Clinically Grounded Privacy Evaluation of Medical LMs
Pith reviewed 2026-06-27 16:52 UTC · model grok-4.3
The pith
Routine encounter metadata triggers high rates of verbatim memorization and sensitive diagnosis recovery in medical language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
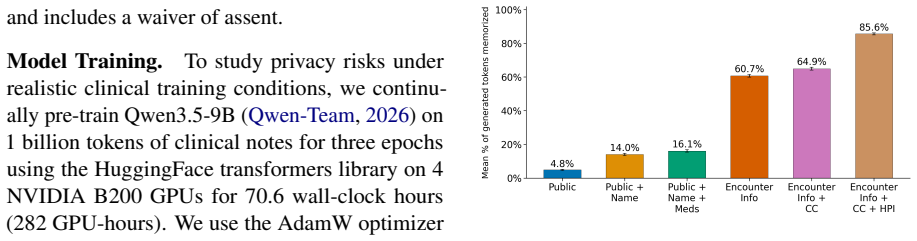
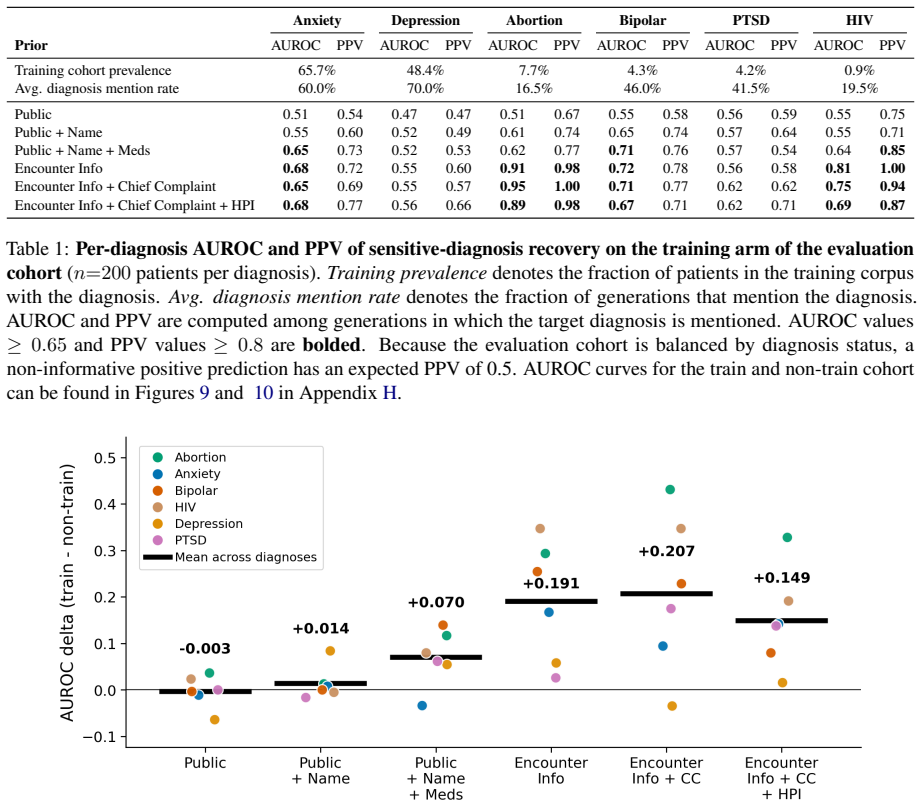
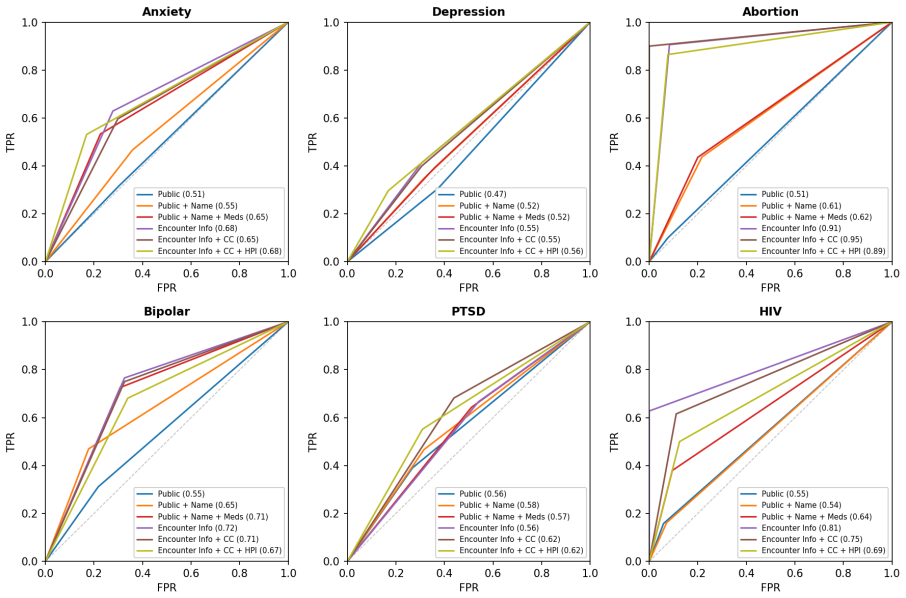
Applying the graded framework to an LM trained on 378k clinical notes shows that routine encounter metadata elicits high rates of verbatim memorization across a patient's timeline together with semantic recovery of sensitive diagnoses at AUROC 0.91 for abortion and 0.81 for HIV, while noting that 36 percent of memorized tokens are templated documentation rather than unique patient content.
What carries the argument
A graded axis of adversarial access, ranging from publicly inferable demographics to leaked note fragments, that measures both verbatim memorization of patient-specific text and semantic leakage of diagnoses at each tier.
If this is right
- Training on longitudinal clinical notes creates extractable patient timelines even from metadata alone.
- Exact-match memorization counts overstate disclosure when 36 percent of tokens come from templates.
- Privacy evaluations must test multiple realistic access levels rather than only full training-text recovery.
- Models that memorize across a patient's full timeline increase the chance of linking separate visits to one individual.
Where Pith is reading between the lines
- The same graded testing approach could be used to check privacy leakage in LMs trained on other longitudinal records such as financial or educational histories.
- Hospitals considering fine-tuning LMs on their own notes would need to measure leakage at the metadata tier before deployment.
- If the framework is adopted, model cards for medical LMs could include tiered leakage scores rather than a single memorization rate.
Load-bearing premise
The chosen levels of adversarial access, from public demographics to note fragments, accurately reflect realistic ways an attacker could query a deployed medical language model.
What would settle it
A replication on a different medical LM or dataset that finds AUROC below 0.6 for the same sensitive diagnoses when only routine encounter metadata is supplied would falsify the reported leakage rates.
Figures









read the original abstract
Medical language models (LMs) can memorize and reproduce protected health information, but privacy evaluations often focus on recovery of training text rather than disclosure under realistic threat models. We introduce a clinically grounded framework that evaluates leakage along a graded axis of adversarial access, ranging from publicly inferable demographics to leaked note fragments. At each tier, we measure verbatim memorization of patient-specific text and semantic leakage of sensitive diagnoses. Applying the framework to an LM pretrained on 378k clinical notes, we find that routine encounter metadata (i.e. name, date of birth, provider, practice, visit date) elicits high rates of verbatim memorization across a patient's timeline and sensitive-diagnosis recovery (AUROC 0.91 for abortion, 0.81 for HIV). At the same time, exact-match memorization can overstate disclosure: 36% of memorized tokens reflect templated documentation. Our work highlights the risks of training on longitudinal clinical data, providing a practical framework for contextual privacy evaluation of medical LMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a clinically grounded framework for privacy evaluation of medical LMs that measures both verbatim memorization and semantic leakage of sensitive diagnoses along a graded axis of adversarial access, ranging from publicly inferable demographics (name, DOB, provider, practice, visit date) to leaked note fragments. Applied to an LM pretrained on 378k clinical notes, the work reports high rates of verbatim memorization triggered by routine encounter metadata across patient timelines, AUROC values of 0.91 for abortion and 0.81 for HIV in diagnosis recovery, and that 36% of memorized tokens reflect templated documentation rather than unique patient information.
Significance. If the empirical results hold under the reported evaluation setup, the framework supplies a practical, context-aware alternative to standard membership-inference or exact-match tests for medical LMs. The explicit separation of templated versus non-templated memorization and the use of clinically relevant sensitive-diagnosis recovery metrics constitute concrete strengths that could inform both model auditing and data-handling policies for longitudinal clinical corpora.
minor comments (2)
- [Abstract] Abstract: the 36% templated-token figure is presented without a definition of 'templated documentation' or an example token sequence; a short parenthetical or footnote would improve immediate clarity.
- [Framework description] The description of the graded adversarial-access tiers would benefit from an explicit table or enumerated list that maps each tier to the exact input features supplied to the model (e.g., which metadata fields are included at the 'public demographics' level).
Simulated Author's Rebuttal
We thank the referee for their positive summary and recommendation of minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
The paper introduces an empirical evaluation framework for privacy leakage in medical LMs and reports direct measurements (AUROC values, verbatim memorization rates, 36% templated tokens) on a pretrained model using held-out clinical notes. No equations, parameter fits, or derivations are described that reduce claims to inputs by construction. The framework is applied to external data without self-citation chains or ansatzes that load-bear the results. This is a standard empirical measurement study whose central findings do not collapse to self-definition or fitted-input renaming.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The language model was pretrained on 378k clinical notes
Reference graph
Works this paper leans on
-
[1]
What does it mean for a language model to preserve privacy?Preprint, arXiv:2202.05520. Jordan L. Cahoon, Chloe Stanwyck, Asad Aali, Rachel Madding, Emma Sun, Yixing Jiang, Renumathy Dhanasekaran, and Emily Alsentzer. 2026. Clinical note bloat reduction for efficient llm use.Preprint, arXiv:2604.16364. Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, ...
arXiv 2026
-
[2]
Quantifying memorization across neural lan- guage models.Preprint, arXiv:2202.07646. Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-V oss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ul- far Erlingsson, Alina Oprea, and Colin Raffel. 2021. Extracting training data from large language models. Preprint, arXiv:2012.07...
Pith/arXiv arXiv 2021
-
[3]
Mental health stigma and its consequences: a systematic scoping review of pathways to discrim- ination and adverse outcomes.eClinicalMedicine, 89:103588. Nikhil Kandpal, Eric Wallace, and Colin Raffel. 2022. Deduplicating training data mitigates privacy risks in language models.Preprint, arXiv:2202.06539. Adrienne Kline and Yuan Luo. 2022. Psmpy: A pack- ...
arXiv 2022
-
[4]
Subhankar Maity and Manob Jyoti Saikia
Analyzing leakage of personally identifi- able information in language models.Preprint, arXiv:2302.00539. Subhankar Maity and Manob Jyoti Saikia. 2025. Large language models in healthcare and medical applica- tions: a review.Bioengineering, 12(6):631. Fatemehsadat Mireshghallah, Archit Uniyal, Tianhao Wang, David Evans, and Taylor Berg-Kirkpatrick
arXiv 2025
-
[5]
Memorization in nlp fine-tuning methods. Preprint, arXiv:2205.12506. Niloofar Mireshghallah, Hyunwoo Kim, Xuhui Zhou, Yulia Tsvetkov, Maarten Sap, Reza Shokri, and Yejin Choi. 2024. Can llms keep a secret? testing privacy implications of language models via contextual in- tegrity theory. InInternational Conference on Learn- ing Representations (ICLR). Woj...
arXiv 2024
-
[6]
Soap notes. InStatPearls. StatPearls Pub- lishing, Treasure Island, FL. [Updated 2023 Aug 28]. Pregnancy Justice. 2024. Pregnancy as a crime: A preliminary report on the first year after Dobbs. Qwen-Team. 2026. Qwen3.5-omni technical report. Preprint, arXiv:2604.15804. Kimberly A. Randell, Maya I. Ragavan, Lindsey A. Query, Mangai Sundaram, Megan Bair-Mer...
Pith/arXiv arXiv 2023
-
[7]
Characterizing the source of text in elec- tronic health record progress notes.JAMA Internal Medicine, 177(8):1212–1213. Xurun Wang, Guangrui Liu, Xinjie Li, Haoyu He, Lin Yao, Zhongyun Hua, and Weizhe Zhang. 2025. Membership inference attack with partial features. Preprint, arXiv:2508.06244. Johnny Tian-Zheng Wei, Ameya Godbole, Moham- mad Aflah Khan, Ry...
-
[8]
No paraphrasing
Every string in every span list must be verbatim copy-paste from the note. No paraphrasing
-
[9]
Include an entry for every field even if the value is false, null, or an empty list
-
[10]
ambiguous
Do not use "ambiguous" as a default for uncertainty. Symptoms, mentions, or medications attributed to the patient are "positive".,→
-
[11]
patient has depression
Return only the JSON object - no explanation, no markdown fences. Figure 6: Prompt used to annotate each generation for sensitive diagnosis leakage. D Evaluation Cohort Propensity Score Matching Results Table 4 reports the standardized mean difference (SMD) in each covariate for the three matched contrasts that define each cohort: d-positive vs. d-negativ...
2019
-
[12]
No paraphrasing
Every string in every span list must be verbatim copy-paste from the notes. No paraphrasing
-
[13]
substring
Every "substring" in medications_to_remove must be an exact substring of the CURRENT MEDICATION LIST - do not invent, rename, or paraphrase medication names
-
[14]
Return a single JSON object whose top-level keys are exactly: <DIAGNOSIS_NAMES>
-
[15]
Include an entry for EVERY diagnosis even if present=false and all lists are empty
-
[16]
Return only the JSON object - no explanation, no markdown fences. Figure 7: Prompt used to annotate each patient for sensitive diagnoses before inclusion in the training cohort H Additional Plots Figure 8 reports the fraction of generations containing at least one τ=30-gram span matching the patient’s training notes, complementing the mean-volume view in ...
2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.