttps://arxiv.org/abs/2511.03310. Olivier Roy and Martin Vetterli. The effective rank: A measure of effective dimensionality. In EUSIPCO, pages 606–610. IEEE,
-
[11]
Paul K. Rubenstein, Chulayuth Asawaroengchai, Duc Dung Nguyen, Ankur Bapna, Zalán Borsos, Félix de Chaumont Quitry, Peter Chen, Dalia El Badawy, Wei Han, Eugene Kharitonov, Hannah Muckenhirn, Dirk Padfield, James Qin, Danny Rozenberg, Tara N. Sainath, Johan Schalkwyk, Matthew Sharifi, Michelle Tadmor Ramanovich, Marco Tagliasacchi, Alexandru Tudor, Miha- ...
-
[12]
Llasm: Large language and speech model.CoRR, abs/2308.15930,
Yu Shu, Siwei Dong, Guangyao Chen, Wenhao Huang, Ruihua Zhang, Daochen Shi, Qiqi Xiang, and Yemin Shi. Llasm: Large language and speech model.CoRR, abs/2308.15930,
-
[13]
Yirong Sun, Yizhong Geng, Peidong Wei, Yanjun Chen, Jinghan Yang, Rongfei Chen, Wei Zhang, and Xiaoyu Shen. Llaso: A foundational framework for reproducible research in large language and speech model.CoRR, abs/2508.15418,
-
[14]
SSR: alignment-aware modality connector for speech language models.CoRR, abs/2410.00168,
Weiting Tan, Hirofumi Inaguma, Ning Dong, Paden Tomasello, and Xutai Ma. SSR: alignment-aware modality connector for speech language models.CoRR, abs/2410.00168,
-
[15]
Closing the modality reasoning gap for speech large language models.CoRR, abs/2601.05543, 2026a
11 Chaoren Wang, Heng Lu, Xueyao Zhang, Shujie Liu, Yan Lu, Jinyu Li, and Zhizheng Wu. Closing the modality reasoning gap for speech large language models.CoRR, abs/2601.05543, 2026a. Chen Wang, Minpeng Liao, Zhongqiang Huang, Jinliang Lu, Junhong Wu, Yuchen Liu, Chengqing Zong, and Jiajun Zhang. BLSP: bootstrapping language-speech pre-training via behavi...
-
[16]
Mmsu: A massive multi-task spoken language understanding and reasoning benchmark, 2026b
Dingdong Wang, Junan Li, Jincenzi Wu, Dongchao Yang, Xueyuan Chen, Tianhua Zhang, and Helen Meng. Mmsu: A massive multi-task spoken language understanding and reasoning benchmark, 2026b. URLhttps://arxiv.org/abs/2506.04779. Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang,...
-
[17]
Qwen2.5 technical report.CoRR, abs/2412.15115,
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu X...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.