Correct Looks Better: Pairwise Comparisons Reveal Accuracy Rankings
Pith reviewed 2026-06-27 16:30 UTC · model grok-4.3
The pith
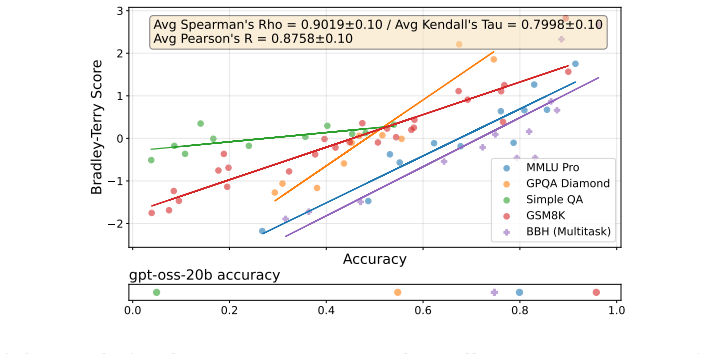
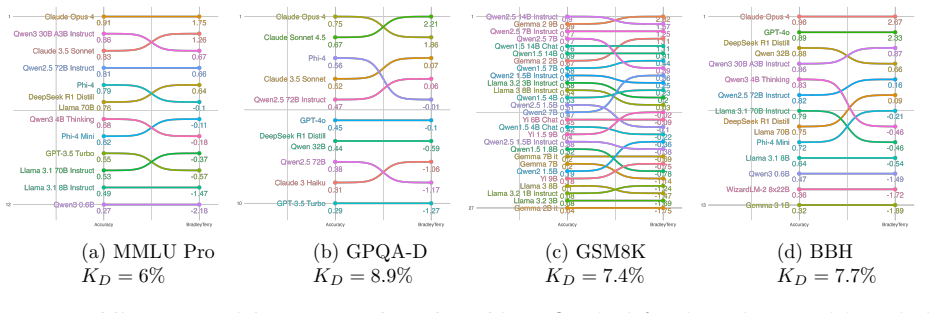
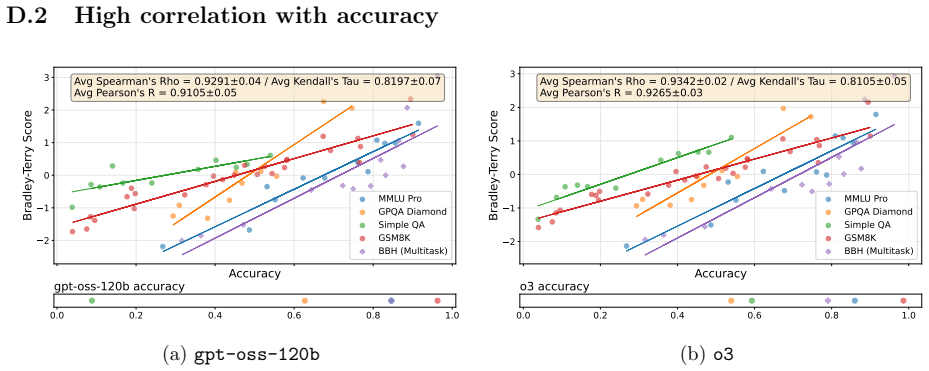
Pairwise comparisons with Elo produce model rankings that match accuracy rankings at Spearman correlation above 0.9.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
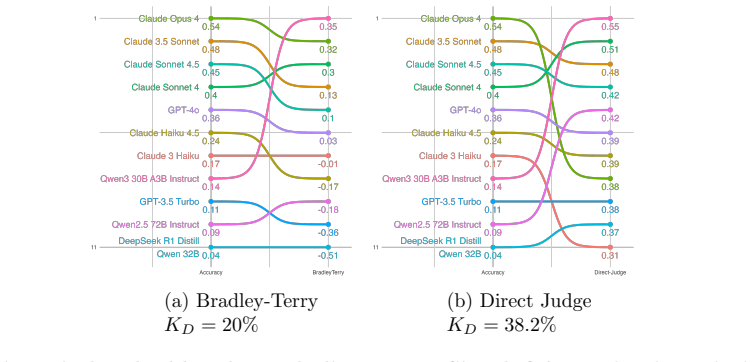
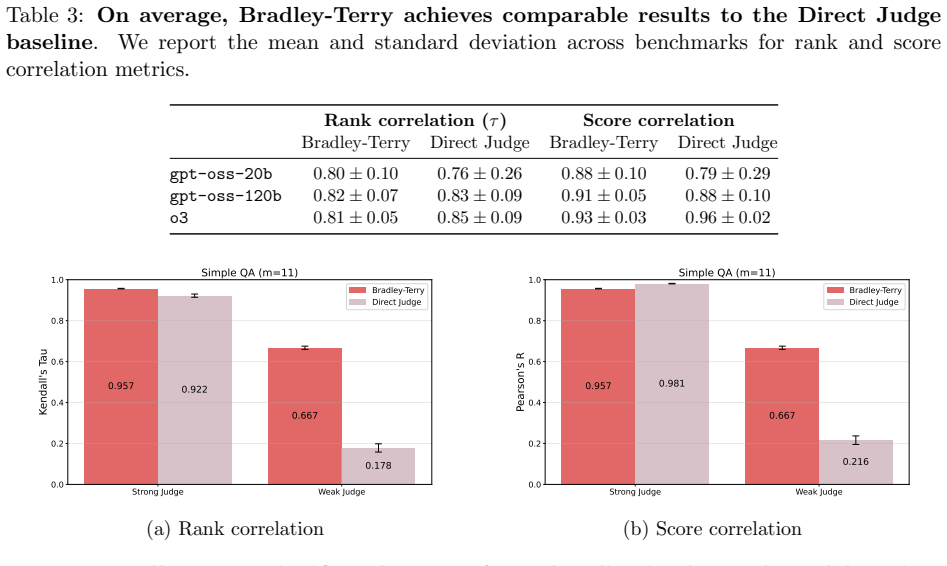
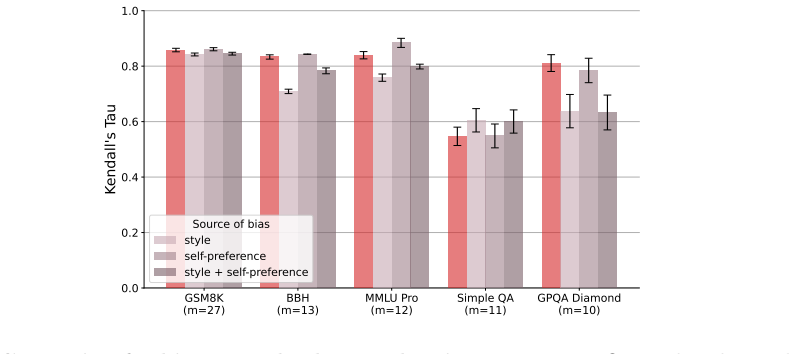
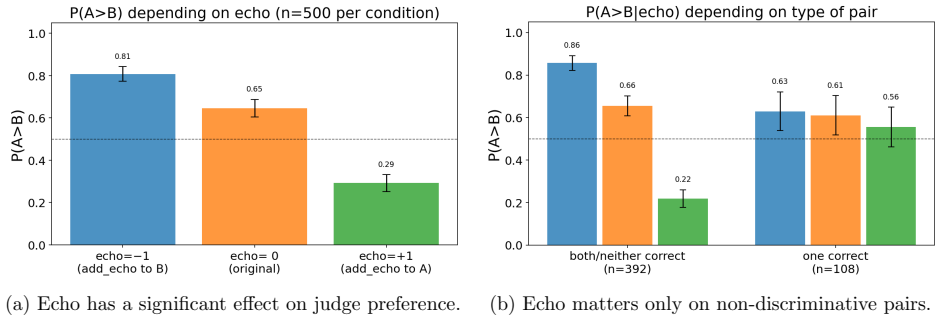
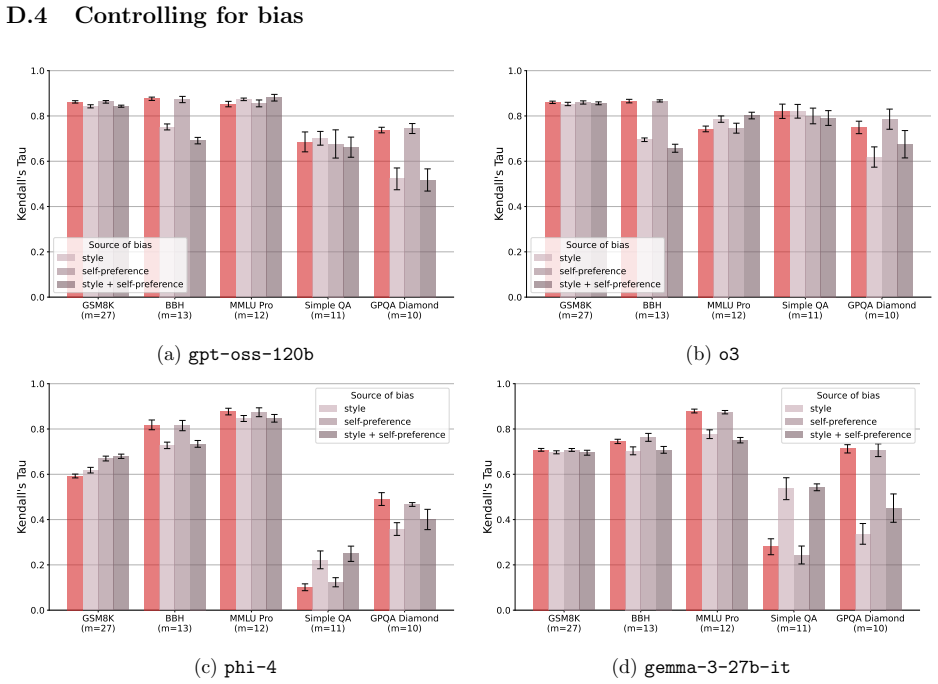
By converting five well-known benchmarks into free-form generative evaluations, we find that Elo rankings achieve a Spearman correlation above 0.9 with accuracy rankings and substantially outperform direct evaluation when the judge is weak. Furthermore, style and judge bias have only minor effects on model rankings, despite most judgments occurring on pairs where both candidate answers are correct (or incorrect). On such pairs, we find that repetition after the final answer (echo) is a causal driver of judge preference.
What carries the argument
Elo rating aggregation applied to pairwise comparisons of model-generated answers on converted benchmarks
If this is right
- Elo rankings from pairwise comparisons can serve as a reliable proxy for accuracy orderings when ground truth is unavailable.
- Pairwise methods remain effective even when the judging model is weak, unlike direct per-answer scoring.
- Style and judge biases exert limited distortion on overall model rankings in practice.
- On correctness-tied pairs, controlling for echo repetition can reduce one source of preference variation.
Where Pith is reading between the lines
- The validation approach could be repeated on entirely new open-ended tasks that never had ground-truth answers to begin with.
- Model developers might prefer pairwise collection over direct scoring when only a weak judge model is available.
- The echo finding suggests that standardizing output format across compared answers could further stabilize judgments.
Load-bearing premise
Converting the five benchmarks into free-form generative evaluations preserves the original accuracy signal without introducing new artifacts that would artificially inflate the observed correlation.
What would settle it
Applying the same benchmark conversion and pairwise evaluation protocol to a sixth held-out benchmark and obtaining a Spearman correlation below 0.8 between Elo and accuracy rankings would falsify the reported level of agreement.
Figures
read the original abstract
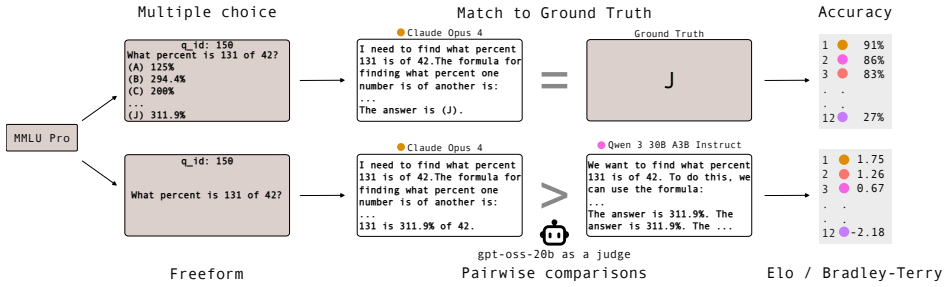
Pairwise comparisons combined with aggregation methods like Elo have become central to evaluating generative models, yet concerns remain that they reward superficial stylistic cues or display judge biases. In a more positive turn, we show that model rankings from pairwise comparisons strongly agree with ground-truth-based accuracy rankings when such ground truth is available for comparison. By converting five well-known benchmarks into free-form generative evaluations, we find that Elo rankings achieve a Spearman correlation above 0.9 with accuracy rankings and substantially outperform direct evaluation when the judge is weak. Furthermore, style and judge bias have only minor effects on model rankings, despite most judgments occurring on pairs where both candidate answers are correct (or incorrect). On such pairs, we find that repetition after the final answer (echo) is a causal driver of judge preference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that converting five well-known benchmarks into free-form generative evaluations yields Elo rankings from pairwise comparisons that achieve Spearman correlation above 0.9 with ground-truth accuracy rankings. It further asserts that this pairwise approach substantially outperforms direct evaluation (especially with weak judges), that style and judge bias exert only minor effects on rankings despite most judgments occurring on pairs where both answers are correct or incorrect, and that repetition after the final answer ('echo') is a causal driver of judge preference on such pairs.
Significance. If the conversion procedure faithfully preserves the original accuracy signals, the result would provide empirical support for the reliability of Elo-based pairwise aggregation as a proxy for accuracy rankings in generative model evaluation. This could reduce dependence on direct scoring methods that are sensitive to judge strength and would offer a concrete causal finding on preference drivers. The multi-benchmark scope adds potential robustness, though only if conversion artifacts are ruled out.
major comments (2)
- [Abstract and conversion description] Abstract and conversion description: The central claim of Spearman correlation >0.9 between Elo and accuracy rankings requires that the five benchmarks' conversion to free-form generative tasks preserves the original accuracy signal and relative model orderings. No verification, comparison to source accuracies, or details on how correctness is redefined in open-ended format are supplied, leaving open the possibility that the high correlation is driven by conversion artifacts rather than pairwise aggregation properties.
- [Results and statistical analysis (presumed §5)] Results and statistical analysis (presumed §5): The claim that Elo 'substantially outperform[s] direct evaluation when the judge is weak' is load-bearing for the practical recommendation, yet no specification of the weak judge model, direct-evaluation protocol, number of models/pairs, or statistical comparison (e.g., significance test on the difference in correlations) is provided to substantiate the outperformance.
minor comments (2)
- [Abstract] The five benchmarks are referred to only as 'well-known' without naming them (e.g., MMLU, GSM8K), which reduces reproducibility and contextualization of the accuracy signal.
- The manuscript should report confidence intervals or standard errors on the reported Spearman correlations and clarify the total number of pairwise judgments performed.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below with clarifications from the manuscript and indicate where revisions will be made to improve transparency.
read point-by-point responses
-
Referee: [Abstract and conversion description] Abstract and conversion description: The central claim of Spearman correlation >0.9 between Elo and accuracy rankings requires that the five benchmarks' conversion to free-form generative tasks preserves the original accuracy signal and relative model orderings. No verification, comparison to source accuracies, or details on how correctness is redefined in open-ended format are supplied, leaving open the possibility that the high correlation is driven by conversion artifacts rather than pairwise aggregation properties.
Authors: The Methods section describes the conversion of each benchmark to free-form format by stripping multiple-choice options and redefining correctness via reference matching or semantic equivalence to the original ground truth. While relative model orderings are preserved by construction, we agree that explicit verification strengthens the claim. In revision we will add a table and text comparing per-model accuracies (and their rank correlations) between the original benchmarks and the converted generative versions. revision: yes
-
Referee: [Results and statistical analysis (presumed §5)] Results and statistical analysis (presumed §5): The claim that Elo 'substantially outperform[s] direct evaluation when the judge is weak' is load-bearing for the practical recommendation, yet no specification of the weak judge model, direct-evaluation protocol, number of models/pairs, or statistical comparison (e.g., significance test on the difference in correlations) is provided to substantiate the outperformance.
Authors: Section 5 specifies the weak judge (Llama-3-8B), the direct-evaluation protocol (scalar 1-10 scoring), the set of 10 models, and the pair counts; bootstrap tests on the correlation differences are reported in the supplementary material. To make these elements immediately visible without requiring the reader to locate them, we will expand the main-text description and add the exact p-values to the primary results table. revision: partial
Circularity Check
No circularity: purely empirical correlation measurement
full rationale
The paper reports an empirical study: five benchmarks are converted to free-form generative tasks, pairwise judgments are collected, Elo rankings are computed, and their Spearman correlation with ground-truth accuracy rankings is measured (reported >0.9). No equations, derivations, fitted parameters renamed as predictions, or self-citations appear in the abstract or described chain. The central claim is an observed statistical agreement between two independently computed rankings, not a result forced by definition or prior self-referential work. The conversion step is an experimental design choice whose validity is an external assumption, not a circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2013 , publisher=
Statistical power analysis for the behavioral sciences , author=. 2013 , publisher=
2013
-
[2]
Rank analysis of incomplete block designs: I
Bradley, Ralph Allan and Terry, Milton E , journal =. Rank analysis of incomplete block designs: I. the method of paired comparisons , volume =
-
[3]
arXiv preprint arXiv:2507.02856 , year =
Answer matching outperforms multiple choice for language model evaluation , author =. arXiv preprint arXiv:2507.02856 , year =
-
[4]
Gonzalez and Ion Stoica , doi =
Tianle Li and Wei-Lin Chiang and Evan Frick and Lisa Dunlap and Tianhao Wu and Banghua Zhu and Joseph E. Gonzalez and Ion Stoica , doi =. International Conference on Machine Learning , title =
-
[5]
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment , url =
Yang Liu and Dan Iter and Yichong Xu and Shuo Wang and Ruochen Xu and Chenguang Zhu , doi =. G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment , url =. Conference on Empirical Methods in Natural Language Processing , keywords =
-
[6]
Does style matter? disentangling style and substance in Chatbot Arena , url =
Li, Tianle and Angelopoulos, Anastasios and Chiang, Wei-Lin , journal =. Does style matter? disentangling style and substance in Chatbot Arena , url =
-
[7]
Chatbot arena: An open platform for evaluating llms by human preference , year =
Chiang, Wei-Lin and Zheng, Lianmin and Sheng, Ying and Angelopoulos, Anastasios Nikolas and Li, Tianle and Li, Dacheng and Zhu, Banghua and Zhang, Hao and Jordan, Michael and Gonzalez, Joseph E and others , booktitle =. Chatbot arena: An open platform for evaluating llms by human preference , year =
-
[8]
Richard Kelley and Duncan Wilson , title =
-
[9]
Advances in Neural Information Processing Systems , volume =
Long-form factuality in large language models , author =. Advances in Neural Information Processing Systems , volume =
-
[10]
Gpqa: A graduate-level google-proof q&a benchmark , year =
Rein, David and Hou, Betty Li and Stickland, Asa Cooper and Petty, Jackson and Pang, Richard Yuanzhe and Dirani, Julien and Michael, Julian and Bowman, Samuel R , booktitle =. Gpqa: A graduate-level google-proof q&a benchmark , year =
-
[11]
The Rating of Chessplayers, Past and Present , year =
Elo, Arpad E , publisher =. The Rating of Chessplayers, Past and Present , year =
-
[12]
Training verifiers to solve math word problems , year =
Cobbe, Karl and Kosaraju, Vineet and Bavarian, Mohammad and Chen, Mark and Jun, Heewoo and Kaiser, Lukasz and Plappert, Matthias and Tworek, Jerry and Hilton, Jacob and Nakano, Reiichiro and others , journal =. Training verifiers to solve math word problems , year =
-
[13]
Boyd-Graber , doi =
Nishant Balepur and Rachel Rudinger and J. Boyd-Graber , doi =. Annual Meeting of the Association for Computational Linguistics , title =
-
[14]
Efficient elicitation of annotations for human evaluation of machine translation , year =
Sakaguchi, Keisuke and Post, Matt and Van Durme, Benjamin , booktitle =. Efficient elicitation of annotations for human evaluation of machine translation , year =
-
[15]
Humans or LLMs as the judge? a study on judgement bias
Chen, Guiming Hardy and Chen, Shunian and Liu, Ziche and Jiang, Feng and Wang, Benyou , booktitle =. Humans or. doi:10.18653/v1/2024.emnlp-main.474 , file =
-
[16]
Do these llm benchmarks agree? fixing benchmark evaluation with benchbench , year =
Perlitz, Yotam and Gera, Ariel and Arviv, Ofir and Yehudai, Asaf and Bandel, Elron and Shnarch, Eyal and Shmueli-Scheuer, Michal and Choshen, Leshem , journal =. Do these llm benchmarks agree? fixing benchmark evaluation with benchbench , year =
-
[17]
Challenging BIG - Bench Tasks and Whether Chain -of- Thought Can Solve Them
Suzgun, Mirac and Scales, Nathan and Sch. Challenging. Findings of the Association for Computational Linguistics: ACL 2023 , month = jul, year =. doi:10.18653/v1/2023.findings-acl.824 , pages =
-
[18]
The validity of evaluation results: Assessing concurrence across compositionality benchmarks , year =
Sun, Kaiser and Williams, Adina and Hupkes, Dieuwke , booktitle =. The validity of evaluation results: Assessing concurrence across compositionality benchmarks , year =
-
[19]
First Conference on Language Modeling , year =
Length-Controlled AlpacaEval: A Simple Debiasing of Automatic Evaluators , author =. First Conference on Language Modeling , year =
-
[20]
Judging llm-as-a-judge with mt-bench and chatbot arena , volume =
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric and others , journal =. Judging llm-as-a-judge with mt-bench and chatbot arena , volume =
-
[21]
LLM-Rubric: A Multidimensional, Calibrated Approach to Automated Evaluation of Natural Language Texts , url =
Helia Hashemi and Jason Eisner and Corby Rosset and Benjamin Van Durme and Chris Kedzie , doi =. LLM-Rubric: A Multidimensional, Calibrated Approach to Automated Evaluation of Natural Language Texts , url =. Annual Meeting of the Association for Computational Linguistics , keywords =
-
[22]
Self-Preference Bias in
Koki Wataoka and Tsubasa Takahashi and Ryokan Ri , booktitle =. Self-Preference Bias in. 2024 , url =
2024
-
[23]
Do Question Answering Modeling Improvements Hold Across Benchmarks? , year =
Liu, Nelson F and Lee, Tony and Jia, Robin and Liang, Percy , booktitle =. Do Question Answering Modeling Improvements Hold Across Benchmarks? , year =
-
[24]
PandaLM: An Automatic Evaluation Benchmark for LLM Instruction Tuning Optimization , url =
Yidong Wang and Zhuohao Yu and Zhengran Zeng and Linyi Yang and Cunxiang Wang and Hao Chen and Chaoya Jiang and Rui Xie and Jindong Wang and Xingxu Xie and Wei Ye and Shikun Zhang and Yue Zhang , doi =. PandaLM: An Automatic Evaluation Benchmark for LLM Instruction Tuning Optimization , url =. International Conference on Learning Representations , keywords =
-
[25]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark , volume =
Wang, Yubo and Ma, Xueguang and Zhang, Ge and Ni, Yuansheng and Chandra, Abhranil and Guo, Shiguang and Ren, Weiming and Arulraj, Aaran and He, Xuan and Jiang, Ziyan and others , journal =. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark , volume =
-
[26]
NeurIPS 2025 Workshop on Evaluating the Evolving LLM Lifecycle: Benchmarks, Emergent Abilities, and Scaling , year =
Train-before-Test Harmonizes Language Model Rankings , author =. NeurIPS 2025 Workshop on Evaluating the Evolving LLM Lifecycle: Benchmarks, Emergent Abilities, and Scaling , year =
2025
-
[27]
arXiv preprint arXiv:2406.09363 , year =
Elicitationgpt: Text elicitation mechanisms via language models , author =. arXiv preprint arXiv:2406.09363 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.